小编对于张量的理解一直很模糊,今天用Excel来帮助大家理解,希望对大家有所帮助。
首先,张量是多维数组,这里不多赘述,可以去查阅相关资料。今天重点介绍的是张量的维度。
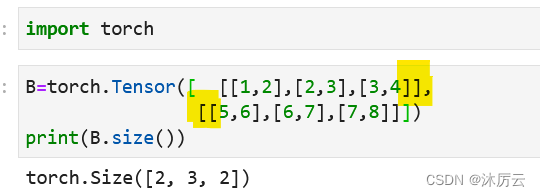
张量有一维、二维、三维、四维等。
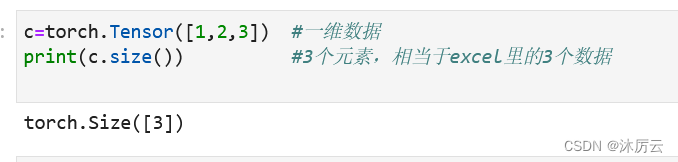
正如我们的Eecel表里的3个数字就组成一维数据。
你也可以把它理解为一行数据,即由单个元素组成的一组数据。
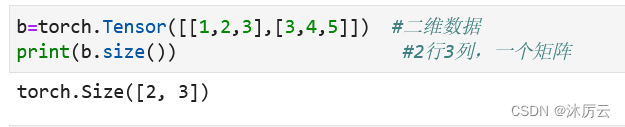
二维就是一维的叠加。
前面所说可以把“一行”看作一维
那么二维就是多行,也就相当于Excel里的一个工作部(下方的sheet1)
但是这里要注意,代码最外面有两个中括号,如果只有一个中括号,就会报错。
这里简单记忆可以理解为:有几维,最外面的中括号就有几个


torch.Size([1,2,3]),第一个1表示1个深度,你可以理解为Excel的一个工作部,如果是2,那就是两个工作部。
第二个数字表示2行,第三个数字表示3列。
三维就相当于Excel里的多个工作部
上图所示是深度为1,即1个Excel工作部,接下来我们来看深度为2的,即2分Excel工作部:
这里就有两个深度,相当于一个Excel文件中的两个工作部,sheet1和sheet2。
注意:标黄处是两个工作部的分隔
前文所说,有几个维度就有几个维度。标黄处是2个中括号,即标黄中括号里的数据是第二维,那么这两个中括号中的二维数据(即多行数据)一叠加就成了我们的三维数据(即一个或多个Excel工作部)
如图
现在已经介绍完三维了,也就是多个工作部,那这些工作部最终就能组成一个Excel文件,即第四维。


这里的torch.Size([1,1,2,3]),左边第一个数字 1表示这个张量在第四维占了一个,即一个Excel表,第二个数字1表示三维上的1,即1个工作部
第三个数字2表示每个工作部里有2行,当然,这里就1个工作部
第四个数字3表示每个工作部里有3列。
接下来,我们就要介绍tensor的升维与降维,降维用到的函数是torch.squeeze()函数。
那么升维用到的就是torch.unsqueeze()函数。
为什么要降维呢?
小编认为这是为了减少计算耗时,就像你的一个Excel文件,里面有10个工作部,但只有第一个工作部有数据,那其他9个工作部在大部分时候就是无用的,此时就需要用到降维。
我们看下面这个代码,这里,第三维第4维都是只有一个占位(维数)的,也就是说,此时我们在第3维,第4维看到的数据都是一样的,那么就可以降去第3维和第4维。
而第二维有3个占位(维数),如果去掉这一维,那么数据就会收到影响。

以下是降维的具体代码

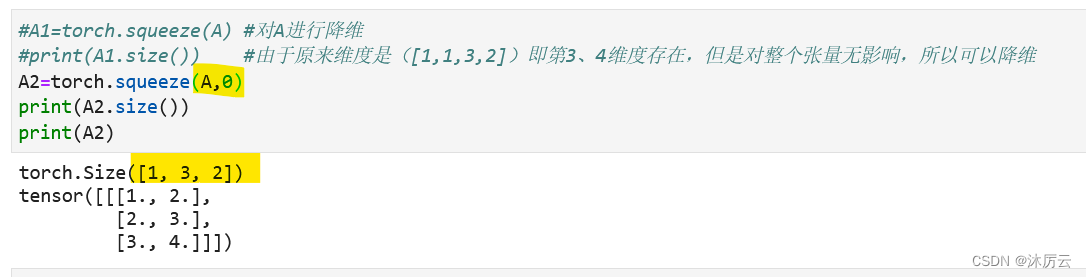
这里的torch.squeeze(A,0)的0时什么意思呢?
