原本想要和之前一样写作“代码复现”,然而由于本人一开始对于Autoformer能力理解有限,参考了一定的论文中的源代码,写着写着就发现自己的代码是“加了注释版本”的源代码,故而只能是源代码的浅读,而非复现。
模型结构:

这一部分之所以是零,是因为我在论文复现时没有对dataloader部分进行复现,但是复现完毕之后发现它实际上是有相当的重要性的,故而在此留空,之后有时间会对此进行解读。
现在所需要知道的就是,dataloader会返回2个结果:其一是经过标准化之后的x,其二是将时间序列数据根据不同的粒度划分出来的列表,也就是接下来的x_mark。
此处的Embedding和Transformer中的有所不同,没有使用Positional Embedding,因为时间序列数据本身就包含了位置信息,所以不再需要Positional Encoding(源代码中的注释是这么写的,然而之后的Fixed Embedding还是像Postional Encoding那样加入了sin和cos的位置信息)。取而代之的,是使用TokenEmbedding和Temporal Embedding作为Embedding层。
Token Embedding:
这个词可能看起来有点陌生,但其实就是Word Embedding的一个一般情况(Token Embedding包含Word Embedding),源代码中使用了一个卷积核将序列中的各个x映射到一个d_model大小的空间上。
class TokenEmbedding(nn.Module):
def __init__(self,c_in,d_model):
#batch_szie,L,c_in->batch_szie,L,d_model
super(TokenEmbedding,self).__init__()
self.tokenConv = nn.Conv1d(in_channels=c_in,out_channels=d_model
,kernel_size=3,padding=1
,padding_mode='circular',bias=False)
for m in self.modules():
if isinstance(m,nn.Conv1d):
nn.init.kaiming_normal_(m.weight,mode='fan_in',nonlinearity='leaky_relu')
def forward(self,x):
x = self.tokenConv(x.transpose(1,2)).transpose(1,2)
return xTemporal Embedding:
这个Temporal Embedding似乎是使用了Informer中的方法。TemporalEmbedding中的embedding层可以使用Pytorch自带的embedding层,再训练参数,也可以使用定义的FixedEmbedding,它使用位置编码作为embedding的参数,不需要训练参数。Temporal Embedding中的hour,day,month等粒度的数据都是通过dataloader预处理后截取得来的。
class FixedEmbedding(nn.Module):
def __init__(self,c_in,d_model):
"""
使用位置编码作为embedding参数,不需要训练
batch_szie,L,c_in->batch_szie,L,d_model
"""
super(FixedEmbedding,self).__init__()
w = torch.zeros(c_in,d_model).float()
w.require_grad = False
position = torch.arange(0,c_in).float().unsqueeze(1)
div_term = torch.pow(torch.from_numpy(np.array([10000])).float(),torch.arange(0,d_model,2).float()/d_model)
w[:,0::2]=torch.sin(position*div_term)
w[:,1::2]=torch.cos(position*div_term)
self.emb = nn.Embedding(c_in,d_model)
self.emb.weight = nn.Parameter(w,require_grad=False)
def forward(self,x):
return self.emb(x).detach()class TemporalEmbedding(nn.Module):
def __init__(self,d_model,embed_type = 'fixed'
,add_minute = False
,add_hour = False
,add_weekday = False
,add_day = False
,add_month = False
):
"""
似乎和Informer是一个Embedding层
TemporalEmbedding中的embedding层可以使用Pytorch自带的embedding层,再训练参数,也可以使用定义的FixedEmbedding,
它使用位置编码作为embedding的参数,不需要训练参数。
batch_szie,L,c_in->batch_szie,L,d_model
"""
super(TemporalEmbedding,self).__init__()
minute_size = 4
hour_size = 24
weekday_size = 7
day_size = 32
month_size = 13
Embed = FixedEmbedding if embed_type == 'fixed' else nn.Embedding
if add_minute == True:
self.minute_embed = Embed(minute_size,d_model)
if add_hour == True:
self.hour_embed = Embed(hour_size,d_model)
if add_weekday == True:
self.weekday_embed = Embed(weekday_size,d_model)
if add_day == True:
self.day_embed = Embed(day_size,d_model)
if add_month == True:
self.month_embed = Embed(month_size,d_model)
def forward(self,x):
x = x.long() #向下取整 为什么?
