文章目录
import numpy as np
import pandas as pd
import sklearn
import matplotlib as mlp
import matplotlib.pyplot as plt
import seaborn as sns
import time
import re, pip, conda
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.model_selection import cross_validate, KFold, GridSearchCV
data = pd.read_csv(r"D:\Pythonwork\2021ML\PART 2 Ensembles\datasets\House Price\train_encode.csv",index_col=0)
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
X.shape
#(1460, 80)
X.head()
y.describe() #RMSE
#参数空间
param_grid_simple = {"criterion": ["squared_error","poisson"]
, 'n_estimators': [*range(20,100,5)]
, 'max_depth': [*range(10,25,2)]
, "max_features": ["log2","sqrt",16,32,64,"auto"]
, "min_impurity_decrease": [*np.arange(0,5,10)]
}
#参数空间大小计算
2 * len([*range(20,100,5)]) * len([*range(10,25,2)]) * len(["log2","sqrt",16,32,64,"auto"]) * len([*np.arange(0,5,10)])
#1536
#直接使用循环计算
no_option = 1
for i in param_grid_simple:
no_option *= len(param_grid_simple[i])
no_option
#1536
#模型,交叉验证,网格搜索
reg = RFR(random_state=1412,verbose=True,n_jobs=-1)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
search = GridSearchCV(estimator=reg
,param_grid=param_grid_simple
,scoring = "neg_mean_squared_error"
,verbose = True
,cv = cv
,n_jobs=-1)
#=====【TIME WARNING: 7mins】=====#
start = time.time()
search.fit(X,y)
print(time.time() - start)
Fitting 5 folds for each of 1536 candidates, totalling 7680 fits
#381.6039867401123
381.6039/60
#6.3600650000000005
search.best_estimator_
#RandomForestRegressor(max_depth=23, max_features=16, min_impurity_decrease=0,
# n_estimators=85, n_jobs=-1, random_state=1412,
# verbose=True)
abs(search.best_score_)**0.5
#29179.698261599166
#按最优参数重建模型,查看效果
ad_reg = RFR(n_estimators=85, max_depth=23, max_features=16, random_state=1412)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
result_post_adjusted = cross_validate(ad_reg,X,y,cv=cv,scoring="neg_mean_squared_error"
,return_train_score=True
,verbose=True
,n_jobs=-1)
def RMSE(cvresult,key):
return (abs(cvresult[key])**0.5).mean()
RMSE(result_post_adjusted,"train_score")
