何为NC文件,如何读取,如何批量转为TIFF(ArcGIS/MATLAB)
文章目录
相信有好多遥感、地信、地理的同学经常会用到全球月均降水数据/气温等数据,而该类数据常以NC文件保存,大家拿到手后常常会迷惑,这是一种什么数据格式,如何读取,又如何转为我们熟悉的栅格数据。今天来为大家答疑解惑。
NetCDF全称为network Common Data Format,中文译法为“网络通用数据格式”;netcdf文件开始的目的是用于存储气象科学中的数据,现在已经成为许多数据采集软件的生成文件的格式。
一个Netcdf文件的结构包括以下对象:
● 变量(Variables) :变量对应着真实的物理数据;
● 维(dimension):一个维对应着函数中的某个自变量,或者说函数图象中的一个坐标轴;
● 属性(Attribute) :属性是对变量值和维的具体物理含义进行注释。
从数学上来说,netcdf存储的数据就是一个多自变量的单值函数。用公式来说就是f(x,y,z,…)=value;
●自变量x,y,z等在netcdf中叫做维(dimension) 或坐标轴(axix);
●value在netcdf中叫做变量(Variables)。
使用MATLAB查看
●使用函数ncdisp
使用方法:
ncFilePath = [‘E:\个人文档1\项目\数据\2000-2020_tmp\tmp_2000_2002.nc’]; %设定NC路径
ncdisp(ncFilePath);
●读取结果
以下为该NC文件的结构,包含类型、维度、和变量;其中变量中又含有经度、纬度、时间、pre(这也就是我们需要的变量);
我们可以形象的理解为:经纬度是它的平面坐标,时间是它的维度,构成一个三维空矩阵,然后将pre分别填充到该矩阵中,就形成了这样的一个数据结构。
●注意:进行这一步操作,直白点就是看它的数据结构以及该文件的介绍,其次是为了确定维度和变量的名称,后续需要用到。
这里例如,经度的名称为lon,纬度的为lat,时间为time,变量为tmp.

这里分为两个软件来讲解,arcgis带有读取NC文件功能,但是仅能读取单个文件,如果数量够多,无疑消耗大量的时间,这里我们使用MATLAB进行批量读取并转换为TIFF。
