本文的参考资料为官方文档AMBA™3 APB Protocol specification
文档下载地址: https://pan.baidu.com/s/1Vsj4RdyCLan6jE-quAsEuw?pwd=w5bi
提取码:w5bi
介绍总线具体握手规则之前,需要先熟悉一下APB总线端口,APB的端口如下:

大体可以分为以下三组:
系统信号:PCLK(系统时钟)、PRESETn(系统复位,低有效)
master信号:PADDR(地址信号,确定读写的地址)、PSELx(片选信号,拉出来接给搭载APB总线的slave,选中slave时,PSELx信号拉高)、PNEABLE(使能信号,在PSELx拉高一个周期后,必定拉高)、PWRITE(写使能信号,PWRITE为高时写有效,为低时读有效)、PWDATA(写数据)
slave信号:PREADY(ready为高时,代表着一次APB数据传输的结束)、PRDATA(读数据)、PSLVERR(错误数据,由slave发出,具体逻辑由slave内部决定,当slave发现内部逻辑出现故障,譬如状态机状态出错、计数器数字异常等,slave都可以使用内部逻辑把该信号拉高,使得master接收到PSLVERR为高时,哪怕ready拉高表示APB结束了,也可以使master放弃该次传输或做出其他应对策略)。

如文档所示,APB的写分为两种情况:①没有等待状态的写;②有等待状态的写。
APB和AHB最大的不同就是APB不采用pipeline形式的写读方式,因此对于APB协议来说,最快的写入或者读出一个数据的周期是两周期,先给地址,再写数据;或者先给地址,再读数据。APB 协议文档中,将上述这种传输方式分为两个阶段(phase),给地址的阶段称为Set up phase;紧接着下一周期PENABLE信号拉高,标志着进入写/读数据的阶段,该阶段称为Access phase。
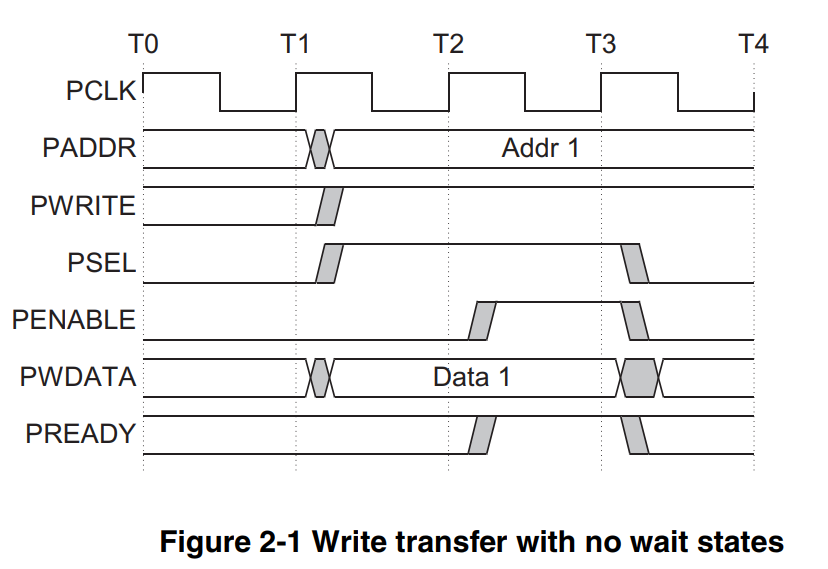
一次没有等待状态的写传输如上图所示,计划写数据时,第一周期PSEL拉高,表示选中某个slave,同时给出地址信息Addr1和写入数据信息Data1,紧接着下一周期,PENABLE信号拉高,PREADY信号也拉高,这时数据写入完成。

没有等待状态的APB连续写波形如上所示(代码见后文),笔者将数据分为了两组,group1为APB slave的端口信号,group2为APB接的单端口SRAM信号。在第一个周期,也就是Setup phase,psel信号拉高,表示slave被选中,值得注意的是此时要将SRAM的写信号和使能信号同步拉高,因为我们写的是一个no wait states的APB接口,数据要在第二周期写进SRAM的话,就需要提前一拍拉高使能信号和写信号。然后到了第二周期,penable信号拉高,pready信号也拉高标志着这一次APB传输的结束。另外,也正是因为在setup phase我们把SRAM的en信号和we信号拉高了,因此在access phase数据传输结束的同时,数据也被写入到SRAM中。
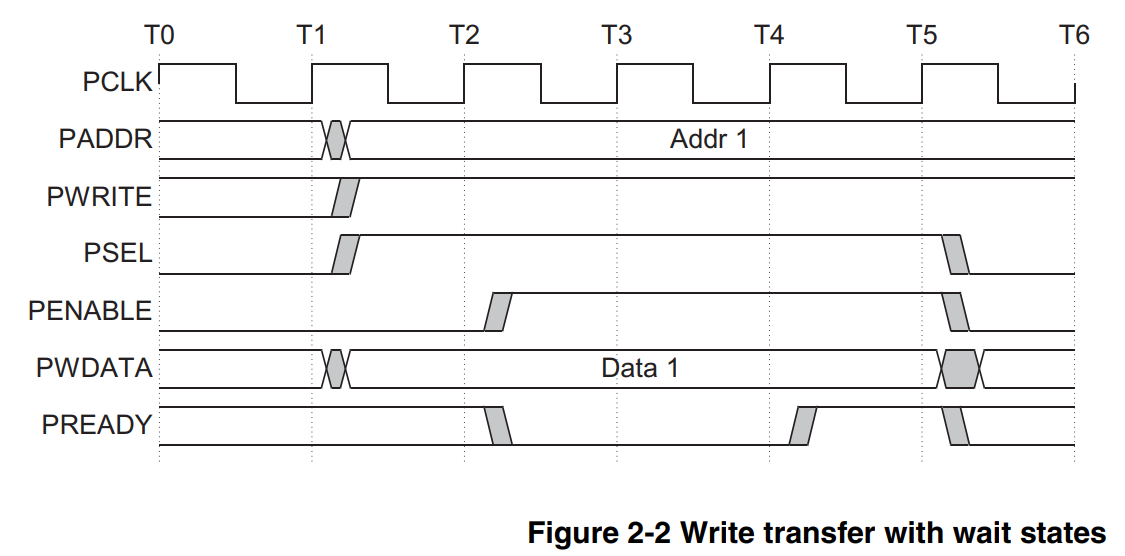

在文档中,对有等待周期的APB写传输描述如上,即:
一开始的setup phase和write with no wait没有区别,psel拉高,penable为低;紧跟着第二周期,penable拉高之后,进入access phase,进入access phase之后,penable不会拉低,直到pready为高标志着一次传输结束时,penable才会随着pready一起拉低。penable等待pready拉高的这段等待时间为additional cycles,在这个阶段PADDR、PWRITE、PSEL、PENABLE、PWDATA都应该保持不变,可以说总线被hold住了。

APB的读传输也分为两种情况:①没有等待状态的读;②有等待状态的读。
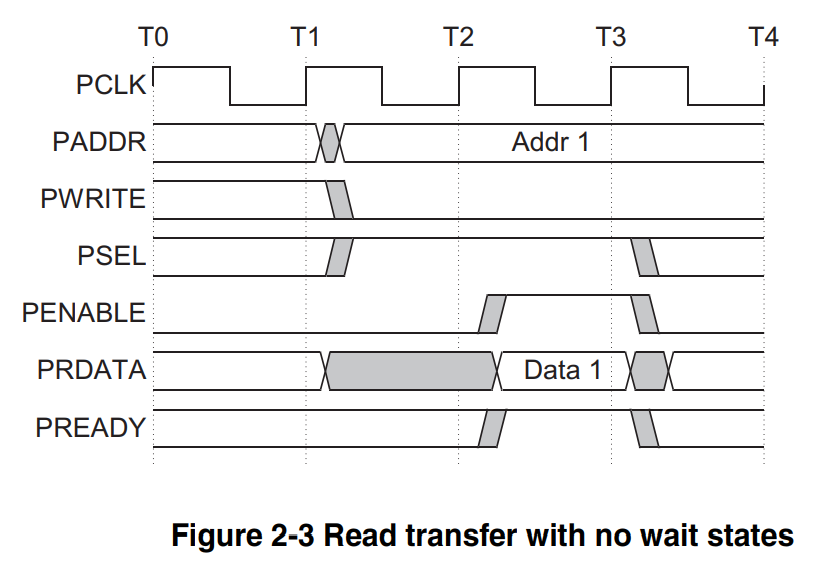