#11000.81099038192
RMSE(result_post_adjusted,"test_score")
#28572.070208366855
| HPO方法 | 默认参数 | 网格搜索 |
|---|---|---|
| 搜索空间/全域空间 | - | 1536/1536 |
| 运行时间(分钟) | - | 6.36 |
| 搜索最优(RMSE) | 30571.266 | 29179.698 |
| 重建最优(RMSE) | - | 28572.070 |
#打包成函数供后续使用
#评估指标RMSE
def RMSE(cvresult,key):
return (abs(cvresult[key])**0.5).mean()
#计算参数空间大小
def count_space(param):
no_option = 1
for i in param_grid_simple:
no_option *= len(param_grid_simple[i])
print(no_option)
#在最优参数上进行重新建模验证结果
def rebuild_on_best_param(ad_reg):
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
result_post_adjusted = cross_validate(ad_reg,X,y,cv=cv,scoring="neg_mean_squared_error"
,return_train_score=True
,verbose=True
,n_jobs=-1)
print("训练RMSE:{:.3f}".format(RMSE(result_post_adjusted,"train_score")))
print("测试RMSE:{:.3f}".format(RMSE(result_post_adjusted,"test_score")))
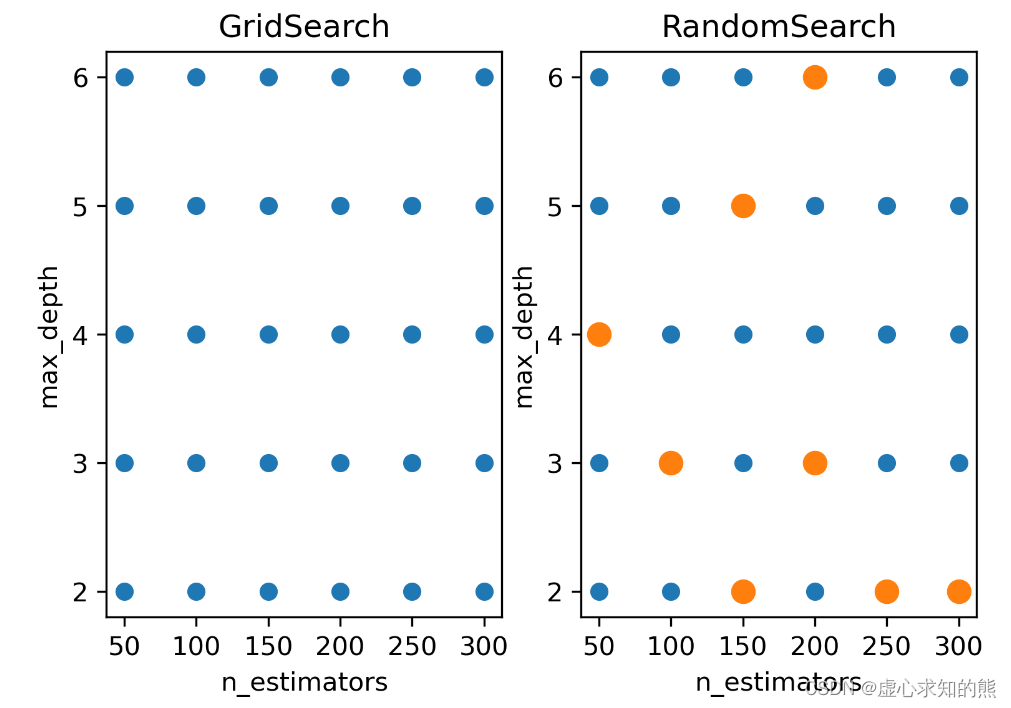
fig, [ax1, ax2] = plt.subplots(1,2,dpi=300)
n_e_list = [*range(50,350,50)]
m_d_list = [*range(2,7)]
comb = pd.DataFrame([(n_estimators, max_depth) for n_estimators in n_e_list for max_depth in m_d_list])
ax1.scatter(comb.iloc[:,0],comb.iloc[:,1],cmap="Blues")
ax1.set_xticks([*range(50,350,50)])
ax1.set_yticks([*range(2,7)])
ax1.set_xlabel("n_estimators")
ax1.set_ylabel("max_depth")
ax1.set_title("GridSearch")
ax2.scatter(comb.iloc[:,0],comb.iloc[:,1],cmap="Blues")
ax2.scatter([50,250,200,200,300,100,150,150],[4,2,6,3,2,3,2,5],cmap="red",s=20,linewidths=5)
ax2.set_xticks([*range(50,350,50)])
ax2.set_yticks([*range(2,7)])
ax2.set_xlabel("n_estimators")
ax2.set_ylabel("max_depth")
ax2.set_title("RandomSearch");
from sklearn.model_selection import RandomizedSearchCV
class sklearn.model_selection.RandomizedSearchCV(estimator, param_distributions, *, n_iter=10, scoring=None, n_jobs=None, refit=True, cv=None, verbose=0, pre_dispatch='2*n_jobs', random_state=None, error_score=nan, return_train_score=False)
| Name | Description |
|---|---|
| estimator | 调参对象,某评估器 |
| param_distributions | 全域参数空间,可以是字典或者字典构成的列表 |
