一、引子
对于一个标量场数据,我们可以描绘轮廓(Contouring),包括2D和3D。2D的情况称为轮廓线(contour lines),3D的情况称为表面(surface)。他们都是等值线或等值面。
以下是一个2D例子:
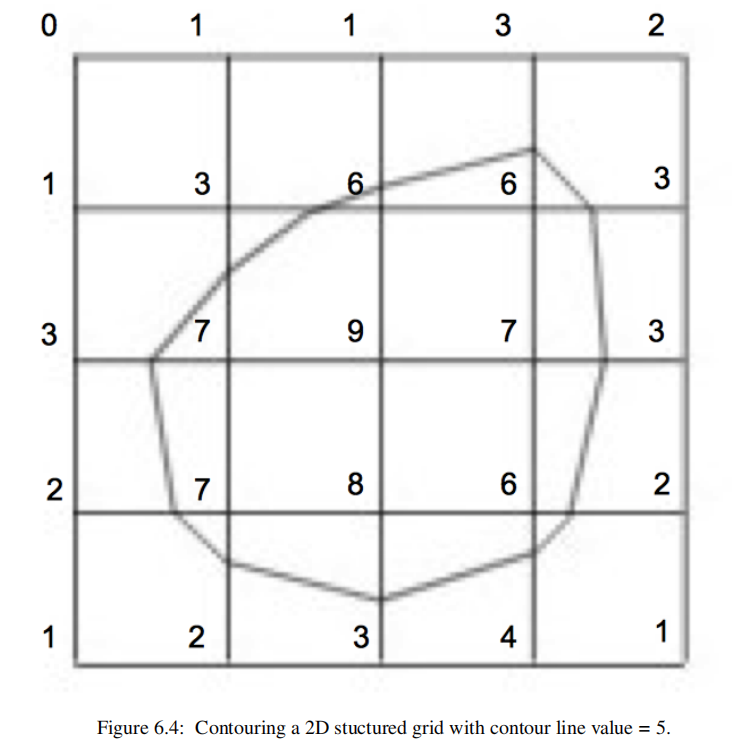
为了生成轮廓,必须使用某种形式的插值。这是因为我们只在数据集中的一个有限点集上有标量值,而我们的等高线值可能位于这两个点的值之间。由于最常见的插值技术是线性插值,我们通过沿边缘的线性插值在轮廓表面上生成点。如果一条边在其两个端点上有标量值10和0,如果我们试图生成一条值为5的等高线,则边缘插值计算该等高线通过边缘的中点。
二、Marching cubes算法——从2D理解
运用了分治思想,对每个单元格(cell)独立地进行处理。该技术的基本假设是,一个轮廓只能以有限数量的方式通过一个单元格。我们可以构造一个案例表(case table),它枚举一个单元的所有可能的拓扑状态(topological state)。拓扑状态的数量取决于单元格顶点的数量,以及一个顶点相对于轮廓值可以具有的内部/外部关系的数量。标量值大于轮廓值的顶点被称为在轮廓之内。标量值小于轮廓值的顶点被称为在轮廓之外。例如,如果一个单元格有四个顶点,并且每个顶点可以在轮廓内部或外部,则有2^4 = 16种可能的方式通过单元格(在实现时可以用bit来实现)。在案例表中,我们不感兴趣的是轮廓通过单元格的位置(例如,geometrical intersection),感兴趣的只是它如何通过单元格(即单元格中轮廓的topology)。
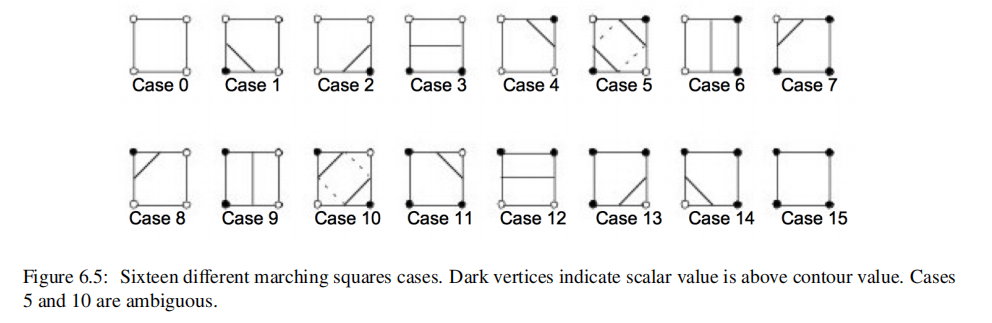
一旦我们选择好属于哪一种case之后,就可以使用插值来计算contour line与cell edge相交的位置。该算法处理一个单元格,然后移动,或行进到下一个单元格。在访问所有单元格后,将完成轮廓。因此称为marching cubes。
算法的步骤如下:
四、算法需要注意的事项
在2D中,轮廓模糊(ambiguos cases,如Fig6.5中的Case 5和Case 10)很容易处理:对于每个模糊的情况,我们选择实现两种可能的情况中的一种。根据选择的不同,轮廓可以延伸或打破当前的轮廓,如Fig 6.9所示。任何一种选择都是可以接受的,因为产生的等高线(contour line)将是连续的和封闭的(或将在数据集(data set)边界结束)。