1.打开ArcGIS,点击工具箱,找到多维工具,点击下方的创建NetCDF栅格图层。
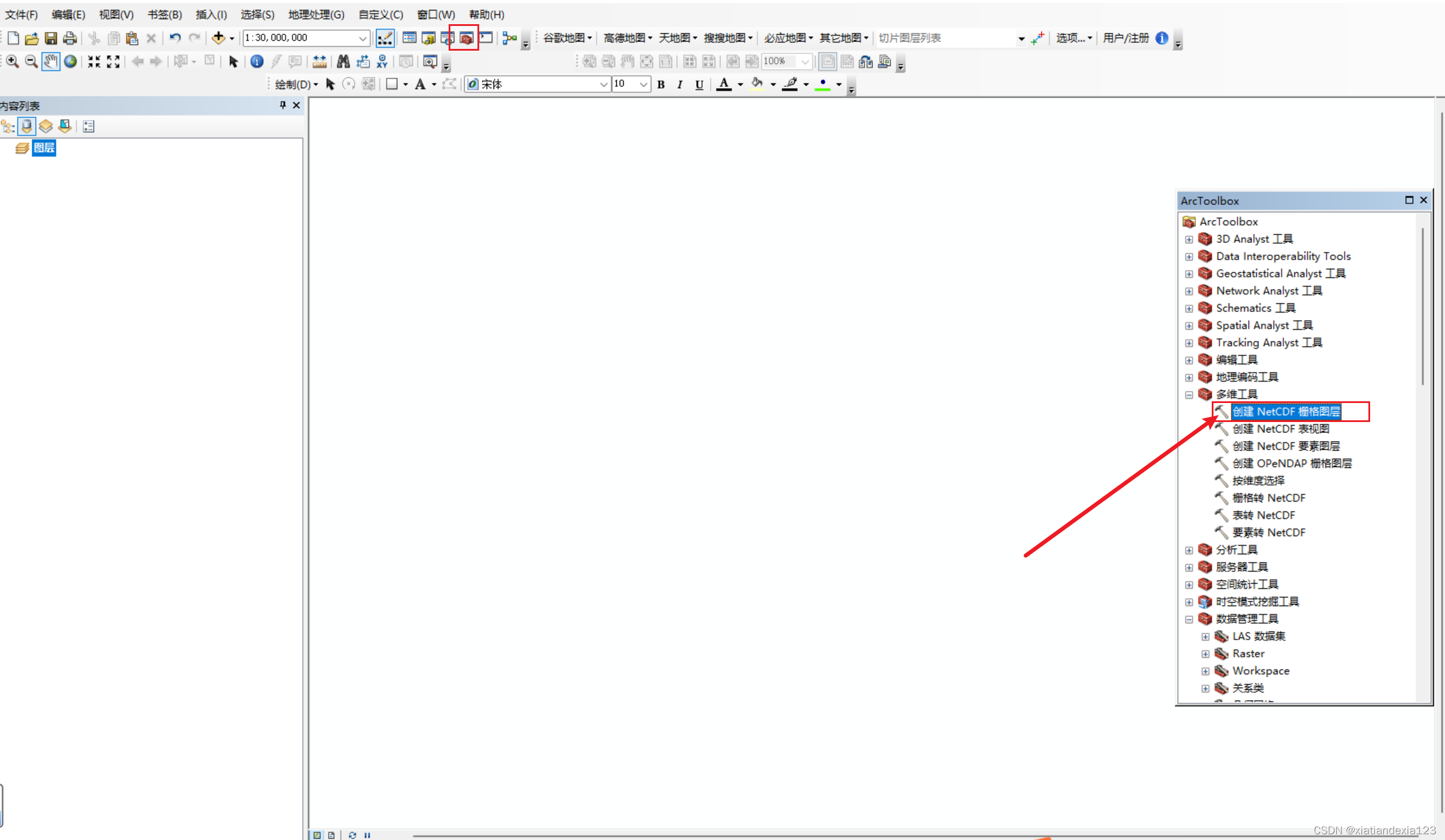
2.弹出如下界面,输入netCDF文件,然后会自动加载如下变量,维度值可以选择time,然后在下面的表格time后面的值中填入相应的日期,即可加载你想读取的NC中某一时间维度的数据,不进行处理的话默认加载维度的第一个值。然后点击确认。
注意:注意该路径不能含有中文,否则不能自动加载以下变量,而且会报错。
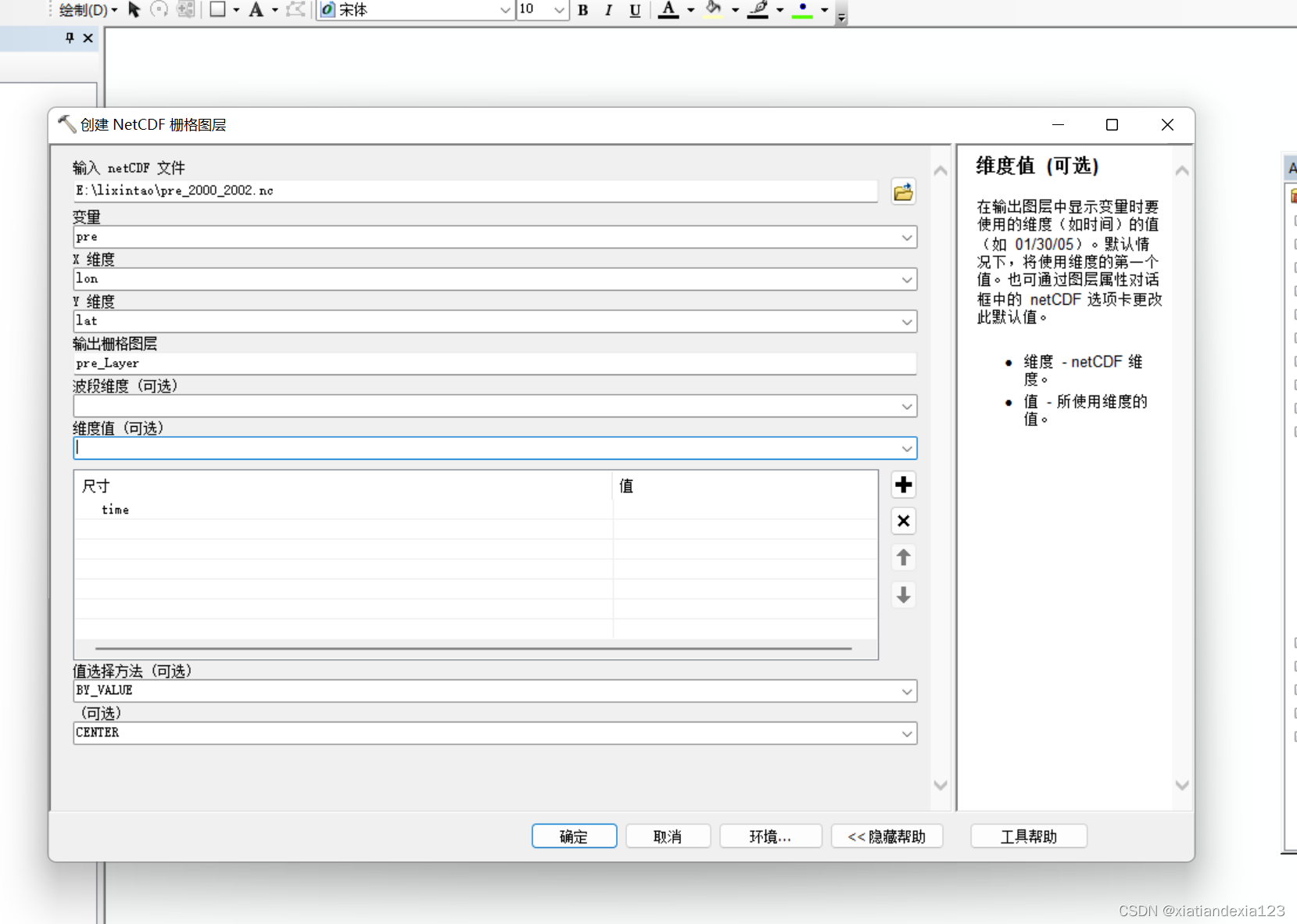
- 结果如下,即读取成功,保存栅格图层即可。
注意:但是这种方法只能导出一个时间点的栅格数据,nc一般都是多维度时间,那如何批量导出呢?接着看下面。

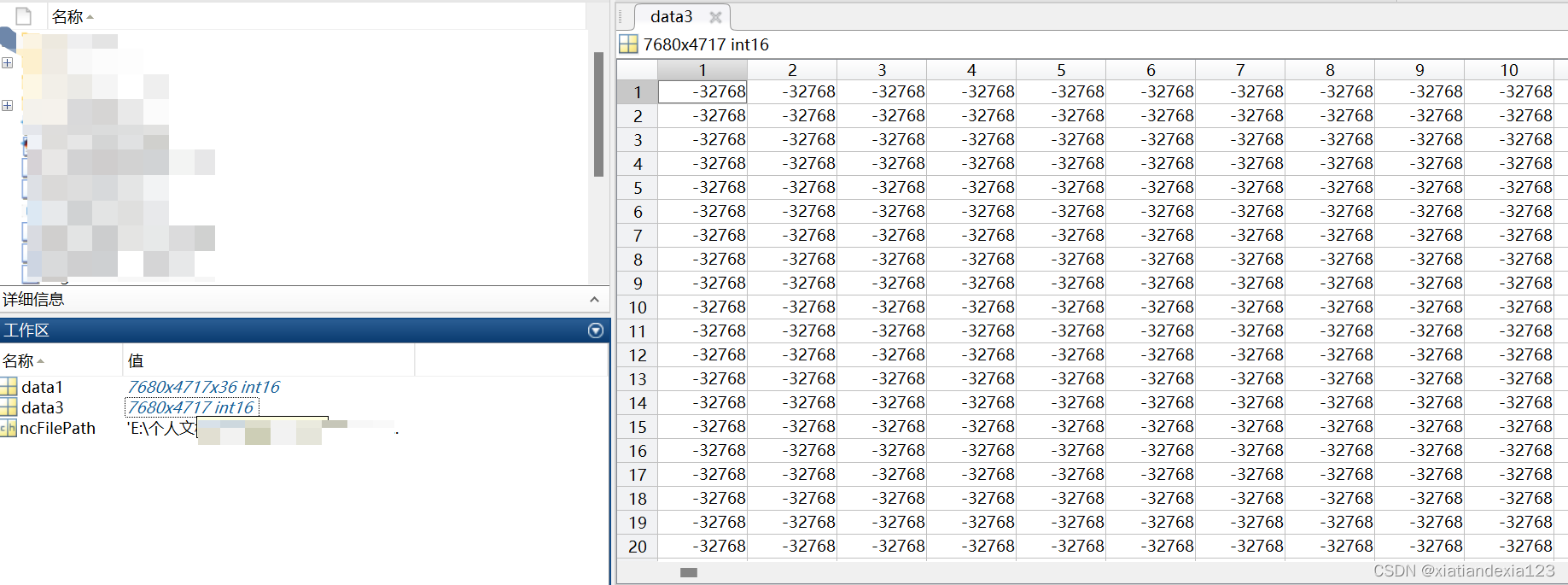
- 先读取任意一组维度的数据来看看,使用一下代码。设置一下自己的路径
clc
clear
ncFilePath = ['E:\个人文档1\项目\数据\2000-2020_tmp\tmp_2000_2002.nc']; %设定NC路径
