写这些博客的原因,是因为打算好好研究一下点云的各种库的源码,其中比较知名的是PCL(point cloud library)和CC(CloudCompare)。
读源码的时候也没有什么头绪,所以看到哪里就写到哪里,算是随兴之作吧!因为不追求严格的逻辑的代码回溯,所以错误不足之处在所难免。回想起当年学网络编程,也是先一头扎进去,总结一番再说。至于总结得比较到位的结论,往往要等到对框架有一个大体的了解熟悉之后才行。
从哪里开始呢?这里从最基本最简单的PLY文件读取开始吧。
PLY是Polygon的意思,是以多边形的方式保存了空间点位信息。Mesh的格式非常多,如果想了解的话,可以参考这里,
Data Formats: 3D, Audio, Image
具体到PLY格式,可以参考这里,
下面我们言归正传。
首先,我随便找一个3D建模软件,画了一个圆柱体,然后保存为ply格式,用CC打开读取其内容,形成mesh网格。
因为格式对应的功能较多,所以作者定义了一系列的读取函数,函数格式定义如下,
/* ----------------------------------------------------------------------
* Input/output driver
*
* Depending on file mode, different functions are used to read/write
* property fields. The drivers make it transparent to read/write in ascii,
* big endian or little endian cases.
* ---------------------------------------------------------------------- */
typedef int (*p_ply_ihandler)(p_ply ply, double *value);
typedef int (*p_ply_ichunk)(p_ply ply, void *anydata, size_t size);
typedef struct t_ply_idriver_ {
p_ply_ihandler ihandler[16];
p_ply_ichunk ichunk;
const char *name;
} t_ply_idriver;
typedef t_ply_idriver *p_ply_idriver;
typedef int (*p_ply_ohandler)(p_ply ply, double value);
typedef int (*p_ply_ochunk)(p_ply ply, void *anydata, size_t size);
typedef struct t_ply_odriver_ {
p_ply_ohandler ohandler[16];
p_ply_ochunk ochunk;
const char *name;
} t_ply_odriver;
typedef t_ply_odriver *p_ply_odriver;其中i表示读入,o表示读出。
比如说,读取一个格式是32位的float(所以这里取名float32),函数定义是这样的,
static int ibinary_float32(p_ply ply, double *value) {
float float32;
if (!ply->idriver->ichunk(ply, &float32, sizeof(float32))) return 0;
*value = float32;
return 1;
}然后,在driver中把该函数的指针传递进去,如下所示,其中ply_idriver_ascii表示读取ascii字符,ply_idriver_binary表示读取二进制码,
/* ----------------------------------------------------------------------
* Constants
* ---------------------------------------------------------------------- */
static t_ply_idriver ply_idriver_ascii = {
{ iascii_int8, iascii_uint8, iascii_int16, iascii_uint16,
iascii_int32, iascii_uint32, iascii_float32, iascii_float64,
iascii_int8, iascii_uint8, iascii_int16, iascii_uint16,
iascii_int32, iascii_uint32, iascii_float32, iascii_float64
}, /* order matches e_ply_type enum */
NULL,
"ascii input"
};
static t_ply_idriver ply_idriver_binary = {
{ ibinary_int8, ibinary_uint8, ibinary_int16, ibinary_uint16,
ibinary_int32, ibinary_uint32, ibinary_float32, ibinary_float64,
ibinary_int8, ibinary_uint8, ibinary_int16, ibinary_uint16,
ibinary_int32, ibinary_uint32, ibinary_float32, ibinary_float64
}, /* order matches e_ply_type enum */
ply_read_chunk,
"binary input"
};注意这里的16个p_ply_ihandler分别对应了16种相关格式,如下,
/* ply data type */
typedef enum e_ply_type {
PLY_INT8, PLY_UINT8, PLY_INT16, PLY_UINT16,