一次没有等待状态的读传输如上图所示,读状态和写状态不同,写数据时PWRITE=1,读数据时应该令PWRITE=0计划读数据时,第一周期PSEL拉高,表示选中某个slave,同时给出地址信息Addr1,紧接着下一周期,PENABLE信号拉高,PREADY信号也拉高,这时数据被读出,master接受到读出数据PRDATA。
上图为连续读的APB传输波形图,从第一次读数据可以看到,随着psel信号拉高,PWRITE=0标志着为读状态,此时传入地址给APB的SRAM,SRAM端口en=1,we=0标志着SRAM为读模式,数据在下一周期从SRAM给到prdata。
这边还要提一个APB的特点,也是大多人容易忽略的点,APB总线完成一次读传输或者写传输之后,PADDR和PWRITE不会改变,会一直维持到下一次的传输,这可以减少功耗。spec中描述如下:

笔者写了一个Write和Read都是with no states的APB SRAM,因为含有SRAM部分,所以在apb_sram中需要例化一个单端口ram,单端口ram代码如下:
module spram_generic#(
parameter ADDR_BITS = 7, //outside input 10
parameter ADDR_AMOUNT = 128, //outside input 1024
parameter DATA_BITS = 32 //outside input 32
)(
input clk ,
input en ,
input we ,
input [ADDR_BITS-1:0] addr ,
input [DATA_BITS-1:0] din ,
output reg [DATA_BITS-1:0] dout
);
reg [DATA_BITS-1:0] mem [0:ADDR_AMOUNT-1];
always @(posedge clk)begin
if(en)begin
if(we == 1'b1)begin
mem[addr] <= din;
end
else
dout <= mem[addr];
end
end
endmodulemodule apb_sram#(
parameter ADDR_BITS = 9,
parameter DATA_BITS = 32,
parameter MEM_DEPTH = 512
)(
input pclk ,
input prstn ,
input psel ,
input penable ,
input [ADDR_BITS-1:0] paddr ,
input pwrite ,
input [DATA_BITS-1:0] pwdata ,
output pready ,
output [DATA_BITS-1:0] prdata
);
// write part
wire apb_write_setup;
reg apb_ram_write;
assign apb_write_setup = (pwrite) && (!penable) && (psel);
always @(posedge pclk or negedge prstn)begin
if(!prstn)begin
apb_ram_write <= 1'b0;
end
else if(apb_write_setup)begin
apb_ram_write <= 1'b1;
end
else if(pready)begin
apb_ram_write <= 1'b0;
end
end
// read part
wire apb_read_setup;
reg apb_ram_read;
assign apb_read_setup = (!pwrite) && (!penable) && (psel);
always @(posedge pclk or negedge prstn)begin
if(!prstn)begin
apb_ram_read <= 1'b0;
end
else if(apb_read_setup)begin
apb_ram_read <= 1'b1;
end
else if(pready)begin
apb_ram_read <= 1'b0;
end
end
assign pready = pwrite ? apb_ram_write : apb_ram_read;