| n_iter | 迭代次数,迭代次数越多,抽取的子参数空间越大 |
| scoring | 评估指标,支持同时输出多个参数 |
| n_jobs | 设置工作时参与计算的线程数 |
| refit | 挑选评估指标和最佳参数,在完整数据集上进行训练 |
| cv | 交叉验证的折数 |
| verbose | 输出工作日志形式 |
| pre_dispatch | 多任务并行时任务划分数量 |
| random_state | 随机数种子 |
| error_score | 当网格搜索报错时返回结果,选择’raise’时将直接报错并中断训练过程,其他情况会显示警告信息后继续完成训练 |
| return_train_score | 在交叉验证中是否显示训练集中参数得分 |
X.shape
#(1460, 80)
X.head()
y.describe()
param_grid_simple = {"criterion": ["squared_error","poisson"]
, 'n_estimators': [*range(20,100,5)]
, 'max_depth': [*range(10,25,2)]
, "max_features": ["log2","sqrt",16,32,64,"auto"]
, "min_impurity_decrease": [*np.arange(0,5,10)]
}
reg = RFR(random_state=1412,verbose=True,n_jobs=-1)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
count_space(param_grid_simple)
#1536
search = RandomizedSearchCV(estimator=reg
,param_distributions=param_grid_simple
,n_iter = 800 #子空间的大小是全域空间的一半左右
,scoring = "neg_mean_squared_error"
,verbose = True
,cv = cv
,random_state=1412
,n_jobs=-1
)
#=====【TIME WARNING: 5~10min】=====#
start = time.time()
search.fit(X,y)
print(time.time() - start)
#Fitting 5 folds for each of 800 candidates, totalling 4000 fits
#170.16785073280334
170.1678/60
#2.83613
search.best_estimator_
#RandomForestRegressor(max_depth=24, max_features=16, min_impurity_decrease=0,
# n_estimators=85, n_jobs=-1, random_state=1412,
# verbose=True)
abs(search.best_score_)**0.5
#29251.284326350575
ad_reg = RFR(max_depth=24, max_features=16, min_impurity_decrease=0,
n_estimators=85, n_jobs=-1, random_state=1412,
verbose=True)
rebuild_on_best_param(ad_reg)
#训练RMSE:11031.299
#测试RMSE:28639.969
| HPO方法 | 默认参数 | 网格搜索 | 随机搜索 |
|---|---|---|---|
| 搜索空间/全域空间 | - | 1536/1536 | 800/1536 |
| 运行时间(分钟) | - | 6.36 | 2.83(↓) |
| 搜索最优(RMSE) | 30571.266 | 29179.698 | 29251.284 |
| 重建最优(RMSE) | - | 28572.070 | 28639.969(↑) |
from mpl_toolkits.mplot3d import axes3d
p1, p2, MSE = axes3d.get_test_data(0.05)
len(p1) #参数1的取值有120个
#120
len(p2) #参数2的取值也有120个
#120
MSE.shape #损失函数值,总共14400个点
#(120, 120)
plt.figure(dpi=300)
plt.scatter(p1,p2,s=0.2)
plt.xticks(fontsize=9)
plt.yticks(fontsize=9)
