目录
1、Carla:0.9.11
2、Python:3.7.8
3、操作系统:Windows10
4、VS 2019,SDK没有特殊限制
5、RoadRunner安装需要许可证,试用许可证30天,高校一般有免费的可以申请
将新建的文件进行导出…
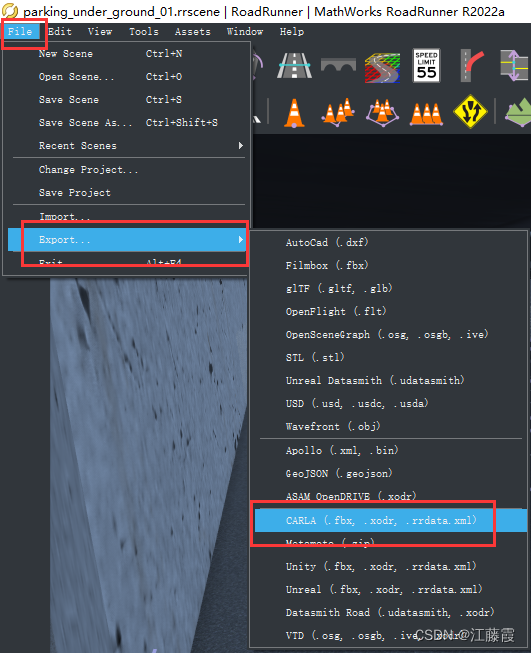
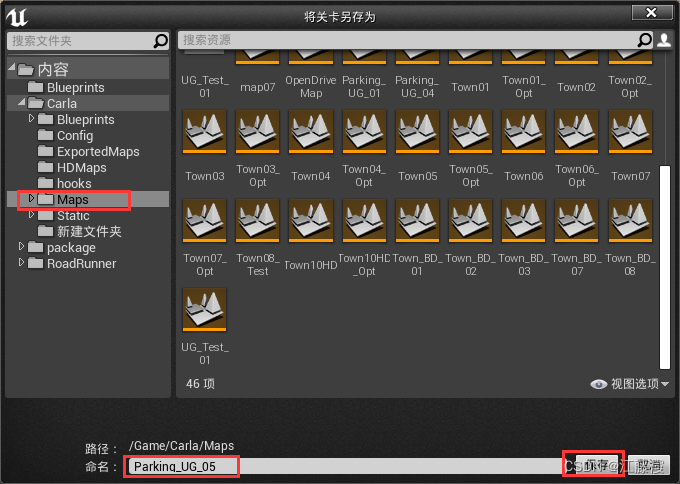
本案例地图命名为:Parking_UG_05
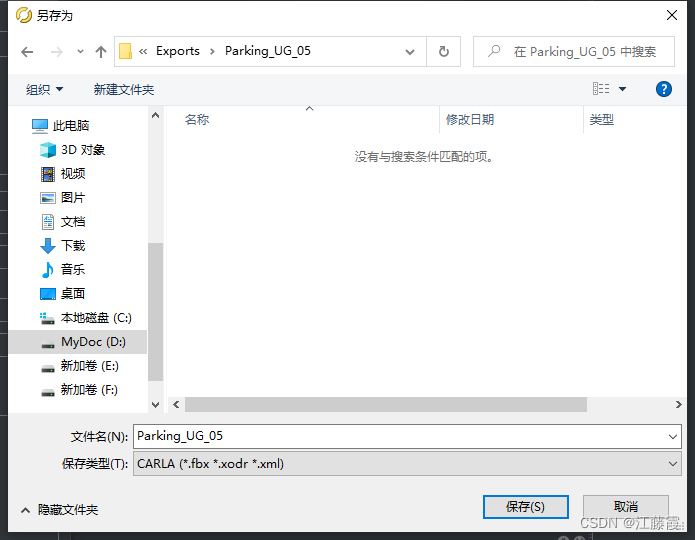
点击Export!
