RTL8201F-phy芯片MDIO接口FPGA配置RMII模式
介绍
以太网物理层芯片支持10Mbps/100Mbps,支持mii、rmii接口;电路图上配置为RMII接口,寄存器也需要配置。
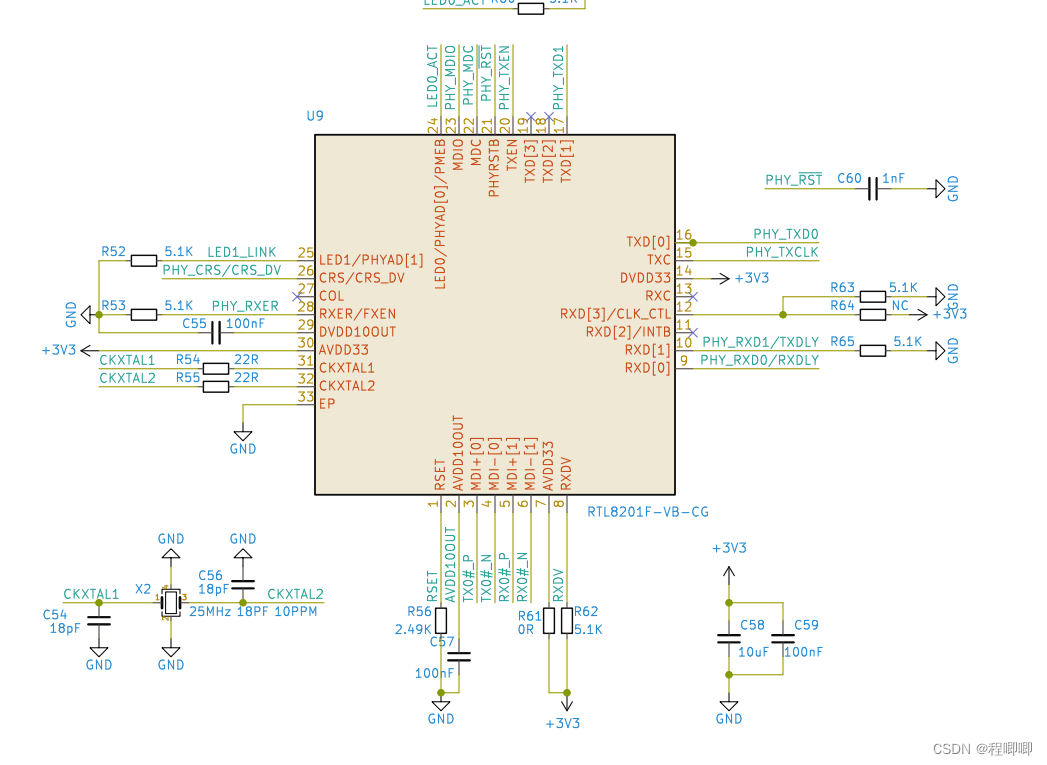
phy芯片使用的是rmii接口,用mdio配置,配置方法比较简单,先看MDIO接口时序:

MDC频率最高为2.5Mhz,phy在上升沿锁存MDIO的数据

phy address 是在挂多个phy芯片的时候用来识别phy的,下面看配置寄存器有哪些:
PHY配置寄存器
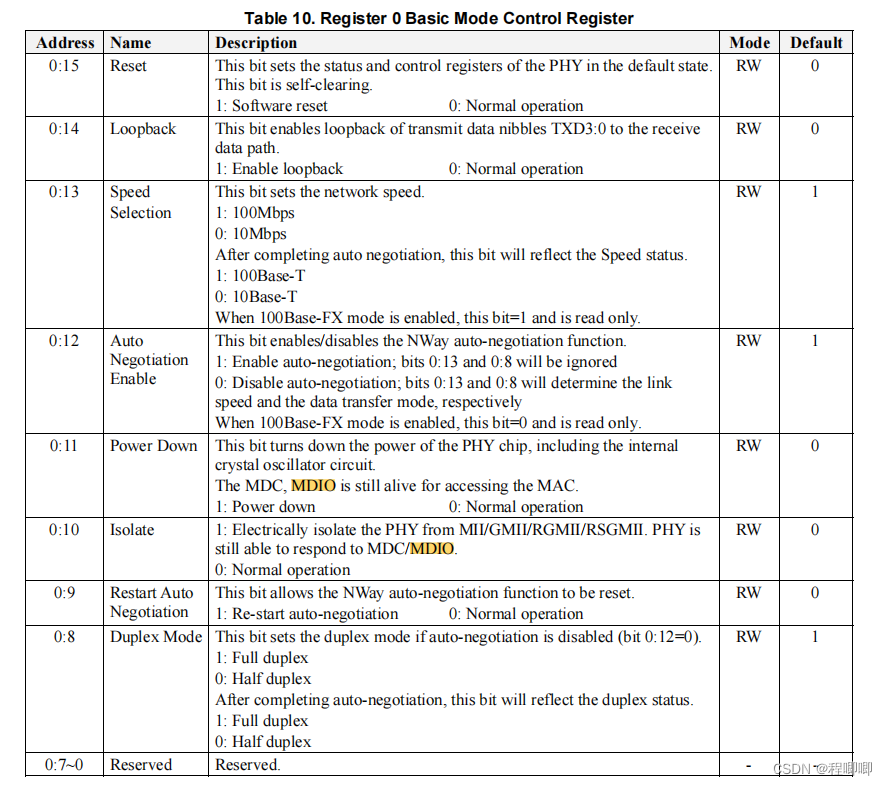
每个寄存器都有默认值,不配置也可以运行,当要修改配置或者查看phy发送接收芯片状态的时候就要使用mdio接口。
下面是写时序的例程可以参考一下:
module mdio_master (
input wire clk,
input wire rst,
/*
* Host interface
*/
input wire [4:0] cmd_phy_addr,
input wire [4:0] cmd_reg_addr,
input wire [15:0] cmd_data,
input wire [1:0] cmd_opcode,
input wire cmd_valid,
output wire cmd_ready,
output wire [15:0] data_out,
output wire data_out_valid,
input wire data_out_ready,
/*
* MDIO to PHY
*/
output wire mdc_o,
input wire mdio_i,
output wire mdio_o,
output wire mdio_t,
/*
* Status
*/
output wire busy,
/*
* Configuration
*/
input wire [7:0] prescale
);
localparam [1:0]
STATE_IDLE = 2'd0,
STATE_PREAMBLE = 2'd1,
STATE_TRANSFER = 2'd2;
reg [1:0] state_reg = STATE_IDLE, state_next;
reg [16:0] count_reg = 16'd0, count_next;
reg [6:0] bit_count_reg = 6'd0, bit_count_next;
reg cycle_reg = 1'b0, cycle_next;
reg [31:0] data_reg = 32'd0, data_next;
reg [1:0] op_reg = 2'b00, op_next;
reg cmd_ready_reg = 1'b0, cmd_ready_next;
reg [15:0] data_out_reg = 15'd0, data_out_next;
reg data_out_valid_reg = 1'b0, data_out_valid_next;
reg mdio_i_reg = 1'b1;
reg mdc_o_reg = 1'b0, mdc_o_next;
reg mdio_o_reg = 1'b0, mdio_o_next;
reg mdio_t_reg = 1'b1, mdio_t_next;
reg busy_reg = 1'b0;
assign cmd_ready = cmd_ready_reg;
assign data_out = data_out_reg;
assign data_out_valid = data_out_valid_reg;
assign mdc_o = mdc_o_reg;
assign mdio_o = mdio_o_reg;
assign mdio_t = mdio_t_reg;
assign busy = busy_reg;
always @* begin
state_next = STATE_IDLE;
count_next = count_reg;
bit_count_next = bit_count_reg;
cycle_next = cycle_reg;
data_next = data_reg;
op_next = op_reg;
cmd_ready_next = 1'b0;
data_out_next = data_out_reg;
