背景
从单一角度来推断三维形状对于计算机说具有挑战,值得研究。
现有技术:
基于体素单一角度来推断三维形状,计算量大,精度与分辨率之间难以平衡。
基于点云单一角度推断三维形状,点云之间缺少连接,重建之后表面不光滑
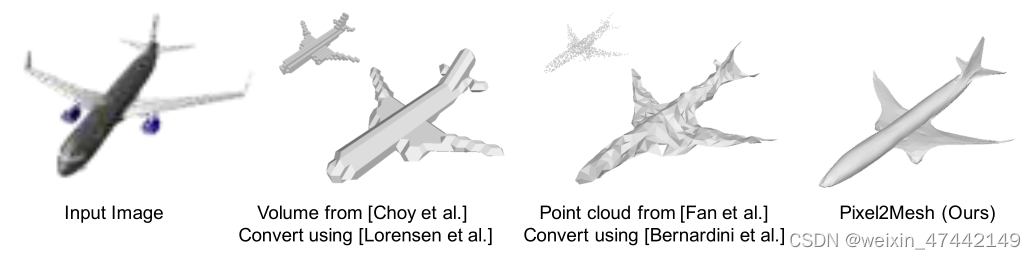
如何在网络中表示一个网格模型?如何从颜色图像中提取形状细节?
作者采用GCN网络,将网格看出点与边连接的拓扑结构,GCN模型可以用来训练拓扑结构。对于单张图片,作者采用了VGG-16模型从颜色图像中提取基于形状特征。
如何更新顶点的位置,让3d模型越来越与图像中的形状靠近?
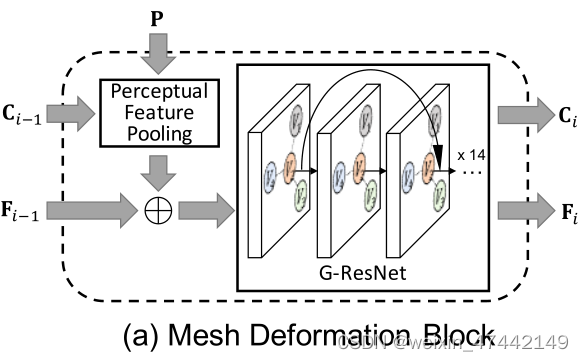
提出了 Perceptual Feature Pooling层,采用了VGG-16 conv5_3层的结构作为图像特征网络。给定一个顶点的三维坐标,利用相机本征计算其在输入图像平面上的二维投影,然后利用双线性插值从附近的四个像素汇集特征。将conv3_3层、conv4_3层和conv5_3层提取的特征进行级联,得到的总维数为1280。然后,这个感知特征与输入网格的128-dim 3D特征连接起来,得到1408的总维数。然后将每个顶点的特征输入到G-ResNet(GCN模型)中,预测每个顶点的位置和三维形状。

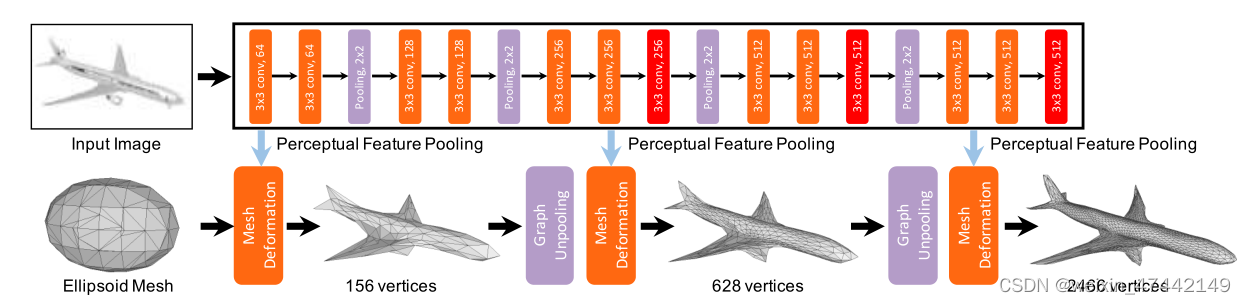
首先先初始化一个椭圆三维模型,三维模型具有156个顶点。三维模型的每个点的初始特征只是每个点的三维坐标。

通过 Perceptual Feature Pooling计算三维模型每一个顶点的特征,然后与上一次的特征进行拼接。输入到G-ResNet模型中,对顶点的位置与模型的三维形状进行更新。
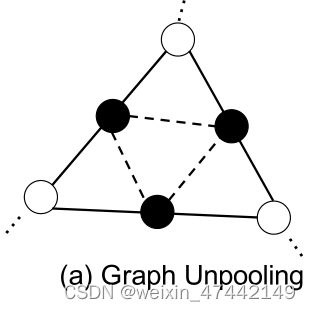