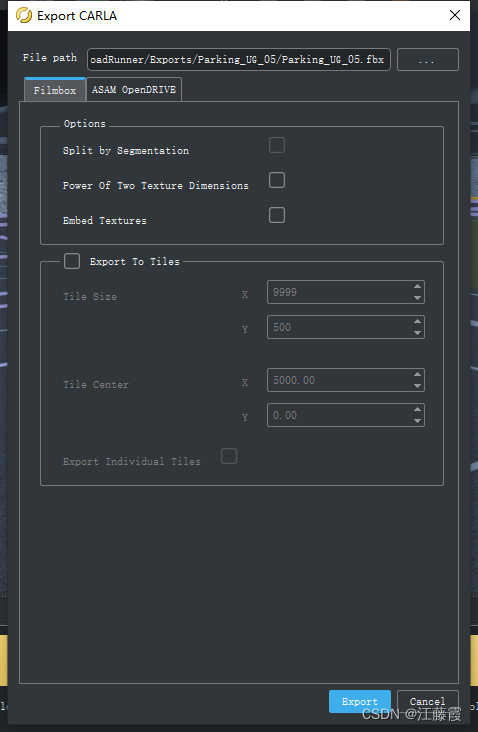
导出结果如下:
一般情况下只要没有`红色`的错误即可
注意: 记住地图的命名以及导出路径,后面要用到!
将刚刚生成的Parking_UG_05文件夹整个复制并粘贴到Carla源码下的Import\Package07目录,本案例为:
F:\Carla\carla-0.9.11\Import\Package07
注意: Package07为我自己新建的一个目录,命名可随机(不要有中文)
在该目录下还有package.json文件,没有的话自己新建,其内容如下:
{
"maps": [
{
"name": "Parking_UG_05",
"source": "./Parking_UG_05/Parking_UG_05.fbx",
"use_carla_materials": true,
"xodr": "./Parking_UG_05/Parking_UG_05.xodr"
}
],
"props": [
]
}
大概结构为这样…
注意: name 参数值尽量与导出的地图文件名一致,不然可能导致莫名其妙的错误!(Parking_UG_05)。
下面执行生成地图文件的命令
本案例Carla源码目录为:
F:\Carla\carla-0.9.11
打开自己安装的对应版本的 VS 2019 工具命令提示行。
进入到Carla源码目录,执行以下命令(Package07是我存放地图文件时新建的,记得灵活变更)
cd F:\Carla\carla-0.9.11
make import ARGS="--package Package07 --no-carla-materials"
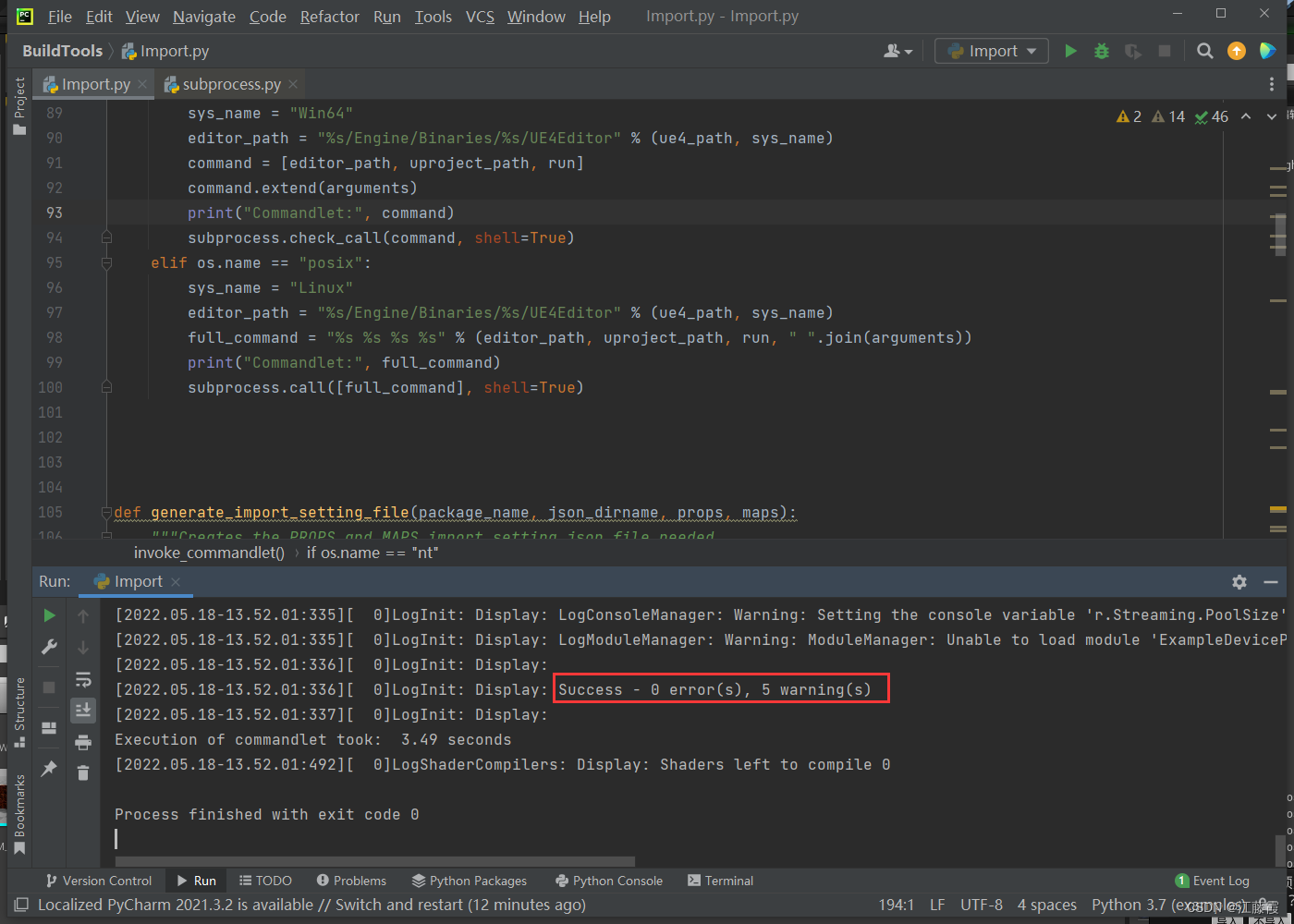
