目前微服务作为分段式、高并发、负载均衡、服务注册、权限认证、聚合文档、熔断保护等机制合为一体的全新分布式服务,功能显而易见,在目前的开发市场中占据很大的优势,如何学习微服务,对程序员来说至关重要(学不会,可能饭碗不保!)springblade 是springcloude 的转化,也可以理解为加强版!,而且也是属于开源项目。我们首先需要再我们的github中下载一个源码
导入到我们的idea中;如下图所示:
执行doc包下边的sql文件:只需要执行后边两个就可以
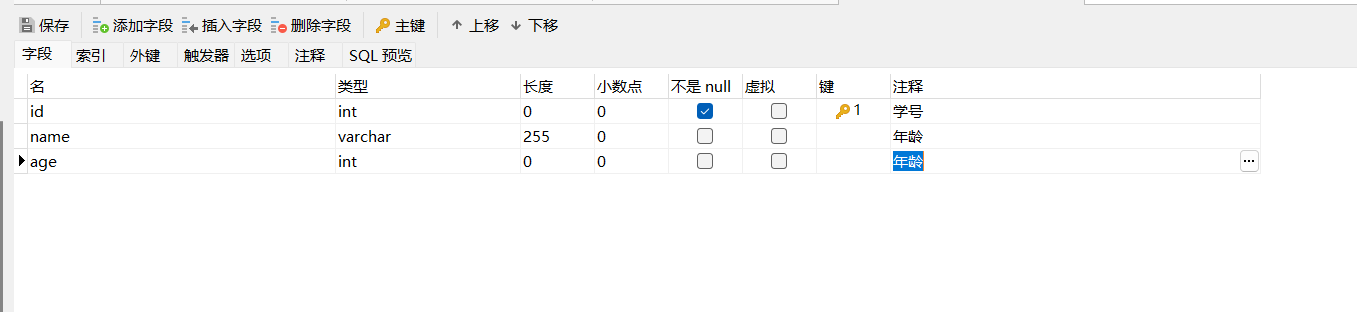
然后创建我们所需要生成的tb_student表:(这里注意我们的表名必须以tb_开头,不然生成配置过程中,会报错。)
这里千万不要忘记给我们的字段和表添加注释!
接下来再idea中创建我们的服务,
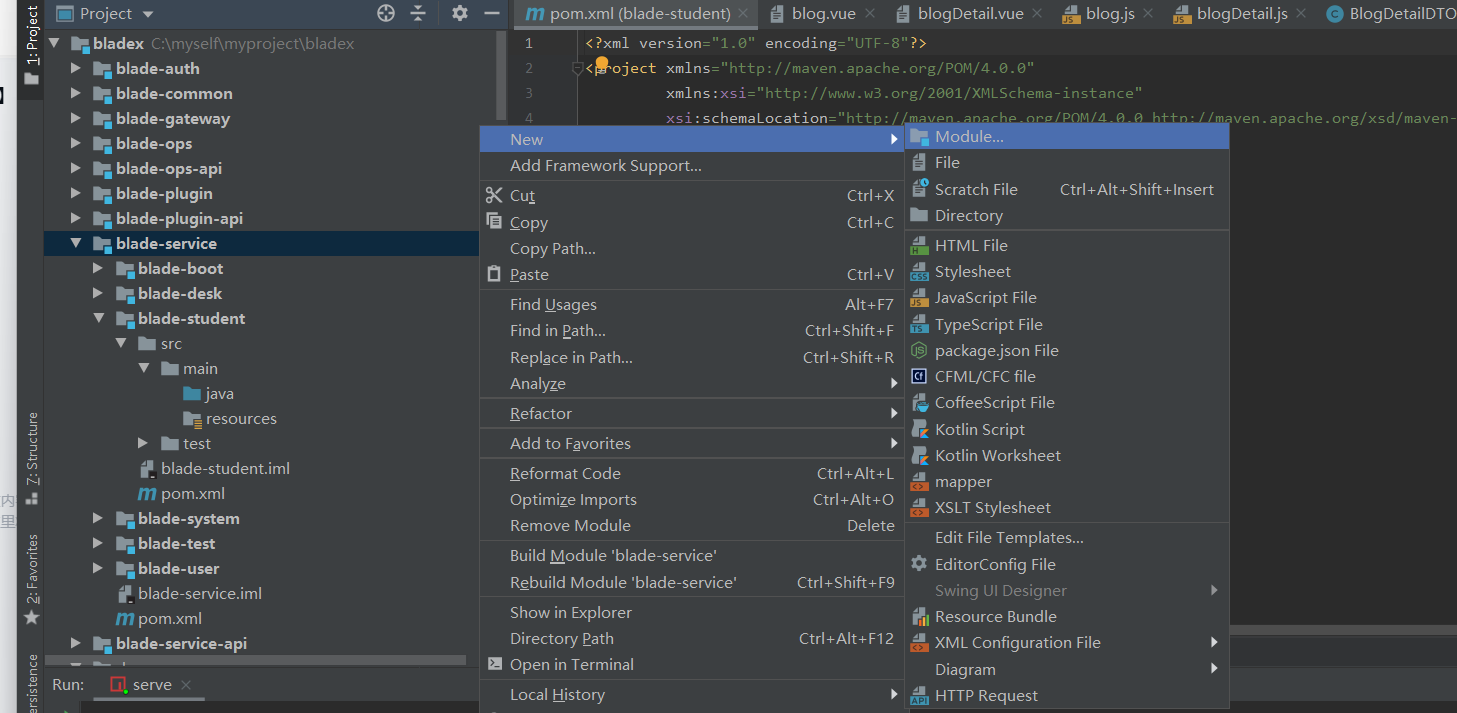
blade里边的微服务默认放到blade-service里边,再blade-service里边放上我们
环境准备方面(具体安装下载可以直接查找csdn,安装比较简单)
后端除了基本的环境设置外还需要准备:redeis 缓存
nacos 服务注册
sentinel 高可用流量控制(附加服务,可以不准备也行)
前端环境准备:node
