上一节介绍了活动网络AOV网络的相关内容,这一节将进一步介绍另一种活动网络AOE网络。如果对于有向无环图(DAG),用有向边表示一个工程的各项活动(activity),边上的权值表示活动的持续时间(duration),用顶点表示事件(event),那么这种DAG被称为边表示活动的网络(Activity On Edges),简称AOE网络。
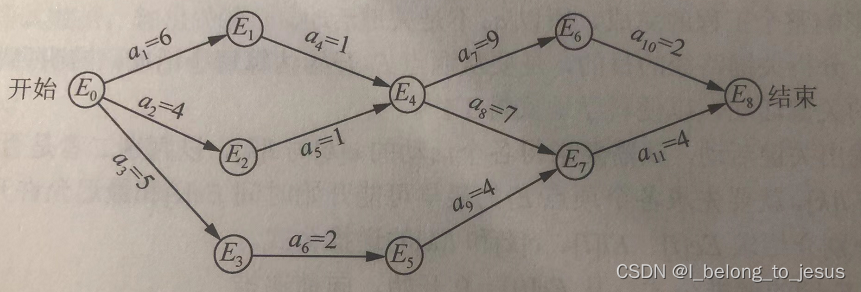
图1
如图所示为一个AOE网络,可以看到有11项活动,有9个事件
。事件
发生表示之前的活动都已经完成,例如
发生表示
和
已完成,
和
可以开始。每条边的权重表示对应活动的持续时间。工程开始之后,
可以并行执行,而
发生后,
也可以并行执行。对于AOE网络,其有两个特殊的顶点:开始点(
, 入度为0的顶点)称之为源点(source)和结束点(
,出度为0的点)称之为汇点(sink),分别表示整个工程的开始和结束,均只有一个。
AOE网络主要要解决的问题:
1.完成整个工程至少需要多长时间?
2.为缩短完成工程的事件,应加快哪些活动?
可以看到从源点到汇点有多条路径,而由于并行化的原因,完成整个工程所需的时间取决于最长路径的长度,这条最长路径称为关键路径(critical path)。例如图1的关键路径为或者
,持续时间之和都是18。
找出关键路径可以分解为找出关键活动(critical activity),即关键路径上的所有活动。先定义几个关键量:
1):事件
最早可能的开始时间,
表示顶点
到顶点
的最长路径长度,例如
;
2):事件
最迟允许开始时间,即在保证汇点
在
时刻完成的前提下,事件
的允许最迟开始时间,其等于
减去
到
的最长路径长度,例如
;
3):活动
的最早可能开始时间,
在有向边
上,则
是从源点
到顶点
的最长路径长度,因此
;
4):活动
的最迟允许开始时间,
在有向边
上,则
是在不会引起时间延迟的前提下,该活动允许的最迟开始时间。
,
为完成
所需的时间。
表示活动
的最早可能开始时间和最迟允许开始时间的时间余量,也称为松弛时间(slack time)。若
则表示活动
没有时间余量,是关键活动。
看下图1的例子,对于:
。
故是关键路径上的关键活动。
考虑:
故可以推迟3个时间单位,并不是关键活动。
为了找出关键活动,就需要求得各个活动的和
,从而判别二者是否相等。而要求得
和
需要先求得各个顶点
的最早可能开始时间
和最迟允许开始时间
。下面分别介绍求
、
、
和
的递推公式。
1.求的递推公式,从
开始,向前递推
为指向顶点
得所有有向边
的集合。
2.求的递推公式。从
(有定义可知)开始,反向递推
是所有从顶点
出发的有向边
集合。
显然这两条递推公式可以通过之前的定义直接得到。
这两个递推公式的计算必须分别在拓扑排序和逆拓扑排序的前提下进行,逆拓扑排序(reverse topological sort)是指首先输出出度为0的顶点,以相反的次序输出拓扑排序序列。
按照拓扑排序,在计算时,
的所有前驱顶点
的
都已经求出。
按照逆拓扑排序,在计算时,
的所有后继顶点
的
都已经求出,这里我们需要根据拓扑排序计算的
来计算
。
3.求和
的递推公式,活动
对应带权有向边
,则有
,
根据前面分析,我们可以给出计算关键路径的算法
1)构建邻接表;
2)从源点出发,令
,按照拓扑排序计算每个顶点的
,若存在有向环则不能继续求关键路径;
3)从汇点出发,令
,按照逆拓扑排序求各顶点的的
;
4)根据各顶点的和
,求各边的
和
;
5)每条边如果满足,则是关键活动,求出所有关键活动并输出。
基于上一节AOV网络的代码来实现,同样用邻接表来表示连接,但需要增加连接的信息,每个连接的数据结构变为:
typedef struct Vertex{
string name; //顶点名字
int index; //顶点索引编号
int dur; // 活动的持续时间
int no; // 活动序号
Vertex(string inputName, int inputIndex, int inputDur, int inputNo):name(inputName),index(inputIndex),dur(inputDur),no(inputNo){}
Vertex():name(""),index(0),dur(0),no(0){}
} VertexNode;增加活动持续时间和活动序号,另外图信息文件与之前有所不同,文件得每一样存储内容格式如下:起始顶点->连接顶点1->连接1持续时间->连接顶点2->连接2持续时间.....
