⭐️写在前面
- 这里是温文艾尔的学习之路
- 👍如果对你有帮助,给博主一个免费的点赞以示鼓励把QAQ
- 👋博客主页🎉 温文艾尔的学习小屋
- ⭐️更多文章👨🎓请关注温文艾尔主页📝
- 🍅文章发布日期:2022.03.07
- 👋java学习之路!
- 欢迎各位🔎点赞👍评论收藏⭐️
- 🎄冲冲冲🎄
- ⭐️上一篇内容:HashMap夺命14问,你能坚持到第几问?
文章目录
文章笔记来源于:小刘老师公开课
在学习源码之前我们先从一个需求开始
需求
package day03;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
/**
* Description
* User:
* Date:
* Time:
*/
public class Demo {
//总访问量
static int count = 0;
//模拟访问的方法
public static void request() throws InterruptedException {
//模拟耗时5毫秒
TimeUnit.MILLISECONDS.sleep(5);
count++;
}
public static void main(String[] args) throws InterruptedException {
long startTime = System.currentTimeMillis();
int threadSize=100;
CountDownLatch countDownLatch = new CountDownLatch(threadSize);
for (int i=0;i<threadSize;i++){
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
//每个用户访问10次网站
try {
for (int j=0;j<10;j++) {
request();
}
}catch (InterruptedException e) {
e.printStackTrace();
}finally {
countDownLatch.countDown();
}
}
});
thread.start();
}
//怎么保证100个线程执行之后,执行后面的代码
countDownLatch.await();
long endTime = System.currentTimeMillis();
System.out.println(Thread.currentThread().getName()+"耗时:"+(endTime-startTime)+",count:"+count);
}
}
我们多输出几次结果
main耗时:66,count:950
main耗时:67,count:928
发现每一次count都不相同,和我们期待的1000相差一点,这里就牵扯到了并发问题,我们的count++在底层实际上由3步操作组成
这并不是一个线程安全的过程,如果有A、B两个线程同时执行count++,同时执行到第一步,得到的count是一样的,三步操作完成后,count只加1,导致count结果不正确
那么怎么解决这个问题呢?
我们可以考虑使用synchronized关键字和ReentrantLock对资源加锁,保证并发的正确性,多线程的情况下,可以保证被锁住的资源被串行访问
package day03;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
/**
* Description
* User:
* Date:
* Time:
*/
public class Demo02 {
//总访问量
static int count = 0;
//模拟访问的方法
public static synchronized void request() throws InterruptedException {
//模拟耗时5毫秒
TimeUnit.MILLISECONDS.sleep(5);
count++;
}
public static void main(String[] args) throws InterruptedException {
long startTime = System.currentTimeMillis();
int threadSize=100;
CountDownLatch countDownLatch = new CountDownLatch(threadSize);
for (int i=0;i<threadSize;i++){
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
//每个用户访问10次网站
try {
for (int j=0;j<10;j++) {
request();
}
}catch (InterruptedException e) {
e.printStackTrace();
}finally {
countDownLatch.countDown();
}
}
});
thread.start();
}
//怎么保证100个线程执行之后,执行后面的代码
countDownLatch.await();
long endTime = System.currentTimeMillis();
System.out.println(Thread.currentThread().getName()+"耗时:"+(endTime-startTime)+",count:"+count);
}
}
执行结果
main耗时:5630,count:1000
可以看到,由于sychronized锁住了整个方法,虽然结果正确,但因为线程执行方法均为串行执行,导致运行效率大大下降
那么我们如何才能使程序执行无误时,效率还不会降低呢?
