Docker容器的本质是宿主机上的一个进程。Docker通过namespace实现了资源隔离,通过cgroups实现了资源限制,通过写时复制机制(copy-on-write)实现了高效的文件操作。
有了以上的隔离,我们认为一个容器可以与宿主机和其他容器是隔离开的。 恰巧Linux 的namespace可以做到这些。
| namespace | 隔离内容 | 系统调用参数 |
|---|---|---|
| UTS | 主机名与域名 | CLONE_NEWUTS |
| IPC | 信号量、消息队列和共享内存 | CLONE_NEWIPC |
| Network | 网络设备、网络栈、端口等 | CLONE_NEWNET |
| PID | 进程编号 | CLONE_NEWPID |
| Mount | 挂载点(文件系统) | CLONE_NEWNS |
| User | 用户和用户组 | CLONE_NEWUSER |
3.1、namespace的操作
3.2、clone()
3.3、/proc/[pid]/ns
用户可以在/proc/[pid]/ns文件下看到指向不同namespace的文件。
$ docker ps
$ docker exec -it host2-c10 hostname
# f057b4b03eb8就是docker ID
$ ps -ef|grep f057b4b03eb8
$ ls -l /proc/3571/ns
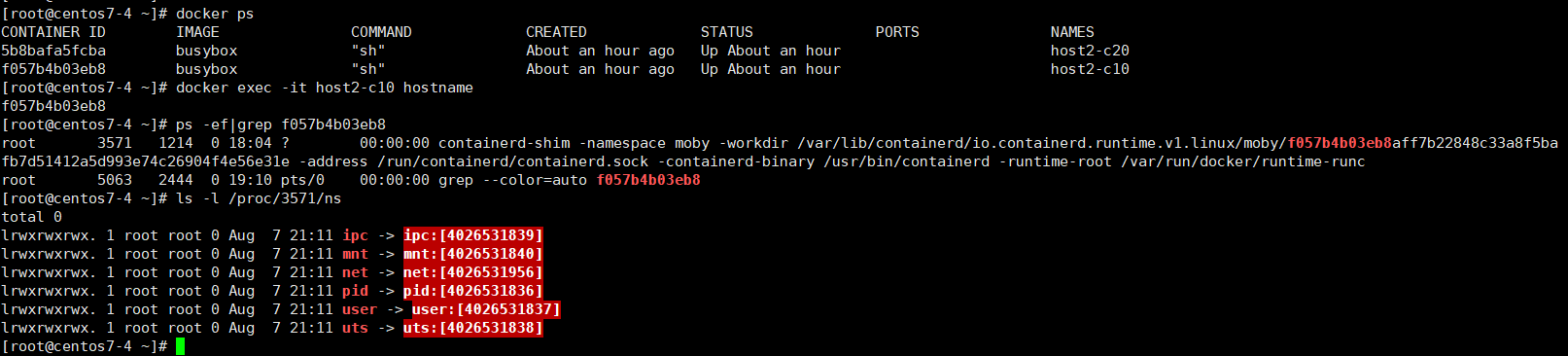
中括号内的为namespace号。如果两个进程指向的namespace号相同,那么说明它们在同一个namespace。
设置link的作用是,即便该namespace下的所有进程都已经结束,这个namespace也会一直存在,后续的进程可以加入进来。
3.4、setns()
int setns(int fd, in nstype);
#fd 表示要加入namespace的文件描述符。是一个指向/proc/[pid]/ns目录的文件描述符,打开目录链接可以获得
#nstype 调用者可以检查fd指向的namespace类型是否符合实际要求,该参数为0则不检查
为了把新加入的namespace利用起来,需要引入execve()系列函数,该函数可以执行用户命令,常用的就是调用/bin/bash并接受参数。
3.5、unshare()
3.6、fork() 系统调用
fork并不属于namespace的API
3.7、使用Namespace进行容器的隔离有什么缺点呢?
