

本系列为 斯坦福CS231n 《深度学习与计算机视觉(Deep Learning for Computer Vision)》的全套学习笔记,对应的课程视频可以在 这里 查看。更多资料获取方式见文末。
之前了解到的都是监督学习(Supervised Learning):我们有数据x和标签y,目标是学习到一个函数可以将数据x映射到标签y,标签可以有很多形式。
典型的有监督学习有:分类问题中输入一张图片,输出图片的分类;目标检测中输入一张图片,输出目标物体的边框;语义分割中,给每个像素都打上标签。
CS231n第13讲给大家介绍的是无监督学习(Unsupervised Learning)以及生成模型的一些知识。
无监督学习在我们只有一些没有标签的训练数据的情况下,学习数据中隐含的结构。无监督学习由于没有标签,数据获取也很容易。典型的无监督学习包括下述算法:
关于聚类算法的详细知识也可以参考ShowMeAI的下述文章
聚类(Clustering)是找到数据的分组,组内数据在某种度量方式下是相似的。随机初始k个中心位置,将每个样本分配到最近的中心位置,然后根据分配的样本更新中心位置。重复这个过程直至收敛(中心位置不再变化)。

关于PCA降维算法的详细知识也可以参考ShowMeAI的下述文章
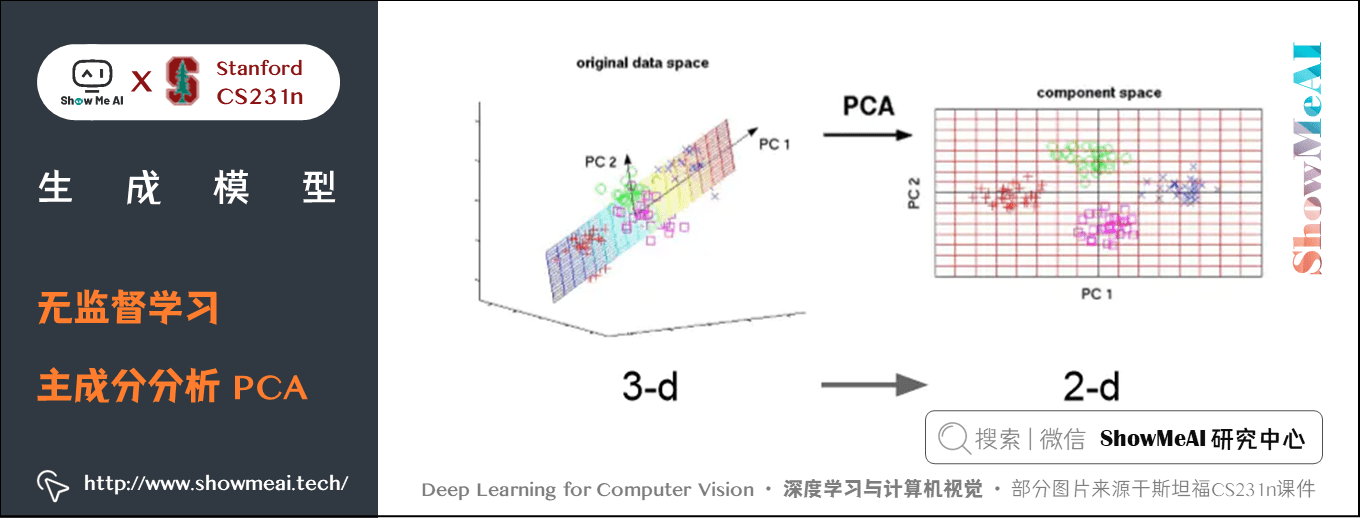
数据降维(Dimensionality reduction):找出一些投影方向(轴),在这些轴上训练数据投影的方差最大。这些轴就是数据内潜在的结构。我们可以用这些轴来减少数据维度,数据在每个保留下来的维度上都有很大的方差。
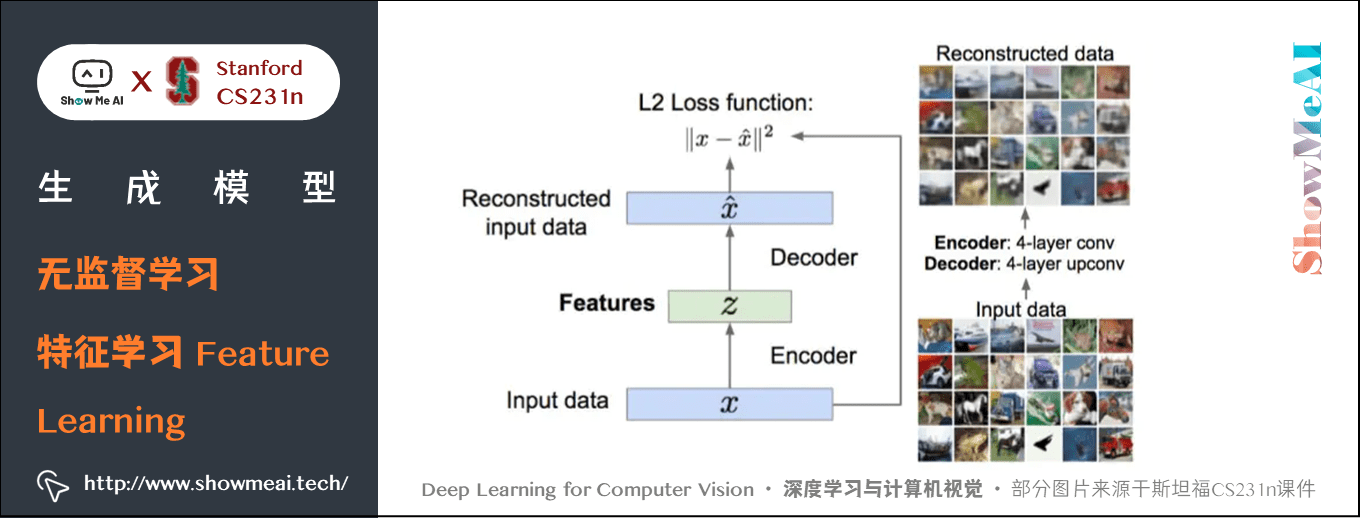
我们还有一些特征学习的方法,比如自编码(Autoencoders):
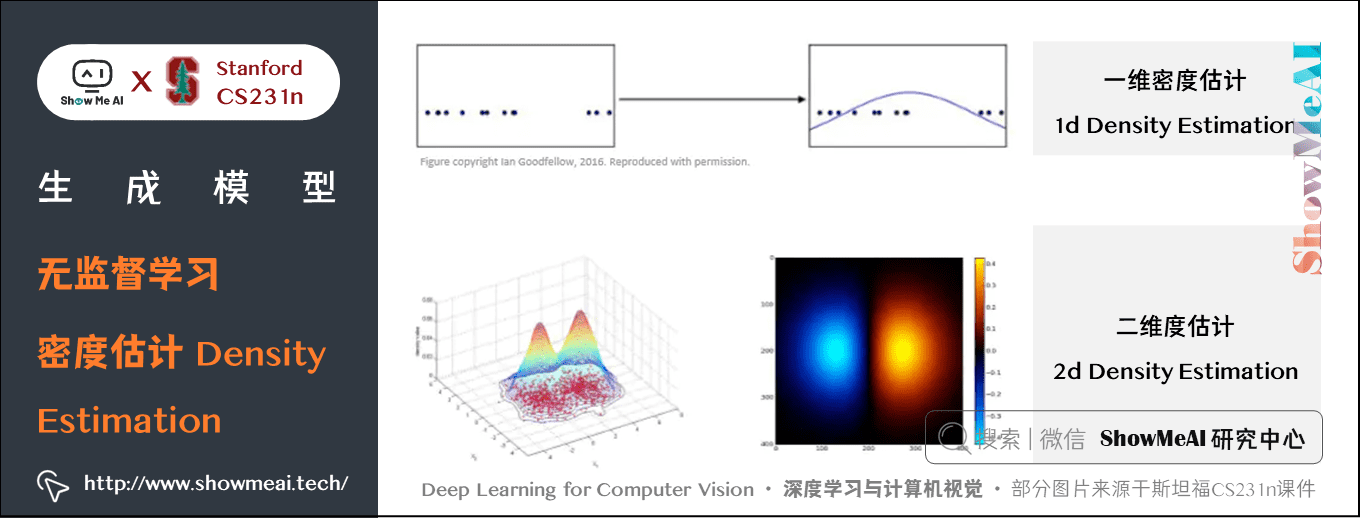
密度估计( Density Estimation)也是一种无监督算法,我们会估计数据的内在分布情况,比如下图上方有一些一维和二维的点,我们用高斯函数来拟合这一密度分布,如下图所示:
生成模型是一种无监督学习方法。它对应的任务是:根据一批由真实分布p-data(x) 产生的训练数据,通过训练学习,得到一个可以以近似于真实的分布p-model(x) 来产生新样本的模型。

为什么生成模型重要,因为其可以支撑一系列问题的解决:生成样本,着色问题,强化学习应用,隐式表征推断等。
下图左边为生成的图片,中间生成的人脸,还可以做超分辨率或者着色之类的任务。