ncdisp(ncFilePath); %查看NC结构
data1=ncread(ncFilePath,'tmp'); 读取NC文件中的变量,注意要设置正确的变量名,该数据集变量名为tmp,怎么查看,参考上文开始的讲解
data3=data1(:,:,1); %读取该数据集维度中的第1个时间序列数据
- 结果如下所示:可以发现data1显示7680471736,前面两个也就是我们说的经纬度,后面36也就是时间序列(该NC含3年数据,3*12月=36月),data3就是读取的2000年1月份的tmp数据。
- 显示data3。选择data3,点击绘图工具,选择imagesc显示该数据,炸一看有点奇怪,仔细一看是一个鸡的形状(中国),但是它是显示的方向不对。应该先逆时针旋转90°,再镜像一下(翻转)。
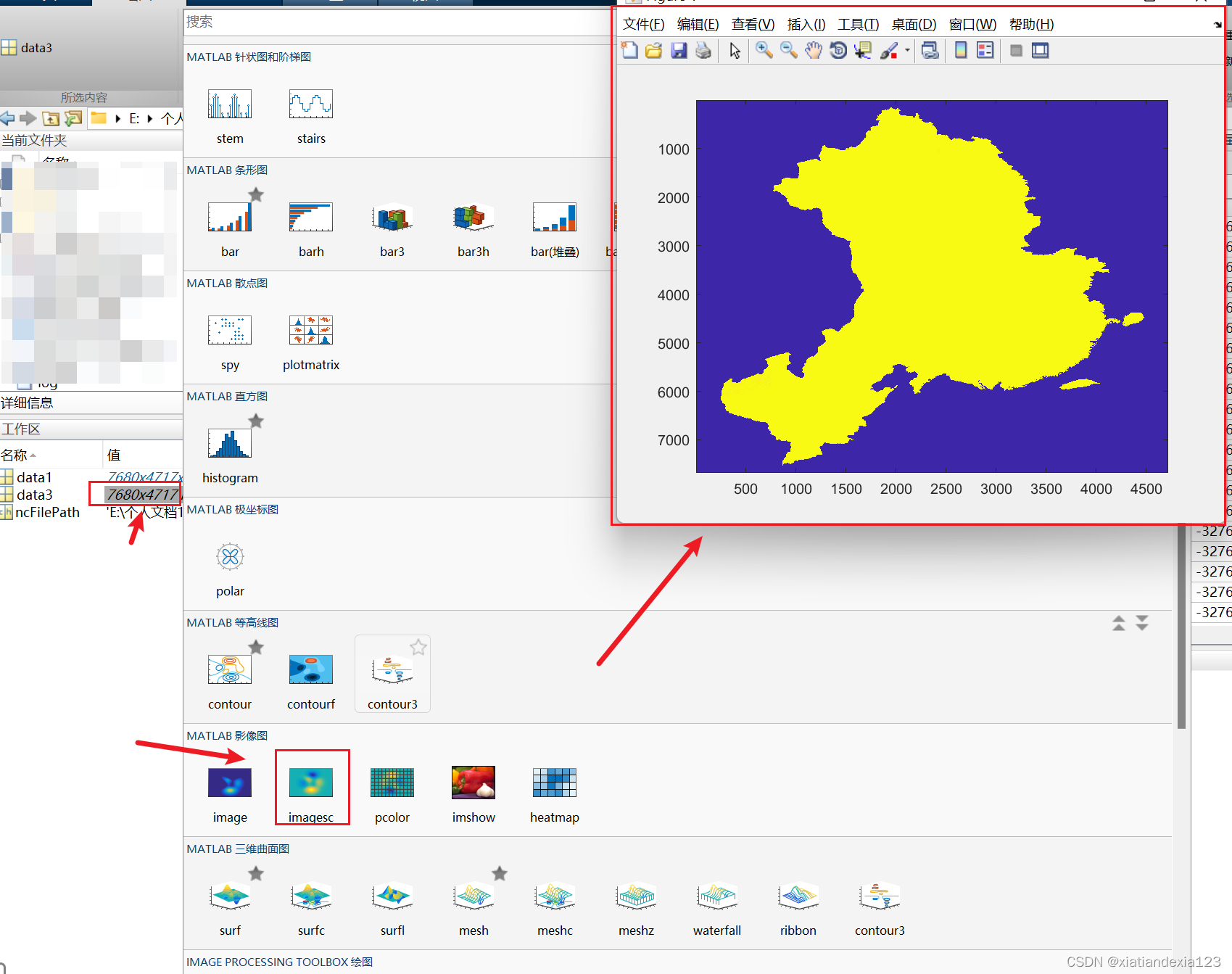
- 我们加上如下代码,一个是逆时针,一个是翻转。发现中国地形正常了。
data4=rot90(data3); %逆时针旋转90°
data5=flipud(data4); %矩阵的翻转