wire mem_en,mem_we;
assign mem_en = apb_write_setup || apb_read_setup;
assign mem_we = apb_write_setup;
spram_generic #(
.ADDR_BITS (ADDR_BITS ),
.DATA_BITS (DATA_BITS ),
.ADDR_AMOUNT (2<<(ADDR_BITS-1) )
)u_spram_generic(
.clk (pclk ),
.en (mem_en ),
.we (mem_we ),
.addr (paddr ),
.din (pwdata ),
.dout (prdata )
);
endmoduletestbench例化apb_sram并给出激励,我这边在tb中发起了10次连续的随机写,然后再发起10次连续读,发现读出来的数据和写入的数据一致。
接着又测试了写和读无缝衔接在一起的apb传输,结果符合spec。tb代码如下:
`timescale 1ns/1ns
`define MEM_PATH u_apb_sram.u_spram_generic
module tb#(
parameter ADDR_BITS = 9,
parameter DATA_BITS = 32,
parameter MEM_DEPTH = 512
)();
reg clk, rstn;
always #5 clk = ~clk;
reg psel, penable, pwrite;
reg [DATA_BITS-1:0] pwdata, ref_data;
reg [ADDR_BITS-1:0] paddr ;
wire pready;
wire [DATA_BITS-1:0] prdata;
reg [DATA_BITS-1:0] pwdata_rand;
reg [DATA_BITS-1:0] prdata_read;
task apb_write;
input [ADDR_BITS-1:0] addr;
input [DATA_BITS-1:0] wdata;
begin
@(posedge clk);#1;
penable = 0; psel = 1; pwrite = 1; paddr = addr; pwdata = wdata;
@(posedge clk);#1;
penable = 1;
end
endtask
task apb_read;
input [ADDR_BITS-1:0] addr;
output [DATA_BITS-1:0] rdata;
begin
@(posedge clk); #1;
penable = 0; psel = 1; pwrite = 0; paddr = addr;
@(posedge clk); #1;
penable = 1;
@(negedge clk); #1;
rdata = prdata;
end
endtask
integer i,j;
initial begin
clk <= 1'b0;
rstn <= 1'b0;
pwrite <= 1'b1;
psel <= 1'b0;
penable <= 1'b0;
pwdata <= 32'd0;
repeat(2) @(posedge clk);
rstn <= 1'b1;
repeat(3) @(posedge clk);
// SRAM data initial
for (i = 0; i < MEM_DEPTH; i = i + 1)begin
pwdata = $random();
`MEM_PATH.mem[i] = pwdata;
end
repeat(5) @(posedge clk); #1;
$display("\ncontinuous writing");
// SRAM data continuous writing
fork
begin
@(posedge clk);#1
paddr = 32'd0;
for (j = 0; j < 10; j = j + 1)begin
repeat(2) @(posedge clk) #1;
paddr = paddr + 1;
@(negedge clk) #1;