p1, p2, MSE = axes3d.get_test_data(0.05)
plt.figure(dpi=300)
ax = plt.axes(projection="3d")
ax.plot_wireframe(p1,p2,MSE,rstride=2,cstride=2,linewidth=0.5)
ax.view_init(2, -15)
ax.zaxis.set_tick_params(labelsize=7)
ax.xaxis.set_tick_params(labelsize=7)
ax.yaxis.set_tick_params(labelsize=7)
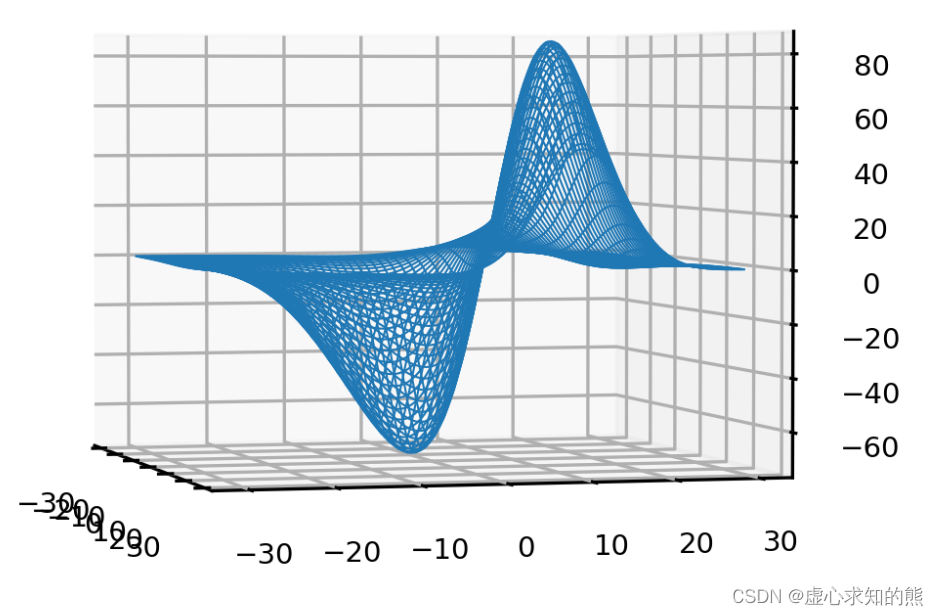
np.min(MSE) #整个参数空间中,可获得的MSE最小值是-73.39
#-73.39620971601681
MSE.shape
#(120, 120)
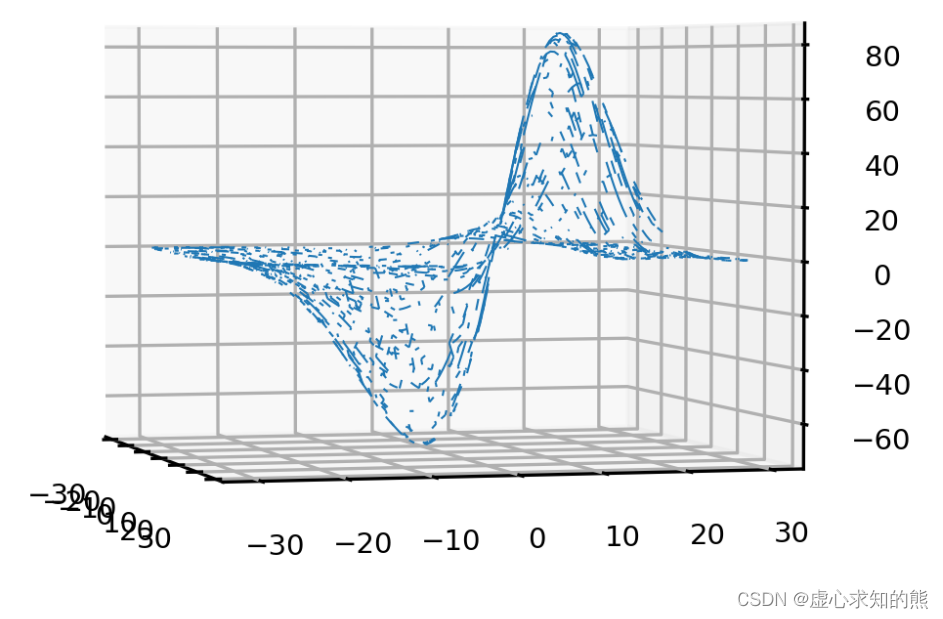
n = 100
unsampled = np.random.randint(0,14400,14400-n)
p1, p2, MSE = axes3d.get_test_data(0.05)
MSE = MSE.ravel()
MSE[unsampled] = np.nan
MSE = MSE.reshape((120,120))
#参数与损失共同构建的函数
plt.figure(dpi=300)
ax = plt.axes(projection="3d")
ax.view_init(2, -15)
ax.plot_wireframe(p1,p2,MSE,rstride=2,cstride=2,linewidth=0.5)
ax.zaxis.set_tick_params(labelsize=7)
ax.xaxis.set_tick_params(labelsize=7)
ax.yaxis.set_tick_params(labelsize=7)
MSE = MSE.ravel().tolist()
MSE = [x for x in MSE if str(x) != 'nan']
print(np.min(MSE))
#-73.24243733589367
param_grid_simple = {'n_estimators': [*range(80,100,1)]
, 'max_depth': [*range(10,25,1)]
, "max_features": [*range(10,20,1)]
, "min_impurity_decrease": [*np.arange(0,5,10)]
}
count_space(param_grid_simple)
#3000
reg = RFR(random_state=1412,verbose=True,n_jobs=-1)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
search = RandomizedSearchCV(estimator=reg
,param_distributions=param_grid_simple
,n_iter = 1536 #使用与枚举网格搜索类似的拟合次数
,scoring = "neg_mean_squared_error"
,verbose = True
,cv = cv
,random_state=1412
,n_jobs=-1)
start = time.time()
search.fit(X,y)
end = time.time() - start
print(end/60)
#Fitting 5 folds for each of 1536 candidates, totalling 7680 fits
#3.8464645385742187
search.best_estimator_
RandomForestRegressor(max_depth=22, max_features=14, min_impurity_decrease=0,
n_estimators=89, n_jobs=-1, random_state=1412,
verbose=True)
abs(search.best_score_)**0.5
#29012.90569846546
rebuild_on_best_param(search.best_estimator_)
#训练RMSE:11208.818
#测试RMSE:28346.673
| HPO方法 | 默认参数 | 网格搜索 | 随机搜索 | 随机搜索 (大空间) |
|---|---|---|---|---|