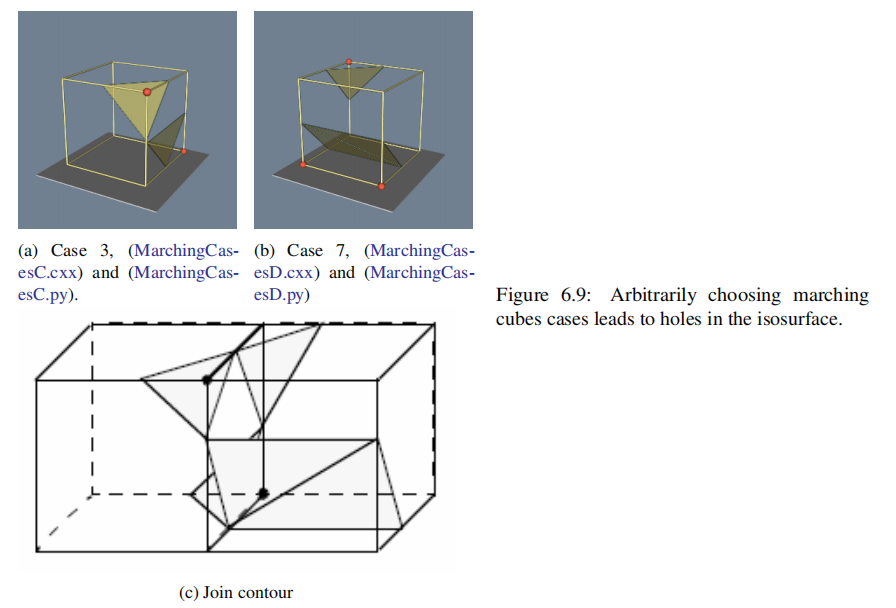
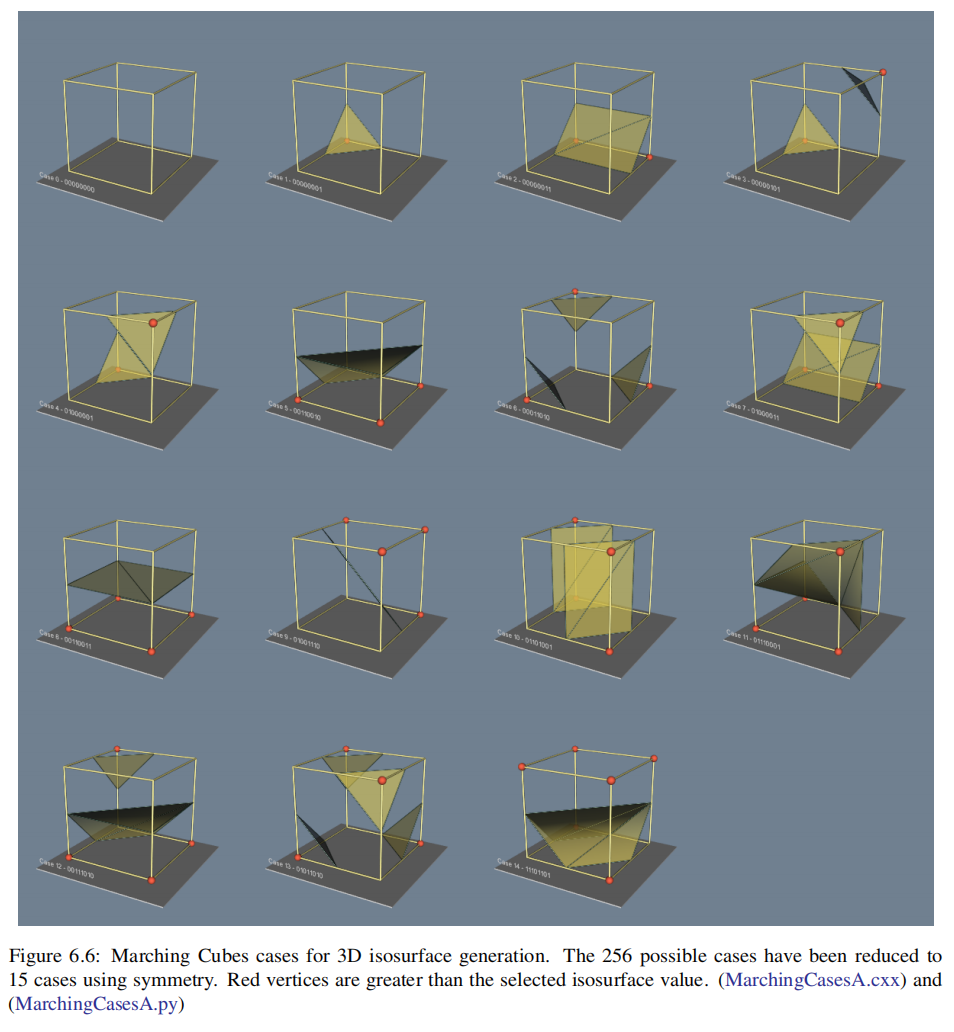
在3D中,这个问题更为复杂。我们不能简单地选择一个独立于所有其他模糊案例的模糊案例。例如,Fig 6.9显示了如果我们不小心实现了两个相互独立的情况,会发生什么。在这个图中,我们使用了通常的情况3,但用它的互补情况替换了情况6。互补的情况是通过将“暗”顶点与“光”顶点交换而形成的。(这相当于将顶点标量值从等值面值以上切换到等值面值以下,反之亦然。)将这两种情况配对的结果是在等值面上留下了一个孔(hole)。
一个简单而有效的解决方案通过添加额外的互补案例(complementary cases),扩展了原来的15个marching cubes案例。这些情况被设计成与邻近的情况兼容,并防止在等值面上产生孔。需要6个互补的情况,分别对应于行进立方体的情况3、6、7、10、12和13。互补的行进立方体案例如Fig 6.10所示。
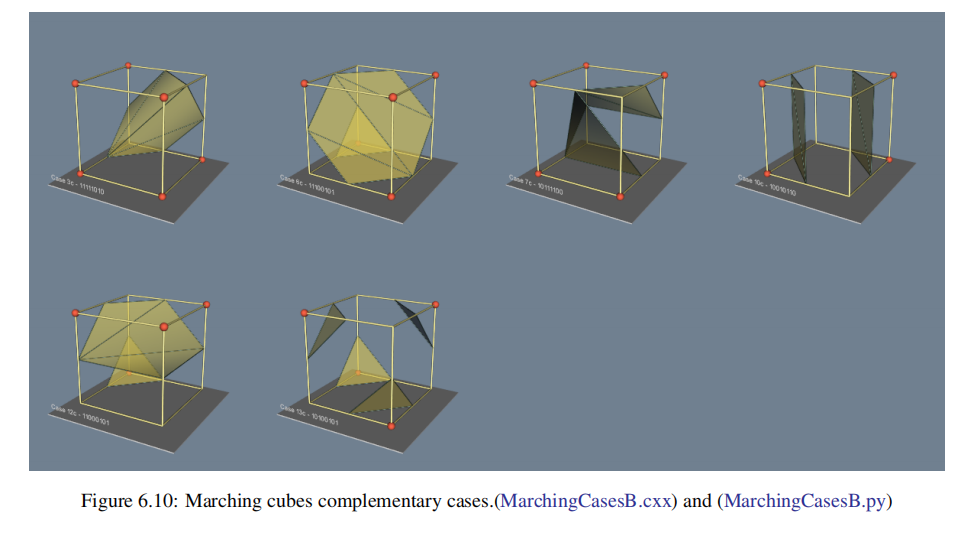
此外,尽管我们说该算法用于规则类型,如四边形和立方体,但marching cubes可以应用于任何拓扑上等同于立方体的单元类型(例如,六面体或非立方体体素)。
五、应用
Fig 6.11d是由marching cubes创建的等值面。图6.11b是一个来自计算机断层扫描(CT)x射线成像系统的恒定图像强度(image intensity)的表面。(图6.11a是该数据的二维子集。)其强度水平对应于人的骨骼。图6.11c为恒定流密度(flow density)的等值面。图6.11d为铁蛋白分子的电子势等值面。由于我们熟悉人体解剖学,图6.11b中所示的图像可以立即被识别出来。然而,对于计算流体动力学和分子生物学领域的从业者来说,图6.11c和图6.11d同样熟悉。正如这些例子所显示的,轮廓形成的方法是各领域可视化数据的强大而又通用的技术。

参考文档:VTKTextBook Scalar Algorithms
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
我一直在尝试用Ruby实现Luhn算法。我一直在执行以下步骤:该公式根据其包含的校验位验证数字,该校验位通常附加到部分帐号以生成完整帐号。此帐号必须通过以下测试:从最右边的校验位开始向左移动,每第二个数字的值加倍。将乘积的数字(例如,10=1+0=1、14=1+4=5)与原始数字的未加倍数字相加。如果总模10等于0(如果总和以零结尾),则根据Luhn公式该数字有效;否则无效。http://en.wikipedia.org/wiki/Luhn_algorithm这是我想出的:defvalidCreditCard(cardNumber)sum=0nums=cardNumber.to_s.s
