3.长度受限制的字符串函数——strncpy,strncat,strncmp
博客主页:张栩睿的博客主页
欢迎关注:点赞+收藏+留言
系列专栏:c语言学习
家人们写博客真的很花时间的,你们的点赞和关注对我真的很重要,希望各位路过的朋友们能多多点赞并关注我,我会随时互关的,欢迎你们的私信提问,也期待你们的转发!
希望大家关注我,你们将会看到更多精彩的内容!!!
C语言中对字符和字符串的处理很是频繁,但是C语言本身是没有字符串类型的,字符串通常放在 常量字符串 中或者 字符数组中。 字符串常量 适用于那些对它不做修改的字符串函数。
以下的函数都需要引用头文件<string.h>
函数原型:

函数作用:
'\0'作为结束标志,strlen函数返回值是在字符串中'\0'前面出现的字符个数(不包含'\0')'\0'结束,否则计算出的长度是随机值size_t,是无符号的函数注意事项:
因为返回值是size_t,所以就要避免出现下图这样的代码:strlen(“abc”)算出的结果是3, strlen("abcde")算出的结果是5,可能想着3-5得到-2,实际上并不是这样的,这里算出的3和5都是无符号整型,算出的-2也是一个无符号整型,-2在内存中以补码的形式存储,从无符号整型的视角看去,这串补码就表示一个很大的正数。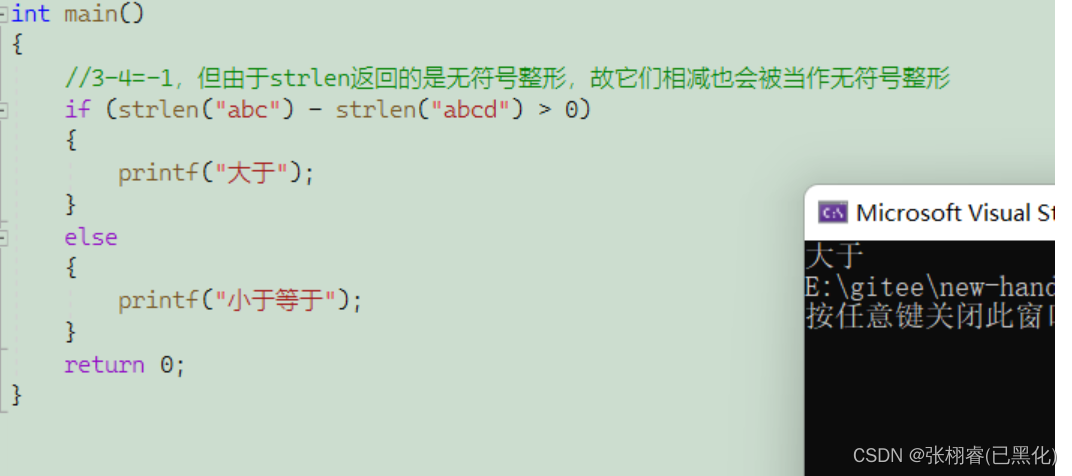
3种模拟的方法:
递归:
递归
int my_strlen1(const char* str)
{
assert(str != NULL);
if (*str != '\0')
return 1 + my_strlen(str + 1);
else
return 0;
}指针-指针
指针-指针
int my_strlen2(const char* str)
{
const char* start = str;
assert(str != NULL);
while (*str)
{
str++;
}
return str - start;递推
int my_strlen(const char* str)
{
assert(str != NULL);
int count = 0;
while (*str != '\0')
{
count++;
str++;
}
return count;
}函数原型:

函数作用:
字符串拷贝函数,把源字符串拷贝到目标空间
注意事项:
函数有两个参数,source指向待拷贝的字符串,也叫做源字符串。destination是目标空间的地址
源字符串必须以’\0’结束
目标空间必须足够大,以确保能存放源字符串,否则会出现非法访问
特殊情况:
会把源字符串中的 ‘\0’ 也拷贝到目标空间

目标空间必须可变,例如把源字符串拷贝到一个字符串常量里面是不可取的

模拟实现:
char* my_strcpy(char* destination, const char* source)
{
assert(destination && source);
char* ret = destination;
while (*destination++ = *source++)
{
;
}
return ret;
}函数原型:

函数作用:
字符串追加函数,将源字符串追加到目标字符串后面,目标中的终止字符’\0’会被源字符串的第一个字符覆盖

注意事项:
函数有两个参数,其中source指向要追加的字符串,也叫做源字符串,destination是目标空间的地址
目标空间中必须要有'\0',作为追加的起始地址
源字符串中也必须要有'\0'作为追加的结束标志
目标空间必须足够大,能容纳下源字符串的内容
目标空间必须可修改
以上与strcpy类似,但是有一点很特殊:
自己给自己追加会陷入死循环!
同学们先看看模拟实现的代码可以知道,该函数本质是将\0覆盖了,再最后追加\0,但是自己改自己会把\0覆盖不见,最后造成死循环。
模拟实现:
char* my_strcat(char* destination, const char* source)
{
assert(destination && source);
char* ret = destination;
while (*destination)
{
ret++;
}
while (*destination++ = *source++)
{
;
}
return ret;
}函数原型:

函数作用:
根据相同位置的ASCII值进行大小的比较。并不是比字符串长度
注意事项:
第一个字符串大于第二个字符串,则返回大于0的数字
第一个字符串等于第二个字符串,则返回0
第一个字符串小于第二个字符串,则返回小于0的数字
该函数是按字典序来比较的。

模拟实现:
int my_strcmp(const char* str1, const char* str2)
{
assert(str1 && str2);
while (*str1 == *str2)//如果相等就进去,两个指针加加,但是可能会出现两个字符串相等的情况,两个指针都指向'\0',此时比较就结束了
{
if (*str1 == '\0')
{
return 0;
}
str1++;
str2++;
}
if (*str1 > *str2)
{
return 1;
}
else
{
return -1;
}
}前面三个函数压根不关心到底拷贝,追加,比较了几个字符。它们只关心是否找到了\0,一旦找到了\0就会停止。这样的话如果目标空间不够大,会造成越界。这些特点就会让人们决定它是不安全的,并且我们之前发现如果自己给自己追加会出现死循环的现象,因为这些缺点,下面介绍较安全的函数。
函数原型:
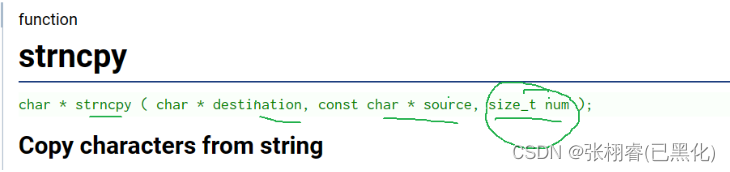
函数作用:
长度受限的字符串拷贝
注意事项:
模拟实现:
char* my_strncpy(char* dest, const char* src, int num)
{
assert(dest && src);
char* ret = dest;
while (num)
{
if (*src == '\0')//此时说明src指针已经指向了待拷贝字符串的结束标志'\0'处,src指针就不用再++了
{
*dest = '\0';
dest++;
}
else
{
*dest = *src;
dest++;
src++;
}
num--;
}
return ret;
}函数原型:

注意事项:
模拟实现:
char* my_strncat(char* dest, const char* src, int sz)
{
assert(dest && src);
char* ret = dest;
//找目标空间的\0
while (*dest != '\0')
{
dest++;
}
//追加
while (sz)
{
*dest++ = *src++;
sz--;
}
*dest = '\0';
return ret;
}
函数原型:

模拟实现:
int my_strncmp(const char* str1, const char* str2, int sz)
{
assert(str1 && str2);
while (sz)
{
if (*str1 < *str2)
{
return -1;
}
else if (*str1 > *str2)
{
return 1;
}
else if(*str1 == '\0'||*str2 =='\0')//当有一个为'\0',说明比较就可以结束了
{
if (*str1 == '\0' && *str2 == '\0')//如果二者都是'\0',说明两个字符串相等
{
return 0;
}
else if(*str1 =='\0')//如果str1为'\0',说明str1小,str2大
{
return -1;
}
else//如果src为'\0',说明str1大,str2小
{
return 1;
}
}
sz--;
str1++;
str2++;
}
}
函数原型:

函数作用:
判断是否为子字符串

注意事项:
BF算法(暴力枚举)模拟函数实现:
char* my_strstr(const char* str1, const char* str2)
{
assert(str1 && str2);
if (*str2 == '\0')
{
return (char*)str1;
}
const char* s1 = NULL;
const char* s2 = NULL;
const char* cp = str1;
while (*cp)
{
s1 = cp;
s2 = str2;
while (*s1 !='\0' && *s2!='\0' && *s1 == *s2)
{
s1++;
s2++;
}
if (*s2 == '\0')
{
return (char*)cp;
}
cp++;
}
return NULL;
}KMP算法模拟实现:
void Getnext(char* next, char* str2)
{
next[0] = -1;
next[1] = 0;
int k = 0;
int i = 2;
while (i <= strlen(str2))
{
if (str2[k] == str2[i-1])
next[i] = k + 1;
else if (str2[i] != str2[0])
next[k] = 0;
else if (str2[i] == str2[0])
next[k] = 1;
k++;
i++;
}
}
char* KMP(const char* str1, const char* str2)
{
assert(str1 && str2);
int* next = (int*)malloc(sizeof(int) * strlen(str2));
assert(next);
Getnext(next, str2);
int i = 0;
int j = 0;
while (i < strlen(str1) && j < strlen(str2))
{
if (j==-1||str1[i] == str2[j])
{
i++;
j++;
}
else
{
j = next[j];
}
}
free(next);
if (i == strlen(str2))
return &str1[i - j];
return NULL;
}关于KMP算法可以通过这两篇博客来了解:
函数原型:

作用:
通过分隔符分割字符串
注意事项:
1.sep参数是个字符串,定义了用作分隔符的字符集合第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标记。
2.strtok函数找到str中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针。(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。)
3. strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置。
4.strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标记。
5.如果字符串中不存在更多的标记,则返回 NULL 指针。
这个函数很奇怪,让我举个栗子:
用来分割字符串。一个例子,例如我的邮箱是xxxxx@163.com。这个邮箱起始由三部分组成,一个是xxxxxx,一个是163,一个是com。我现在想把这三部分分开。


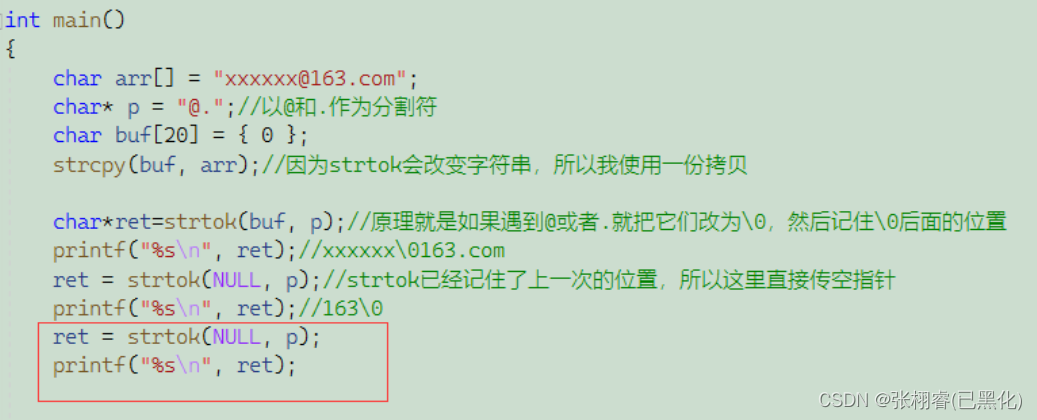

当然,我们可以用for循环简写:
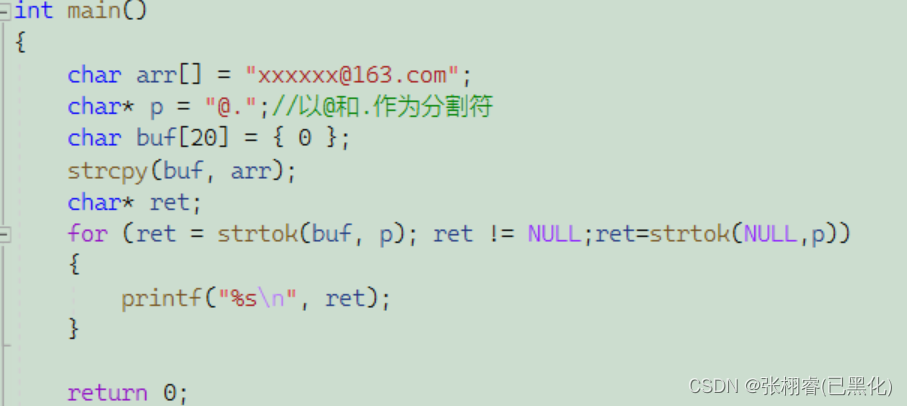
该函数模拟较复杂,我们就先不模拟了。
函数原型:

作用:
把错误码转换成错误信息
注意事项:
一些栗子:

用法:
int main()
{
//打开文件
FILE* pf = fopen("test.c", "r");
if (pf == NULL)
{
printf("%s\n", strerror(errno));//需要包含头文件#include<errno.h>
return 1;
}
//读文件
//关闭文件
fclose(pf);
return 0;
}
//打开失败时屏幕显示:
No such file or directory
关于这里的errno,C语言的库函数在运行的时候,如果发生错误,就会将错误码存在一个变量中,这个变量是:errno,错误码是一些数字:1 2 3 4 5,我们需要讲错误码翻译成错误消息。
perror函数:
实际上就是printf和strerror的结合!

 字符转换函数:
字符转换函数:
tolower:将大写字母转换为小写字母
int tolower ( int c );
toupper:将小写字母转换成大写字母
int toupper ( int c );
这些函数我就不一一讲解了,家人们有兴趣的话可以去官网了解一下哦!
上面我们介绍了处理字符串的函数,但是对于其他类型,我们该如何处理呢?通过下面的内存函数的介绍,相信你会有所感悟!
函数原型:

注意事项:
这里的destination指向要在其中赋值内容的目标数组,source指向要复制的数据源,num是要复制的字节数,注意这里前两个指针的的类型还有函数返回值都是void*,这是因为,memcpy这个函数是内存拷贝函数,它有可能拷贝整型,浮点型,结构体等等各种类型的数据……虽然返回类型是void*,但他也是必不可少的,void*也表示一个地址,用户可以把它强制转换成自己需要的类型去使用。

 函数的模拟实现:
函数的模拟实现:
void* my_memcpy(void* dest, const void* src, size_t num)
{
void* ret = dest;
assert(dest && src);
//前->后
while (num--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
return ret;
}注意:这里对于(char*)dest不能++或--,因为虽然强制转化类型,但是他的类型实质是没有改变的。
然而,这个函数存在缺陷,就是当对于自己拷贝并且有重叠部分时,会出现bug
如果我们只在一个字符串里操作就会出现问题。例如我想把arr1里的1,2,3,4,5拷贝到3,4,5,6,7上就,理论上arr1[]应该变为1,2,1,2,3,4,5,8,9。
但是实际上:

为了修改这个bug,大佬们又写出了memmove函数!
函数原型和memcpy一样,作用也是一样的,不同的就是可以拷贝自己,并且重叠不会出bug!
为什么之前的模拟实现会出现这个bug呢?

原因是:当1拷贝到3上时,原来的3已经被1替换,当2拷贝到4上的时候,原来的4已将被2替换。所以当拷贝arr[2]到arr[4]上的时候,原本arr[2]里面存放的3已将被1替换了,同理,所以才得出了不符合我们预期的结果。那如何解决这个问题呢?先来分析这个问题产生的原因,这是因为源空间与目标空间之间有重叠,这里的arr[2]、arr[3]、arr[4]既是源空间也是目标空间,当拷贝1和2的时候把源空间中开没有拷贝的3和4就给覆盖了,此时源空间arr[2]和arr[3]里面存的就不再是3和4了,而是1和2,所以此时拷贝arr[2]和arr[3]里面的数据,其实拷贝的就是1和2。为了解决这个问题,我们可以从后往前拷贝,此时就不会出现这样的问题
但是,我们从后往前拷贝就可以解决这个问题吗?答案是当然不是,比如:

所以我们需要分类讨论:
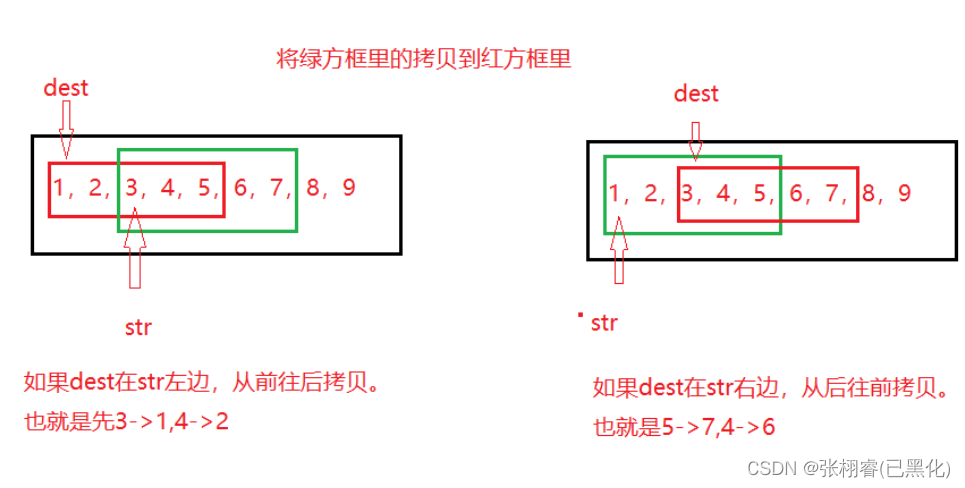 模拟实现:
模拟实现:
void* my_memmove(void* dest, const void*src, size_t num)
{
void* ret = dest;
assert(dest && src);
if (dest < src)
{
//前-->后
while (num--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
}
else
{
//后->前
while (num--)
{
*((char*)dest+num) = *((char*)src + num);
}
}
return ret;
} 函数作用:
函数作用:
内存设置
注意事项:

函数原型:

注意事项:
本文通过函数使用的介绍来初步学习,函数的模拟实现来深刻理解了库函数的使用。辛苦各位小伙伴们动动小手,三连走一波 最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我正在尝试用ruby中的gsub函数替换字符串中的某些单词,但有时效果很好,在某些情况下会出现此错误?这种格式有什么问题吗NoMethodError(undefinedmethod`gsub!'fornil:NilClass):模型.rbclassTest"replacethisID1",WAY=>"replacethisID2andID3",DELTA=>"replacethisID4"}end另一个模型.rbclassCheck 最佳答案 啊,我找到了!gsub!是一个非常奇怪的方法。首先,它替换了字符串,所以它实际上修改了
我有一些代码在几个不同的位置之一运行:作为具有调试输出的命令行工具,作为不接受任何输出的更大程序的一部分,以及在Rails环境中。有时我需要根据代码的位置对代码进行细微的更改,我意识到以下样式似乎可行:print"Testingnestedfunctionsdefined\n"CLI=trueifCLIdeftest_printprint"CommandLineVersion\n"endelsedeftest_printprint"ReleaseVersion\n"endendtest_print()这导致:TestingnestedfunctionsdefinedCommandLin
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
如何在Ruby中按名称传递函数?(我使用Ruby才几个小时,所以我还在想办法。)nums=[1,2,3,4]#Thisworks,butismoreverbosethanI'dlikenums.eachdo|i|putsiend#InJS,Icouldjustdosomethinglike:#nums.forEach(console.log)#InF#,itwouldbesomethinglike:#List.iternums(printf"%A")#InRuby,IwishIcoulddosomethinglike:nums.eachputs在Ruby中能不能做到类似的简洁?我可以只
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
说在前面这部分我本来是合为一篇来写的,因为目的是一样的,都是通过独立按键来控制LED闪灭本质上是起到开关的作用,即调用函数和中断函数。但是写一篇太累了,我还是决定分为两篇写,这篇是调用函数篇。在本篇中你主要看到这些东西!!!1.调用函数的方法(主要讲语法和格式)2.独立按键如何控制LED亮灭3.程序中的一些细节(软件消抖等)1.调用函数的方法思路还是比较清晰地,就是通过按下按键来控制LED闪灭,即每按下一次,LED取反一次。重要的是,把按键与LED联系在一起。我打算用K1来作为开关,看了一下开发板原理图,K1连接的是单片机的P31口,当按下K1时,P31是与GND相连的,也就是说,当我按下去时