等待PyCharm弹出Import工程后,点击运行按钮
等待程序运行完后会自动结束…
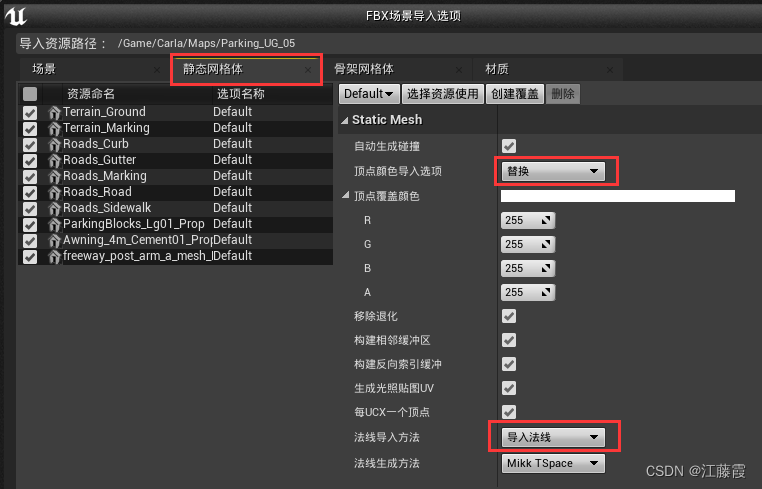
Carla的UE4工程(名称一般为:CarlaUE4.uproject)以启动UE4EditorCarla\Maps目录下新增Parking_UG_05文件夹并进入(如下所示)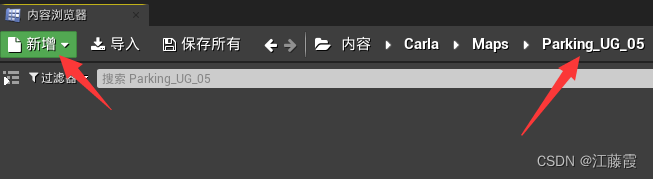
导入,指定刚刚的Import目录(如下)下的地图文件,选中Parking_UG_05.fbx文件F:\Carla\carla-0.9.11\Import\Package07\Parking_UG_05
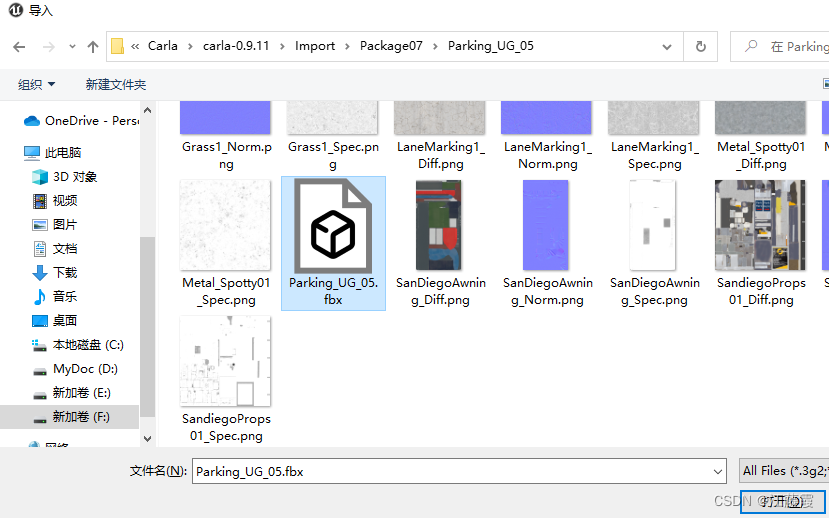
注意事项如下:
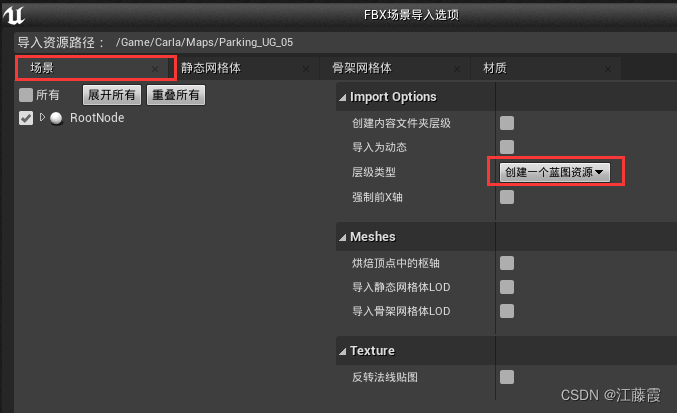
文件 -》 将当前关卡另存为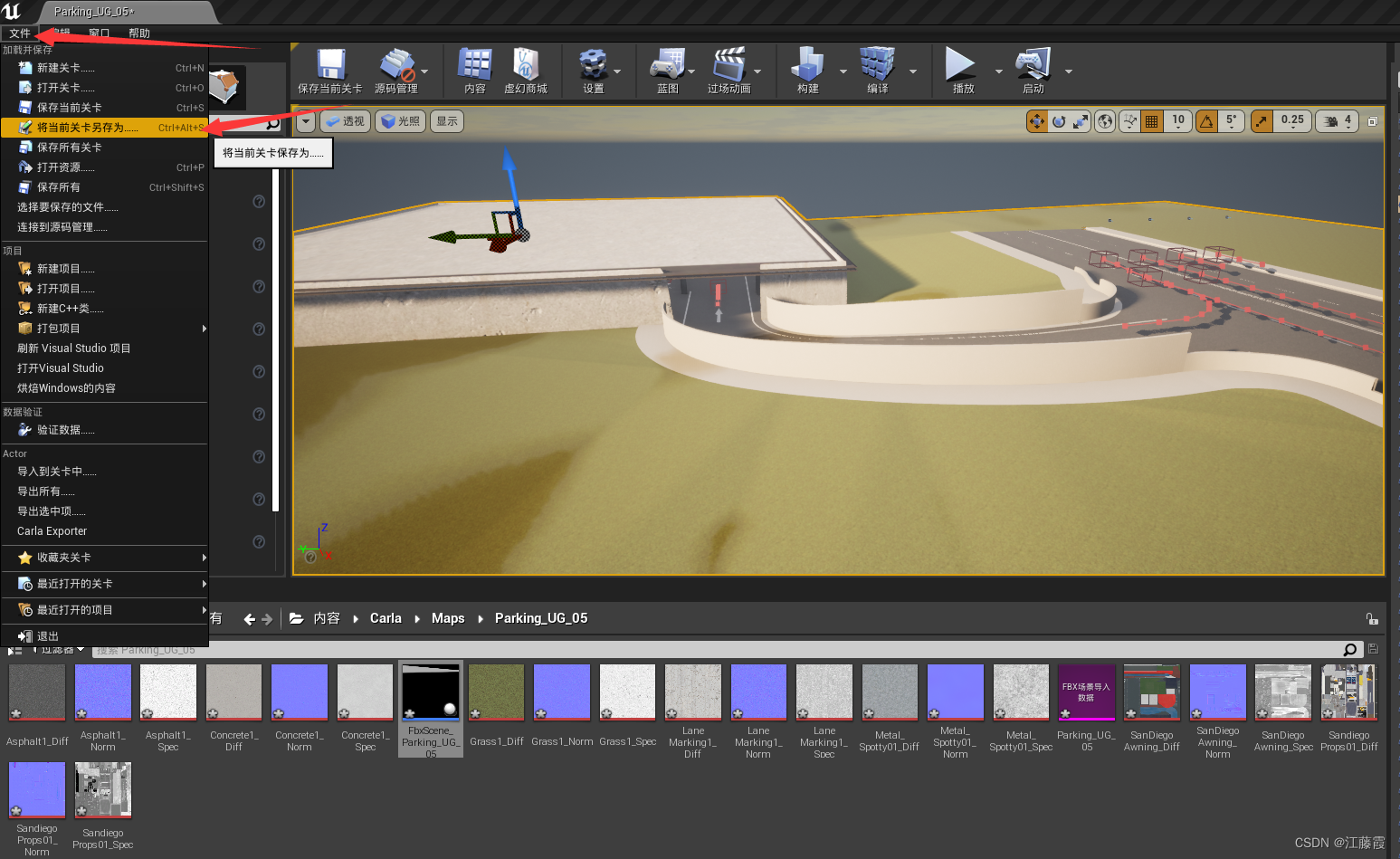
如何检查Ruby文件是否是通过“require”或“load”导入的,而不是简单地从命令行执行的?例如:foo.rb的内容:puts"Hello"bar.rb的内容require'foo'输出:$./foo.rbHello$./bar.rbHello基本上,我想调用bar.rb以不执行puts调用。 最佳答案 将foo.rb改为:if__FILE__==$0puts"Hello"end检查__FILE__-当前ruby文件的名称-与$0-正在运行的脚本的名称。 关于ruby-检查是否
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