我们一个例子(graph_struct.txt):
0 1 6 2 4 3 5
1 4 1
2 4 1
3 5 2
4 6 9 7 7
5 7 4
6 8 2
7 8 4
8对应的就是图1中的图结构,完整代码如下:
#include<iostream>
#include<vector>
#include<fstream>
#include<sstream>
#include<string>
#include<unordered_map>
#include<stack>
using namespace std;
typedef struct Vertex{
string name; //顶点名字
int index; //顶点索引编号
int dur; // 活动的持续时间
int no; // 活动序号
Vertex(string inputName, int inputIndex, int inputDur, int inputNo):name(inputName),index(inputIndex),dur(inputDur),no(inputNo){}
Vertex():name(""),index(0),dur(0),no(0){}
} VertexNode;
// graph表示邻接表,id表示每个节点入度统计,topSortId存储拓扑排序的索引。
bool criticalPath(const vector<vector<VertexNode> >& graph, const vector<vector<VertexNode> >& revGraph, vector<int>& id, vector<int>& invId,
vector<int>& Ee, vector<int>& El, vector<int>& e, vector<int>& L) {
vector<int> topSortId;
topSortId.reserve(graph.size());
//step1: 拓扑排序,获取各事件最早可能开始时间Ee
stack<int> S; // 栈,存放入度为0的顶点
for(int i = 0; i < graph.size(); i++) {
if (id[i] == 0) {
S.push(i);
}
}
for (int i = 0; i < graph.size(); i++) {
if(S.empty()) {
return false;
}
int j = S.top();
S.pop(); //弹出栈顶存储的顶点j
topSortId.push_back(j); //存入拓排序序列
for(int k = 0; k < graph[j].size(); k++) {
int currentIndex = graph[j][k].index; // 顶点j连接的顶点
int currentDur = graph[j][k].dur; // 顶点j连接的顶点之间边的活动持续时间
if(--id[currentIndex] == 0) {
S.push(currentIndex);
}
if (Ee[j] + currentDur > Ee[currentIndex]) {
Ee[currentIndex] = Ee[j] + currentDur;
}
}
}
// step2: 逆拓扑排序,获取各事件最迟允许开始时间El
stack<int> S1; // 栈,存放出度为0的顶点
for(int i = 0; i < El.size(); i++) {
El[i] = Ee[Ee.size() - 1];
if(invId[i] == 0) S1.push(i); //初始出度为0的顶点入栈
}
for (int i = 0; i < revGraph.size(); i++) {
int j = S1.top();
S1.pop(); //弹出栈顶存储的顶点j
for(int k = 0; k < revGraph[j].size(); k++) {
int currentIndex = revGraph[j][k].index; // 顶点j连接的顶点
int currentDur = revGraph[j][k].dur; // 顶点j连接的顶点之间边的活动持续时间
if(--invId[currentIndex] == 0) {
S1.push(currentIndex);
}
if (El[j] - currentDur < El[currentIndex]) {
El[currentIndex] = El[j] - currentDur;
}
}
}
// step3: 判定各条边是否是关键活动
for(int i = 0; i < graph.size(); i++) {
for(int k = 0; k < graph[i].size(); k++) {
int currentIndex = graph[i][k].index; // 顶点j连接的顶点
int currentDur = graph[i][k].dur; // 顶点j连接的顶点之间边的活动持续时间
int no = graph[i][k].no; // 该条边对应活动的序号
e[no] = Ee[i];
L[no] = El[currentIndex] - currentDur;
if(e[no] == L[no]) {
cout << "a" << no + 1 <<" : " << i << "->" << currentIndex <<endl;
}
}
}
return true; // 如果前面所有顶点全部循环没问题,那么说明可以拓扑排序故返回true.