下面是我写的一个计算斐波那契数列中的值的方法:deffib(n)ifn==0return0endifn==1return1endifn>=2returnfib(n-1)+(fib(n-2))endend它工作到n=14,但在那之后我收到一条消息说程序响应时间太长(我正在使用repl.it)。有人知道为什么会这样吗? 最佳答案 Naivefibonacci进行了大量的重复计算-在fib(14)fib(4)中计算了很多次。您可以将内存添加到您的算法中以使其更快:deffib(n,memo={})ifn==0||n==1returnnen
为了防止在迁移到生产站点期间出现数据库事务错误,我们遵循了https://github.com/LendingHome/zero_downtime_migrations中列出的建议。(具体由https://robots.thoughtbot.com/how-to-create-postgres-indexes-concurrently-in概述),但在特别大的表上创建索引期间,即使是索引创建的“并发”方法也会锁定表并导致该表上的任何ActiveRecord创建或更新导致各自的事务失败有PG::InFailedSqlTransaction异常。下面是我们运行Rails4.2(使用Acti
我正在开发一个类似微论坛的项目,其中一个特殊用户发布一条快速(接近推文大小)的主题消息,订阅者可以用他们自己的类似大小的消息来响应。直截了当,没有任何形式的“挖掘”或投票,只是每个主题消息的响应按时间顺序排列。但预计会有很高的流量。我们想根据它们引起的响应嗡嗡声来标记主题消息,使用0到10的等级。在谷歌上搜索了一段时间的趋势算法和开源社区应用示例,到目前为止已经收集到两个有趣的引用资料,但我还没有完全理解它们:Understandingalgorithmsformeasuringtrends,关于使用基线趋势算法比较维基百科页面浏览量的讨论,在SO上。TheBritneySpearsP