minute_x = self.minute_embed(x[:,:,4]) if hasattr(self,'minute_embed') else 0. #x_mark
hour_x = self.hour_embed(x[:,:,3]) if hasattr(self,'hour_embed') else 0.
weekday_x = self.weekday_embed(x[:,:,2]) if hasattr(self,'weekday_embed') else 0.
day_x = self.day_embed(x[:,:,1]) if hasattr(self,'day_embed') else 0.
month_x = self.month_embed(x[:,:,0]) if hasattr(self,'month_embed') else 0.
return minute_x+hour_x+weekday_x+day_x+month_x最终将以上2个Embedding合为1个:
class DataEmbedding_wo_pos(nn.Module):
"""
batch_szie,L,c_in->batch_szie,L,d_model
"""
def __init__(self,c_in,d_model,embed_type = 'fixed'
,add_minute = False
,add_hour = False
,add_weekday = False
,add_day = False
,add_month = False
,p_dropout = 0.1):
super(DataEmbedding_wo_pos,self).__init__()
self.value_embedding = TokenEmbedding(c_in=c_in,d_model=d_model)
self.temporal_embedding = TemporalEmbedding(d_model=d_model,
embed_type = embed_type,
add_minute = add_minute
,add_hour = add_hour
,add_weekday = add_weekday
,add_day = add_day
,add_month = add_month)
self.dropout = nn.Dropout(p=p_dropout)
def forward(self,x,x_mark):
x = self.value_embedding(x) + self.temporal_embedding(x_mark)
#x为经过标准化的序列,x_mark为在data_loader中预处理过的序列集合,包括month,day,weekday,hour四个维度
return self.dropout(x)
在Autoformer中,使用了Auto-Correlation代替了原本Transformer中的self-Attention。
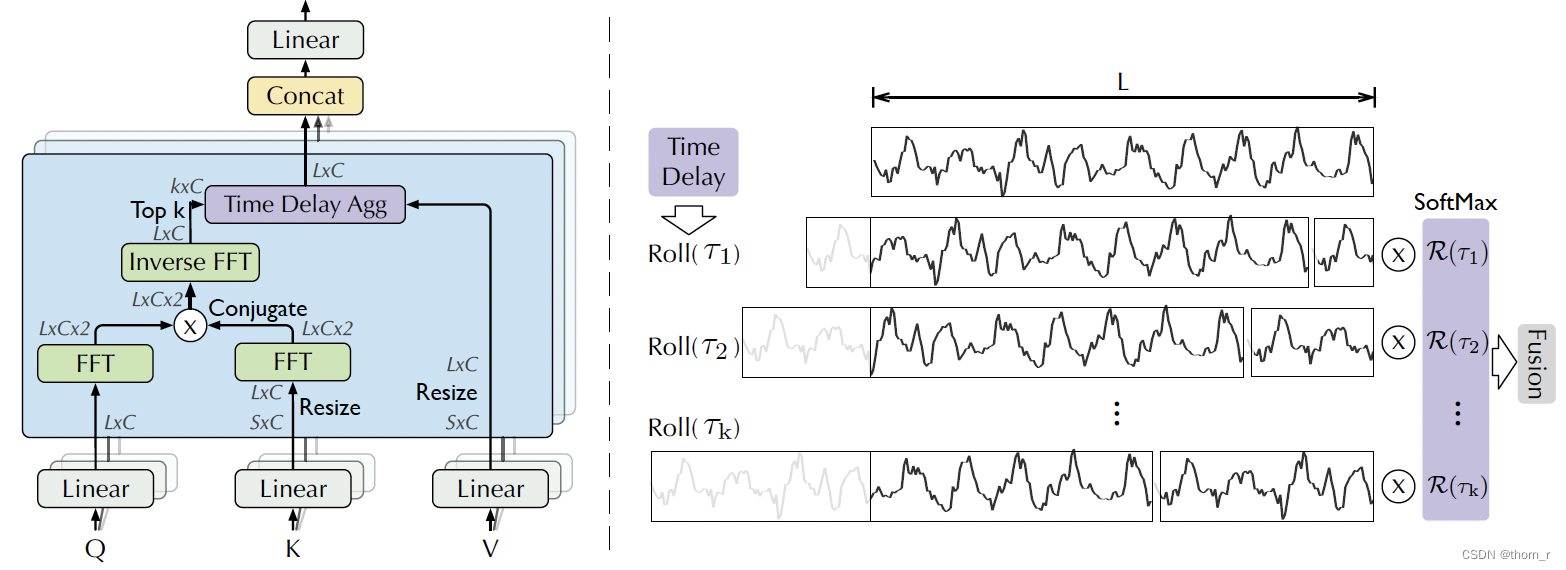
首先将Key和Value的长度截取或补全为和Query一样的长度。然后与Transformer不同,不再使用缩放点积来度量Query和Value的相似程度,取而代之的是使用序列的相关系数作为度量。使用维纳-辛钦定理计算出Q和K的相关系数。