PLY_INT32, PLY_UIN32, PLY_FLOAT32, PLY_FLOAT64,
PLY_CHAR, PLY_UCHAR, PLY_SHORT, PLY_USHORT,
PLY_INT, PLY_UINT, PLY_FLOAT, PLY_DOUBLE,
PLY_LIST /* has to be the last in enum */
} e_ply_type; /* order matches ply_type_list */所以在后面的ply_read_scalar_property等函数中,只需要取相应的序号即可得到相应的处理函数,
p_ply_ihandler handler = driver[property->type];这样准备好后,后面就可以读取文件了。
以我的圆柱体文件为例,内容是这样的,
ply
format binary_little_endian 1.0
comment SOLIDWORKS generated,length unit = 毫米
element vertex 80
property float x
property float y
property float z
element face 152
property uchar red
property uchar green
property uchar blue
property uchar alpha
property list uchar int vertex_indices
end_header读取文件的主体函数是loadFile,这个函数比较长,全面负责管理读取工作。
下面我们来慢慢介绍。
读取文件的过程是这样的,
ply->fp = fp;首先,ply_read_header读取前面的文件头的信息,一直读取到“end_header”字符串。在ply_read_header读取完之后, LoadFile分析读取的文件头信息,设置ply的相关参数,比如little-endian,是否是PLY_LIST/PLY_FLOAT格式,有没有face等。
同时,根据文件头的信息,这里会设置一些回调函数。例如,在ply_read_header中,通过 ply_read_header_format设置了相关的回调函数。例如我这里是binary格式,little-endian,其中的处理函数就是前面定义的
ply->idriver = &ply_idriver_binary;
如果是big-endian的话,处理函数就是
ply_idriver_binary_reverse
根据前面的文件,弹出对话框,
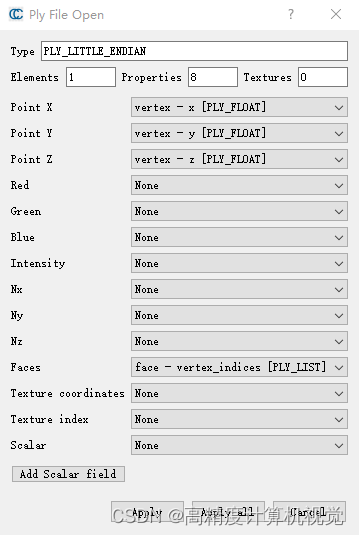
因为我的这个文件里并没有保存normals信息,所以这里直接跳过。
这里,通过ply_set_read_cb设置了读取回调函数 face_cb。
读取函数是ply_read,
//ref. PlyFilter.cpp, LoadFile
success = ply_read(ply);
//ref. rply.c, ply_read
int ply_read(p_ply ply) {
long i;
p_ply_argument argument;
assert(ply && ply->fp && ply->io_mode == PLY_READ);
argument = &ply->argument;
/* for each element type */
for (i = 0; i < ply->nelements; i++) {
p_ply_element element = &ply->element[i];
argument->element = element;
if (!ply_read_element(ply, element, argument))
return 0;
}
return 1;
}函数会根据element的类型来进行回调,比如是vertices,就调用前面传入的vertices_cb;如果是faces,就调用face_cb。
对于顶点信息,比如我这里有80个vertex,在ply_read_element中会逐个循环读取。
读取的线路是这样的,如果是PLY_FLOAT,
ply_read_element ----> ply_read_property ----> ply_read_scalar_property ----> ibinary_float32
如果是PLY_LIST,
ply_read_element ----> ply_read_property ----> ply_read_list_property ----> ibinary_float32
在发现有X,Y, Z坐标时,会设置相应的顶点读取回调函数,
ply_set_read_cb(ply, pointElements[pp.elemIndex].elementName, pp.propName, vertex_cb, cloud, flags);具体顶点的读取,可以参考后面的说明。
对于面的数据,非常类似,也是通过ply_read_element这个函数实现循环读取的,
static int ply_read_element(p_ply ply, p_ply_element element,
...在读取的时候,先通过
ply_read_element ----> ply_read_property ----> ply_read_scalar_property ----> ibinary_int32
读取下面的5个参数,占5个字节,
property uchar red
property uchar green
property uchar blue
property uchar alpha
property list uchar int vertex_indices然后,对于后面的PLY_LIST格式,通过
ply_read_element ----> ply_read_property ----> ply_read_list_property ----> read_cb(face_cb), ibinary_int32,etc.