data_out_valid_next = data_out_valid_reg & ~data_out_ready;
mdc_o_next = mdc_o_reg;
mdio_o_next = mdio_o_reg;
mdio_t_next = mdio_t_reg;
if (count_reg > 16'd0) begin
count_next = count_reg - 16'd1;
state_next = state_reg;
end else if (cycle_reg) begin
cycle_next = 1'b0;
mdc_o_next = 1'b1;
count_next = prescale;
state_next = state_reg;
end else begin
mdc_o_next = 1'b0;
case (state_reg)
STATE_IDLE: begin
// idle - accept new command
cmd_ready_next = ~data_out_valid;
if (cmd_ready & cmd_valid) begin
cmd_ready_next = 1'b0;
data_next = {2'b01, cmd_opcode, cmd_phy_addr, cmd_reg_addr, 2'b10, cmd_data};
op_next = cmd_opcode;
mdio_t_next = 1'b0;
mdio_o_next = 1'b1;
bit_count_next = 6'd32;
cycle_next = 1'b1;
count_next = prescale;
state_next = STATE_PREAMBLE;
end else begin
state_next = STATE_IDLE;
end
end
STATE_PREAMBLE: begin
cycle_next = 1'b1;
count_next = prescale;
if (bit_count_reg > 6'd1) begin
bit_count_next = bit_count_reg - 6'd1;
state_next = STATE_PREAMBLE;
end else begin
bit_count_next = 6'd32;
{mdio_o_next, data_next} = {data_reg, mdio_i_reg};
state_next = STATE_TRANSFER;
end
end
STATE_TRANSFER: begin
cycle_next = 1'b1;
count_next = prescale;
if ((op_reg == 2'b10 || op_reg == 2'b11) && bit_count_reg == 6'd19) begin
mdio_t_next = 1'b1;
end
if (bit_count_reg > 6'd1) begin
bit_count_next = bit_count_reg - 6'd1;
{mdio_o_next, data_next} = {data_reg, mdio_i_reg};
state_next = STATE_TRANSFER;
end else begin
if (op_reg == 2'b10 || op_reg == 2'b11) begin
data_out_next = data_reg[15:0];
data_out_valid_next = 1'b1;
end
mdio_t_next = 1'b1;
state_next = STATE_IDLE;
end
end
endcase
end
end
always @(posedge clk) begin
if (rst) begin
state_reg <= STATE_IDLE;
count_reg <= 16'd0;
bit_count_reg <= 6'd0;
cycle_reg <= 1'b0;
cmd_ready_reg <= 1'b0;
data_out_valid_reg <= 1'b0;
mdc_o_reg <= 1'b0;
mdio_o_reg <= 1'b0;
mdio_t_reg <= 1'b1;
busy_reg <= 1'b0;
end else begin
state_reg <= state_next;
count_reg <= count_next;