在第0个位置,这个函数就是,如果第0个位置的维度是1,那么就删除该维度
在原本的维度(1,1,3,2)中,从左向右一次是位置0,1,2,3,。没有第四位
如果我们输入torch.squeeze(A,2),看一看结果:
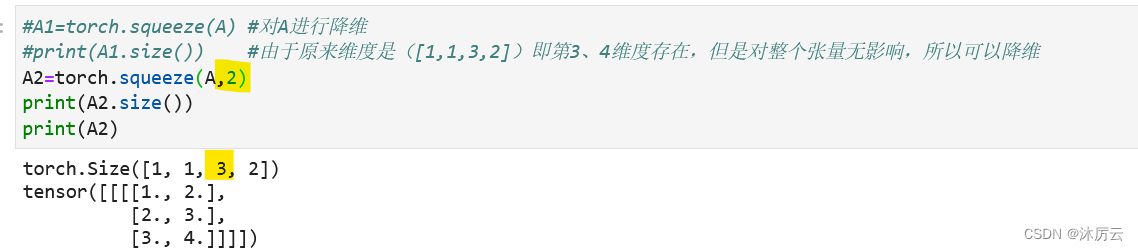
一个维度也没降,因为第2位置的维度是3,自然不会删除该维度。
那我们再来看看如果输入torch.squeeze(A,4)会是什么结果呢
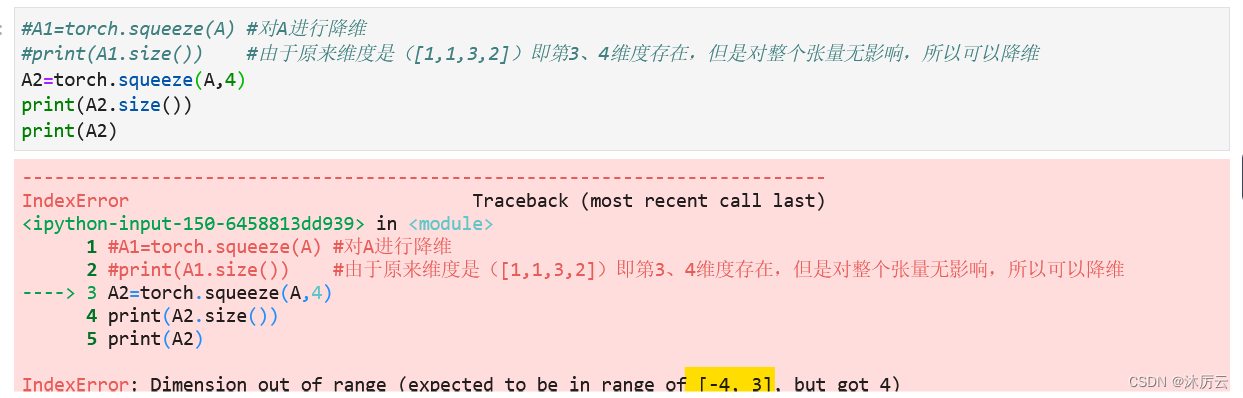
(哈哈,当然会报错啦)
同样,也可以输入负数的,负数就有-4,如果是负数,那从左向右一次是-4,-3,-2,-1
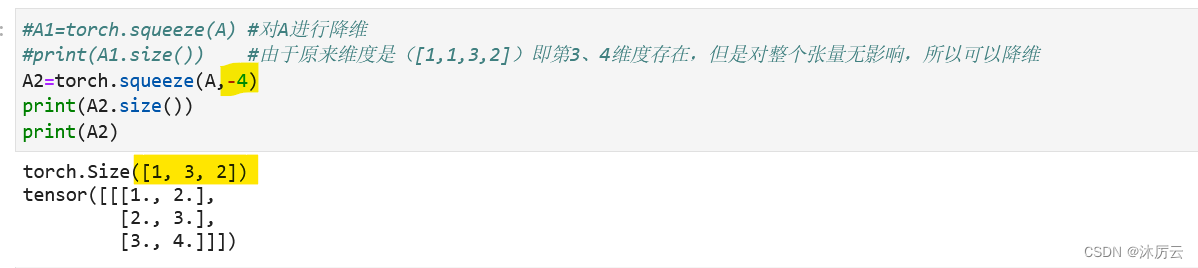
介绍完降维,我们来介绍一下升维吧
降维理解了,升维就不难理解了
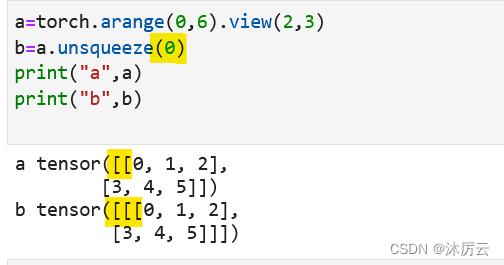
b=a.unsqueeze(0)即在索引0对应的位置增加一个维度
下面是咋索引1对应位置增加一个维度

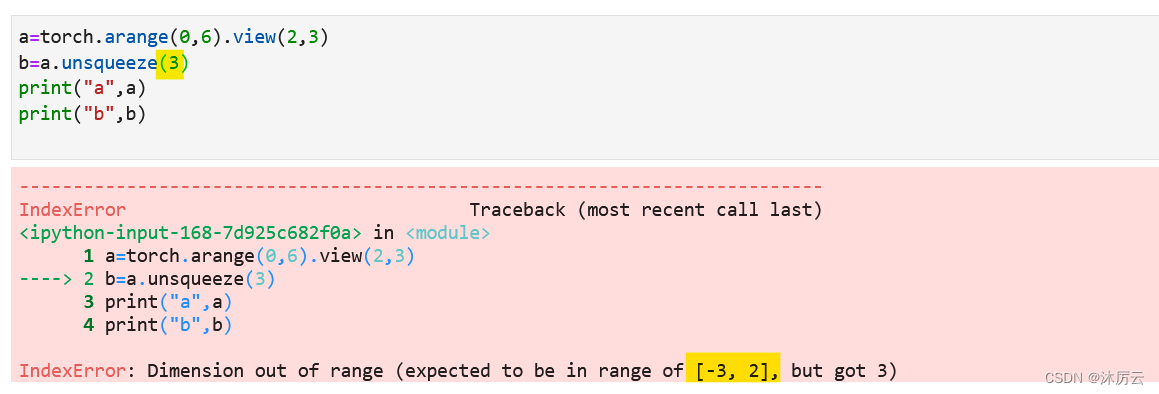
这是在索引2位置增加:
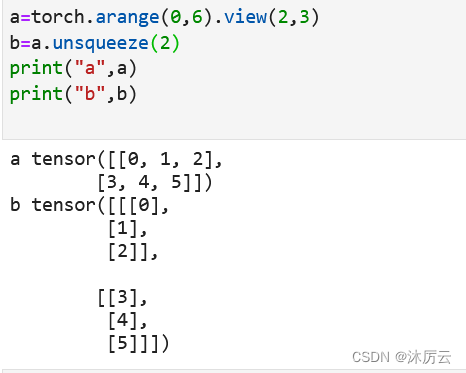
同样的,这里也没有3,但是可以有负数,就不一一赘述了。
先创建一个tensor>>>importtorch>>>a=torch.rand(1,4,3) >>>print(a) tensor([[[0.0132,0.7809,0.0468], [0.2689,0.6871,0.2538], [0.7656,0.5300,0.2499], [0.2500,0.4967,0.0685]]]) 分类进行reshape操作时,假如第二维代表类别,直接reshape使得数据对应结果会错>>>b=a.reshape(-1,4)>>>print(b) tensor([[0.0132,0.7809,0.0468,0.2689],
导读随着ChatGPT出现,语言大模型的进步与对话交互方式相结合,正在搅动科研、产业,以及普通人的想象力。我们对智能的探索是正在步入决胜之局,还是仍在中场酣战;是需要精巧完备的一致系统,还是可以遵循实效至上WorseisBetter的设计哲学?打造面向未来的LLM与Chatbot,技术人员面对哪些共同阻碍,有哪些极限有待超越,如何协作共赢?在青源Workshop(第20期)|LLMandChatbot:Endgame,WorseisBetter,HowtoWinBig研讨会上,智源社区与青源会邀请十余位相关领域专家,围绕以上话题展开热烈研讨。引导报告环节,袁进辉提出:ChatGPT开启了全新维
