近期开始阅读cv领域的一些经典论文,本文整理计算机视觉的奠基之作——Alexnet
论文原文:ImageNet Classification with Deep Convolutional Neural Networks(有需要论文原文的可以私信联系我)
本文的阅读方法是基于李沐老师的B站讲解视频,需要细致去看的小伙伴可以去搜索,链接如下:
9年后重读深度学习奠基作之一:AlexNet【论文精读】_哔哩哔哩_bilibili
本文整理用于之后自己能够更快的回忆起这篇论文,所以有些地方记录的可能没那么严谨,有问题的地方欢迎各位指出和讨论,我及时修改,谢谢各位!
如果该论文笔记对你有所帮助,希望可以点个赞关注一下,之后会继续更新cv领域的一些经典论文的笔记,谢谢大家!
当我们在阅读一篇论文时,可以分为三遍阅读:
目录
Training on Multiple GPUs—用多个GPU训练
Local Response Normalization——局部归一化
摘要简单总结来说提出了以下四点:
总结来说讨论就是作者的一些吐槽以及后续的一些工作打算,大概分为了以下三点:

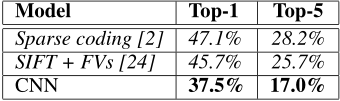
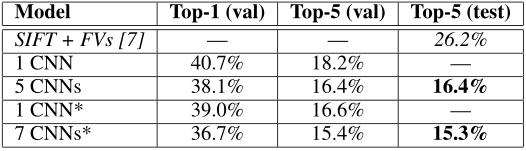
下面两张表格是与之前最好的模型做的对比以及一些数据,这里不做详细解释了:
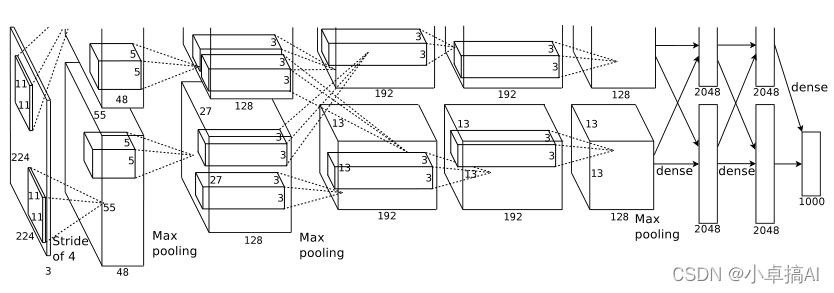
结构流程图非常重要,在第二遍阅读时再详细解释:
Introduce部分主要说了以下几点:
网络架构分为八个层,其中有五个卷积层和三个全连接层。下面每一小节都介绍了一些新颖的不同寻常的功能:
讲述了一下我们采用的激活函数是非线性的ReLU函数。这个非线性激活函数是不饱和的,但是训练速度要比饱和的非线性激活函数tanh和sigmoid要快的多。(但具体为什么快没具体说,现在的视角看来也没快多少,都差不多,但是ReLU函数要简单所以用的多)
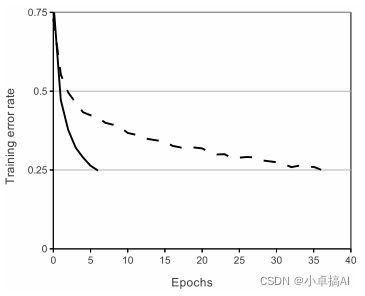
下图的实线为采用ReLU的误差下降率,虚线则是tanh的下降率,明显ReLU下降起来要快得多。
这一部分偏工程型,不用太注意这些细节,主要是说了图片太多我们无法在一个GPU上训练,所以把网络切开训练,之后的架构图中会说明怎么切的,切完之后用了两个GPU去训练。
总结来说,在ReLU层之前我们应用了normalization得到了一个更好的效果。(注:这个现在看来不重要了,因为之后没人用过这种normalization技术,而且我们有了更好的normalization方法,下述方法也不用了,所以不重要)
首先说了ReLU虽然有一个性质是说不需要input normalization来避免饱和,但是用一下normalization效果会更好
下面复杂的公式可以忽略掉,但是这里我们也放上了:
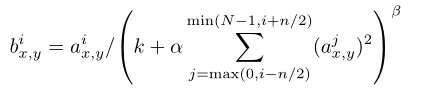
采用了重叠pooling。
总结一些:一般来说两个pooling是不重叠的,但是这里采用了一种对传统的pooling改进的方式,效果很好。知道这些即可。
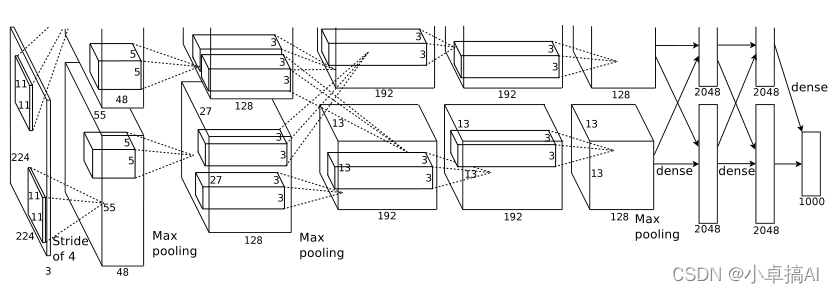
上图为整体流程图,说明几点:
总结:整个过程就是一张图片,经过模型处理变为了一个4096维的向量,这个向量可以把中间的语义信息表示出来。机器学习可以认为是一个压缩知识的过程;具体来讲就是我们原始的一个图片,文字或者视频输入到一个模型中,这个模型就会把它压缩为一个向量,这个向量机器可以识别,用来实现别的任务,例如分类等等。