cgroups是Linux的另外一个强大的内核工具,有了cgroups,不仅可以限制被namespace隔离起来的资源,还可以为资源设置权重、计算使用量、操控任务(进程或县城)启停等。说白了就是:cgroups可以限制、记录任务组所使用的物理资源(包括CPU,Memory,IO等),是构建Docker等一系列虚拟化管理工具的基石。
$ ls -l /sys/fs/cgroup/*/docker -d
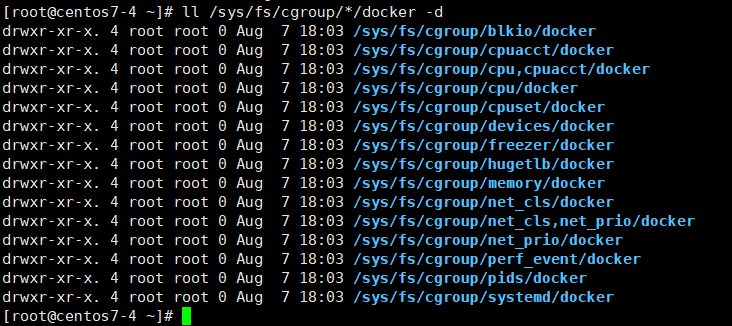
cpu 子系统,主要限制进程的 cpu 使用率。
cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告。
cpuset 子系统,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
memory 子系统,可以限制进程的 memory 使用量。
blkio 子系统,可以限制进程的块设备 io。
devices 子系统,可以控制进程能够访问某些设备。
net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
freezer 子系统,可以挂起或者恢复 cgroups 中的进程。
ns 子系统,可以使不同 cgroups 下面的进程使用不同的 namespace。
cgroups可以对任务使用的资源(内存,CPU,磁盘等资源)总额进行限制。
如 设定应用运行时使用的内存上限,一旦超过配额就发出OOM提示
通过分配的CPU时间片数量以及磁盘IO带宽大小,实际上就相当于控制了任务运行的优先级
cgroups可以统计系统的资源使用量
如CPU使用时长,内存用量等,这个功能非常适用于计费
cgroups 可以对任务进行挂起、恢复等操作
使用Dockerfile来创建一个基于Centos的stress工具镜像
$ mkdir -p /opt/stress
$ vi /opt/stress/Dockerfile
FROM centos:7
MAINTAINER chen "liugp@tom.com"
RUN yum install -y wget
RUN wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
RUN yum install -y stress
新建镜像
$ cd /opt/stress/
$ docker build -t centos:stress .
CPU 限制相关参数
| 选项 | 描述 |
|---|---|
| --cpuset-cpus="" | 允许使用的 CPU 集,值可以为 0-3,0,1 |
| -c,--cpu-shares=0 | CPU 共享权值(相对权重) |
| cpu-period=0 | 限制 CPU CFS 的周期,范围从 100ms~1s,即[1000, 1000000] |
| --cpu-quota=0 | 限制 CPU CFS 配额,必须不小于1ms,即 >= 1000 |
| --cpuset-mems="" | 允许在上执行的内存节点(MEMs),只对 NUMA 系统有效 |
其中--cpuset-cpus用于设置容器可以使用的 vCPU 核。-c,--cpu-shares用于设置多个容器竞争 CPU 时,各个容器相对能分配到的 CPU 时间比例。--cpu-period和--cpu-quata用于绝对设置容器能使用 CPU 时间。
1)创建容器的CPU权重控制
创建两个容器,分别制定不同的权重比
# --cpu-shares 指定使用cpu的权重
# stress -c 指定产生子进程的个数
$ docker run -itd --name cpu512 --cpu-shares 512 centos:stress stress -c 10
$ docker run -itd --name cpu1024 --cpu-shares 1024 centos:stress stress -c 10
# 查看
$ docker exec -it cpu512 top
$ docker exec -it cpu1024 top
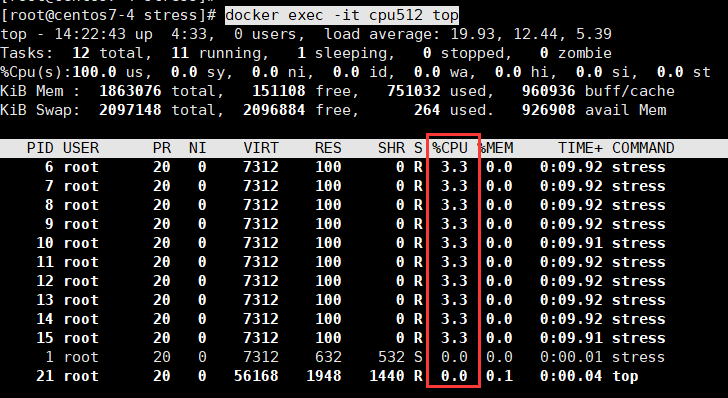
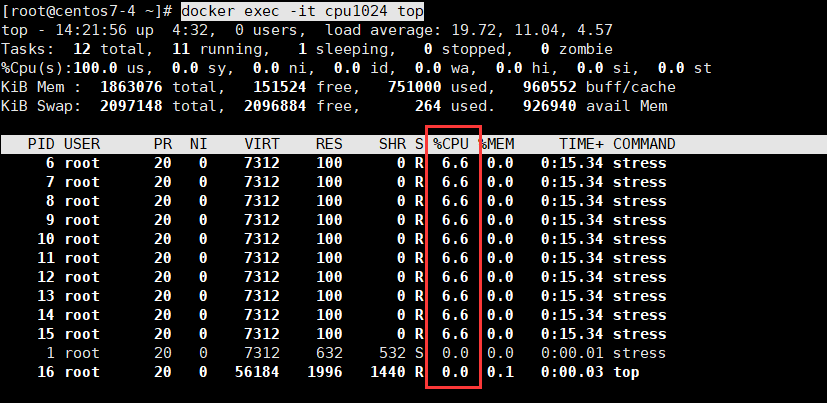
分别进入cpu512和cpu1024之后可以看到,%cpu的比例是1:2,符合我们设置的–cpu-shares参数。
2)cpu core控制
对于多核cpu的服务器,docker还可以控制容器运行使用那些cpu内核,以及使用–cpuset-cpus参数,这对于具有多cpu服务器尤其有用,可以对需要高性能计算的容器进行性能最优的配置。
执行以下命令需要宿主机为双核,表示创建的容器只能使用两个内核/使用哪几个CPU,最终生成cgroup的cpu内核配置如下:
$ docker run -itd --name cpu1 --cpus=2 centos:stress