将G-ResNet模型的输出结果再通过Graph unpooling 层,这一层主要的目的是对三维模型进行插值,使更具有细节。具体的思路使对将在每个三角形三边的中点再取顶点,让这些顶点连接起来。
整个系统实质的想法是通过图像的特征去不断调整整个三维模型的形状。这是系统的整个架构图
在模型的迭代过程中,采用四种Loss去约束模型形状
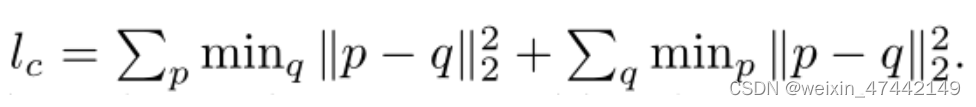
p是预测mesh顶点坐标,q是真实mesh顶点坐标。第一项计算p中任意一点到q中最小距离之和,第二项计算q中任意一点到p中最小距离之和。

q(真实mesh顶点坐标)距离p(预测mesh顶点坐标)最近距离的点。k是p的邻近节点,nq是真实mesh中q点对应平面法向量。<p-k,nq>代表两个向量的内积。当两个内积越小,表示它们越接近于垂直。因此可以是预测平面与真实平面越来越接近于平行。
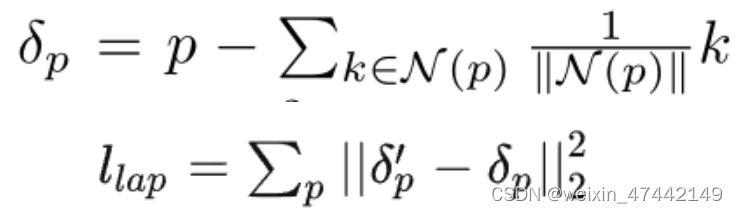
公式1,计算顶点的拉普拉斯算子坐标。公式二计算坐标变化后与坐标变化前拉普拉斯算子坐标的变化,作为loss。
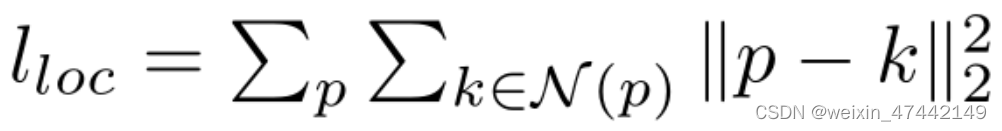
最后总的loss是四种loss的加权和,比列分别是1,1.6e-4,0.3,0.1。
shapeNet中13个对象类别50k模型的渲染图像。该数据集是根据WordNet层次结构组织的3D CAD模型的集合。从不同的摄像机视角对模型进行渲染,记录摄像机的内、外矩阵。
评价指标
F1-score
Chamfer Distance
Earth Mover’s Distance
baseline
A unified approach for single and multi-view 3d object reconstruction.