缩小锁的范围,升级上述3步中第三步的实现
package day03;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
/**
* Description
* User:
* Date:
* Time:
*/
public class Demo03 {
//总访问量
volatile static int count = 0;
//模拟访问的方法
public static void request() throws InterruptedException {
//模拟耗时5毫秒
TimeUnit.MILLISECONDS.sleep(5);
// count++;
int expectCount;
while (!compareAndSwap(expectCount=getCount(),expectCount+1)){}
}
/**
* @param expectCount 期待的值,比如最刚开始count=3
* @param newCount 新值 count+1之后的值,4
* @return
*/
public static synchronized boolean compareAndSwap(int expectCount,int newCount){
if (getCount()==expectCount){
count = newCount;
return true;
}
return false;
}
public static int getCount(){return count;}
public static void main(String[] args) throws InterruptedException {
long startTime = System.currentTimeMillis();
int threadSize=100;
CountDownLatch countDownLatch = new CountDownLatch(threadSize);
for (int i=0;i<threadSize;i++){
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
//每个用户访问10次网站
try {
for (int j=0;j<10;j++) {
request();
}
}catch (InterruptedException e) {
e.printStackTrace();
}finally {
countDownLatch.countDown();
}
}
});
thread.start();
}
//怎么保证100个线程执行之后,执行后面的代码
countDownLatch.await();
long endTime = System.currentTimeMillis();
System.out.println(Thread.currentThread().getName()+"耗时:"+(endTime-startTime)+",count:"+count);
}
}
main耗时:67,count:1000
CAS全称“CompareAndSwap”,中文翻译过来为“比较并替换”
定义:
内存位置(V)、期望值(A)和新值(B)。如果内存位置的值和期望值匹配,那么处理器会自动将该位置值更新为新值。否则处理器不作任何操作。无论哪种情况,它都会在CAS指令之前返回该位置的值。java中提供了对CAS操作的支持,具体在sun.misc.unsafe类中,声明如下
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
CAS通过调用JNI的代码实现,JNI:java native interface,允许java调用其他语言。而compareAndSwapxxx系列的方法就是借助C语言来调用cpu底层指令实现的
以常用的Intel x86平台为例,最终映射到cpu的指令为"cmpxchg",这是一个原子指令,cpu执行此命令时,实现比较并替换的操作
现代计算机动不动就上百核心,cmpxchg怎么保证多核心下的线程安全?
系统底层在进行CAS操作的时候,会判断当前系统是否为多核心系统,如果是就给“总线”加锁,只有一个线程会对总线加锁成功,加锁之后执行CAS操作,也就是说CAS的原子性是平台级别的
CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,在CAS方法执行之前,被其他线程修改为B,然后又修改回了A,那么CAS方法执行检查的时候会发现它的值没有发生变化,但是实际却不是原来的A了,这就是CAS的ABA问题
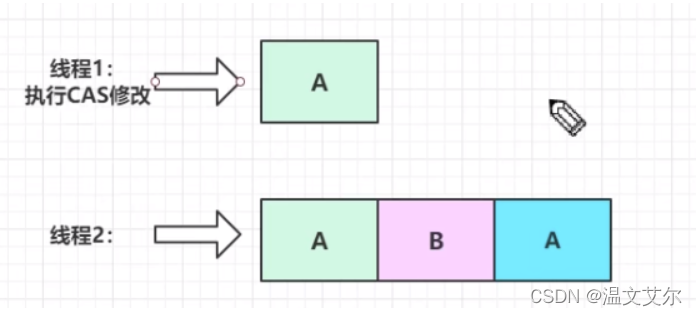
可以看到上图中线程A在真正更改A之前,A已经被其他线程修改为B然后又修改为A了
package day04;
import java.util.concurrent.atomic.AtomicInteger;
/**
* Description
* User:
* Date:
* Time:
*/
public class Test01 {
public static AtomicInteger a = new AtomicInteger();
public static void main(String[] args) {
Thread main = new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"执行,a的值为:"+a.get());
try {
int expect = a.get();
int update = expect+1;
//让出cpu
Thread.sleep(1000);
boolean b = a.compareAndSet(expect, update);
System.out.println(Thread.currentThread().getName()+"CAS执行:"+b+",a的值为:"+a.get());
}
catch (InterruptedException e) {
e.printStackTrace();
}
}
},"主线程");
// main.start();
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(20);
a.incrementAndGet();
System.out.println(Thread.currentThread().getName()+"更改a的值为:"+a.get());
a.decrementAndGet();
System.out.println(Thread.currentThread().getName()+"更改a的值为:"+a.get());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"其他线程");
main.start();
thread1.start();
}
}
主线程执行,a的值为:0
其他线程更改a的值为:1
其他线程更改a的值为:0
主线程CAS执行:true,a的值为:1
可以看到,在执行CAS之前,a被其他线程修改为1又修改为0,但是对执行CAS并没有影响,因为它根本没有察觉到其他线程对a的修改
解决ABA问题最简单的方案就是给值加一个修改版本号,每次值变化,都会修改它的版本号,CAS操作时都去对比此版本号
在java中的ABA解决方案(AtomicStampedReference)
AtomicStampedReference主要包含一个对象引用及一个可以自动更新的整数stamp的pair对象来解决ABA问题
AtomicStampedReference源码
/**
* Atomically sets the value of both the reference and stamp
* to the given update values if the
* current reference is {@code ==} to the expected reference
* and the current stamp is equal to the expected stamp.
