最近想了解如何Java对接微信平台,快速搭建完整项目开发,发现网上有很对开源的这类二开源码。https://gitee.com/luozijing123/JooLun-wx(Frok)就是其中一个,但是这里面并没有实现多租户的设计,后续在git上发现了一个又一个开源,是基于JooLun-wx的基础上继续封装组件,并且另外加了很多功能的开源项目,具体地址是https://github.com/YunaiV/ruoyi-vue-pro,具体了解下该项目是如何实现多租户的。
多租户的设计主要还是在数据隔离上,有以下隔离方式:
1.表行级别数据隔离,同一张表存储不同租户数据,加TenantID多租户的数据字段,优点:支持的租户数量最多、简单,节省资源 缺点:不适合数剧量大、数据备份和恢复最困难、数据不安全,一故障全部故障
2.同库不同表数据隔离,每一张表存储不同租户数据,利用分表实现,优点:增大了存储数据量、隔离性较好 缺点:支持的租户数量少、数据恢复和统计困难
3.不同库不同表数据隔离,每个库存储不同租户数据,利用分库分表实现,优点:存储数据量最大、隔离性最好 、故障恢复简单 缺点:支持的租户数量少、成本高
租户应该是一个集体的概念,包含了用户、角色、组织等,并且能够实现数据隔离和资源隔离的特性,每个租户之间操作不影响且不相互可见。真正实现起来的该架构还是挺难的。首先是租户权限和角色模型的定义,这里介绍下ruoyi-vue-pro的租户业务模型。同一租户,这里可以理解统一公司ID下的用户或者员工具有角色、岗位、部门属性,不同的岗位对应相应角色,角色拥有相应的操作权限或者菜单可见权限,同时,在不同部门间的数据权限控制,不同部门是不可见的(mybatisPlus interceptor控制),也可以自定义其他数据权限,例如加上用户表的UserID字段,表示只有自己才能编辑改数据。
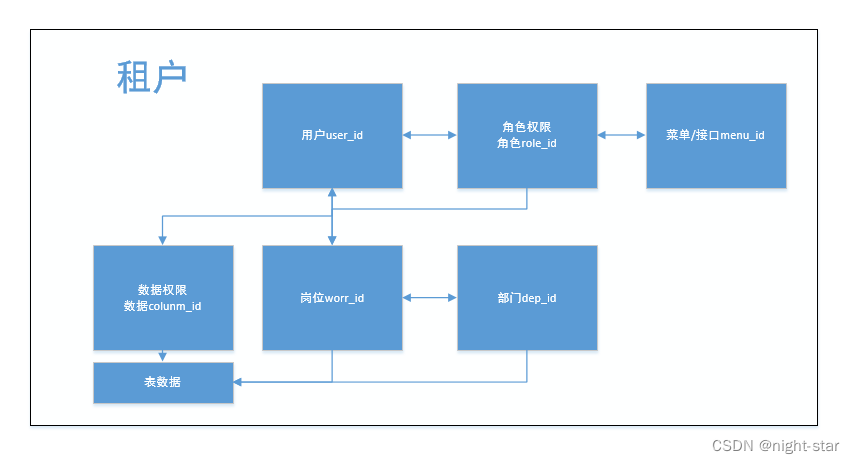
方案大致实现是利用threadLocal存储前端的放置在请求头中的租户ID,然后在springSecurity中的过滤器进行租户的验证。
mybatisPlus interceptor提供了一个拦截器,提供了TenantId 行级处理租户的功能,定义了一些获取租户 ID、获取租户字段名、忽略表的一些方法,这个接口TenantLineHandler需要用户自己去实现。
/**
* 基于 MyBatis Plus 多租户的功能,实现 DB 层面的多租户的功能
*
* @author 芋道源码
*/
@AllArgsConstructor
public class TenantDatabaseInterceptor implements TenantLineHandler {
private final TenantProperties properties;
@Override
public Expression getTenantId() {
return new LongValue( TenantContextHolder.getRequiredTenantId());
}
@Override
public boolean ignoreTable(String tableName) {
return TenantContextHolder.isIgnore() // 情况一,全局忽略多租户
|| CollUtil.contains(properties.getIgnoreTables(), tableName); // 情况二,忽略多租户的表
}
}
TenantLineInnerInterceptor就是实现多租户的插件了,其继承了JsqlParserSupport类,实现了InnerInterceptor接口。对sql进行处理,在查询和更新sqk中家伙是那个where TenantId = ? 条件,以select sql为例
protected void processPlainSelect(PlainSelect plainSelect) {
FromItem fromItem = plainSelect.getFromItem();
Expression where = plainSelect.getWhere();
this.processWhereSubSelect(where);
if (fromItem instanceof Table) {
Table fromTable = (Table)fromItem;
if (!this.tenantLineHandler.ignoreTable(fromTable.getName())) {
plainSelect.setWhere(this.builderExpression(where, fromTable));
}
} else {
this.processFromItem(fromItem);
}
List<SelectItem> selectItems = plainSelect.getSelectItems();
if (CollectionUtils.isNotEmpty(selectItems)) {
selectItems.forEach(this::processSelectItem);
}
List<Join> joins = plainSelect.getJoins();
if (CollectionUtils.isNotEmpty(joins)) {
this.processJoins(joins);
}
}
protected Expression builderExpression(Expression currentExpression, Table table) {
EqualsTo equalsTo = new EqualsTo();
equalsTo.setLeftExpression(this.getAliasColumn(table));
equalsTo.setRightExpression(this.tenantLineHandler.getTenantId());// 上面的TenantDatabaseInterceptor,获取TenantId拼接
if (currentExpression == null) {
return equalsTo;
} else {
return currentExpression instanceof OrExpression ? new AndExpression(new Parenthesis(currentExpression), equalsTo) : new AndExpression(currentExpression, equalsTo);
}
}
具体的方案可以在 https://doc.iocoder.cn/saas-tenant/页面看到。另外,数据权限的方案也是利用mybatisPlus的拦截器实现, 对sql进行拦截,根据用户相关权限拼接sql,做到数据访问的控制。
shardingJDBC可以具备下面能力,
读写分离 配置主从库
分库分表 配置多主库 多主表 路由规则(例如根据主键%2路由,分别配置两个主库,两个主表 2X2)
配置分库分表或者同库同表 进行读写分离
考虑部署可能没有那么多数据库实例来,简单可以选择同库分表方案来实现,根据租户ID来实现分表策略,配置文件如下,这里租户ID的生成是根据%2来判断入哪张表,这里真正实施的时候需要将所有租户的关联表,例如用户表、业务表等都需要创建分表来存储数据。这样适合数据量不多、租户表不多的情况。
server.port=8900
#只有主库
spring.shardingsphere.datasource.names=master