ref_data = `MEM_PATH.mem[paddr-1];
$display("ref_data = %d, addr = %d", ref_data, paddr-1);
end
end
begin
for (i = 0; i < 10; i = i + 1)begin
pwdata_rand = $random();
apb_write(paddr, pwdata_rand);
$display("pwdata = %d", pwdata);
end
end
join_none
repeat(21) @(posedge clk);#1;
penable = 1'b0;psel = 1'b0;pwrite = 1'b0;
repeat(5) @(posedge clk);#1;
$display("\ncontinuous reading");
//SRAM continuous reading
fork
begin
@(posedge clk);#1;
paddr = 32'd0;
for (j = 0; j < 10; j = j + 1)begin
repeat(2) @(posedge clk);#1;
paddr = paddr + 1;
end
end
begin
for (i = 0; i < 10; i = i + 1)begin
apb_read(paddr, prdata_read);
$display("prdata_read = %d", prdata_read);
end
end
join
penable = 0;psel = 0;
repeat(5) @(posedge clk);#1;
$display("\ncontinuos writing and reading");
//SRAM continuous write and read
fork
begin
@(posedge clk);#1;
paddr = 32'd0;
for (j = 0; j < 10; j = j + 1)begin
repeat (4) @(posedge clk); #1;
paddr = paddr + 1;
end
end
begin
for (i = 0; i < 10; i = i + 1)begin
pwdata_rand = $random();
apb_write(paddr, pwdata_rand);
apb_read(paddr, prdata_read);
$display("write data is %d, read data is %d", pwdata_rand, prdata_read);
end
end
join
penable = 0;psel = 0;
// finish simulation
repeat(20) @(posedge clk);
$finish();
end
initial begin
$fsdbDumpfile("apb_sram.fsdb");
$fsdbDumpvars(0);
end
apb_sram #(
.ADDR_BITS(ADDR_BITS),
.DATA_BITS(DATA_BITS),
.MEM_DEPTH(MEM_DEPTH)
) u_apb_sram(
.pclk (clk ),
.prstn (rstn ),
.psel (psel ),
.penable(penable),
.paddr (paddr ),
.pwrite (pwrite ),
.pwdata (pwdata ),
.pready (pready ),
.prdata (prdata )
);
endmodulevcs仿真结果如下:
continuous writing
pwdata = 620927818
ref_data = 620927818, addr = 0
pwdata = 1557269945
ref_data = 1557269945, addr = 1
pwdata = 160312595
ref_data = 160312595, addr = 2
pwdata = 164115731
ref_data = 164115731, addr = 3