我收到错误:unsupportedcipheralgorithm(AES-256-GCM)(RuntimeError)但我似乎具备所有要求:ruby版本:$ruby--versionruby2.1.2p95OpenSSL会列出gcm:$opensslenc-help2>&1|grepgcm-aes-128-ecb-aes-128-gcm-aes-128-ofb-aes-192-ecb-aes-192-gcm-aes-192-ofb-aes-256-ecb-aes-256-gcm-aes-256-ofbRuby解释器:$irb2.1.2:001>require'openssl';puts
文章目录一.Dijkstra算法想解决的问题二.Dijkstra算法理论三.java代码实现一.Dijkstra算法想解决的问题解决的问题:求解单源最短路径,即各个节点到达源点的最短路径或权值考察其他所有节点到源点的最短路径和长度局限性:无法解决权值为负数的情况二.Dijkstra算法理论参数:S记录当前已经处理过的源点到最短节点U记录还未处理的节点dist[]记录各个节点到起始节点的最短权值path[]记录各个节点的上一级节点(用来联系该节点到起始节点的路径)Dijkstra算法步骤:(1)初始化:顶点集S:节点A到自已的最短路径长度为0。只包含源点,即S={A}顶点集U:包含除A外的其他顶
对于体育新闻中文文本的关键字提取,常用的算法包括TF-IDF、TextRank和LDA等。它们的基本步骤如下:1.TF-IDF算法: -将文本进行分词和词性标注处理。-统计每个词在文本中的词频(TF)。-计算每个词在整个语料库中出现的文档频率(DF)和逆文档频率(IDF)。-计算每个词的TF-IDF值,并按照值的大小进行排序,选择排名前几的词作为关键字。2.TextRank算法:-将文本进行分词和词性标注处理。-将分词结果转化成图模型,每个词语为节点,根据词语之间的共现关系建立边。-对图模型进行迭代计算,计算每个节点的PageRank值,表示该节点的重要性。-选择排名前几的节点作为关键字。3.
我正在尝试计算由二进制形式的1和0的P数表示的数字的数量。如果P=2,则表示的数字为0011、1100、0110、0101、1001、1010,所以计数为6。我试过:[0,0,1,1].permutation.to_a.uniq但这不是大数的最佳解决方案(P可以什么可能是最好的排列技术,或者我们是否有任何直接的数学来做到这一点? 最佳答案 Numberofpermutationcanbecalculatedusingfactorial.a=[0,0,1,1](1..a.size).inject(:*)#=>4!=>24要计算重复项,