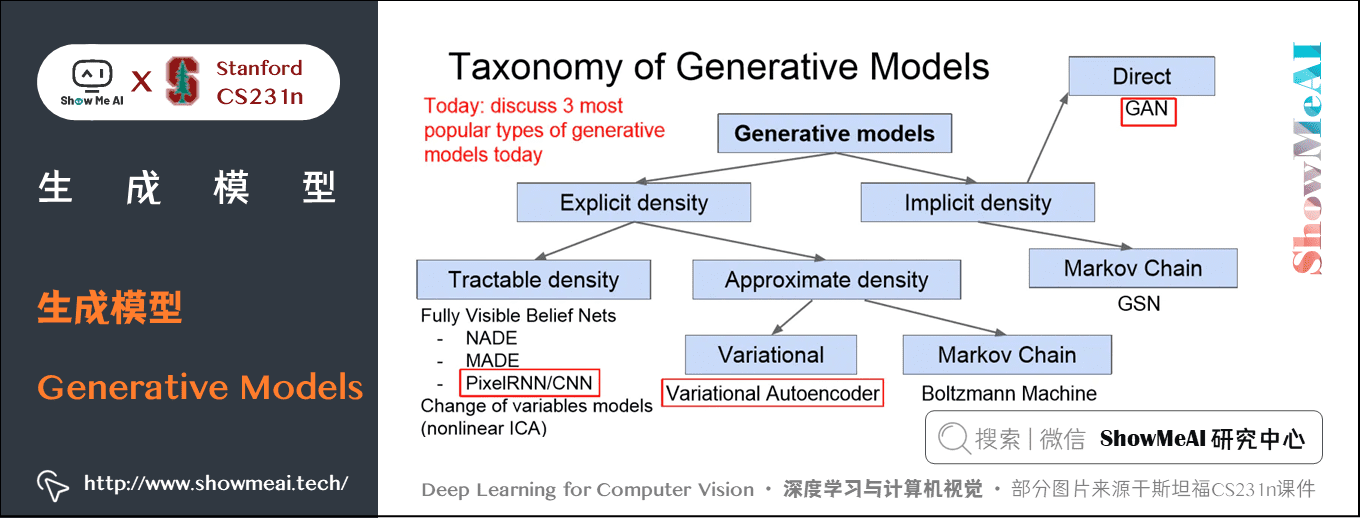
生成模型分为「显式」和「隐式」的生成模型,往下分又可以分成很多子类。如下图所示。
我们在本篇内容中主要讨论3种模型:PixelRNN / CNN,变分自动编码器属于显示密度模型,生成对抗网络(GAN)属于隐式密度估计模型。
PixelRNN 和 PixelCNN 使用概率链式法则来计算一张图片出现的概率。其中每一项为给定前 \(i-1\) 个像素点后第 \(i\) 个像素点的条件概率分布。这个分布通过神经网络 RNN 或 CNN 来建模,再通过最大化图片 \(x\) 的似然概率来学习出 RNN 或 CNN 的参数。
条件概率公式为:
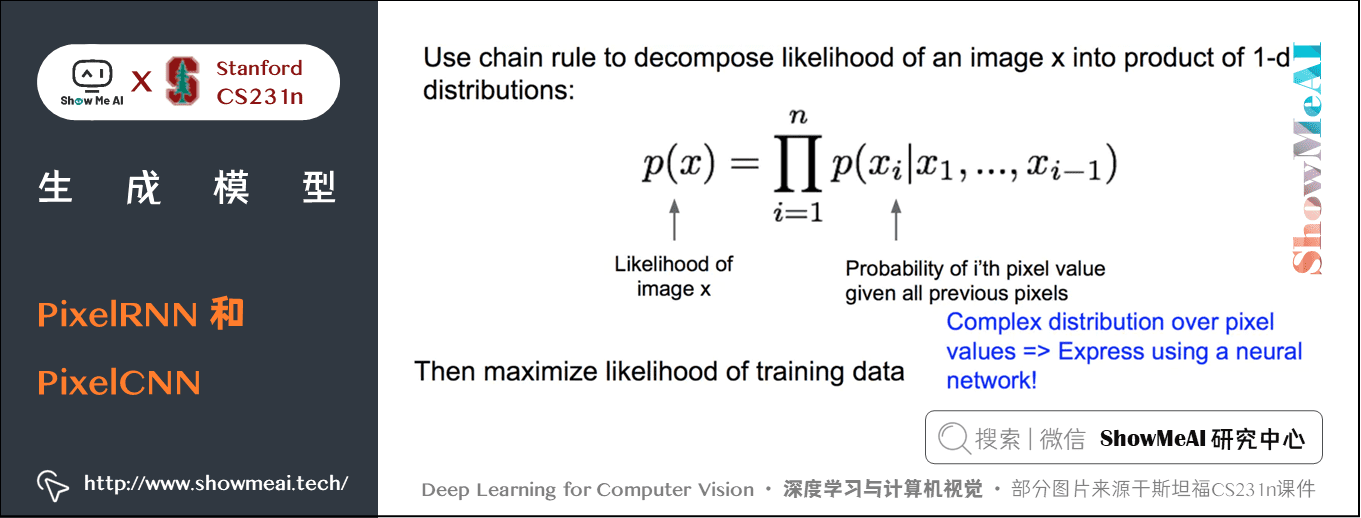
其中:
PixelRNN 中,从左上角开始定义「之前的像素」。由于 RNN 每个时间步的输出概率都依赖于之前所有输入,因此能够用来表示上面的条件概率分布。

我们训练这个 RNN 模型时,一次前向传播需要从左上到右下串行走一遍,然后根据上面的公式求出似然,并最大化似然以对参数做一轮更新。因此训练非常耗时。
PixelCNN中,使用一个CNN来接收之前的所有像素,并预测下一个像素的出现概率:

对比 PixelRNN 和 PixelCNN,后者在训练时可以并行计算公式中的每一项,然后进行参数更新,因此训练速度远快于 PixelRNN。
不过,在测试阶段,我们会发现PixelRNN和PixelCNN都要从左上角开始逐个像素点地生成图片,实际应用阶段生成图像的速度是很慢的。

PixelRNN 和 PixelCNN 能显式地计算似然 \(p(x)\),是一种可优化的显式密度模型,该方法给出了一个很好的评估度量,可以通过计算的数据的似然来度量出生成样本有多好。

PixelCNN定义了一个易于处理的密度函数,我们可以直接优化训练数据的似然;而我们下面介绍到的变分自编码器方法中,密度函数就不易处理了,我们要通过附加的隐变量 \(z\) 对密度函数进行建模:
我们数据的似然 \(p(x)\) 是等式右边的积分形式,即对所有可能的 \(z\) 值取期望,但它是无法直接优化的,我们只能找出一个似然函数的下界然后再对该下界进行优化。
自编码器是为了无监督地学习出样本的特征表示,原理如下:
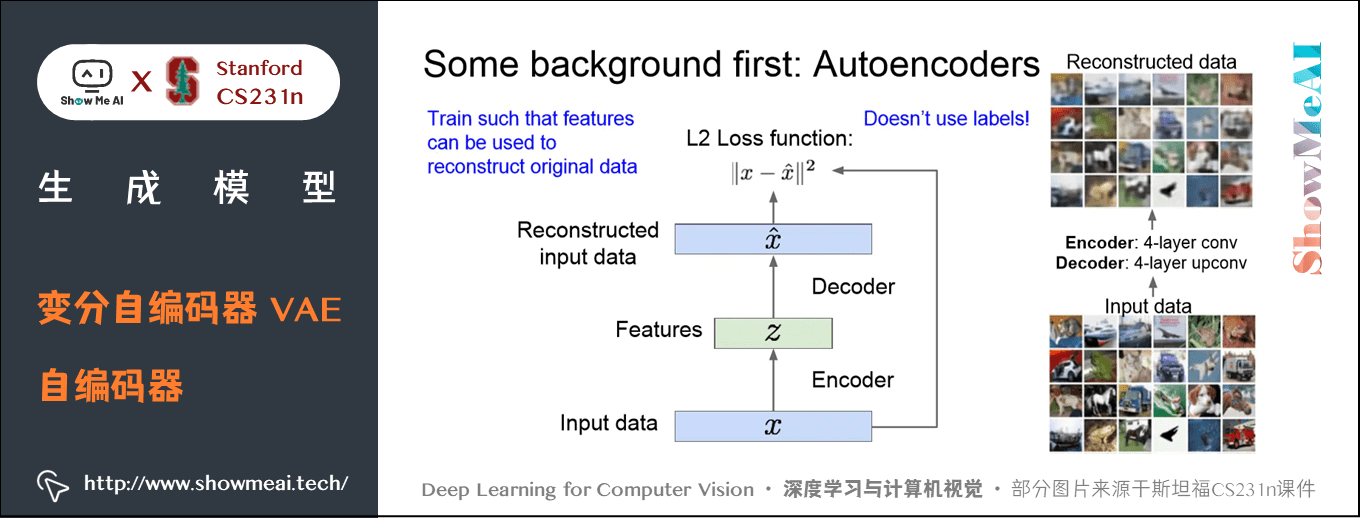