*
* @param expectedReference the expected value of the reference 期待引用
* @param newReference the new value for the reference 新值引用
* @param expectedStamp the expected value of the stamp 期望引用的版本号
* @param newStamp the new value for the stamp 新值的版本号
* @return {@code true} if successful
*/
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair<V> current = pair;
return
expectedReference == current.reference &&//期望引用与当前引用保持一致
expectedStamp == current.stamp &&//期望引用版本号与当前版本号保持一致
((newReference == current.reference &&//新值引用与当前引用一致并且新值版本号与当前版本号保持一致
newStamp == current.stamp)
||//如果上述版本号不一致,则通过casPair方法新建一个Pair对象,更新值和版本号,进行再次比较
casPair(current, Pair.of(newReference, newStamp)));
}
private boolean casPair(Pair<V> cmp, Pair<V> val) {
return UNSAFE.compareAndSwapObject(this, pairOffset, cmp, val);
}
使用AtomicStampedReference解决ABA问题代码
package day04;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicReference;
import java.util.concurrent.atomic.AtomicStampedReference;
/**
* Description
* User:
* Date:
* Time:
*/
public class Test02 {
public static AtomicStampedReference<Integer> a = new AtomicStampedReference(new Integer(1),1);
public static void main(String[] args) {
Thread main = new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"执行,a的值为:"+a.getReference());
try {
Integer expectReference = a.getReference();
Integer newReference = expectReference+1;
Integer expectStamp = a.getStamp();
Integer newStamp = expectStamp+1;
//让出cpu
Thread.sleep(1000);
boolean b = a.compareAndSet(expectReference, newReference,expectStamp,newStamp);
System.out.println(Thread.currentThread().getName()+"CAS执行:"+b);
}
catch (InterruptedException e) {
e.printStackTrace();
}
}
},"主线程");
// main.start();
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(20);
a.compareAndSet(a.getReference(),a.getReference()+1,a.getStamp(),a.getStamp()+1);
System.out.println(Thread.currentThread().getName()+"更改a的值为:"+a.getReference());
a.compareAndSet(a.getReference(),a.getReference()-1,a.getStamp(),a.getStamp()-1);
System.out.println(Thread.currentThread().getName()+"更改a的值为:"+a.getReference());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"其他线程");
main.start();
thread1.start();
}
}
主线程执行,a的值为:1
其他线程更改a的值为:2
其他线程更改a的值为:1
主线程CAS执行:false
因为AtomicStampedReference执行CAS会去检查版本号,版本号不一致则不会进行CAS,所以ABA问题成功解决
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
我基本上来自Java背景并且努力理解Ruby中的模运算。(5%3)(-5%3)(5%-3)(-5%-3)Java中的上述操作产生,2个-22个-2但在Ruby中,相同的表达式会产生21个-1-2.Ruby在逻辑上有多擅长这个?模块操作在Ruby中是如何实现的?如果将同一个操作定义为一个web服务,两个服务如何匹配逻辑。 最佳答案 在Java中,模运算的结果与被除数的符号相同。在Ruby中,它与除数的符号相同。remainder()在Ruby中与被除数的符号相同。您可能还想引用modulooperation.
Java的Collections.unmodifiableList和Collections.unmodifiableMap在Ruby标准API中是否有等价物? 最佳答案 使用freeze应用程序接口(interface):Preventsfurthermodificationstoobj.ARuntimeErrorwillberaisedifmodificationisattempted.Thereisnowaytounfreezeafrozenobject.SeealsoObject#frozen?.Thismethodretur