bit_count_reg <= bit_count_next;
cycle_reg <= cycle_next;
cmd_ready_reg <= cmd_ready_next;
data_out_valid_reg <= data_out_valid_next;
mdc_o_reg <= mdc_o_next;
mdio_o_reg <= mdio_o_next;
mdio_t_reg <= mdio_t_next;
busy_reg <= (state_next != STATE_IDLE || count_reg != 0 || cycle_reg || mdc_o);
end
data_reg <= data_next;
op_reg <= op_next;
data_out_reg <= data_out_next;
mdio_i_reg <= mdio_i;
end
endmodule
读时序图如下:

读时序和写时序一样,FPGA在上升沿锁存MDIO的数据。
**
**因为phy芯片电路配置的是rmii接口,需要使用mdio接口配置成rmii模式:
1)Register 0 Basic Mode Control Register:配置成默认值就可以;
2)Register 31 Page Select Register:要配置成RMII需要跳转到 RMII Mode Setting Register,后者属于page7, page sel为7;
3)Page 7 Register 16 RMII Mode Setting Register (RMSR)
电路图上晶振25m输出到CKXTAL2 pin.,需要配成7FFB;
Note: Set Page7, Register 16 to ‘7FFB’ when an external clock (25MHz and 50MHz) inputs to the CKXTAL2 pin.

然后再把register31配置成0就完成配置了。
链接如下:
https://download.csdn.net/download/weixin_39577718/86912489
在Rails中,什么是集成更新模型某些元素的UDP监听过程的最佳方式(特别是它将向其中一个表添加行)。简单的答案似乎是在同一个进程中使用UDP套接字对象启动一个线程,但我什至不清楚我应该在哪里做适合Rails方式的事情。有没有一种巧妙的方法来开始收听UDP?具体来说,我希望能够编写一个UDPController并在每个数据报消息上调用一个特定的方法。理想情况下,我希望避免在UDP上使用HTTP(因为它会浪费一些在这种情况下非常宝贵的空间),但我完全控制消息格式,因此我可以为Rails提供它需要的任何信息。 最佳答案 Rails是一个
FPGA时钟和时钟域时钟树所谓时钟树为FPGA内部资源,分:全局时钟树,区域时钟树,IO时钟树原则上优先使用全局时钟树,在GT接口上使用IO时钟树,一般工具也会对GT时钟加以限制;时钟树使用方式正确的物理连接FPGA会由物理管脚专门用于全局时钟设置,通过查询数据手册可以在PCB设计阶段进行确认,当外部时钟接入此管脚时,工具会自动占有全局时钟树资源,当接入普通信号时不会分配时钟树资源;恰当的代码描述原语的使用,即BUFG的使用,可以将PLL的输出等内部时钟进行全局时钟资源的分配;IO时钟资源需要参考相应接口手册,以ultrascale的GTH为例,其JESD204的时钟方案针对不同的子类会由不同
外部SPIFLASH:MicronN25Q128A13ESE40G(128Mbit(16MByte))FPGA:XC7A100T CPU:Microblaze第一种情况:Microblaze在简单的应用,比如运行LED,IIC,SPI,UART之类的低俗接口驱动,或做一些简单的辅助型工作时,一般生成的applicationelf文件都不大,在10几KB或者几十,百几KB,此时使用FPGA内部的BRAM资源已经足够。XC7A100T本身就有600几KB的BRAM资源。这种情况下直接将硬件流文件和elf文件合并为download.bit文件,在直接烧录到外部SPIFLAH即可。1.Xilinx--