一次读取4个字节,逐个数据地读取;读取后通过
//ref. PlyFilter.cpp, face_cb
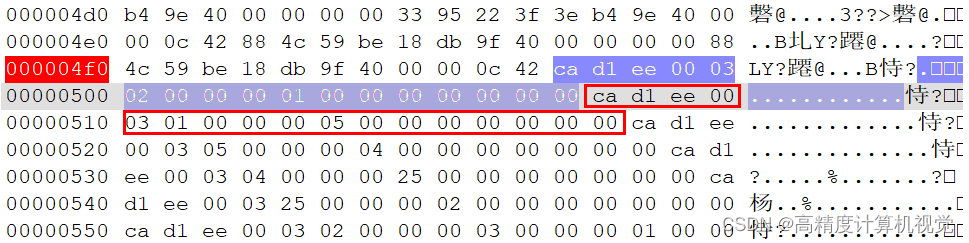
mesh->addTriangle(s_tri[0], s_tri[1], s_tri[2]);添加到ccMesh结构中去。如下图所示,对于前5个字节,ca d1 ee 00 03,分别表示前面的5个属性参数,最后的3表示后续有3个32位的数据;后面的3个32位的数据(2, 1, 0)表示三个顶点的序号。依次循环读取faces的信息。
读取的时候,不管是何种方式何种数据,最后都通过ply_read_chunk实现
static int ply_read_chunk(p_ply ply, void *anybuffer, size_t size) {
char *buffer = (char *) anybuffer;
size_t i = 0;
assert(ply && ply->fp && ply->io_mode == PLY_READ);
assert(ply->buffer_first <= ply->buffer_last);
while (i < size) {
if (ply->buffer_first < ply->buffer_last) {
buffer[i] = ply->buffer[ply->buffer_first];
ply->buffer_first++;
i++;
} else {
ply->buffer_first = 0;
ply->buffer_last = fread(ply->buffer, 1, BUFFERSIZE, ply->fp);
if (ply->buffer_last <= 0) return 0;
}
}
return 1;
}读取的时候都是逐个字节的,感觉这是作者为了统一读取方式故意这么做的。
最后读取完毕,数据根据种类(vertices,faces, etc.)的不同,数据的地址在ply->ply_element->ply_property->pdata指针保存,如果是vertices,这个数据的管理类就是ccPointCloud;如果是faces,这个数据的管理类就是ccMesh。
cloud这些顶点信息,最后也会加入到mesh里,
//ref. PlyFilter.cpp, LoadFile
mesh->addChild(cloud);mesh本身也是一个ccHObject,所以实际上就是放在m_children中,
class QCC_DB_LIB_API ccHObject : public ccObject, public ccDrawableObject
{
public: //construction
......
//! Standard instances container (for children, etc.)
using Container = std::vector<ccHObject *>;
......
//! Children
Container m_children;
......
}最后, 当一切结束的时候,这个mesh被加入到container中,
// ref. PlyFilter.cpp, loadFile
CC_FILE_ERROR PlyFilter::loadFile(const QString& filename, const QString& inputTextureFilename, ccHObject& container, LoadParameters& parameters)
{
......
container.addChild(mesh);
......
}读取完后, 最后通过ply_close(ply)关闭文件。
顶点数据保存在一个叫做ccPointCloud的结构体里。在PlyFilter.cpp中,当loadFile在读文件的时候,创建了这个结构体,
/*************************/
/*** Callbacks setup ***/
/*************************/
//Main point cloud
ccPointCloud* cloud = new ccPointCloud("unnamed - Cloud");随即这个顶点通过传递给property->pdata指针,
ply_set_read_cb(ply, pointElements[pp.elemIndex].elementName, pp.propName, vertex_cb, cloud, flags);\
//ref.rply.c
long ply_set_read_cb(p_ply ply, const char *element_name,
const char* property_name, p_ply_read_cb read_cb,
void *pdata, long idata) {
p_ply_element element = NULL;
p_ply_property property = NULL;
assert(ply && element_name && property_name);
element = ply_find_element(ply, element_name);
if (!element) return 0;
property = ply_find_property(element, property_name);
if (!property) return 0;
property->read_cb = read_cb;
property->pdata = pdata;
property->idata = idata;
return (int) element->ninstances;
}在读取数据的进修,这个指针被ply_read_element又传递给了argument->pdata,
//ref. rply.c
static int ply_read_element(p_ply ply, p_ply_element element,
p_ply_argument argument) {
long j, k;
/* for each element of this type */
for (j = 0; j < element->ninstances; j++) {
argument->instance_index = j;
/* for each property */
for (k = 0; k < element->nproperties; k++) {
p_ply_property property = &element->property[k];
argument->property = property;
argument->pdata = property->pdata;
argument->idata = property->idata;
if (!ply_read_property(ply, element, property, argument))
return 0;
}
}
return 1;
}经过几个设置函数,最后由前面传递进去的read_cb函数,也就是PlyFilter.cpp中的vertex_cb函数将读取到的点加入cloud中,
//ref. PlyFilter.cpp
static int vertex_cb(p_ply_argument argument)
{
ccPointCloud* cloud;
ply_get_argument_user_data(argument, (void**)(&cloud), &flags);
......