如上图,自编码器由编码器和解码器组成,编码器将样本 \(x\) 映射到特征 \(z\),解码器再 \(x\) 将特征 \(z\) 映射到重构样本。我们设定损失函数为 \(x\) 与重构样本之间的 L2 损失,训练出编码器和解码器的参数,希望能够使 \(z\) 解码后恢复出原来的 \(x\)。
编码器可以有多种形式,常用的是神经网络。最先提出的是非线性层的线性组合,然后有了深层的全连接网络(MLP),后来又使用 CNN,我们通过神经网络对输入数据 \(x\) 计算和映射,得到特征 \(z\),\(z\) 的维度通常比 \(x\) 更小。这种降维压缩可以压缩保留 \(x\) 中最重要的特征。
解码器主要是为了重构数据,它输出一些跟 \(x\) 有相同维度的结果并尽量拟合 \(x\) 。解码器一般使用和编码器相同类型的网络(与编码器对称)。
训练好完整的网络后,我们会把解码器的部分去掉,使用训练好的编码器实现特征映射。
通过编码器得到输入数据的特征,编码器顶部有一个分类器,如果是分类问题我们可以用它来输出一个类标签,在这里使用了外部标签和标准的损失函数如 Softmax。
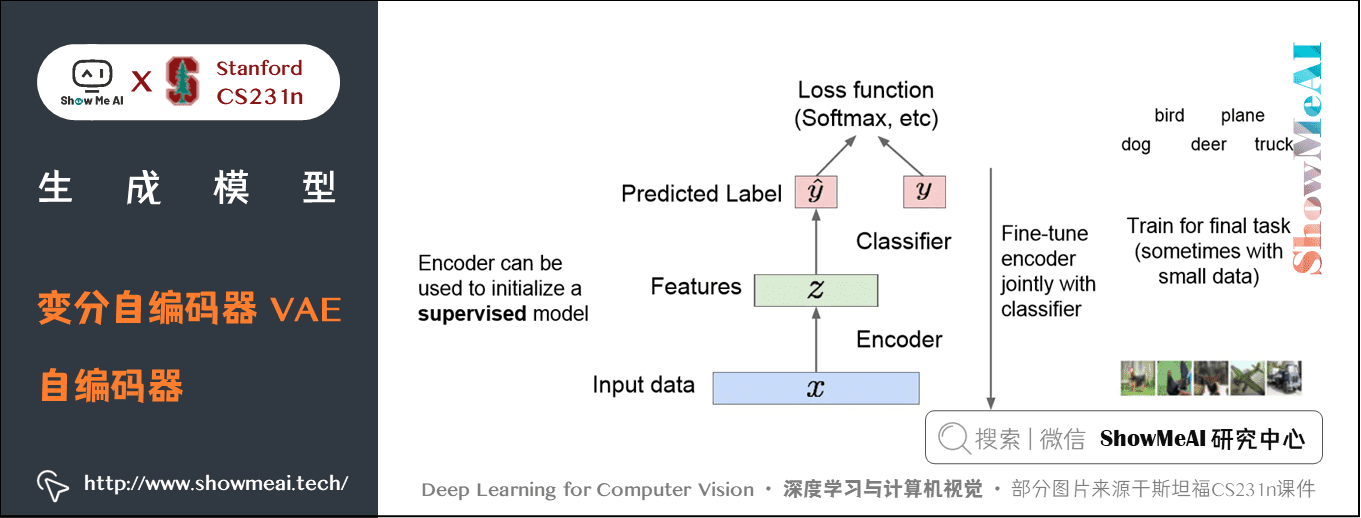
无标签数据得到的模型,可以帮助我们得到普适特征(比如上述自编码器映射得到的特征),它们作为监督学习的输入是非常有效的(有些场景下监督学习可能只有很少的带标签的训练数据,少量的数据很难训练模型,可能会出现过拟合等其他一些问题),通过上述方式得到的特征可以很好地初始化下游监督学习任务的网络。
自编码器具有重构数据、学习数据特征、初始化一个监督模型的能力。这些学习到的特征具有能捕捉训练数据中蕴含的变化因素的能力。我们获得了一个含有训练数据中变化因子的隐变量 \(z\) 。
VAE模型的思路是,如果我们无法直接获得样本 \(x\) 的分布,那么我们可以假设存在一个 \(x\) 对应的隐式表征 \(z\) , \(z\) 的分布是一个先验分布(比如高斯分布或其他简单的分布)。
举例来说,如果我们想要生成微笑的人脸, \(z\) 代表的是眉毛的位置,嘴角上扬的弧度,它经过解码网络后,能够映射得到 \(x\) 的近似真实分布。那在样本生成阶段,我们可以通过标准正态分布采样得到 \(z\) ,然后解码得到样本近似分布,再在此分布上采样来生成样本。
对于这个采样过程,真实的参数是 \(\theta \ast\) ,是有关于先验假设和条件概率分布的参数,我们的目的在于获得一个样本生成式模型,从而利用它来生成新的数据,真实参数是我们想要估计并得出的。