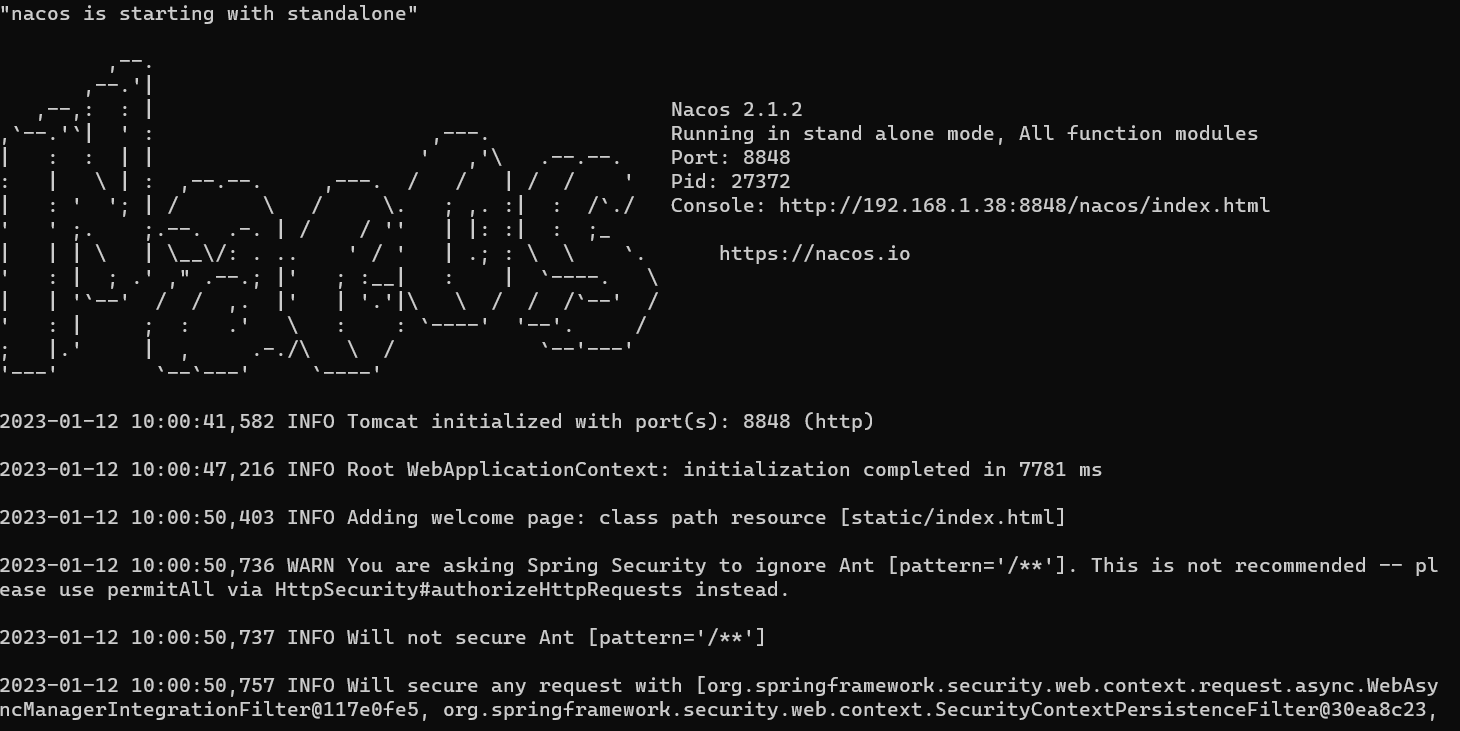
首先启动本地的nacos服务:双击安装好的nacos里边bin下的stratup,启动成功的样子如下图
然后启动我们的redis;后端环境部署完成之后就可以启动我们的项目了
首先,我们需要启动的基础项目为 下图所示:
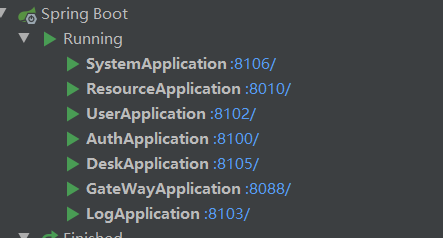
基础项目启动之后,我们是需要用到他的代码生成的,所以我们需要额外启动我们的blade-develop模块;启动之后所有服务如下图:
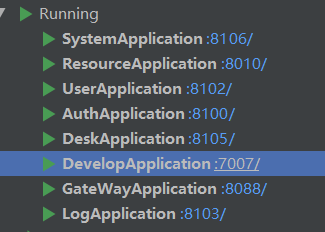
然后我们就可以启动我们的前端了,前端默认的网关地址为geteway的地址80端口:
启动前端
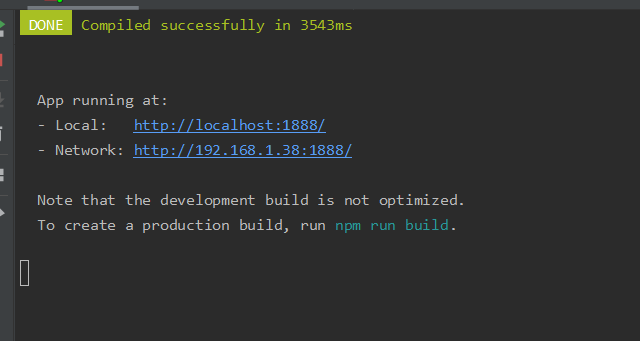
运行之后我们打开地址路径:
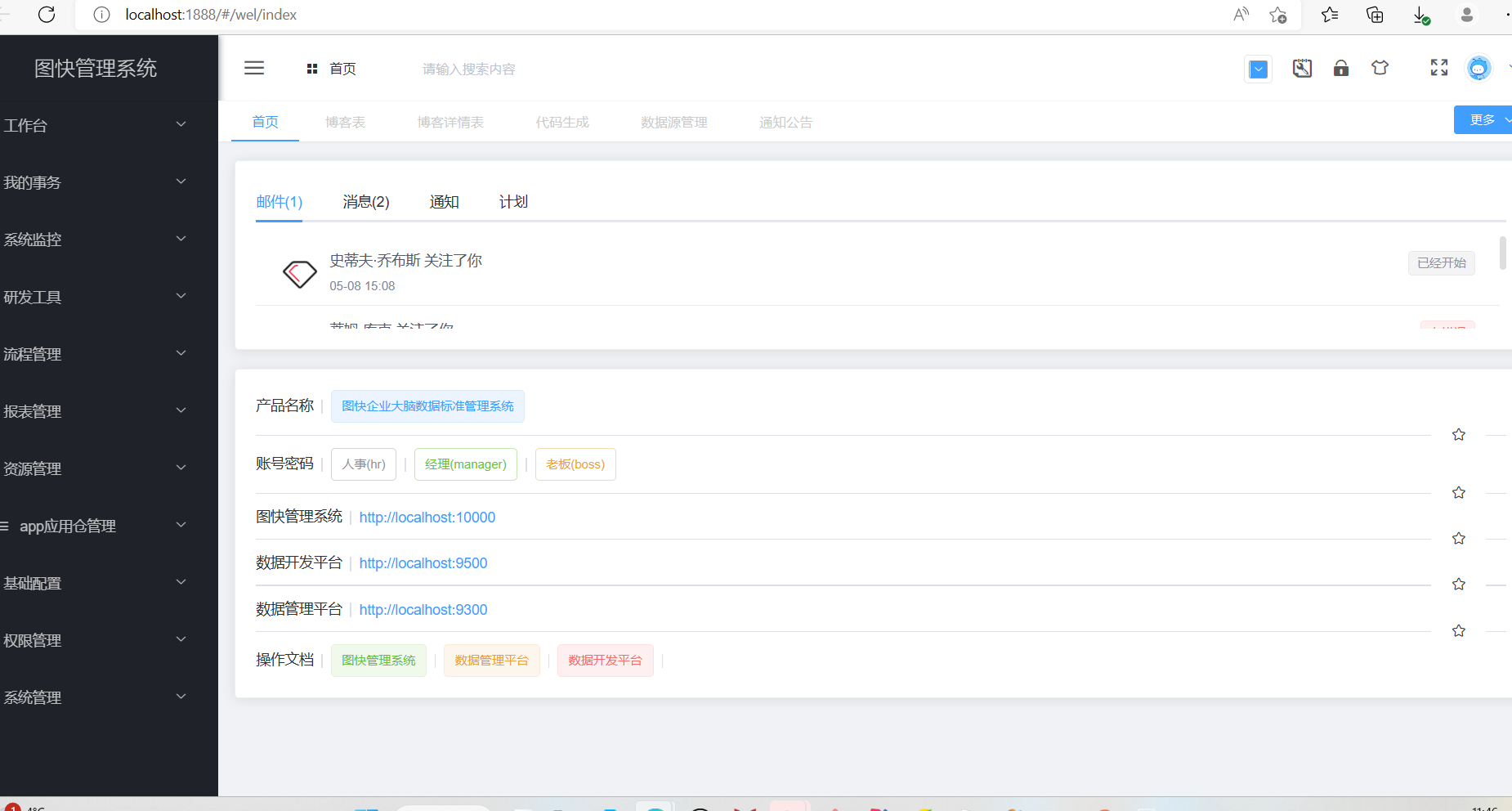
登录之后页面如下图所示:
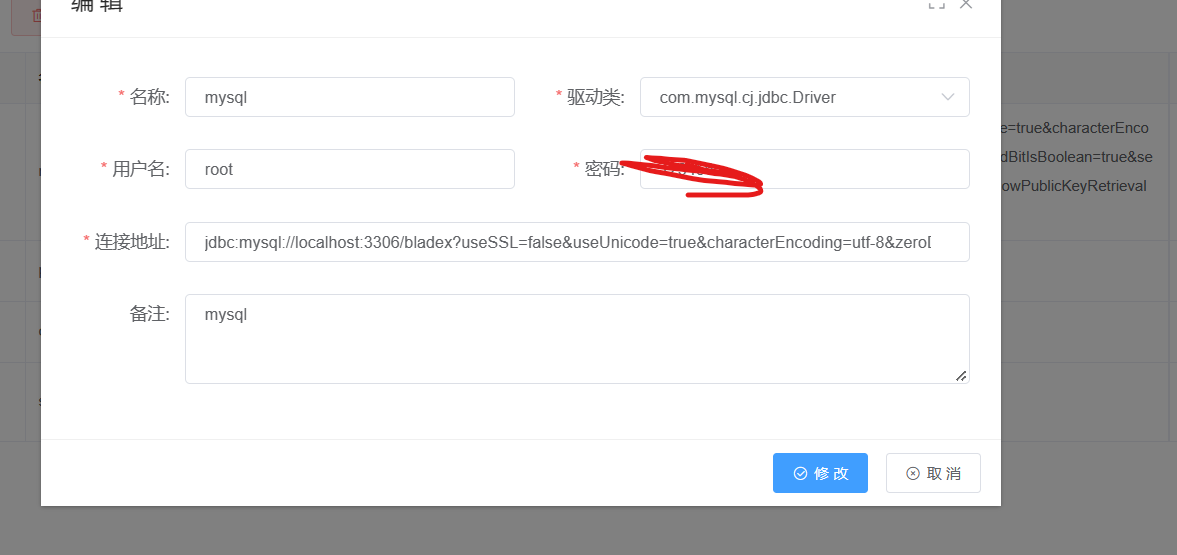
点击研发工具 里边的数据源管理:选择我们的使用的数据源,我这边使用的是mysql的数据源。
点击编辑:修改我们的mysql的账户跟密码
配置好数据源之后,我们点击数据模型设计,