imagesc(data5);

- MATLAB中将数据保存成TIFF格式牵扯到地理坐标系的问题。两种做法:一是利用Matlab中的georasterref函数来创建tif的地理坐标系,二是读取一个现成tiff文件,当做参考地理坐标系。由于第一种方法可能会出现偏移或者出错,为了保证数据的准确性,我们使用第二种方法。
- 同第三节的Arcgis读取操作,先读取NC中的某一期数据。然后定义投影,投影操作如下。
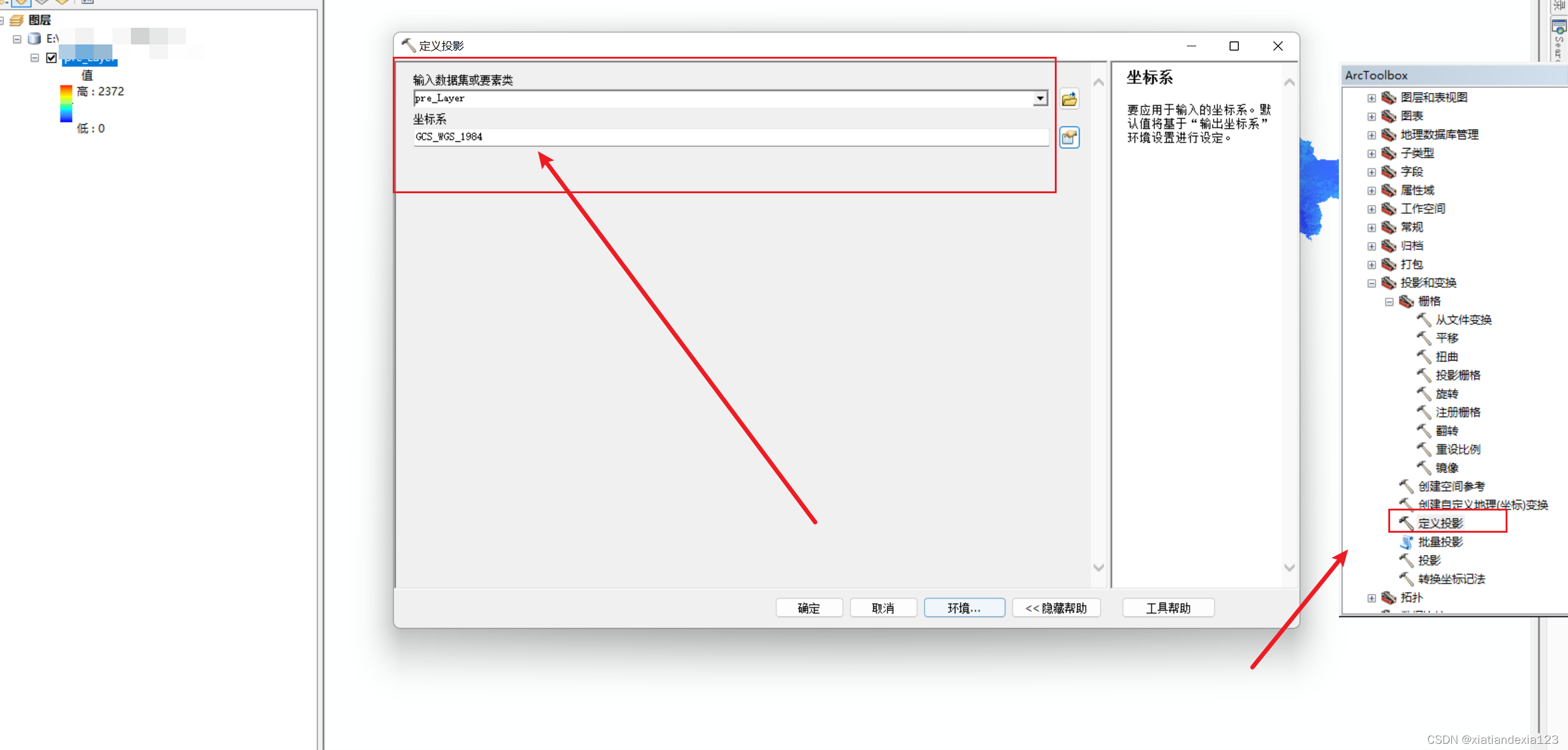
- 查看属性,如果空间参考中有坐标系,即定义成功,如果定义了后还是没有,进行下一步操作。
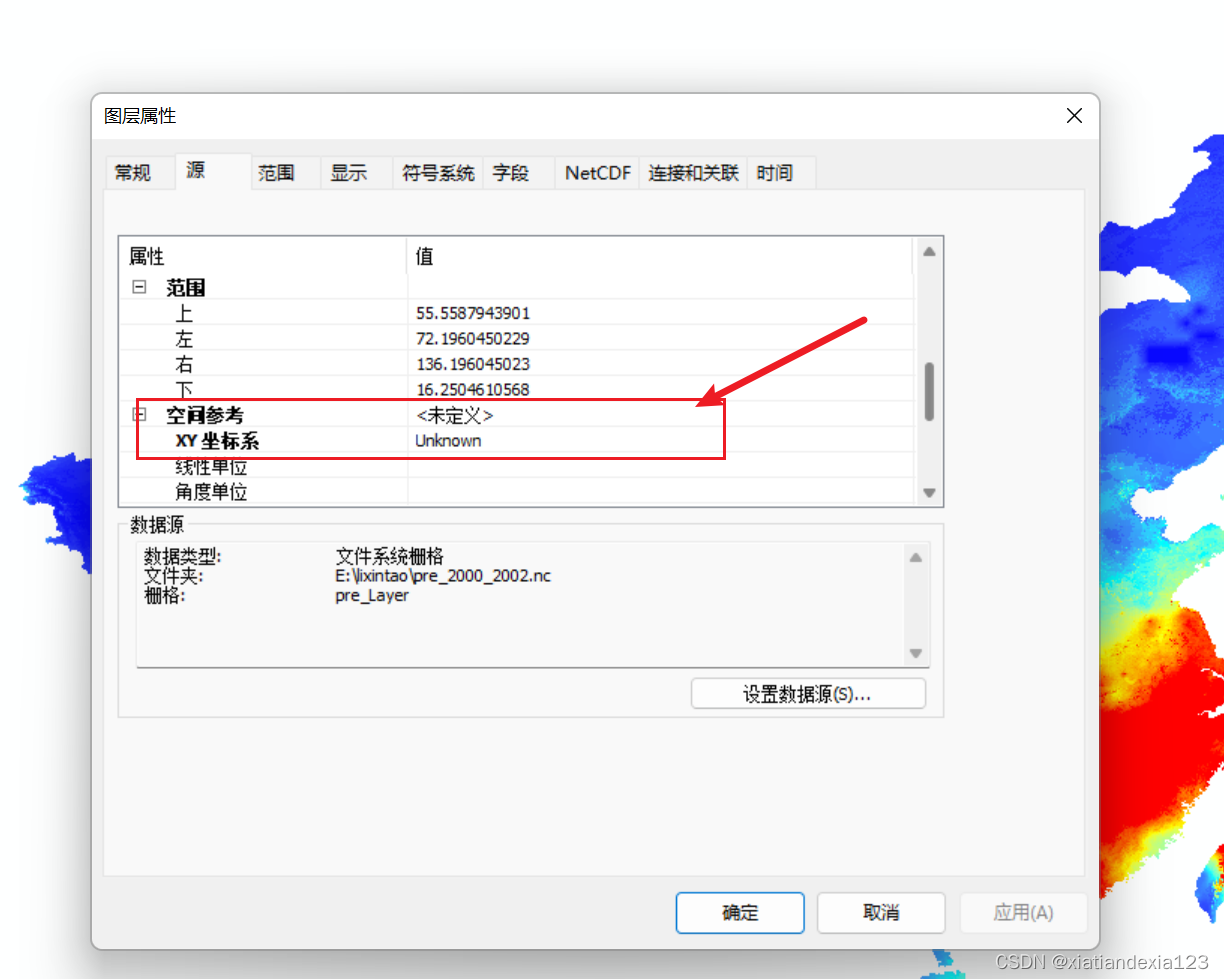
- 如图选中图层,右击选择属性,设定图层的坐标系。

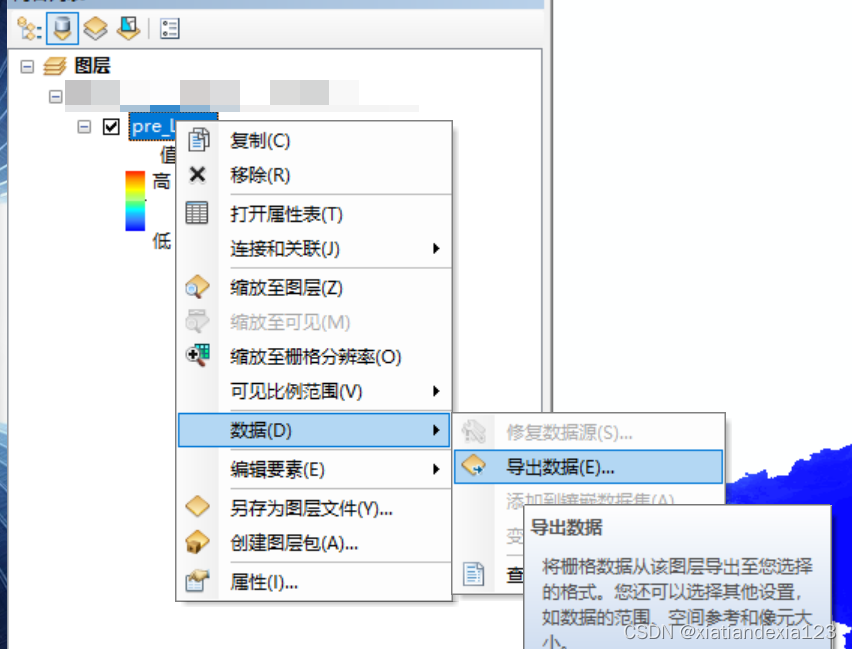
- 点击导出数据。将栅格数据集(原始)更改为数据框(当前),即可发现空间参考中有坐标系了,设置下保存路径,点击保存即可。
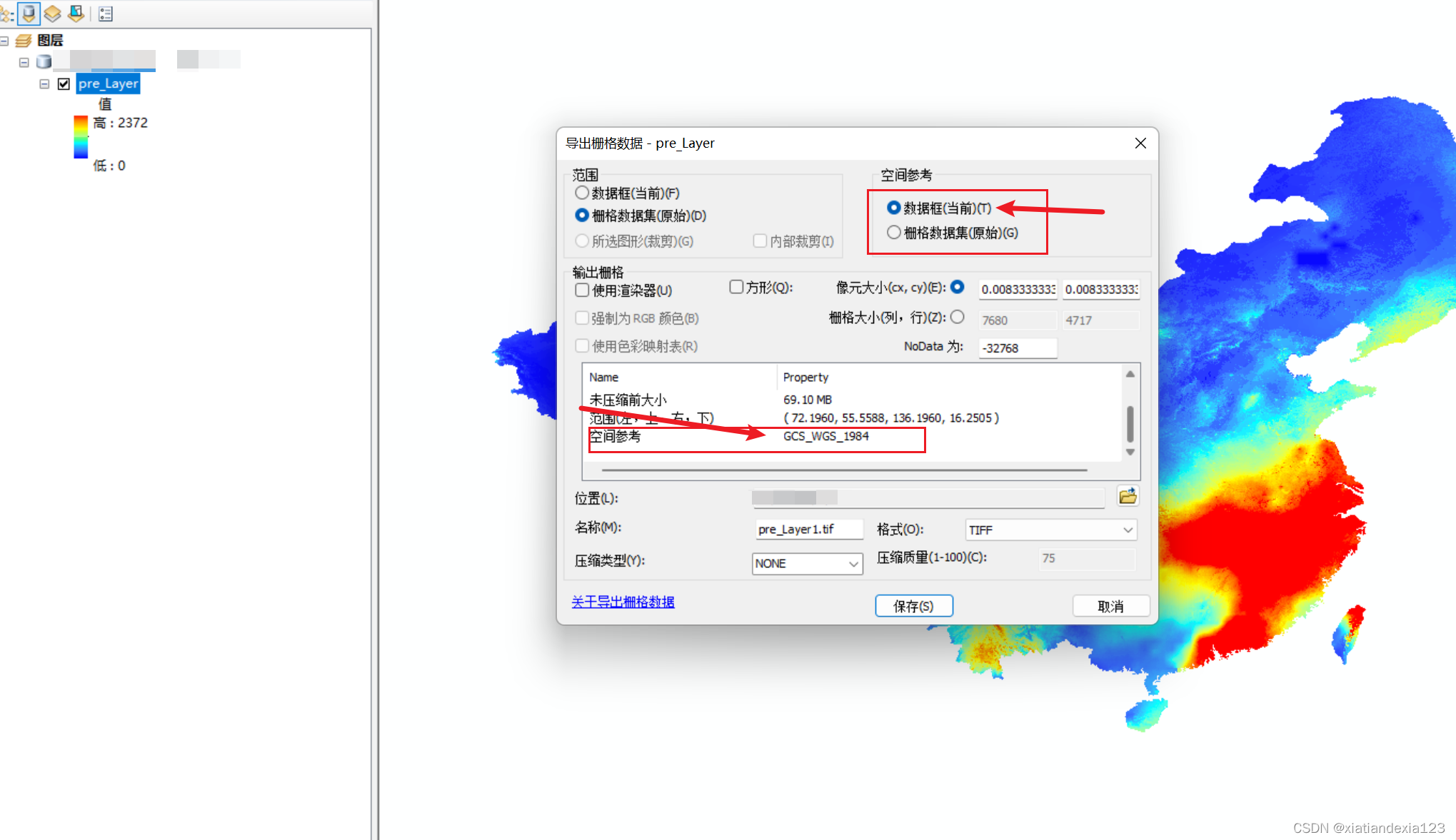