if (flags & ELEM_EOL)
{
......
cloud->addPoint((s_Point + s_Pshift).toPC());
++s_PointCount;
......
}
return 1;
}这个addPoint函数,最终把点加入到一个vector向量中,
// ref. CCTypes.h
using PointCoordinateType = float;
// ref. CCGeom.h
using CCVector3 = Vector3Tpl<PointCoordinateType>;
// ref. PointCloudTpl.h
std::vector<CCVector3> m_points;这个模板CCVector3最重要的定义是下面这个Union,他定义了一个XYZ的位置坐标。
//! 3-Tuple structure (templated version)
template <class Type> class Tuple3Tpl
{
public:
// The 3 tuple values as a union (array/separate values)
union
{
struct
{
Type x, y, z;
};
Type u[3];
};
......
};
template <typename Type> class Vector3Tpl : public Tuple3Tpl<Type>
{
public:
......
};类似的,ccMesh是一个专门保存面数据信息的类。
//ref. PlyFilter.cpp, LoadFile
mesh = new ccMesh(cloud);我这里,圆柱体有152个面(numberOfFacets==152)。注意到前面顶点信息其实是保存在向量里,和顶点信息类似,面的信息也是通过一个向量保存的;不同的是,这里显示通过下面这个函数来获取内存空间,
// ref. PlyFilter.cpp, LoadFile
mesh->reserve(numberOfFacets)
// ref. ccMesh.cpp
bool ccMesh::reserve(size_t n)
{
if (m_triNormalIndexes)
if (!m_triNormalIndexes->reserveSafe(n))
return false;
if (m_triMtlIndexes)
if (!m_triMtlIndexes->reserveSafe(n))
return false;
if (m_texCoordIndexes)
if (!m_texCoordIndexes->reserveSafe(n))
return false;
return m_triVertIndexes->reserveSafe(n);
}最终使用到的,是下面这样的一个结构体,
//ref. ccMesh.h
//! Container of per-triangle vertices indexes (3)
using triangleIndexesContainer = ccArray<CCCoreLib::VerticesIndexes, 3, unsigned>;
//! Triangles' vertices indexes (3 per triangle)
triangleIndexesContainer* m_triVertIndexes;根据定义,
ccArray<CCCoreLib::VerticesIndexes, 3, unsigned>可以知道每一个元素只保存了3个unsigned数据。
更具体一些,其数据类型的定义如下,
//ref. GenericIndexedMesh.h
struct VerticesIndexes
{
union
{
struct
{
unsigned i1, i2, i3;
};
unsigned i[3];
};
....
};其相关定义ccArray如下,
ccArrary.h
//! Shareable array that can be properly inserted in the DB tree
template <class Type, int N, class ComponentType>
class ccArray :
public std::vector<Type>,
public CCShareable, public ccHObject
{
public:
...
}其核心就是
std::vector<Type>也就是
std::vector<CCCoreLib::VerticesIndexes>在读取时,几乎和顶点一模一样的操作,先设置face_cb回调函数,
ply_set_read_cb(ply, meshElements[pp.elemIndex].elementName, pp.propName, face_cb, mesh, 0);然后逐个读取face的数据点,通过face_cb添加到mesh
//ref. PlyFilter.cpp, face_cb
mesh->addTriangle(s_tri[0], s_tri[1], s_tri[2]);本文结束。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只