}
int main() {
unordered_map<string ,int> graphMap; // 图节点名和编号的Map
vector<vector<VertexNode> > adjGraph; // 图的连接表表示法,邻接表
vector<vector<VertexNode> > reverseAdjGraph; // 图的连接表表示法,逆邻接表
ifstream graphRdFile("graph_struct.txt");
if(!graphRdFile.good()) {
cout << "open graph file failed!" << endl;
return -1;
}
string line;
int index = 0;
string vertexName;
// 首先对Vertex Name进行编码
while (getline(graphRdFile, line)) {
istringstream ss(line);
string tmp1,tmp2; //顶点名字和顶点权重。
if (ss >> tmp1) {
if (graphMap.find(tmp1) == graphMap.end()) {
graphMap.insert(make_pair(tmp1, index++));
}
}
while(ss >> tmp1 >> tmp2) {
if (graphMap.find(tmp1) == graphMap.end()) {
graphMap.insert(make_pair(tmp1, index++));
}
}
}
// 编码与Vertex的反映射
vector<string> indexName = vector<string>(graphMap.size(),"");
for(auto itr=graphMap.begin();itr!=graphMap.end();itr++) {
indexName[itr->second] = itr->first;
}
// 重新读
graphRdFile.clear();
graphRdFile.seekg(0,std::ios::beg);
adjGraph.resize(graphMap.size());
reverseAdjGraph.resize(graphMap.size());
int currentIndex = 0; // 当前图节点的编号
vector<int> id(adjGraph.size(), 0); // 每个节点入度统计
vector<int> invId(adjGraph.size(), 0); // 每个节点出度统计
vector<int> Ee(adjGraph.size(), 0); //各事件最早可能开始时间
vector<int> El(adjGraph.size(), 0); //各事件最迟允许开始时间
int activNum = 0; // 活动序号
while (getline(graphRdFile, line)) { //按行读,每一行是一个图节点的连接情况
istringstream ss(line);
string tmp; // 顶点名字
int inputDur; //顶点权重
bool firstFlag = true;
while(ss >> tmp) {
if (firstFlag) {
if (graphMap.find(tmp) != graphMap.end()) {
currentIndex = graphMap[tmp];
} else {
break;
}
firstFlag = false;
continue;
}
if (graphMap.find(tmp) != graphMap.end()) {
if(ss >> inputDur){
adjGraph[currentIndex].emplace_back(VertexNode(tmp,graphMap[tmp],inputDur, activNum++)); //邻接表构造
id[graphMap[tmp]]++; // 终点入度+1
invId[currentIndex]++; //起点出度+1
reverseAdjGraph[graphMap[tmp]].emplace_back(VertexNode(indexName[currentIndex],currentIndex,inputDur,0));
}
}
}
}
vector<int> e(activNum, 0); //各活动最早可能开始时间
vector<int> L(activNum, 0); //各活动最迟允许开始时间
// AOE关键路径测试:
if(criticalPath(adjGraph, reverseAdjGraph, id, invId, Ee, El, e, L)) {
cout << "Success!" << endl;
} else {
cout << "Network has a cycle!" << endl;
}
return 0;
}对应图1的图结构执行结果如下:
a1 : 0->1
a4 : 1->4
a7 : 4->6
a8 : 4->7
a10 : 6->8
a11 : 7->8
Success!可以看到成功输出了所有的关键活动。
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我正在尝试学习Ruby词法分析器和解析器(whitequarkparser)以了解更多有关从Ruby脚本进一步生成机器代码的过程。在解析以下Ruby代码字符串时。defadd(a,b)returna+bendputsadd1,2它导致以下S表达式符号。s(:begin,s(:def,:add,s(:args,s(:arg,:a),s(:arg,:b)),s(:return,s(:send,s(:lvar,:a),:+,s(:lvar,:b)))),s(:send,nil,:puts,s(:send,nil,:add,s(:int,1),s(:int,3))))任何人都可以向我解释生成的
下面的代码工作正常:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson)do|key,oldv,newv|ifkey==:aoldvelsifkey==:bnewvelsekeyendendputskerson.inspect但是如果我在“ifblock”中添加return,我会得到一个错误:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案