1FPGA启动流程图1 7SerialsFPGA配置流程1.1DevicePower-Up1.2ClearConfigurationMemory在上电后的任何时间内,可以对Slave-FPGA配置存储器(BlockRAM)进行复位处理。复位方式是将PROGRAM_B信号拉低(下降沿有效)。1.3SampleModePins当复位完成后,INIT_B恢复高电平,Slave-FPGA对M[2:0]模式引脚进行采样,然后开始在CCLK上升沿接收配置数据。1.4Synchronization在接收配置数据前,Slave-FPGA首先进行总线位宽检测。主机发送的配置文件中,“BusWidthAutoDe
文章目录1、行为级与RTL级的区别1.1RTL级(可综合成门级电路)1.2行为级2、关于LUT2.1LUT是什么2.2N维查找表2.3FPGA中的LUT3、`include和条件编译4、写异步D触发器(扬智电子笔试)4.1八位同步D触发器4.2具有异步清零,同步复位信号功能的D触发器5、静态、动态时序分析的优缺点(威盛VIA2003.11.06上海笔试试题)6、采用二选一多路器mux2和inv非门实现异或操作(飞利浦-大唐笔试)7、寄存器和锁存器的区别,为什么多用寄存器,行为级描述中锁存器如何产生8、D触发器实现2分频的Verilog描述(汉王笔试)9、D触发器实现带同步高置数和异步高复位端的
我想将Jqueryslider范围更改为RTL。我正在使用这个:http://jqueryui.com/slider/#rangeJ查询代码:$(function(){$("#slider-range").slider({range:true,min:0,max:1000000,values:[100000,500000],slide:function(event,ui){$("#amount").val(addCommas(ui.values[1])+"تومان"+addCommas(ui.values[0])+"تومان");}});$("#amount").val(addCo
我在谷歌浏览器上看到一个错误。在ChromeV31上运行以下html代码ChromescrollWidthissue当我将主体方向从ltr更改为rtl时,父div的scrollWith是不同的。这不会发生在FireFoxV25或InternetExplorerV10上。我在chromeissuetracker上报告了这个问题.我的问题是如何使用css或javascript解决这个问题? 最佳答案 尝试在子元素中使用clientWidth,您将在rtl和ltr中获得1080,希望这是一个足够好的解决方案,直到他们修复chrome上的错
如何使用FPGA加速机器学习算法如何使用FPGA加速机器学习算法 当前,AI因为其CNN(卷积神经网络)算法出色的表现在图像识别领域占有举足轻重的地位。基本的CNN算法需要大量的计算和数据重用,非常适合使用FPGA来实现。上个月,RalphWittig(XilinxCTOOffice的卓越工程师)在2016年OpenPower峰会上发表了约20分钟时长的演讲并讨论了包括清华大学在内的中国各大学研究CNN的一些成果。在这项研究中出现了一些和CNN算法实现能耗相关的几个有趣的结论:①限定使用片上Memory;②使用更小的乘法器;③进行定点匹配:相对于32位定点或浮点计算,将定点计算结果精度降为16
当主体方向为rtl时,div的scrollLeft属性似乎在不同的浏览器中返回不同的值。这里可以看到一个例子-http://jsfiddle.net/auVLZ/2/body{direction:rtl;}div.Container{border:5pxsolid#F00;width:500px;height:400px;overflow:auto;}div.Content{background-color:#00F;width:900px;height:380px;}$(document).ready(function(){$("#showScrollLeft").click(f
是否可以在Node.js上使用WebRTC数据通道来模仿WebSockets的功能,但不使用UDP?本质上,我想要一个运行Node.js的服务器,浏览器客户端可以通过JavaScript建立全双工双向UDP连接。我的问题和thisone一样从8个月前。我重新发布它是因为唯一的答案是:Yes,intheoryyoushouldbeabletotodothis.However,you'llneedanodemodulethatsupportsWebRTCdatachannels,sothatyoucanconnecttoitlikeanyotherpeer.Unfortunately,sc