我在我的Windows机器和名为“default”的OracleVMVirtualbox之间设置了一个共享文件夹“tensor”。[我运行Windows7,正在使用OracleVMVirtualBoxManager和Docker工具箱。]然后,我打开DockerToolboxQuickstart终端,ssh进入“默认”VMBox,然后可以成功地将张量文件夹安装到它的目录中,如下所示:我在本地计算机上创建了“hello_world.txt”,该文件显示在虚拟机中。我的问题是,当我在默认框中的容器中运行tensorflow图像时,我似乎无法弄清楚如何使用这个目录(另外,我是新手,所以如果我
一、Tensor的降维——torch.squeeze()函数1.tensor的维度小编对于张量的理解一直很模糊,今天用Excel来帮助大家理解,希望对大家有所帮助。首先,张量是多维数组,这里不多赘述,可以去查阅相关资料。今天重点介绍的是张量的维度。张量有一维、二维、三维、四维等。一维:正如我们的Eecel表里的3个数字就组成一维数据。你也可以把它理解为一行数据,即由单个元素组成的一组数据。 二维: 二维就是一维的叠加。前面所说可以把“一行”看作一维那么二维就是多行,也就相当于Excel里的一个工作部(下方的sheet1)但是这里要注意,代码最外面有两个中括号,如果只有一个中括号,就会报错。这
🚀优质资源分享🚀学习路线指引(点击解锁)知识定位人群定位🧡Python实战微信订餐小程序🧡进阶级本课程是pythonflask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。💛Python量化交易实战💛入门级手把手带你打造一个易扩展、更安全、效率更高的量化交易系统本文记录阅读该paper的笔记,这篇论文是TenSeal库的原理介绍。摘要机器学习算法已经取得了显著的效果,并被广泛应用于各个领域。这些算法通常依赖于敏感和私有数据,如医疗和财务记录。因此,进一步关注隐私威胁和应用于机器学习模型的相应防御技术至关重要。在本文中,我们介绍了TenSEAL,这是一个使用同态加密保
在C++中表示稀疏张量的适当数据结构是什么?想到的第一个选项是boost::unordered_map,因为它允许像快速设置和检索an元素这样的操作,如下所示:A(i,j,k,l)=5但是,我也希望能够对单个索引进行收缩,这将涉及对其中一个索引的求和C(i,j,k,m)=A(i,j,k,l)*B(l,m)用boost::unordered_map实现这个运算符有多容易?有没有更合适的数据结构? 最佳答案 有可用的张量库,例如:http://www.codeproject.com/KB/recipes/tensor.aspx和http