Convolutional neural networks on graphs with fast localized spectral filtering
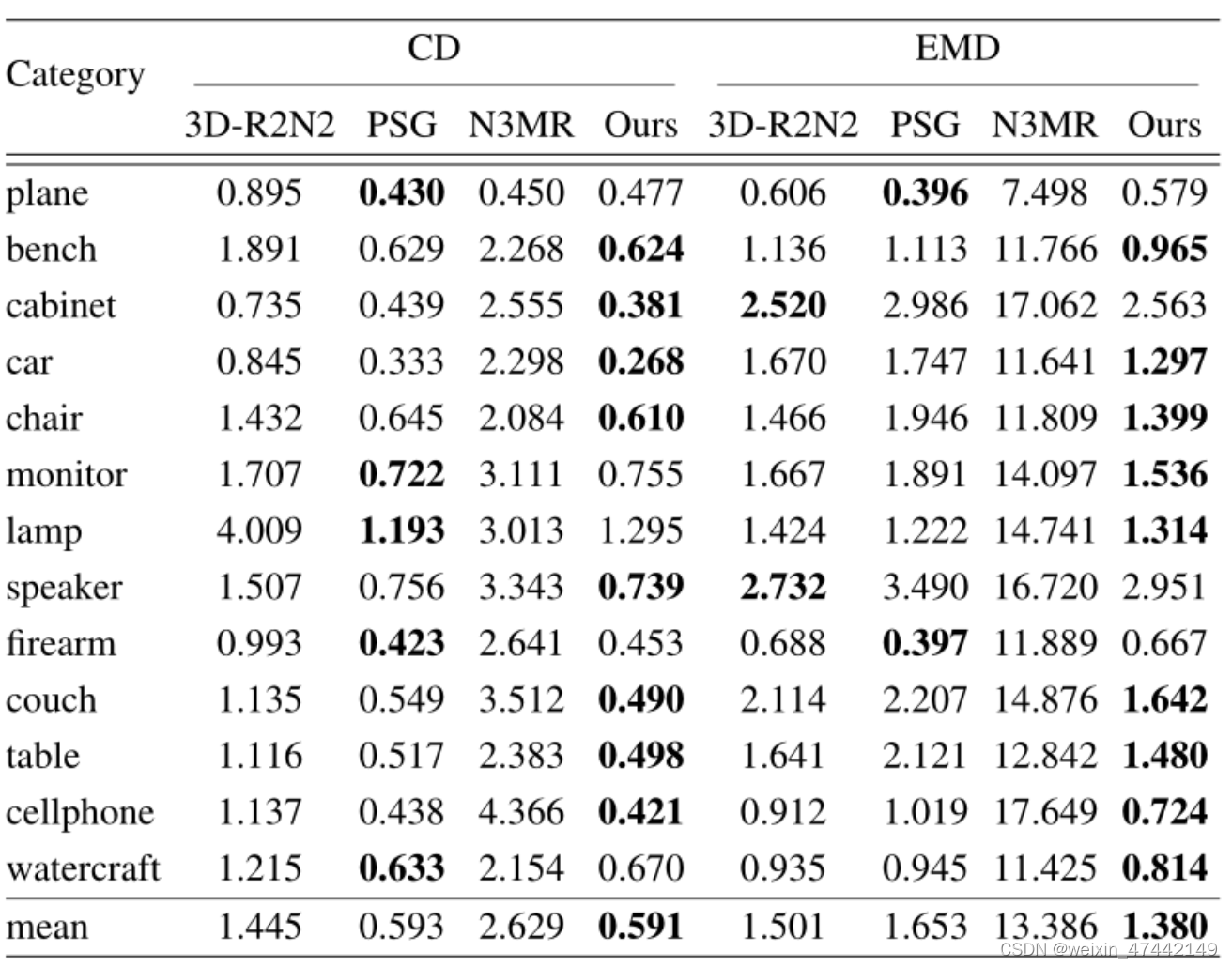
与这两个论文中提出的方法相比。
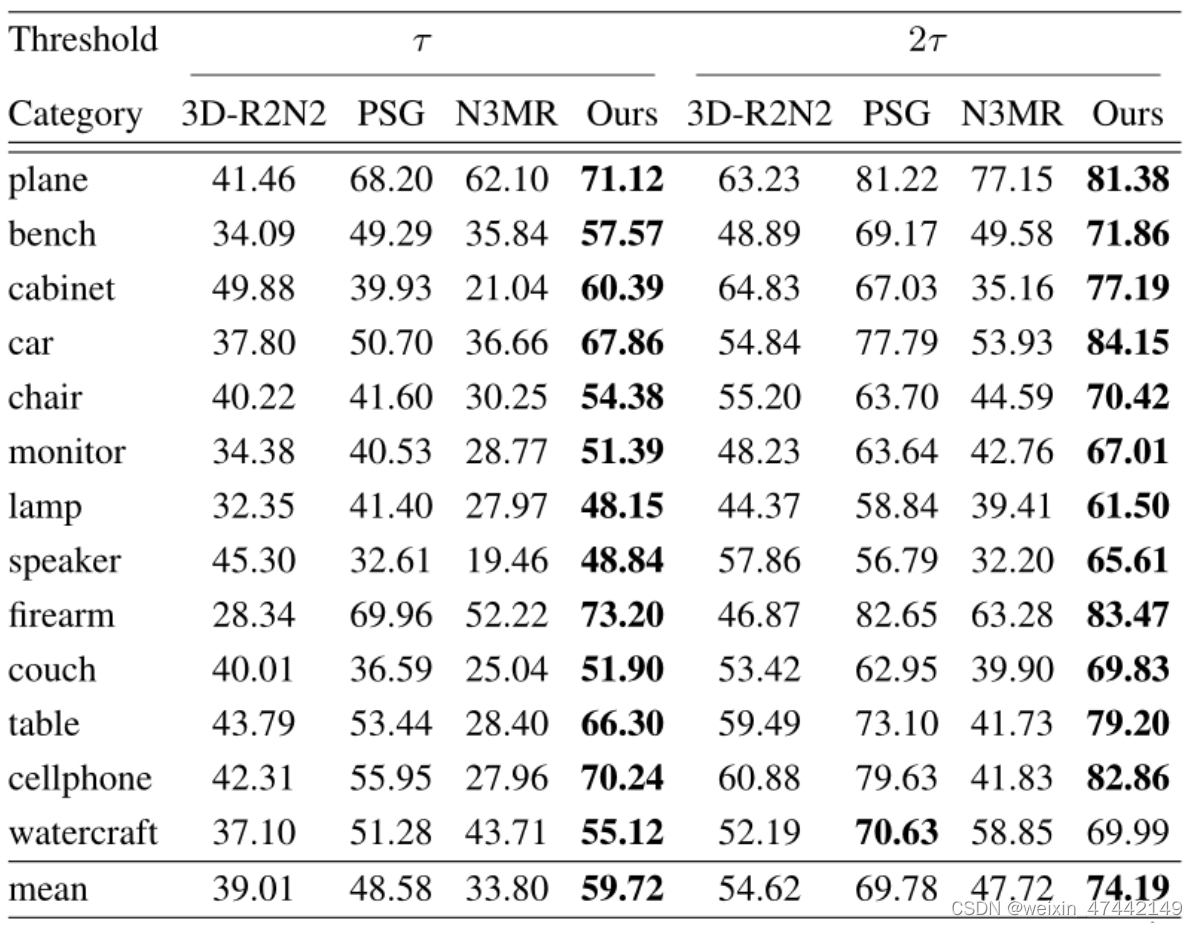