我们表示这个生成式模型的方法是:选一个简单的关于 \(z\) 的先验分布,例如高斯分布,对于给定 \(z\) 的 \(x\) 的条件概率分布 \(p(x \mid z)\) 很复杂,我们会使用神经网络来对 \(p(x \mid z)\) 进行建模。
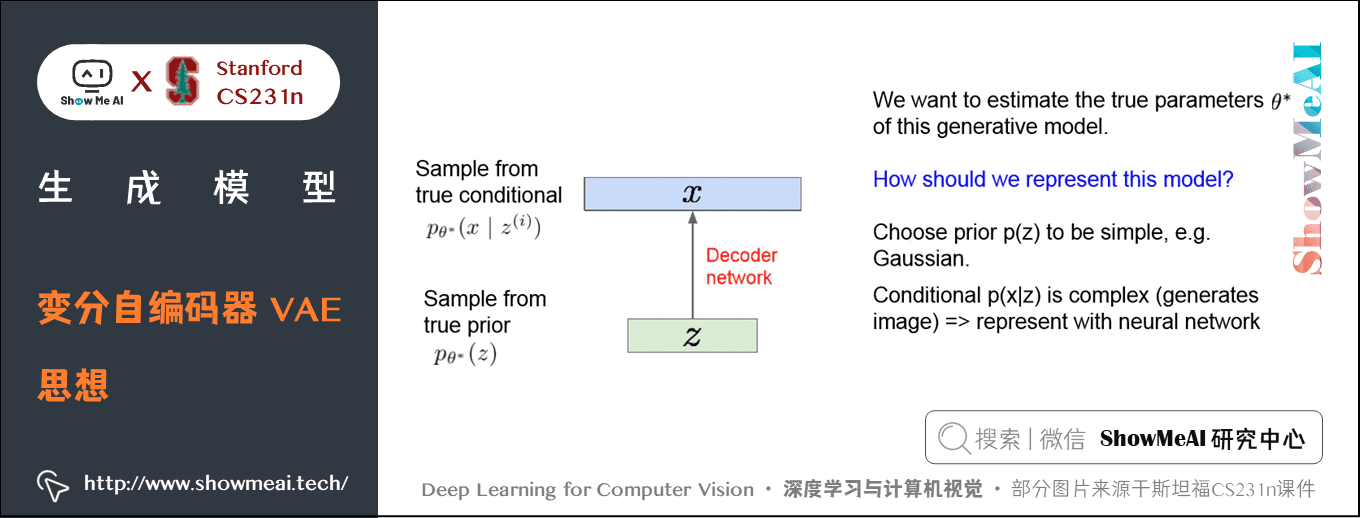
我们的目标是:从一堆样本中学习出解码网络的参数,使得在标准高斯分布上采样得到的 \(z\) ,经过解码后得到的 \(x\) 的分布,刚好近似于 \(x\) 的真实分布。
我们通过「最大化样本 \(x\) 的似然 \(P(x)\)」来达到上述目标。 在已经给定隐变量 \(z\) 的情况下,写出 \(x\) 的分布 \(p\) 并对所有可能的 \(z\) 值取期望,因为 \(z\) 值是连续的所以表达式是一个积分:
问题是利用求导来直接求最大化的似然,很不好解。
第一项是 \(z\) 的分布 \(p(z)\) ,这里将它简单地设定为高斯分布,所以很容易求;\(p(x \mid z)\) 是一个指定的神经网络解码器,也容易得到。
但是计算所有的 \(z\) 对应的 \(p(x \mid z)\) 很困难,所以无法计算该积分。这样也导致 \(p(z \mid x)\) 是难解的。
解决方法是,在使用神经网络解码器来定义一个对 \(p(x \mid z)\) 建模神经网络的同时,额外定义一个编码器 \(q(z \mid x)\) ,将输入 \(x\) 编码为 \(z\) ,从而得到似然 \(p(z \mid x)\) 。
也就是说我们定义该网络来估计出 \(p(z \mid x)\) ,这个后验密度分布项仍然是难解的,我们用该附加网络来估计该后验分布,这将使我们得到一个数据似然的下界,该下界易解也能优化。
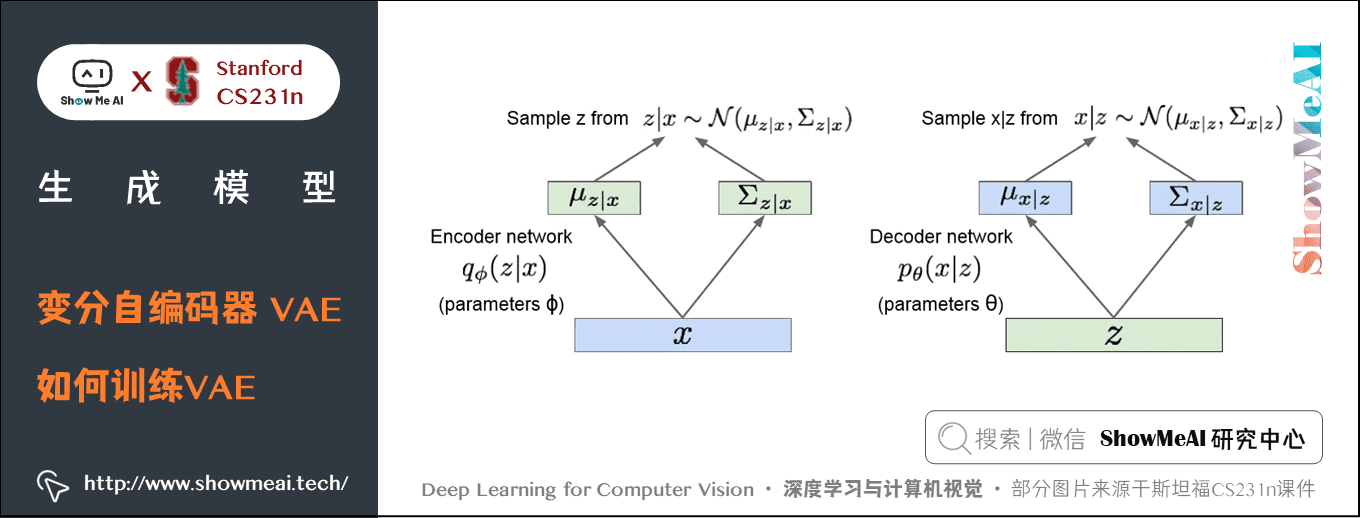
在变分自编码器中我们想得到一个生成数据的概率模型,将输入数据 \(x\) 送入编码器得到一些特征 \(z\) ,然后通过解码器网络把 \(z\) 映射到图像 \(x\) 。
我们这里有编码器网络和解码器网络,将一切参数随机化。参数是 \(\phi\) 的编码器网络 \(q(z \mid x)\) 输出一个均值和一个对角协方差矩阵;解码器网络输入 \(z\) ,输出均值和关于 \(x\) 的对角协方差矩阵。为了得到给定 \(x\) 下的 \(z\) 和给定 \(z\) 下的 \(x\) ,我们会从这些分布(\(p\)和\(q\))中采样,现在我们的编码器和解码器网络所给出的分别是 \(z\) 和 \(x\) 的条件概率分布,并从这些分布中采样从而获得值。