# 指定使用哪几个cpu(0和3)
$ docker run -itd --name cpu1 --cpuset-cpus="0,3" centos:stress
# 指定使用哪几个cpu(0,1,2),只执行这个行
$ docker run -itd --name cpu1 --cpuset-cpus="0-2" centos:stress
查看
$ docker exec -it cpu1 bash
$ cat /sys/fs/cgroup/cpuset/cpuset.cpus
# 上面是登录到容器上查,其实也可以在宿主机上查,找到容器对应的容器ID
$ docker ps --no-trunc
$ cat /sys/fs/cgroup/cpuset/docker/7ca231149ecb0e06cbabda944697c0787c9a9e1f77565fd001aa978f4b3adede/cpuset.cpus

与操作系统类似,容器可使用的内存包括两部分:物理内存和swap;Docker 默认容器交换分区的大小和内存相同;若没有设置memory和memory-swap选项,则该容器可以使用主机的所有内存,没有限制。
内存限制相关的参数
| 选项 | 描述 |
|---|---|
| -m,--memory | 内存限制,格式是数字加单位,单位可以为 b,k,m,g。最小为 4M |
| --memory-swap | 内存+交换分区大小总限制。格式同上。必须必-m设置的大 |
| --memory-reservation | 内存的软性限制。格式同上 |
| --oom-kill-disable | 是否阻止 OOM killer 杀死容器,默认没设置 |
| --oom-score-adj | 容器被 OOM killer 杀死的优先级,范围是[-1000, 1000],默认为 0 |
| --memory-swappiness | 用于设置容器的虚拟内存控制行为。值为 0~100 之间的整数 |
| --kernel-memory | 核心内存限制。格式同上,最小为 4M |
1)允许容器最多使用200M的内存和300M的swap
$ docker run -it -m 200M --memory-swap=300M progrium/stress --vm 1 --vm-bytes 280M
#--vm 1 ,代表启动一个内存工作线程
#--vm-bytes 280 M ,代表每个线程可以分配280M内存
2)容器中的进程最多能使用 500M 内存,在这 500M 中,最多只有 50M 核心内存。
docker run -it -m 500M --kernel-memory 50M ubuntu:16.04 /bin/bash
核心内存
核心内存和用户内存不同的地方在于核心内存不能被交换出。不能交换出去的特性使得容器可以通过消耗太多内存来堵塞一些系统服务。
相对于CPU和内存的配额控制,docker对磁盘IO的控制相对不成熟,大多数都必须在有宿主机设备的情况下使用。主要包括以下参数:
| 选项 | 描述 |
|---|---|
| –device-read-bps | 限制此设备上的读速度(bytes per second),单位可以是kb、mb或者gb。 |
| –device-read-iops | 通过每秒读IO次数来限制指定设备的读速度。 |
| –device-write-bps | 限制此设备上的写速度(bytes per second),单位可以是kb、mb或者gb。 |
| –device-write-iops | 通过每秒写IO次数来限制指定设备的写速度。 |
| –blkio-weight | 容器默认磁盘IO的加权值,有效值范围为10-100。 |
| –blkio-weight-device | 针对特定设备的IO加权控制。其格式为DEVICE_NAME:WEIGHT |
1)Block IO的限制
默认情况下,所有容器平等地读写磁盘,可以通过设置–blkio-weight参数来改变容器block IO的优先级。
$ docker run -it --name container_A --blkio-weight 600 centos:stress
$ cat /sys/fs/cgroup/blkio/blkio.weight

当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我真的为这个而疯狂。我一直在搜索答案并尝试我找到的所有内容,包括相关问题和stackoverflow上的答案,但仍然无法正常工作。我正在使用嵌套资源,但无法使表单正常工作。我总是遇到错误,例如没有路线匹配[PUT]"/galleries/1/photos"表格在这里:/galleries/1/photos/1/edit路线.rbresources:galleriesdoresources:photosendresources:galleriesresources:photos照片Controller.rbdefnew@gallery=Gallery.find(params[:galle