spring.shardingsphere.datasource.master.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master.jdbc-url=jdbc:mysql://${dbIp}:3306/tenant_common?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=false
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=123456
#配置路由策略,分配数据落的表
spring.shardingsphere.sharding.tables.sys_user.actual-data-nodes=master0.sys_user$->{0..1}
spring.shardingsphere.sharding.tables.sys_user.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.sys_user.table-strategy.inline.algorithm-expression=sys_user$->{id % 2}
#\u6253\u5370sql
spring.shardingsphere.props.sql.show=true
spring.main.allow-bean-definition-overriding=true
#\u8C03\u6574\u65E5\u5FD7\u4E3Adebug
logging.level.com.yisu= debug
也可以采用同一数据实例,多个数据源库来分租户,可以解决租户业务表隔离和数据量存储少的问题,这样就要配多个数据库源连接实例。
server.port=8900
#数据源定义
spring.shardingsphere.datasource.names=master0,slave0,master1,slave1
# 数据源 主库0
spring.shardingsphere.datasource.master0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master0.jdbc-url=jdbc:mysql://${dbIp}:3306/master0?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=false
spring.shardingsphere.datasource.master0.username=root
spring.shardingsphere.datasource.master0.password=123456
# 数据源 主库1
spring.shardingsphere.datasource.master1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master1.jdbc-url=jdbc:mysql://${dbIp}:3306/master1?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=false
spring.shardingsphere.datasource.master1.username=root
spring.shardingsphere.datasource.master1.password=123456
# 数据源 从库0
spring.shardingsphere.datasource.slave0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave0.jdbc-url=jdbc:mysql://${dbIp}:3306/slave0?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=false
spring.shardingsphere.datasource.slave0.username=root
spring.shardingsphere.datasource.slave0.password=123456
# 数据源 从库1
spring.shardingsphere.datasource.slave1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.slave1.jdbc-url=jdbc:mysql://${dbIp}:3306/slave1?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=false
spring.shardingsphere.datasource.slave1.username=root
spring.shardingsphere.datasource.slave1.password=123456
#设置master0为主库,slave0为它的从库
spring.shardingsphere.sharding.master-slave-rules.master0.master-data-source-name=master0
spring.shardingsphere.sharding.master-slave-rules.master0.slave-data-source-names=slave0
#设置master1为主库,slave1为它的从库
spring.shardingsphere.sharding.master-slave-rules.master1.master-data-source-name=master1
spring.shardingsphere.sharding.master-slave-rules.master1.slave-data-source-names=slave1
#根据id分库
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=master$->{id % 2}
#根据id分表
spring.shardingsphere.sharding.tables.sys_user.actual-data-nodes=master$->{0..1}.sys_user$->{0..1}
spring.shardingsphere.sharding.tables.sys_user.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.sys_user.table-strategy.inline.algorithm-expression=sys_user$->{id % 2}
#打印sql
spring.shardingsphere.props.sql.show=true
spring.main.allow-bean-definition-overriding=true
#调整日志为debug
logging.level.com.yisu= debug
实际多租户方案感觉第一种可行性更高,只需要在同一张表里面即可存储上千万租户数据,采用第二种或者第三种,成本太高,尤其是租户数量上来的时候,需要维护上千个数据库实例,维护成本相当高。sharding-JDBC的读写分离或者分库分表,主要还是用来切割大表数据,优化数据库读写效率。
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候