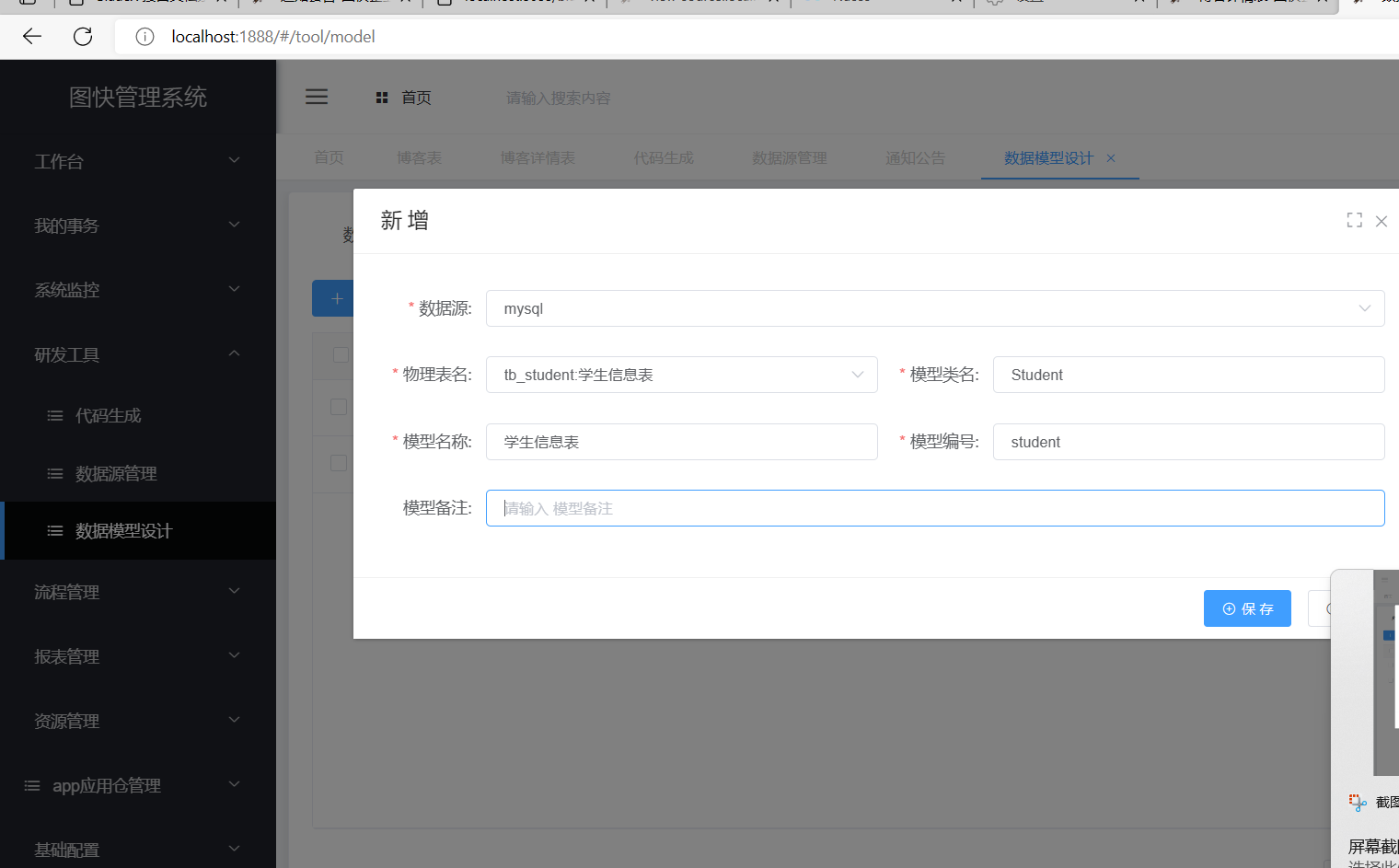
模型备注可以不写,如果添加的有备注,其它的必填项会自动生成;
然后点击研发工具里边的代码生成,点击新增,将我们刚才数据配置过的tb_student新增上去:
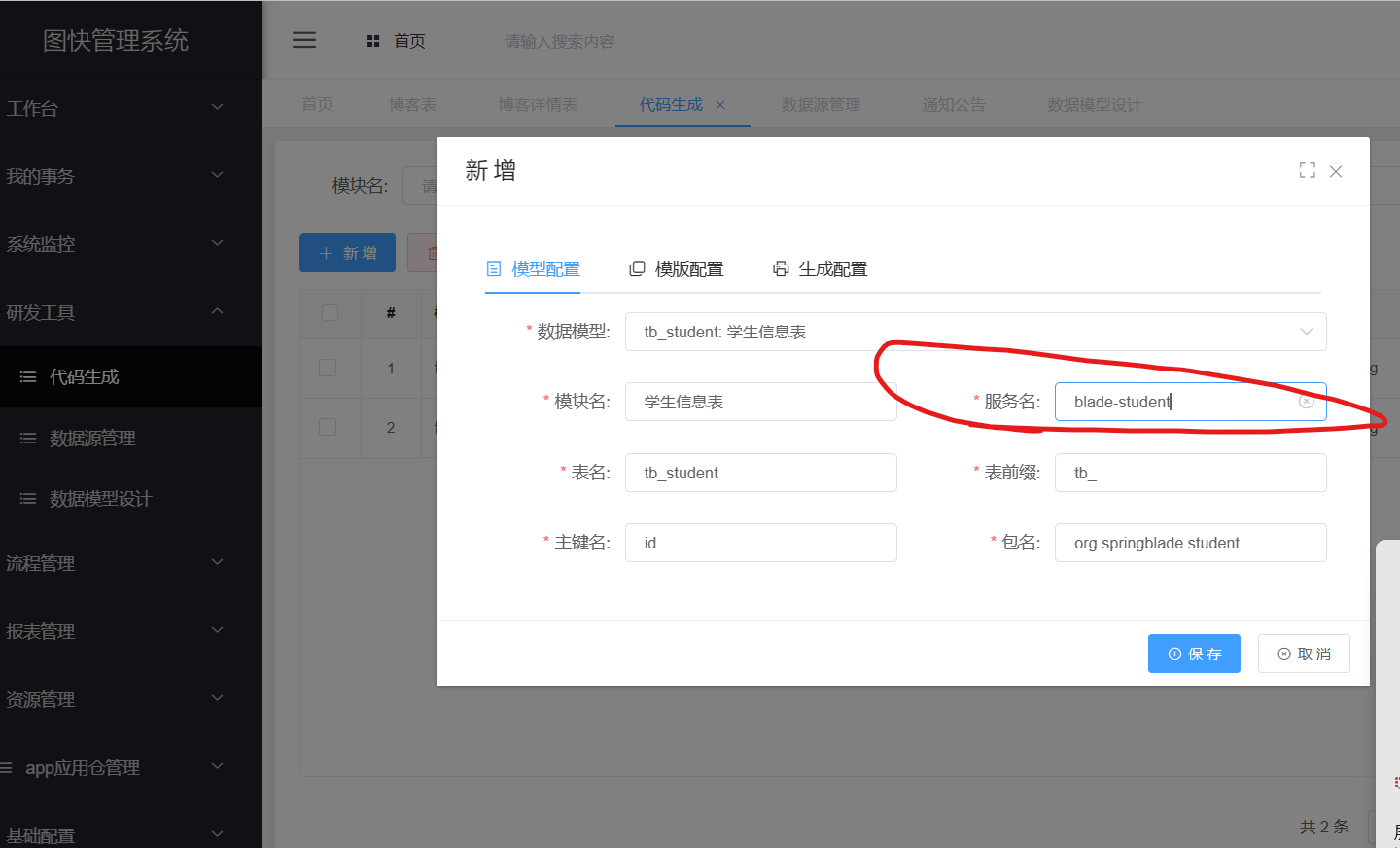
这里注意服务名,一定要给你创建的服务名保持一致,不要后边的方法测试会报404.因为blade默认是将项目名挡住服务名进行注册的;
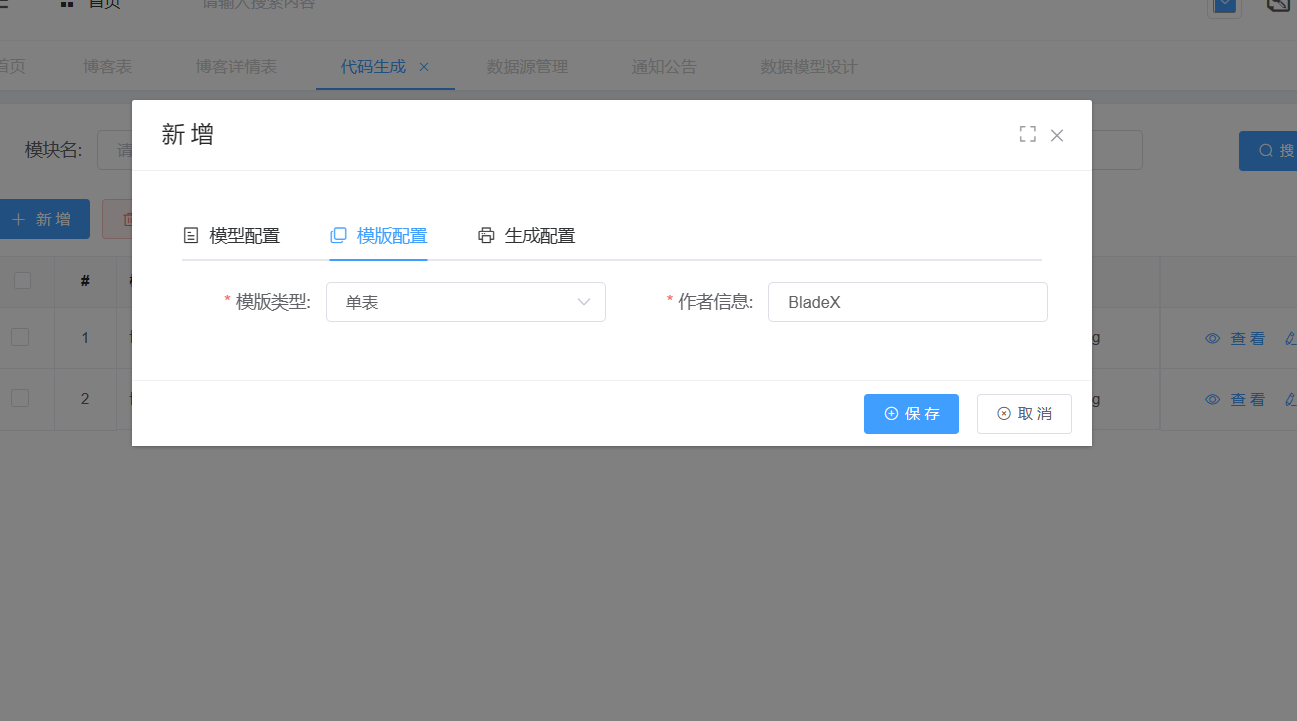
blade 加强了生成配置,可以直接将我们的代码直接放到我们所创建的服务上边;在我们的生成配置中可以直接设置路径;我们直接将我们创建好的项目的根路径地址填写上去;‘
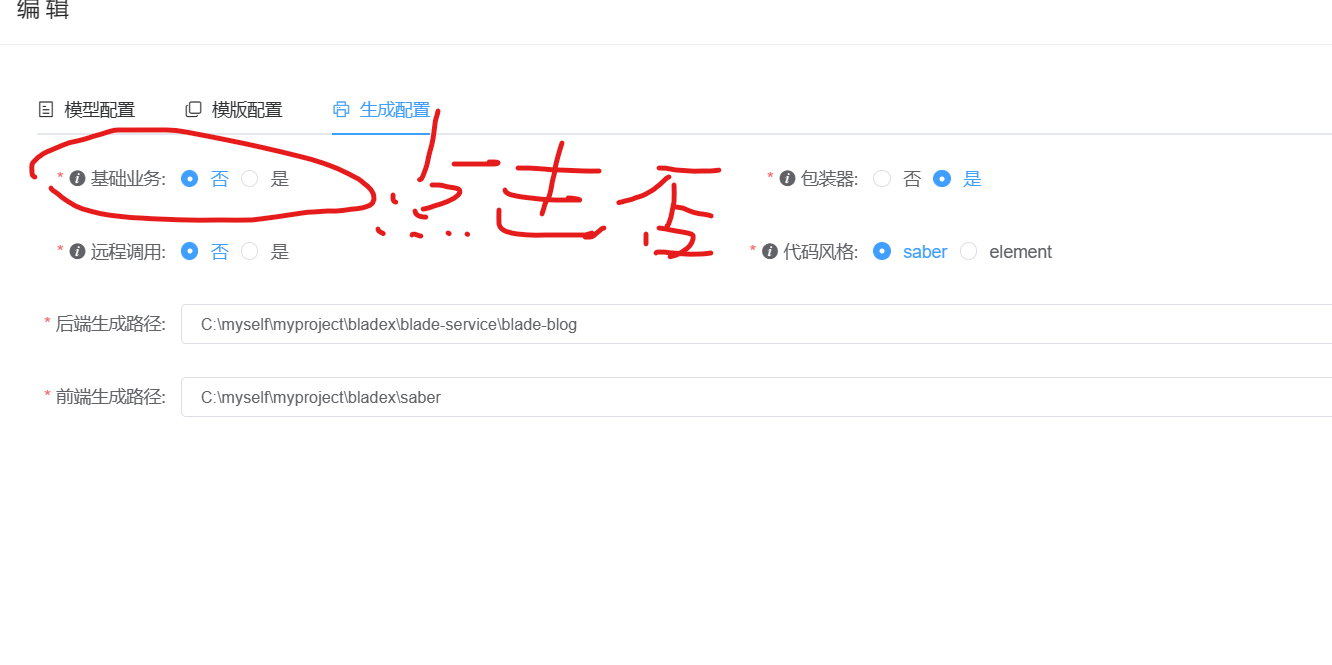
然后点击代码生成:
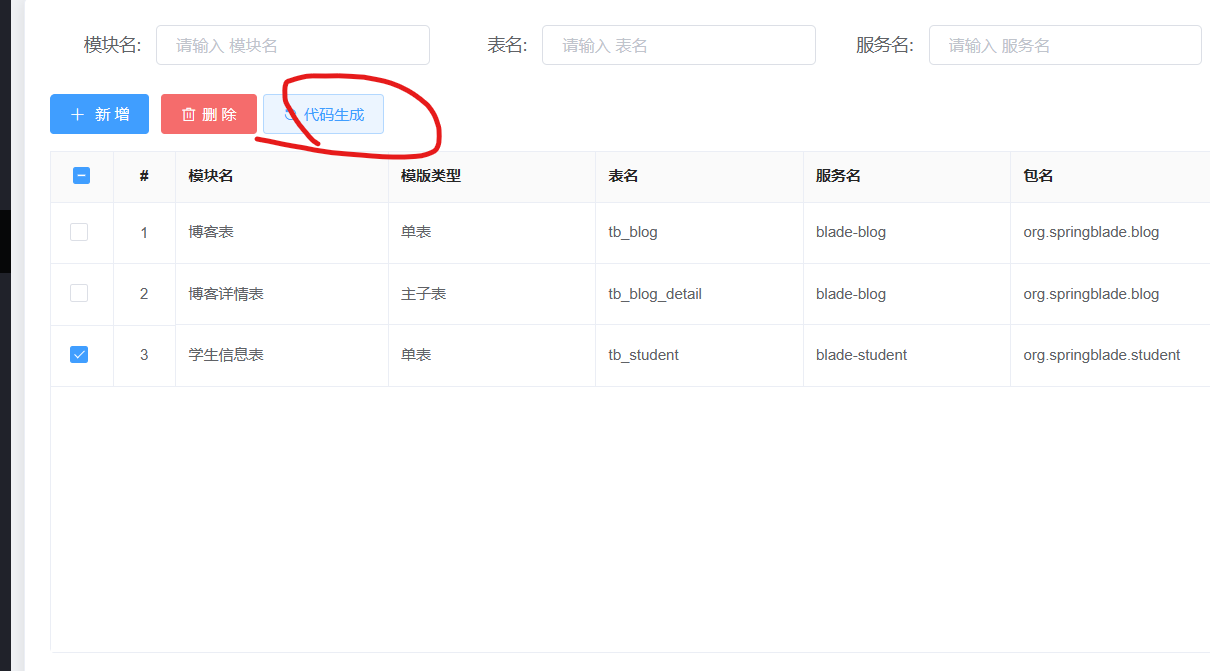
然后查看我们的idea中的前后端代码是否生成到指定的位置:
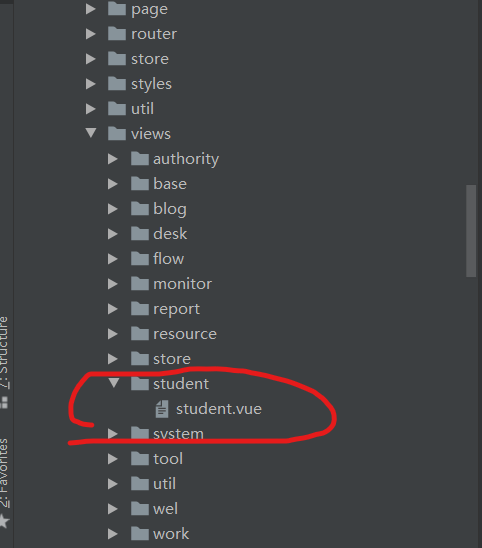
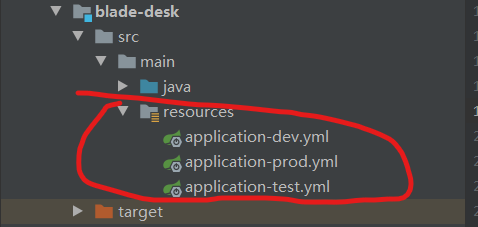
然后我们需要配置一下我们的resources;将blade-desk的resource文件直接复制到blade-student下,更改一下端口号