下面是推导过程:
这里引入了一个分布 \(q(z \mid x)\) ,就是编码网络。这里我们暂时只把它当作一个符号,继续推导即可:
对第一项,我们有:
这样我们就得到了 VAE 的核心等式:
注意到这个式子的第三项中,含有 \(p(z \mid x)\) ,而

由于这个积分无法求解出来,因此我们没办法求第三项的梯度。幸运的是,由于第三项是一个KL散度,其恒大于等于 \(0\),因此前两项的和是似然的一个下界。因此我们退而求其次,来最大化似然的下界,间接达到最大化似然的目的。
现在我们引入编码器网络来对 \(q(z \mid x)\) 建模,我们的训练框架如下:
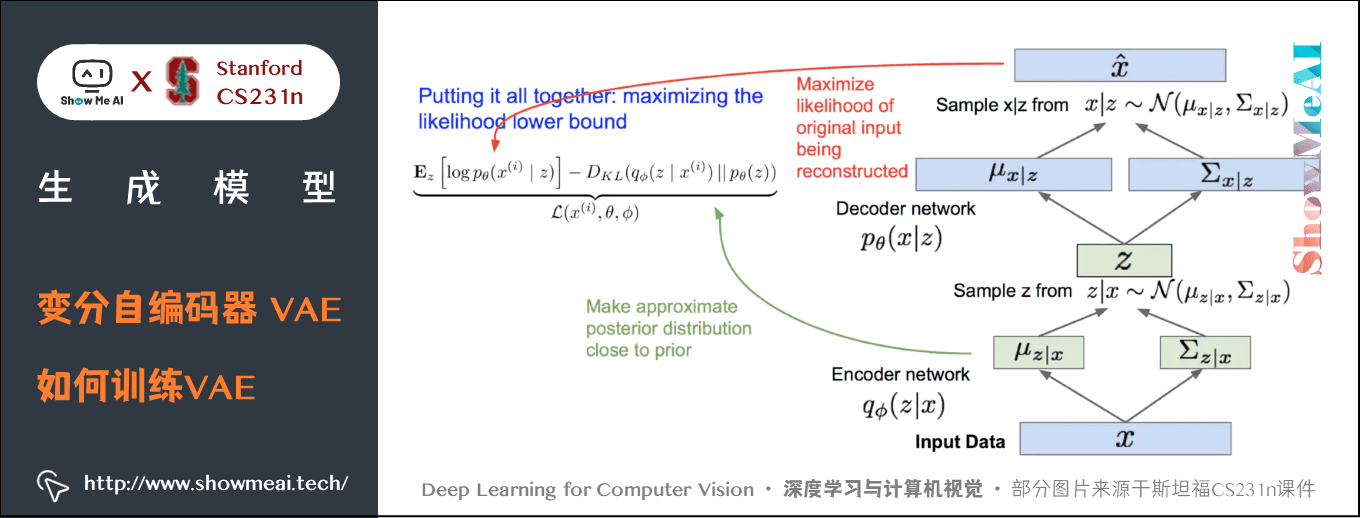
如何得到下界:
① 第1项是对所有采样的 \(z\) 取期望, \(z\) 是 \(x\) 经过编码器网络采样得到,对 \(z\) 采样然后再求所有 \(z\) 对应的 \(p(x \mid z)\) 。让 \(p(x \mid z)\) 变大,就是最大限度地重构数据。
② 第2项是让KL的散度变小,让我们的近似后验分布和先验分布变得相似,意味着我们想让隐变量z遵循我们期望的分布类型。
这个框架就非常类似于自编码器。
其中最大化下界的第一项表示我们要能从解码器最大概率地重构出 \(x\) ,这一步等价于去最小化与样本 \(x\) 的均方误差。最小化下界的第二项则限定了 \(z\) 要遵循我们事先给它指定的分布。
公式是我们要优化及最大化的下界,前向传播按如上流程处理,对输入数据 \(x\) ,让小批量的数据传递经过编码器网络的到 \(q(z \mid x)\) ,通过 \(q(z \mid x)\) 来计算 KL 项,然后根据给定 \(x\) 的 \(z\) 分布对 \(z\) 进行采样,由此获得了隐变量的样本,这些样本可以根据 \(x\) 推断获得;然后把 \(z\) 传递给第二个解码器网络,通过解码器网络 \(x\) 在给定 \(z\) 的条件下的两个参数,均值和协方差,最终可以在给定 \(z\) 的条件下从这个分布中采样得到 \(x\) 。
训练时需要获得该分布,损失项是给定 \(z\) 条件下对训练像素值取对数,损失函数要做的是最大化被重构的原始输入数据的似然;对于每一个小批量的输入我们都计算这一个前向传播过程,取得所有我们需要的项,他们都是可微分的,接下来把他们全部反向传播回去并获得梯度,不断更新我们的参数,包括生成器和解码器网络的参数 \(\theta\) 和 \(\phi\) 从而最大化训练数据的似然。