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
我正在尝试将一个资源属性的默认值设置为另一个属性的值。我正在为我正在构建的tomcat说明书定义一个资源,其中包含以下定义。我想要可以独立设置的“名称”和“服务名称”属性。当未设置服务名称时,我希望它默认为为“名称”提供的任何内容。以下不符合我的预期:attribute:name,:kind_of=>String,:required=>true,:name_attribute=>trueattribute:service_name,:kind_of=>String,:default=>:name注意第二行末尾的“:default=>:name”。当我在Recipe的新block中引用我
我正在尝试使用docker运行一个Rails应用程序。通过github的sshurl安装的gem很少,如下所示:Gemfilegem'swagger-docs',:git=>'git@github.com:xyz/swagger-docs.git',:branch=>'my_branch'我在docker中添加了keys,它能够克隆所需的repo并从git安装gem。DockerfileRUNmkdir-p/root/.sshCOPY./id_rsa/root/.ssh/id_rsaRUNchmod700/root/.ssh/id_rsaRUNssh-keygen-f/root/.ss
我正在根据Rails指南的建议开发Rails应用程序,以创建包含翻译的文件夹树和文件。我的文件夹树与此类似:|-defaults|---es.rb|---en.rb|-models|---book|-----es.rb|-----en.rb|-views|---defaults|-----es.rb|-----en.rb|---books|-----es.rb|-----en.rb|---users|-----es.rb|-----en.rb|---navigation|-----es.rb|-----en.rbconfig/locales/views/books/en.yml中的内容
假设我们有两个资源:template'template1'doowner'root'group'root'endtemplate'template2'doowner'root'group'root'end我想在资源中重用代码。但是,如果我在配方中定义了一个过程,您会得到owner、group等的NoMethodError。为什么会这样?词法范围没有什么不同,是吗?因此,我必须使用self.instance_eval&common_cfg。common_cfg=Proc.new{owner'root'group'root'}template'template1'docommon_cfg.
当我尝试使用“套接字”库中的方法“read_nonblock”时出现以下错误IO::EAGAINWaitReadable:Resourcetemporarilyunavailable-readwouldblock但是当我通过终端上的IRB尝试时它工作正常如何让它读取缓冲区? 最佳答案 IgetthefollowingerrorwhenItrytousethemethod"read_nonblock"fromthe"socket"library当缓冲区中的数据未准备好时,这是预期的行为。由于异常IO::EAGAINWaitReadab
我在Heroku上构建了一个必须在Docker容器内运行的RoR应用程序。为此,我使用officialDockerfile.因为它在Heroku中很常见,所以我需要一些附加组件才能使这个应用程序完全运行。在生产中,变量DATABASE_URL在我的应用程序中可用。但是,如果我尝试其他一些使用环境变量(在我的例子中是Mailtrap)的加载项,变量不会在运行时复制到实例中。所以我的问题很简单:如何让docker实例在Heroku上执行时知道环境变量?您可能会问,我已经知道我们可以在docker-compose.yml中指定一个environment指令。我想避免这种情况,以便能够通过项目
我很难给出正确的答案,所以我会在这里征求我的问题。我正在研究RESTFulAPI。自然地,我有多种资源,其中一些由父子关系组成,一些是独立资源。我有点困难的地方是弄清楚如何让那些将根据我的API构建客户端的人更容易。情况是这样的。假设我有一个“街道”资源。每条街道都有多个住宅。SoStreet:has_manytoHomes和Homes:belongs_toStreet。如果用户想要在特定的home资源上请求HTTPGET,以下应该可行:http://mymap/streets/5/homes/10这允许用户获取ID为10的房屋的信息。直截了当。我的问题是,我授予用户访问权限是否违反了