我运行了一个小实验来对tf.sparse_tensor_dense_matmul操作进行基准测试。不幸的是,我对结果感到惊讶。我正在运行稀疏矩阵、密集vector乘法和变化稀疏矩阵的列数(递减)密集vector的行数(递减)稀疏矩阵的稀疏度(递增)在增加每次运行的稀疏性的同时,我减少了列。这意味着非零值的数量(nnz)始终保持不变(每行100个)。在测量计算matml操作所需的时间时,我希望它会保持不变(因为输出大小和nnz会发生变化)。我看到的是以下内容:我查看了C++代码,看是否能找出导致该结果的任何原因。不过,考虑到C++代码,我希望每次运行的时间相同。如果我对代码的理解正确,它
我想将一个N维Eigen::Tensor广播到一个(N+1)维Tensor来做一些简单的代数。我想不出正确的语法。我已经尝试过就地广播,并将广播的结果分配给一个新的张量。两者都无法编译并显示大量模板错误消息(在Mac上使用AppleClang10.0.1编译)。我认为相关的问题是编译器无法为.resize()找到有效的重载。我已尝试使用std::array、Eigen::array和`Eigen::Tensor::Dimensions进行维度类型的广播操作,但均无效:srand(time(0));Eigen::Tensort3(3,4,5);Eigen::Tensort2(3,4);t
好吧,我已经在谷歌上搜索了太久,我只是不确定如何称呼这种技术,所以我认为最好在这里问一下。如果我忽略了明显的名称和/或解决方案,请指出正确的方向。对于外行来说:张量是矩阵的逻辑扩展,就像矩阵是vector的逻辑扩展一样。vector是1阶张量(在编程术语中,一维数字数组),矩阵是2阶张量(2维数字数组),N阶张量只是一个N维数字数组.现在,假设我有类似这个Tensor类的东西:template//possiblyalsowithsizeparametersclassTensor{private:T*M;//Tensordata(C-array)//alternatively,std::
在Python代码中,图像数据赋值给tensorimage_batch:部分代码:image_data=misc.imread(image_path)image_batch=graph.get_tensor_by_name("input:0")phase_train_placeholder=graph.get_tensor_by_name("phase_train:0")embeddings=graph.get_tensor_by_name("embeddings:0")feed_dict={image_batch:np.expand_dims(image_data,0),phase_