我正在尝试创建一个与compass一起使用的本地配置文件,这样我们就可以处理开发人员机器上的不同导入路径。到目前为止,我已经尝试将文件导入到异常block中,以防它不存在,然后进一步使用该变量:local_config.rbVENV_FOLDER='venv'config.rbVENV_FOLDER='.'beginrequire'local_config.rb'rescueLoadErrorendputsVENV_FOLDER通常我是一名Python开发人员,所以我希望导入将VENV_FOLDER的值更改为venv,但它仍然是。之后。有没有一种方法可以导入local_config.r
最好用一个例子来解释:文件1.rb:deffooputs123end文件2.rb:classArequire'file1'endA.new.foo将给出错误“':调用了私有(private)方法'foo'”。我可以通过执行A.new.send("foo")来解决这个问题,但是有没有办法公开导入的方法?编辑:澄清一下,我没有混淆include和require。另外,我不能使用正常包含的原因(正如许多人正确指出的那样)是因为这是元编程设置的一部分。我需要允许用户在运行时添加功能;例如,他可以说“run-this-app--includefile1.rb”,应用程序的行为将根据他在file1
尝试在我的Rails应用程序中导入CSV文件时,出现错误UTF-8中的无效字节序列。一切正常,直到我添加了一个gsub方法来将其中一个CSV列与我的数据库中的一个字段进行比较。当我导入CSV文件时,我想检查每一行的地址是否包含在特定客户端的不同地址数组中。我有一个带有alt_addresses属性的客户端模型,其中包含客户端地址的几种不同可能格式。