模型性能实验
与多个三维重构方法相比
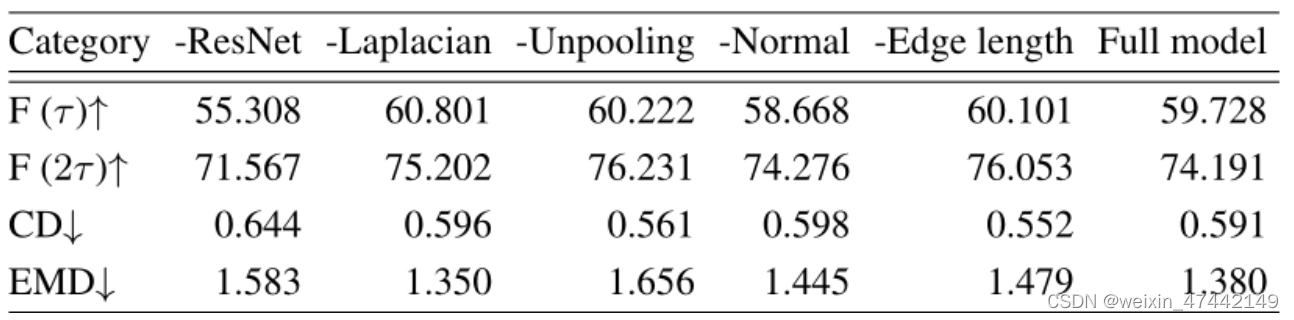
模型结构功能实验
针对模型每种结构进行消融实验,验证其功能。‘-’符号表示去除这一模块。F越大于好,CD与EMD越小越好。
每一种实验都是对前面内容的呼应,去验证自己方法的正确性。