由于本人没有信号学基础,以下内容都是自己的理解,不一定对。
纳-辛钦定理:任意一个均值为常数的广义平稳随机过程的功率谱密度是其自相关函数的傅立叶变换。反过来讲,功率谱密度的逆傅里叶变换就是其自相关函数。而根据帕塞瓦尔定理,信号的功率谱密度可以表现为这个信号的傅里叶变换乘以他的共轭傅里叶变换(此处存疑,因为源代码中是这么写的,而帕塞瓦尔定理我也没有看懂,单纯是根据结果问来的)。所以,将一个序列作傅里叶变换再乘以共轭傅里叶变换,然后再作傅里叶逆变换,就可以得到他的自相关函数。(问题:2个序列的相关系数可以这么做吗?有时Q和K不是相同的)。
之后选择前k个最高的自相关的滞后期,对每个序列作TimeDelayAgg处理:每个序列都看作是周期无穷的序列,向后滞后t个时刻,之后再将前面部分的信息拼接在后面,使得长度一样。
类似于如下所示:
test_v = torch.from_numpy(np.concatenate([[np.arange(30)],[np.arange(30)]]).reshape(1,1,2,30))
v = test_v.repeat(1,1,1,2)
corr = torch.from_numpy(np.random.random(test_v.shape))
weight,delay = torch.topk(corr,5,dim=-1)
idx = torch.arange(30).unsqueeze(0).unsqueeze(0).unsqueeze(0).repeat(1,1,2,1)
tmp_delay = idx+delay[:,:,:,0].unsqueeze(-1)
pattern = torch.gather(v,dim=-1,index = tmp_delay)plt.plot(test_v[0,0,0,:])
plt.show() 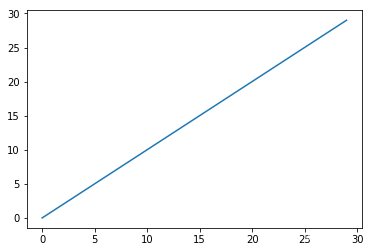
plt.plot(pattern[0,0,0,:])
plt.show()
如图,相当于是将最后的那几段t长度的值挪到前面去了。
最后,将前k个自相关函数softmax之后作为权重,对经过滞后的各个序列加权求和,得到目标序列。
Autoformer使用了Series Decomposition,将序列分为了长期趋势与季节性因素。
顺带一提,传统的时间序列还会考虑周期性(相对于季节性而言,频率不固定),Facebook的prophet模型还可以加入外部因素(如假日或是调休等)这一先验知识。
Autoformer使用类似于MA模型的moving average思想,使用一个AveragePool提取其长期趋势,将原序列减去长期趋势得到季节性因素。
class series_decomp(nn.Module):
"""
移动平均moving average:提取序列的趋势,之后减去它获得周期趋势
"""
def __init__(self,kernel_size,stride):
super(Moving_average,self).__init__()
self.kernel_size = kernel_size
self.stride = stride
self.avg = nn.AvgPool1d(kernel_size=kernel_size,stride=stride,padding=0)
#源代码中,之后调用stride都会默认填一个1进去
#问题:平稳序列是否就不能这么做了?