pwdata = 853295461
ref_data = 853295461, addr = 4
pwdata = 684074833
ref_data = 684074833, addr = 5
pwdata = 3684186807
ref_data = 3684186807, addr = 6
pwdata = 3432517785
ref_data = 3432517785, addr = 7
pwdata = 2635204666
ref_data = 2635204666, addr = 8
pwdata = 3102358129
ref_data = 3102358129, addr = 9
continuous reading
prdata_read = 620927818
prdata_read = 1557269945
prdata_read = 160312595
prdata_read = 164115731
prdata_read = 853295461
prdata_read = 684074833
prdata_read = 3684186807
prdata_read = 3432517785
prdata_read = 2635204666
prdata_read = 3102358129
continuos writing and reading
write data is 830211938, read data is 830211938
write data is 4063587044, read data is 4063587044
write data is 353623338, read data is 353623338
write data is 3201975421, read data is 3201975421
write data is 753819481, read data is 753819481
write data is 1925424101, read data is 1925424101
write data is 1994288109, read data is 1994288109
write data is 3836215497, read data is 3836215497
write data is 2695810113, read data is 2695810113
write data is 1472319919, read data is 1472319919
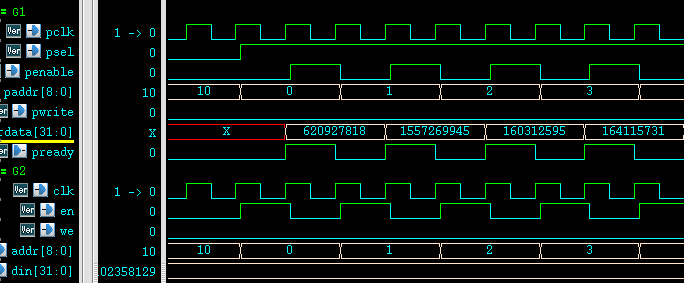
连续10次写、连续10次读、连续10次读写波形如下

如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
文章目录git常用命令(简介,详细参数往下看)Git提交代码步骤gitpullgitstatusgitaddgitcommitgitpushgit代码冲突合并问题方法一:放弃本地代码方法二:合并代码常用命令以及详细参数gitadd将文件添加到仓库:gitdiff比较文件异同gitlog查看历史记录gitreset代码回滚版本库相关操作远程仓库相关操作分支相关操作创建分支查看分支:gitbranch合并分支:gitmerge删除分支:gitbranch-ddev查看分支合并图:gitlog–graph–pretty=oneline–abbrev-commit撤消某次提交git用户名密码相关配置g
打印1:defsum(i)i=i+[2]end$x=[1]sum($x)print$x打印12:defsum(i)i.push(2)end$x=[1]sum($x)print$x后者是修改全局变量$x。为什么它在第二个例子中被修改而不是在第一个例子中?类Array的任何方法(不仅是push)都会发生这种情况吗? 最佳答案 变量范围在这里无关紧要。在第一段代码中,您仅使用赋值运算符=为变量i赋值,而在第二段代码中,您正在修改$x(也称为i)使用破坏性方法push。赋值从不修改任何对象。它只是提供一个名称来引用一个对象。方法要么是破坏性