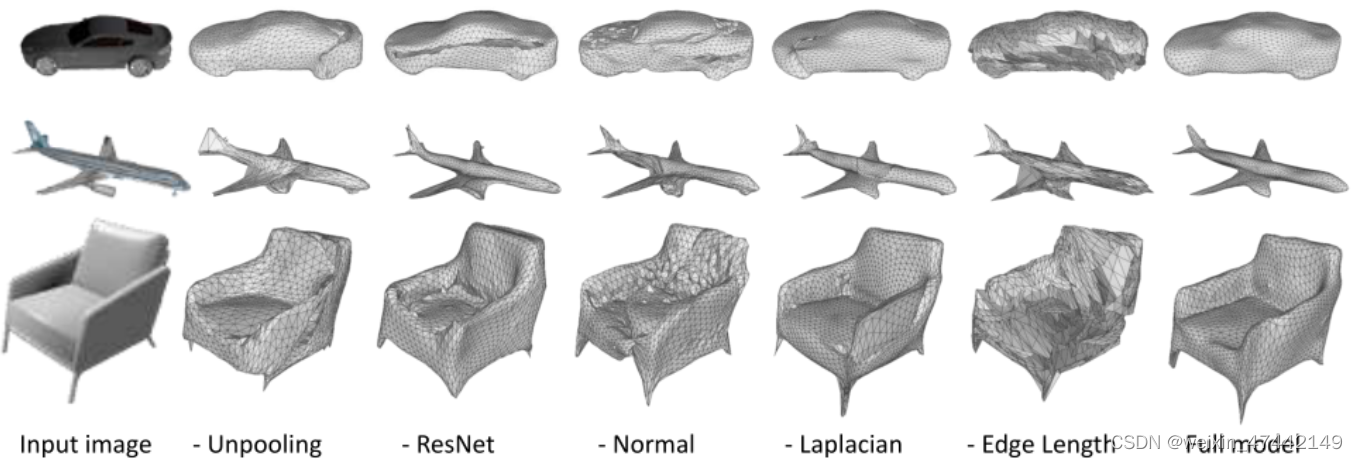
对真实世界图像进行重建

读完论文最大的困惑就是在3D模型形成的过程中,需要ground truth去计算loss。这个ground truth从何而来,是已有的点云数据吗,实际生活中随手拍一张图片如何重建?