训练好变分自编码器,当生成数据时只需要用解码器网络,我们在训练阶段就对 \(z\) 采样,而不用从后验分布中采样,在生成阶段会从真实的生成过程中采样。先从设定好的先验分布中采样,接下来对数据 \(x\) 采样。
需要注意的是,这个框架里面,梯度无法通过「采样」这个算子反向传播到编码器网络,因此我们使用一种叫做重采样的 trick。即将 \(z\) 采样的算子分解为:
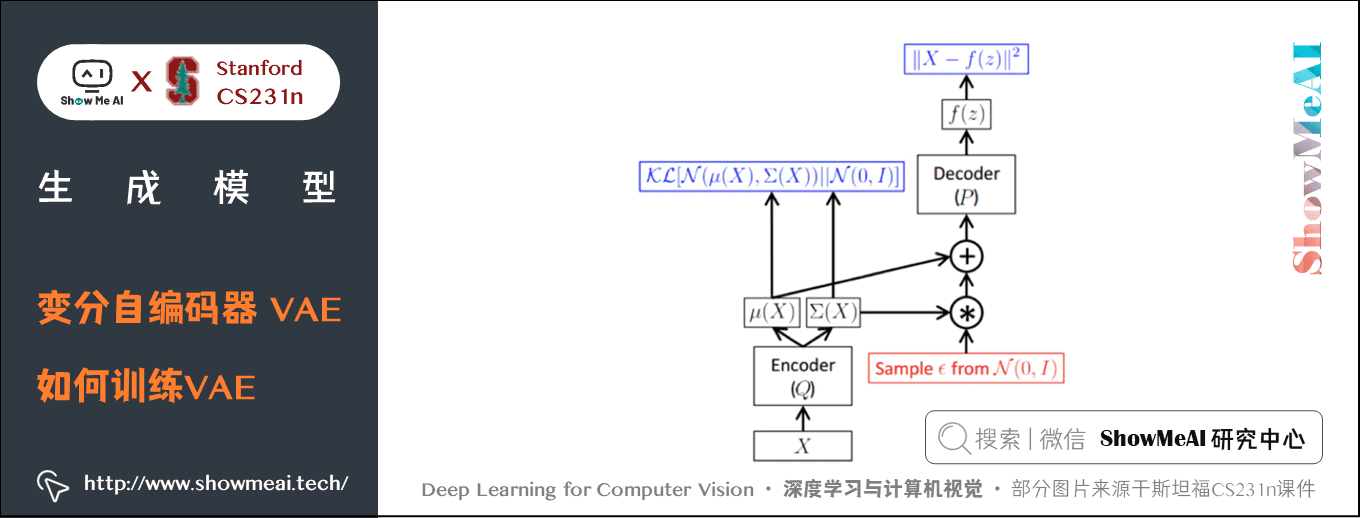
这样梯度不需要经过采样算子就能回流到编码器网络中。
总结一下,VAE 是在原来的自编码器上加了随机成分,我们使用VAE不是直接取得确定的输入 \(x\) 然后获得特征 \(z\) 最后再重构 \(x\) ,而是采用随机分布和采样的思想,这样我们就能生成数据。 为了训练模型 VAEs,我们定义了一个难解的密度分布,我们推导出一个下界然后优化下界,下界是变化的,「变分」指的是用近似来解决这些难解的表达式,这是模型被称为变分自动编码器的原因。
VAEs优点
VAEs 就生成式模型来说是一种有据可循的方法,它使得查询推断称为可能,如此一来便能够推断出像 \(q(z \mid x)\) 这样的分布,这些东西对其他任务来说会是很有用的特征表征。
VAEs缺点
最大化似然下界思想是OK的,但是不像 PixelRNN 和 PixelCNN 那样精准评估。而 VAE 相对后续会讲到的GAN等方法,生成的图像结果更模糊。
我们之前的 PixelCNN 和 PixelRNN 定义了一个易于处理的密度函数,通过密度函数优化训练数据的似然;VAEs有一个额外定义的隐变量 \(z\) ,有了 \(z\) 以后获得了很多的有利性质但是我们也有了一个难解的密度函数,对于该函数我们不能直接优化,我们推到了一个似然函数的下界,然后对它进行优化。
现在我们放弃显式地对密度函数建模,我们想要得到的是从分布中采样并获得质量良好的样本。GANs 中不再在显式的密度函数上花费精力,而是采用一个博弈论的方法,并且模型将会习得从训练分布中生成数据,具体的实现是基于「生成器」和「判别器」这一对博弈玩家。
相比变分自编码器,GAN 的核心思路非常简单。
在 GAN 中我们定义了两个网络:「生成器」和「判别器」。
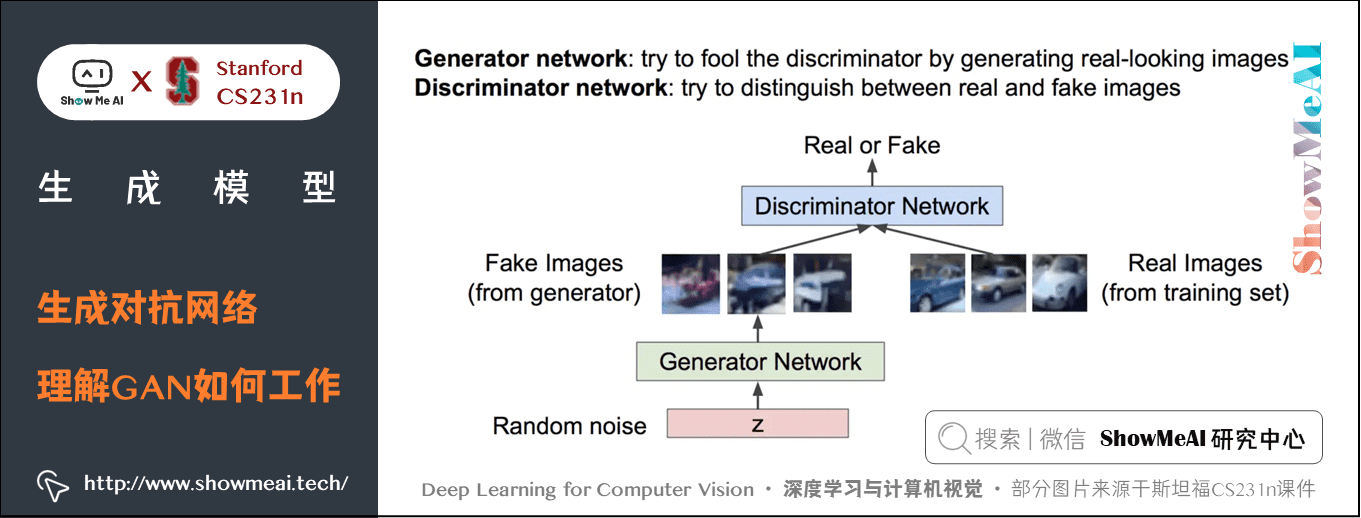
这种对抗形式的目标可以写成如下形式:

现在我们有两个玩家,通过一个 \(\min \max\) 博弈公式联合训练这两个网络,该 \(\min \max\) 目标函数就是如图所示的公式,我们的目标是:
公式中各项的含义:
对该过程的解释:我们的判别器的目的是最大化目标函数也就是在 \(\theta_d\) 上取最大值,这样一来 \(D(x)\) 就会接近1,也就是使判别结果接近真,因而该值对于真实数据应该相当高,这样一来 \(D(G(z))\) 的值也就是判别器对伪造数据输出就会相应减小,我们希望这一值接近于 \(0\)。
如果我们能最大化这一结果,就意味着判别器能够很好的区别真实数据和伪造数据。
对于生成器来说,我们希望它最小化该目标函数,也就是让 \(D(G(z))\) 接近 \(1\),如果 \(D(G(z))\) 接近 \(1\),那么用 \(1\) 减去它就会很小,判别器网络就会把伪造数据视为真实数据,也就意味着我们的生成器在生成真实样本。
从数据准备上看,整个过程是一个无监督学习,我们无需人工给每个图片打上标签。具体网络学习时候,我们会把生成器生成的图片标记为 \(0\)(对应假图片),训练集标记为 \(1\)(都是真图片)。
判别器的损失函数会使用上述信息,判别器是一个分类器,我们希望它能经过训练获得分辨能力:对生成器生成的图片输出 \(0\),而对真实图片输出 \(1\)。
对于GAN,我们最初能想到的训练方式如下:
① 对判别器进行梯度上升,学习到 \(\theta_d\) 来最大化该目标函数;
② 对生成器进行梯度下降, \(\theta_g\) 进行梯度下降最小化目标函数(此时目标函数如下的部分,因为只有它与 \(\theta_g\) 有关)
不断在上述 ① 和 ② 之间重复。
这里有个trick:我们观察生成器的损失函数形状如下:
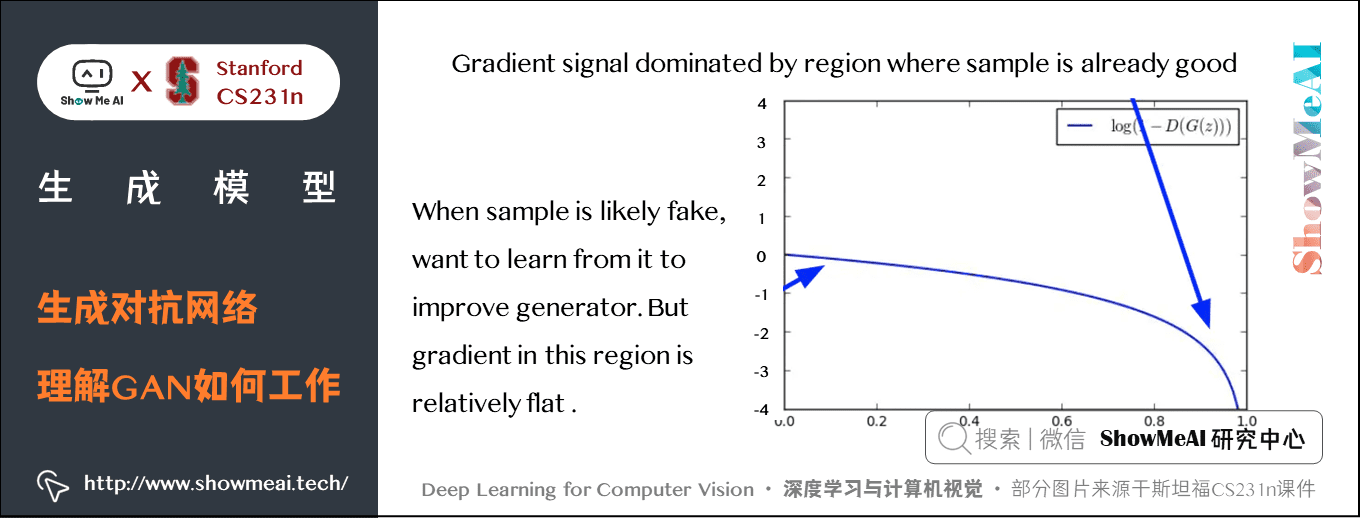
发现当生成器效果不好(\(D(G(z)\) 接近 \(0\))时,梯度非常平缓;当生成器效果好(\(D(G(z)\)接近\(1\))时,梯度很陡峭。这就与我们期望的相反了,我们希望在生成器效果不好的时候梯度更陡峭,这样能学到更多。因此我们使用下面的目标函数来替代原来的生成器损失:
这样就使得在生成器效果不好时具有较大的梯度。此外,联合训练两个网络很有挑战,交替训练的方式不可能一次训练两个网络,还有损失函数的函数空间会影响训练的动态过程。
在每一个训练迭代期都先训练判别器网络,然后训练生成器网络,GAN 的总体训练过程如下:
训练判别器
此时我们有了一个小批量伪造图像和小批量真实图像,我们有这些小批量数据在判别器生进行一次梯度计算,接下来利用梯度信息更新判别器参数,按照以上步骤迭代几次来训练判别器。