def forward(self,x):
"""
x的形状:[batchsize,Length,dv或dk*n_head]
"""
origin_x = x
front = x[:,0,:].repeat(1,(self.kernel_size-1)//2,1)#这个repeat是代替了原来padding的作用
end = x[:,-1,:].repeat(1,(self.kernel_size-1)//2,1)
x = torch.cat([front,x,end],dim=1)
x = x.permute(0,2,1)
x = self.avg(x)
x = x.permute(0,2,1)
return origin_x - x,x注意到此处的kernel_size再源代码中被设置为了25,我个人理解是这里的kernel_size为移动平均步长,想要提取长期趋势的话,最好和时序本身的周期相同。下面是我的个人实验:
x = torch.from_numpy(np.concatenate([
[0.1*np.arange(70)+0.01*np.arange(70)],
[0.3*np.arange(70)+0.01*np.arange(70)],
[0.5*np.arange(70)+0.01*np.arange(70)],
[0.7*np.arange(70)+0.01*np.arange(70)],
[0.9*np.arange(70)+0.01*np.arange(70)],
[1.1*np.arange(70)+0.01*np.arange(70)],
[1.3*np.arange(70)+0.01*np.arange(70)],
[1.5*np.arange(70)+0.01*np.arange(70)]
]).reshape(1,-1,1))
plt.plot(x[0,:,0])
plt.show()
ma = Moving_average(71,1)
res = ma.forward(x)
plt.plot(res[0,:,0])
plt.show()
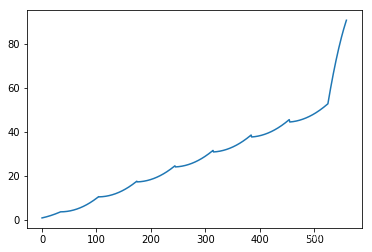
如图所示。但是有一点需要注意:kernel_size也不能随便取,有时这个数字会导致长期趋势的数组长度为原始序列长度-1,从而导致序列长度不一样的报错。
并且如果kernel_size过大,也就是滑动平均步长过大,会变成“将开始与结果直接连一条线”的粗暴结果。
在源代码中,有一个LayerNorm的实现,注释说是为季节因素而特制的。其实就是在普通的LayerNorm的基础上再减去一个平均值(将季节因素标准化?)。
class LayerNorm(nn.Module):
"""
原文中说这是为季节因素特制的LayerNorm
"""
def __init__(self,channels):
super(LayerNorm,self).__init__()
self.layernorm = nn.LayerNorm(channels)
def forward(self,x):
x_hat = self.layernorm(x)
bias = torch.mean(x_hat,dim=1).unsqueeze(1).repeat(1,x.shape[1],1) #个人理解:在LayerNorm之后再减去一个平均值(将季节因素标准化)
return x_hat-bias
有了上述的准备后,就可以实现Encoder了。实际上和Transformer的Encoder只有2处不同:其一是将self-Attention改为了Auto-Correlation,另一处就是使用series-decomp提取了季节因素。
class EncoderLayer(nn.Module):
def __init__(self,attention,d_model,d_ff,moving_avg,p_dropout,activation = F.relu):
super(EncoderLayer,self).__init__()
self.attn = attention
self.conv1 = nn.Conv1d(in_channels=d_model,out_channels=d_ff,kernel_size=1,bias=False)
self.conv2 = nn.Conv1d(in_channels=d_ff,out_channels=d_model,kernel_size=1,bias=False)
#conv1d和Linear的区别:https://zhuanlan.zhihu.com/p/77591763
#实际上,conv1d和Linear除了对于输入形状的要求不同,理论上原理应该是一样的conv1d是channel_first
self.decomp1 = series_decomp(moving_avg)
self.decomp2 = series_decomp(moving_avg)
self.dropout = nn.Dropout(p_dropout)
self.activation = activation
def forward(self,x,attn_mask=None):
x = self.dropout(self.attn(x,x,x,attn_mask = attn_mask))+x #auto-correlation
x,_ = self.decomp1(x)#Series decomp 在Encoder中只提取季节因素
#feed-forward
residual = self.dropout(self.activation(self.conv1(x.tranpose(-1,1))))
residual = self.dropout(self.conv2(residual.tranpose(-1,1)))
x = x+residual
res,_ = self.decomp2(x) #只返回周期趋势给到Decoder
return resclass Encoder(nn.Module):
def __init__(self,attn_layers,conv_layers,norm_layer):
super(Encoder,self).__init__()
self.attn_layers = attn_layers
self.conv_layers = nn.ModuleList(attn_layers)
self.norm = norm_layer
def forward(self,x,attn_mask=None):
"""
源代码中,convlayers为None
"""
if self.conv_layers is not None:
for attn_layer,conv_layer in zip(self.attn_layers,self.conv_layers):
x,attn = attn_layer(x,attn_mask)
x = conv_layer(x)
x = self.attn_layers[-1](x) #attn_layer比convlayer多1个
else:
for attn_layer in self.attn_layers:
x = attn_layer(x)
if self.norm is not None:
x = self.norm(x)
return xDecoder的输入分为2部分,其一是Seasonal_init:取原始序列季节因素的最后k个长度(k为设定的训练用的长度),在剩下的pred_len(要预测的长度)中使用0来填充。而Trend_init则是取原始序列趋势因素的最后k个长度,最后用均值填充。其中Seasonal_init和传统Transformer一样,不过将其中的self-Attention改为了Auto-Correlation,并且加入series decompostion,将序列的周期因素传到下一步,长期趋势因素加入到Trend_init中,最终将2部分相加。
class DecoderLayer(nn.Module):
def __init__(self,self_attn,cross_attn,d_model,c_out,d_ff,moving_avg,dropout,activation=F.relu):
"""
输入:[batchsize,Length,d_model],为embedding之后经过Seasonal Init的序列
前一部分是长度同预测序列长度的后t个时间段的序列,后一部分用0填充
"""
super(DecoderLayer,self).__init__()
self.d_ff = d_ff
self.self_attn = self_attn
self.cross_attn = cross_attn
self.conv1 = nn.Conv1d(in_channels=d_model,out_channels=d_ff,kernel_size=1,stride=1,bias=False)
self.conv2 = nn.Conv1d(in_channels=d_ff,out_channels=d_model,kernel_size=1,stride=1,bias=False)
self.decomp1 = series_decomp(moving_avg)
self.decomp2 = series_decomp(moving_avg)
self.decomp3 = series_decomp(moving_avg)
self.conv_out = nn.Conv1d(in_channels=d_model,out_channels=c_out,kernel_size=3,stride=1,padding=1,padding_mode='circular',bias=False) #为什么?
self.activation = activation
def forward(self,x,cross,x_mask=None,cross_mask=None):
#cross是Encoder的输出
x = x+self.dropout(self.self_attn(x,x,x,attn_mask = x_mask))
x,trend1 = self.decomp1(x)
x = x+self.dropout(self.cross_attn(x,cross,cross,attn_mask = cross_mask))
x,trend2 = self.decomp2(x)
#Feed_forward
y = x
y = self.dropout(self.activation(self.conv1(y.transpose(-1,1))))
y = self.dropout(self.conv2(y).transpose(-1,1))
x, trend3 = self.decomp3(x+y)
residual_trend = trend1 + trend2 + trend3
residual_trend = self.conv_out(residual_trend.transpose(2,1)).transpose(1,2) #卷积层代替全连接层
return x,residual_trendclass Decoder(nn.Module):
def __init__(self,layers,norm_layer=None,projection = None):
super(Decoder,self).__init__()
self.layers = nn.ModuleList(layers)
self.norm = norm_layer
self.projection = projection
def forward(self,x,cross,x_mask=None,cross_mask=None,trend=None):
for layer in self.layers:
x,residual_trend = layer(x,cross,x_mask=x_mask,cross_mask=cross_mask)
trend = trend + residual_trend
#输入的trend最初是经过trend Init的序列:前一部分是长度同预测序列长度的后t个时间段的序列,后一部分用均值填充
#之后将decoder中分解出来的趋势因素不断对其相加
if self.norm is not None:
x = self.norm(x)
if self.projection is not None:
x = self.projection(x)
return x,trend最后,根据以上准备,写出Autoformer
class Autoformer(nn.Module):
"""
"""
def __init__(self,**kwargs):
super(Autoformer,self).__init__()
self.seq_len = kwargs['seq_len']
self.label_len = kwargs['label_len']
self.pred_len = kwargs['pred_len']
self.output_attn = kwargs['output_attn']
self.decomp = series_decomp(kwargs['moving_avg'])
#源代码中的注释:
#The series-wise connection inherently contains the sequential information.