避免过拟合采用了两种方法:数据增强和dropout
减少图像数据过度拟合的最简单也是最常见的方法是使用保留标签的变换人为地放大数据集。这里用了两种方式:
随机的将隐藏层的输出以50%的概率设为0,相当于一个L2的正则化,只不过用了这种方式实现了L2正则化的功能。
SGD:我们使用随机梯度下降法(SGD)训练我们的模型,批量大小为128,momentum为0.9(对传统SGD增加了动量这个观点,来解决传统SGD的一些问题,例如优化过程非常不平滑或者梯度下降很低效的时候),weight decay为0.0005(可以理解为是一个L2的正则化项,用在优化算法上而不是模型上)。我们发现,这种少量的weight decay对模型的学习很重要。换句话说,这里的weight decay不仅仅是一个正则化器:它减少了模型的训练误差。权重w的更新规则为
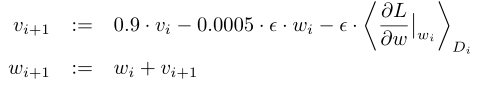
初始化参数:用均值为0 ,方差为0.01的高斯随机变量去初始化了权重参数(0.01是一个非常好的数,不大也不小,如果网络过大,例如BERT ,我们才用到0.02)。然后偏置bias也进行了初始化,不过这里不太重要,因为数据平衡的话初始为0最好,但是这里初始1效果更好一些,这个地方也没有继续深入研究。
学习率:我们在所有层上使用相同的学习率,设为0.01。但验证误差不降的时候我们就手动的乘以0.1,也就是降低十倍。也有自动的方法,例如Resnet,训练120轮epoch,初始学习率也是设为0.01,每30轮降低十倍,本文是训练了90个epoch,每一次是120w张图片。当然现在我们都不采用十倍十倍去降低了,我们采用更平滑的降低方式,例如利用cos函数去降低,如下图,蓝色线为本文中的降低方式,十倍十倍去降,红色线是我们现在用的,一开始学习率设的大一些,慢慢下降,这样更高效。

实验部分就知道效果就可以了,具体怎么实验的不用关心,除非你需要重复他的实验。
小知识:训练集、验证集、测试集。验证集就是说用来调参的数据集,可以一直用来调参,但是测试集就运行几次用来看这个模型的效果怎么样。
第一遍阅读时讲的图,不作详述了。
这里记录一点:就是说神经网络一直被人诟病的一个问题,不知道神经网络内部到底训练了一个什么东西,这里右边这个图展示出了最后4096维的向量,可以在一定程度证明神经网络内部的特征到底是一个什么东西。
总结:偏底层的神经元学习的是一些纹理、方向等;偏上的神经元则是学到的是全局点,例如一个手、一个头之类的。
再看一些第二遍未看懂的细节,例如激活函数的饱和和非饱和,这里不带着读第三遍了。
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
目录一、安装包链接二、安装详细步骤1.安装Wireshark和WinPcap2.安装OracleVMVirtualBox3.安装ensp三、安装后注册四、启动路由器出现40错误怎么解决一、安装包链接二、安装详细步骤链接:https://pan.baidu.com/s/1QbUUYMOMIV2oeIKHWP1SpA?pwd=xftx提取码:xftx1.安装Wireshark和WinPcap找到Wireshark安装包所在文件夹,双击它,按照以下步骤安装。2.安装OracleVMVirtualBox找到OracleVMVirtualBox安装包所在文件夹,双击它,按照以下步骤安装。注:可自定义安装