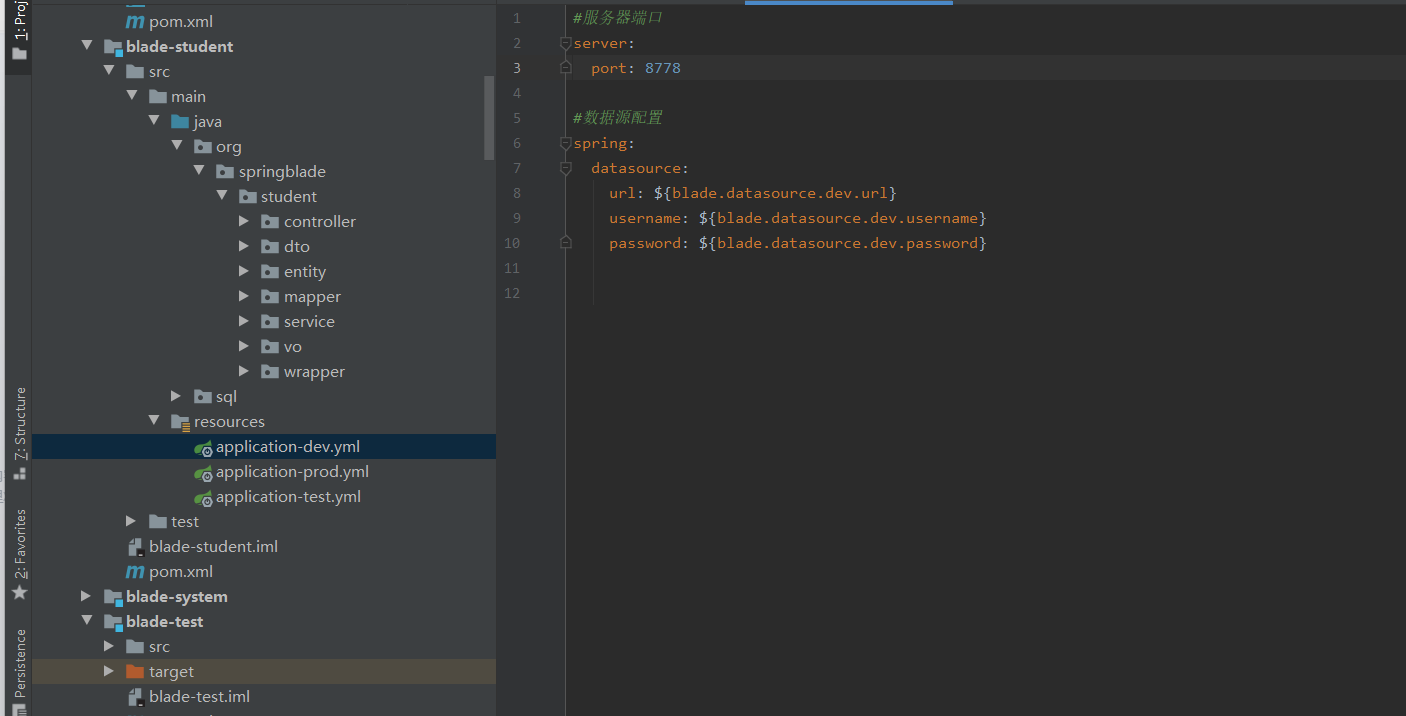
然后就是编写我们这个模块的启动类了,我们可以直接将blade-desk的启动类复制过来就可以;
具体启动类的代码如下:
/*
* Copyright (c) 2018-2028, Chill Zhuang All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
*
* Redistributions of source code must retain the above copyright notice,
* this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* Neither the name of the dreamlu.net developer nor the names of its
* contributors may be used to endorse or promote products derived from
* this software without specific prior written permission.
* Author: Chill 庄骞 (smallchill@163.com)