- 保存成功后结果如下所示。

1.废话不多说,直接上代码。将下面代码copy可直接用,需要调整的地方在文中已进行标注(需要调整),更改下文件路径即可,再有就是循环的地方,根据自己需求进行调整。
clc
clear
%% 导入NC数据集
ncFilePath = ['E:\个人文档1\项目数据\2000-2020_pre\2000-2020\pre_2020.nc']; %设定NC路径**需要调整**
ncdisp(ncFilePath); %查看NC数据结构
%% 导入TIFF影像的坐标信息
[A,R]=geotiffread('E:\li\pre_2018.tif');%该处路径为上述Arcgis中导出带坐标系的TIFF文件**需要调整**
info=geotiffinfo('E:\li\pre_2018.tif'); %该处路径为上述Arcgis中导出带坐标系的TIFF文件 **需要调整**
%% 读取pre数据
data=ncread(ncFilePath,'pre');
%% 批量处理
for year=2000:2020 %年循环**需要调整**
data1=data(:,:,1+12*(year-2000):12*(year-1999)); %得到每年的12个月数据。注意,第一个减去的时间与循环的起始时间相同,第二个减去的时间在起始时间的基础上减1。如该处的2000和1999。**需要调整**
data3=sum(data1,3)/12; %表示沿X轴的第3维求和,求年平均数据
data4=rot90(data3); %使矩阵逆时针旋转90°
data5=flipud(data4); %矩阵的翻转
filename=strcat('E:\个人文档1\项目\数据\NC_TO_TIFF\pre\year\中国',int2str(year),'年pre.tif'); %**需要调整**
geotiffwrite(filename,data5,R,'GeoKeyDirectoryTag',info.GeoTIFFTags.GeoKeyDirectoryTag);
for mon=1:12 %月循环
data2=data1(:,:,mon); %读取月数据
data4=rot90(data2);%使矩阵逆时针旋转90°
data5=flipud(data4); %矩阵的翻转
filename=strcat('E:\个人文档1\项目数据\NC_TO_TIFF\pre\month\中国',int2str(year),'_',int2str(mon),'月pre.tif'); **需要调整**
geotiffwrite(filename,data5,R,'GeoKeyDirectoryTag',info.GeoTIFFTags.GeoKeyDirectoryTag);
end
end
2.导出成功。
选取2000年1月份的结果,在ARCGIS中打开,发现数值在-32768-2339之间;在MATLAB中调出该期NC原始数据,提取最大最小值提取,可以发现和该数据99%接近,至于有细微的个位数误差,是由于将TIFF影像导入到ARcgis中进行了金字塔重采样。说明导出的结果是没问题的。

好了,以上就是本次讲解的内容了,希望能给大家带来帮助,有问题也欢迎在下方留言探讨。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信