| 搜索空间/全域空间 | - | 1536/1536 | 800/1536 | 1536/3000 |
| 运行时间(分钟) | - | 6.36 | 2.83(↓) | 3.86(↓) |
| 搜索最优(RMSE) | 30571.266 | 29179.698 | 29251.284 | 29012.905(↓) |
| 重建最优(RMSE) | - | 28572.070 | 28639.969(↑) | 28346.673(↓) |
import scipy #使用scipy来帮助我们建立分布
scipy.stats.uniform(loc=1,scale=100)
#<scipy.stats._distn_infrastructure.rv_frozen at 0x137a147d7c0>
param_grid_simple = {'n_estimators': [*range(80,100,1)]
, 'max_depth': [*range(10,25,1)]
, "max_features": [*range(10,20,1)]
, "min_impurity_decrease": scipy.stats.uniform(0,50)
}
#建立回归器、交叉验证
reg = RFR(random_state=1412,verbose=True,n_jobs=12)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
#定义随机搜索
search = RandomizedSearchCV(estimator=reg
,param_distributions=param_grid_simple
,n_iter = 1536 #还是使用1536这个搜索次数
,scoring = "neg_mean_squared_error"
,verbose = True
,cv = cv
,random_state=1412
,n_jobs=12)
#训练随机搜索评估器
start = time.time()
search.fit(X,y)
end = time.time() - start
print(end/60)
#Fitting 5 folds for each of 1536 candidates, totalling 7680 fits
#3.921058924992879
#查看最佳评估器
search.best_estimator_
#RandomForestRegressor(max_depth=22, max_features=14,
# min_impurity_decrease=20.070367229896224, n_estimators=98,
# n_jobs=12, random_state=1412, verbose=True)
#查看最终评估指标
abs(search.best_score_)**0.5
#29148.381610182565
rebuild_on_best_param(search.best_estimator_)
#训练RMSE:11184.428
#测试RMSE:28495.682
| HPO方法 | 默认参数 | 网格搜索 | 随机搜索 | 随机搜索 (大空间) | 随机搜索 (连续型) |
|---|---|---|---|---|---|
| 搜索空间/全域空间 | - | 1536/1536 | 800/1536 | 1536/3000 | 1536/无限 |
| 运行时间(分钟) | - | 6.36 | 2.83(↓) | 3.86(↓) | 3.92 |
| 搜索最优(RMSE) | 30571.266 | 29179.698 | 29251.284 | 29012.905(↓) | 29148.381 |
| 重建最优(RMSE) | - | 28572.070 | 28639.969(↑) | 28346.673(↓) | 28495.682 |
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
我有一个名为Post的类,我需要能够适应以下场景:如果用户选择了一个类别,则只显示该类别的帖子如果用户选择了一种类型,则只显示该类型的帖子如果用户选择了一个类别和类型,则只显示该类别中该类型的帖子如果用户没有选择任何内容,则显示所有帖子我想知道我的Controller是否不可避免地会因大量条件语句而显得粗糙...这是我解决此问题的错误方法-有谁知道我如何才能做到这一点?classPostsController 最佳答案 您最好遵循“胖模型,瘦Controller”的惯例,这意味着您应该将这种逻辑放在模型本身中。Post类应该能够报告