然后我有一个引用模型(如果您熟悉本地SEO,您就会知道这个术语)。引用模型没有地址字段,但它有一个nap_correct?字段(NAP代表“姓名”、“地址”、“电话号码”)。如果CSV行的名称、地址和电话号码与我在该客户的数据库中拥有的相同,
我在bitbucket上创建了一个私有(private)git存储库并提交了代码。现在我想导出所有(提交、代码、历史记录)并将其导入github上的gitrepo。有没有办法做到这一点?谢谢 最佳答案 在本地检查所有内容到您的计算机和gitpull。创建一个github存储库将此存储库添加为您的第二个远程(“使用gitremote添加githubURL”)推送到第二个Remote 关于ruby-git:从bitbucket导出并导入github(带提交),我们在StackOverflow
这是我的主要rake文件subrake='subrake'task:init=>[subrake]do#callsubrake.buildendimportsubrake我看到有关上述步骤如何工作的文档,但我无法弄清楚如何调用其他subrake文件中的任务。顺便说一句,这些任务可能与我的同名,这是个问题吗? 最佳答案 我想我回答晚了,但几分钟前我也有同样的问题。因此该解决方案可能对某些人有用。Rakefile.rbsubrake='subrake'task:default=>:inittask:init=>["#{subrake}:
我正在尝试向orientdbgem添加一些基本的rake任务,这将允许我创建数据库、创建数据库迁移和迁移数据库——类似于rails迁移。当我在本地执行rake任务时,我可以使用db:settings、db:create和db:create_migration,但是在将它们放入gem之后,我不知道如何从Sinatra访问它们使用“rake”时的应用。我有一种感觉,我要么是a)没有正确地组织gem中的文件和/或b)没有从Sinatra应用程序正确地调用东西。我的fork存储库的当前状态是https://github.com/ricaurte/orientdb-jruby我将任务文件放在li
我目前在尝试测试RubyMine时遇到了不必要的麻烦。我最大的问题是我无法找到一种方法将我系统上的现有Rails应用程序转换为官方RubyMine应用程序,以便我可以体验RubyMine的所有功能。我唯一可用的选项是创建一个新的RubyMinerails项目,从git远程拉取一个rails项目(不起作用),或者打开以前的rails目录(它允许您编辑rails代码,但它无法将此目录识别为RubyMine项目,因此我无法充分利用RubyMine对rails的所有好处)。请帮帮我,RubyMine看起来很有前途顺便说一句,这是RubyMine4。 最佳答案
目标:使用CRON任务(或其他预定事件)更新数据库,每晚从现有系统导出数据。所有数据都是在现有系统中创建/更新/删除的。该网站不直接与该系统集成,因此Rails应用程序只需要反射(reflect)数据导出中出现的更新。我有一个包含约5,000种产品的.txt文件,如下所示:"1234":"productname":"attr1":"attr2":"ABCManufacturing":"2222""A134":"anotherproduct":"attr1":"attr2":"FoobarWorld":"2447"...所有值都是用双引号(")括起来的字符串,用冒号(:)分隔字段是:id