*/
package org.springblade.student;
import org.springblade.common.constant.LauncherConstant;
import org.springblade.core.cloud.client.BladeCloudApplication;
import org.springblade.core.launch.BladeApplication;
import org.springblade.core.launch.constant.AppConstant;
/**
* Desk启动器
*
* @author Chill
*/
@BladeCloudApplication
public class StudentApplication {
public static void main(String[] args) {
BladeApplication.run(LauncherConstant.APPLICATION_STUDENT_NAME, StudentApplication.class, args);
}
}
因为blade微服务中生成有聚合文档,所以我们可以直接调式直接在聚合文档中调试:(不需要再postman中进行调式了)
启动我们的blade-swagger服务前需要添加swagger依赖
具体的student依赖如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>blade-service</artifactId>
<groupId>org.springblade</groupId>
<version>3.0.1.RELEASE</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>blade-student</artifactId>
<name>${project.artifactId}</name>
<version>${bladex.project.version}</version>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>org.springblade</groupId>
<artifactId>blade-core-boot</artifactId>
</dependency>
<dependency>
<groupId>org.springblade</groupId>
<artifactId>blade-starter-excel</artifactId>
</dependency>
<dependency>
<groupId>org.springblade</groupId>
<artifactId>blade-starter-swagger</artifactId>
</dependency>
<dependency>
<groupId>org.springblade</groupId>
<artifactId>blade-system-api</artifactId>
<version>${bladex.project.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>com.spotify</groupId>
<artifactId>dockerfile-maven-plugin</artifactId>
<configuration>
<username>${docker.username}</username>
<password>${docker.password}</password>
<repository>${docker.registry.url}/${docker.namespace}/${project.artifactId}</repository>
<tag>${project.version}</tag>