Nginx安装1.官网下载Nginx2.使用XShell和Xftp将压缩包上传到Linux虚拟机中3.解压文件nginx-1.20.2.tar.gz4.配置nginx5.启动nginx6.拓展(修改端口和常用命令)(一)修改nginx端口(二)常用命令1.官网下载Nginxhttp://nginx.org/en/download.html这里我下载的是1.20.2版本,大家按需下载对应稳定版即可2.使用XShell和Xftp将压缩包上传到Linux虚拟机中没有XShell可以参考《Linux操作系统CentOS7连接XShell》3.解压文件nginx-1.20.2.tar.gz1)检查是否存
因学习需要用到keras,通过查找较多资料最终完成Anaconda、TensorFlow和Keras的简单安装。因为网上的相关资料较多但大部分不够全面,查找起来不太方便,因此自己记录一下成功下载安装的详细过程,顺便推荐一下借鉴的写的很好的相关教程文章。keras需要在TensorFlow之上才能运行,所以要先安装TensorFlow,而TensorFlow只能在3.7以前的python版本中运行,所以需要先创建一个基于python3.6的虚拟环境,因此便需要先下载Anaconda。一、Anaconda3下载和安装Anaconda下载安装教程原文链接:https://blog.csdn.net/
CSDN优秀解读:https://blog.csdn.net/jiaoyangwm/article/details/1266387752021https://arxiv.org/pdf/2103.14259.pdf关键解读在目标检测中标签分配的最新进展主要寻求为每个GT对象独立定义正/负训练样本。在本文中,我们创新性地从全局的角度重新审视标签分配,并提出将分配程序制定为一个最优传输(OT)问题——优化理论中一个被充分研究的课题。具体来说,我们将每个需求方(锚框)和供应商(GT标签)的单位传输成本定义为他们的分类和回归损失加权之和。在公式化后,找到最好的分配方案即为最小传播成本解决最优传输方案,
【动态规划】一、背包问题1.背包问题总结1)动规四部曲:2)递推公式总结:3)遍历顺序总结:2.01背包1)二维dp数组代码实现2)一维dp数组代码实现3.完全背包代码实现4.多重背包代码实现一、背包问题1.背包问题总结暴力的解法是指数级别的时间复杂度。进而才需要动态规划的解法来进行优化!背包问题是动态规划(DynamicPlanning)里的非常重要的一部分,关于几种常见的背包,其关系如下:在解决背包问题的时候,我们通常都是按照如下五部来逐步分析,把这五部都搞透了,算是对动规来理解深入了。1)动规四部曲:(1)确定dp数组及其下标的含义(2)确定递推公式(3)dp数组的初始化(4)确定遍历顺
✅作者简介:大家好,我是小杨📃个人主页:「小杨」的csdn博客🔥系列专栏:小杨带你玩转C语言【初阶】🐳希望大家多多支持🥰一起进步呀!大家好呀!我是小杨。小杨花几天的时间将C语言中的操作符这部分知识做了一个大总结,在方便自己复习的同时也能够帮助到大家。通篇字数在一万字左右,可以算作是非常详细了,一文就可以带领大家彻底掌握操作符这部分内容,文章很长建议先收藏再看,防止下次想看就找不到啦。文章目录✍1,算术操作符✍2,移位操作符 🔍2.1,左移操作符 🔍2.2,右移操作符 ✨2.2.1,算术移位 ✨2.2.2,逻辑移位✍3,位操作符 🔍3.1,按位与&