训练生成器
训练 GAN 的过程会交替进行上述两个步骤。

训练完毕后,就可以用生成器来生成比较逼真的样本了。
可以点击 B站 查看视频的【双语字幕】版本
[video(video-ohaiAwnB-1655045024553)(type-bilibili)(url-https://player.bilibili.com/player.html?aid=759478950&page=13)(image-https://img-blog.csdnimg.cn/img_convert/4d2759bf157ddfb1b29f92f922554f9d.png)(title-【字幕+资料下载】斯坦福CS231n | 面向视觉识别的卷积神经网络 (2017·全16讲))]
本篇讲了三种目前最常用生成模型:

我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我是Rails的新手,所以请原谅简单的问题。我正在为一家公司创建一个网站。那家公司想在网站上展示它的客户。我想让客户自己管理这个。我正在为“客户”生成一个表格,我想要的三列是:公司名称、公司描述和Logo。对于名称,我使用的是name:string但不确定如何在脚本/生成脚手架终端命令中最好地创建描述列(因为我打算将其设置为文本区域)和图片。我怀疑描述(我想成为一个文本区域)应该仍然是描述:字符串,然后以实际形式进行调整。不确定如何处理图片字段。那么……说来话长:我在脚手架命令中输入什么来生成描述和图片列? 最佳答案 对于“文本”数
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
有这些railscast。http://railscasts.com/episodes/218-making-generators-in-rails-3有了这个,你就会知道如何创建样式表和脚手架生成器。http://railscasts.com/episodes/216-generators-in-rails-3通过这个,您可以了解如何添加一些文件来修改脚手架View。我想把两者结合起来。我想创建一个生成器,它也可以创建脚手架View。有点像RyanBates漂亮的生成器或web_app_themegem(https://github.com/pilu/web-app-theme)。我
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我