<useMavenSettingsForAuth>true</useMavenSettingsForAuth>
<buildArgs>
<JAR_FILE>target/${project.build.finalName}.jar</JAR_FILE>
</buildArgs>
<skip>false</skip>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-antrun-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
添加好依赖之后我们需要将我们的student模块配置到我们的swagger文档当中:
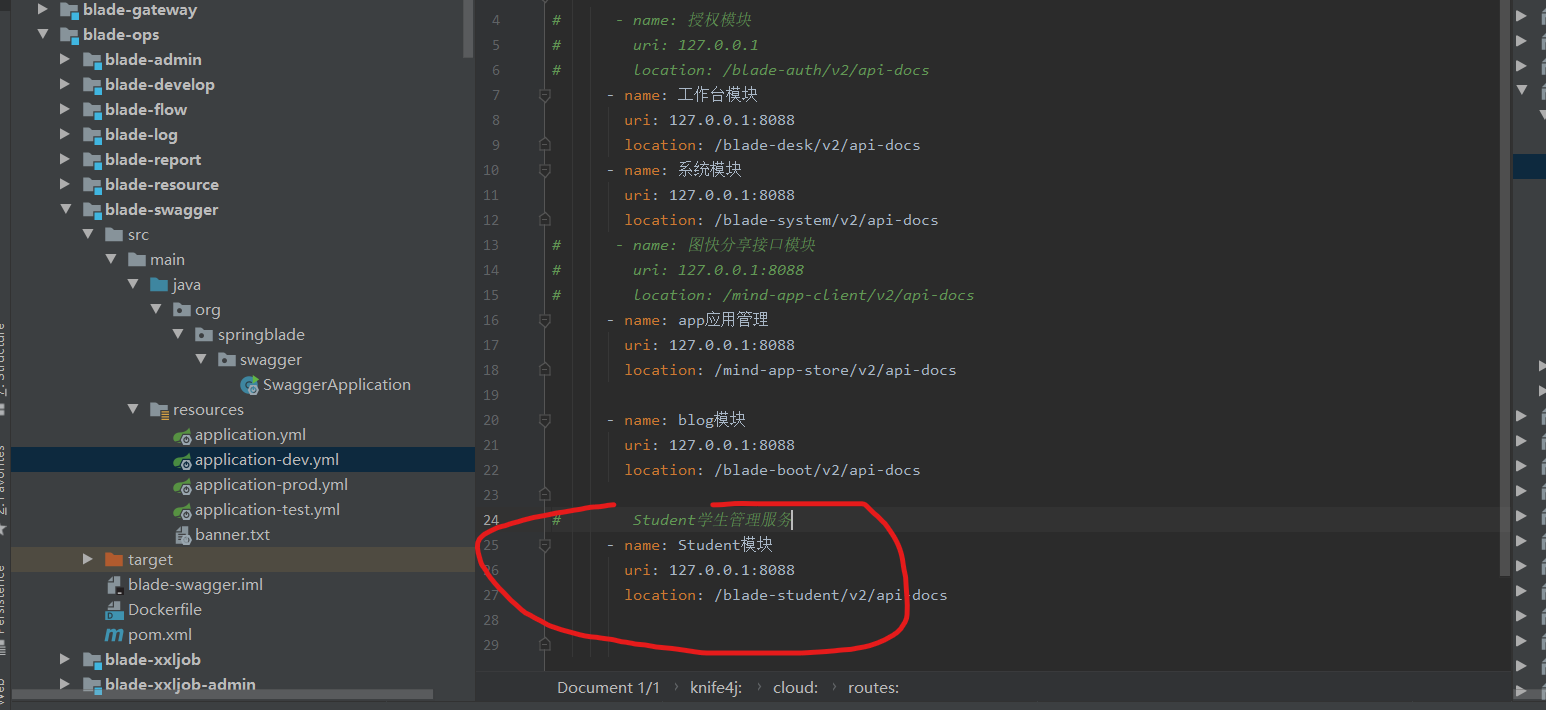
然后配置好之后先启动我们的blade-student,然后启动我们的blade-swagger;
swagger聚合文档的访问地址为http://localhost:18000/doc.html#/home
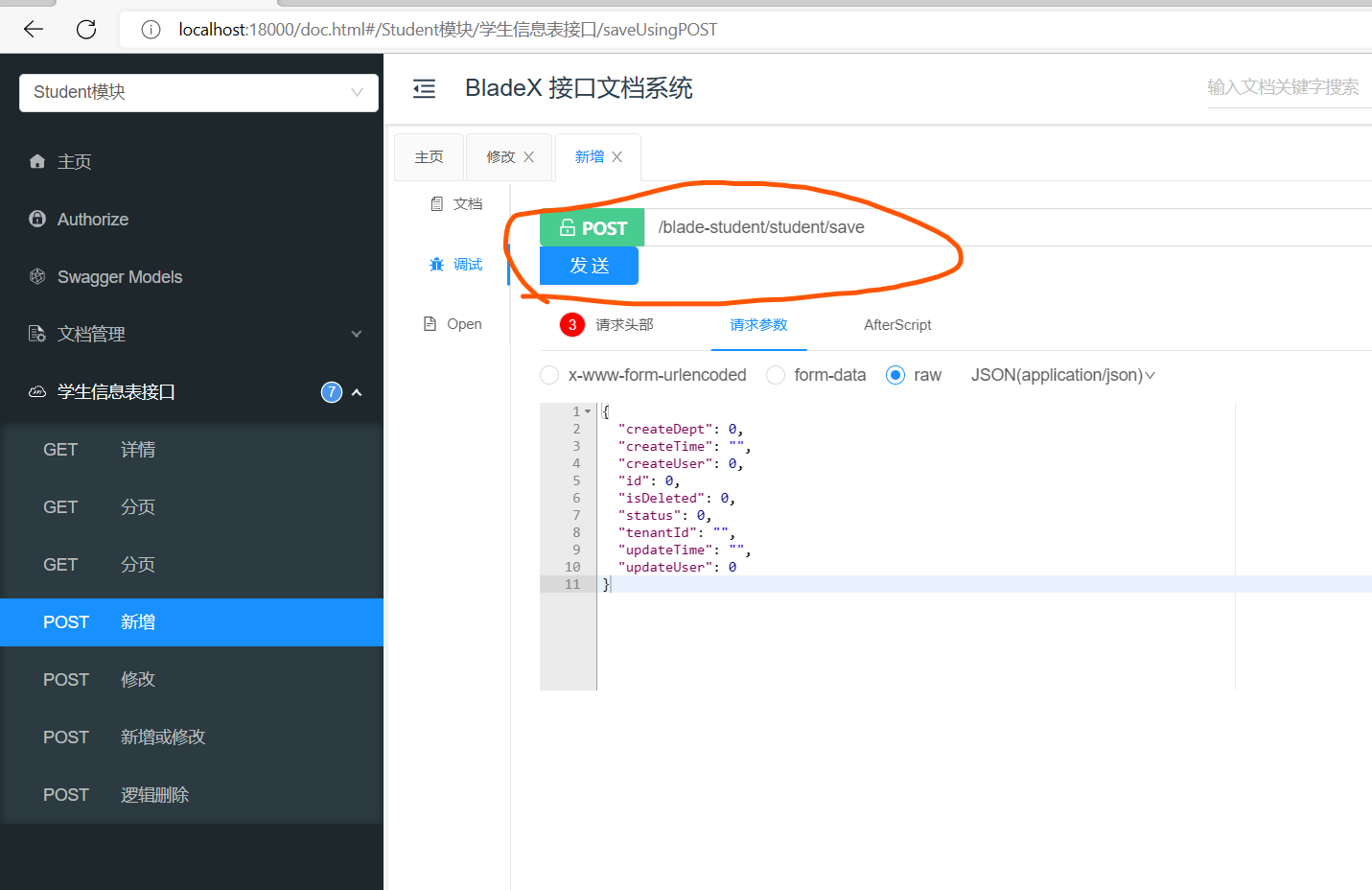
在模块中选择我们的student模块试下方法能否正常访问:点击新增方法的发送:
这样我们的微服务就创建完成了:
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el