#Thus, we can discard the position embedding of transformers.
#问题:但是Fixed-Embedding中不是也加入了位置编码作为embedding参数吗?
self.enc_embedding = DataEmbedding_wo_pos(kwargs['enc_in']
,kwargs['d_model']
,kwargs['embed_type']
,kwargs['add_minute']
,kwargs['add_hour']
,kwargs['add_weekday']
,kwargs['add_day']
,kwargs['add_month']
,kwargs['p_dropout']
)
self.dec_embedding = DataEmbedding_wo_pos(kwargs['dec_in']
,kwargs['d_model']
,kwargs['embed_type']
,kwargs['add_minute']
,kwargs['add_hour']
,kwargs['add_weekday']
,kwargs['add_day']
,kwargs['add_month']
,kwargs['p_dropout']
)
self.encoder = Encoder(
[
EncoderLayer(
AutoCorrelation(
kwargs['d_model'],
kwargs['n_heads'], #原本还有个d_ff的参数,在AutoCorrelation中显示为scale,但其实并没用到这一参数
dk=kwargs['d_model']//kwargs['n_heads'],
dv=kwargs['d_model']//kwargs['n_heads']
),
kwargs['d_model'],
kwargs['d_ff'],
kwargs['moving_avg'],
kwargs['p_dropout']
) for _ in range(kwargs['e_layers'])
],
norm_layer=LayerNorm(kwargs['d_model'])
)
self.decoder = Decoder(
[
DecoderLayer(
AutoCorrelation(
kwargs["d_model"],
kwargs["n_heads"],
dk=kwargs['d_model']//kwargs['n_heads'],
dv=kwargs['d_model']//kwargs['n_heads']
),#decoder的auto-correlation
AutoCorrelation(
kwargs["d_model"],
kwargs["n_heads"],
dk=kwargs['d_model']//kwargs['n_heads'],
dv=kwargs['d_model']//kwargs['n_heads']
),#encoder结果用的auto-correlation
kwargs['d_model'],
kwargs['c_out'],
kwargs['d_ff'],
kwargs['p_dropout'],
kwargs['activation']
)
for _ in range(kwargs['d_layers'])
],
norm_layer=LayerNorm(kwargs["d_model"]),
projection=nn.Linear(kwargs['d_model'],kwargs['n_heads'],bias=True)
)
def forward(self,x_enc,x_mark_enc,x_dec,x_mark_dec):
"""
mask暂时没用
"""
mean = torch.mean(x_enc,dim=1).unsqueeze(1).repeat(1,self.pred_len,1)
zeros = torch.zeros([x_dec.shape[0],self.pred_len,x_dec[2]],device = x_enc.device)
seasonal_init,trend_init = self.decomp(x_enc)
#decoder_input
trend_init = torch.cat([trend_init[:,-self.label_len:,:],mean],dim=1) #输入被当作标签长度的序列
season_init = torch.cat([seasonal_init[:,-self.label_len:,:],zeros],dim=1) #2个decoder的初始化输入,和图中左侧示例一样
#enc
enc_out = self.enc_embedding(x_enc,x_mark_enc)
enc_out = self.encoder(enc_out)
#dec
dec_out = self.dec_embedding(season_init,x_mark_dec)
seasonal,trend = self.decoder(dec_out,enc_out,trend = trend_init)
#final
res = trend+seasonal_init
return res[:,-self.pred_len:,:] #Batch,L,D
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称