今天开始用VS(C#)二次开发海康相机,上来就遇到问题。作为小白我也是跟着某站的视频课入门,下载了海康官方提供的MVS,附上链接。打开就是这样(第二页是这个第一页是VM):
下载安装完成后按照这个路径打开文件夹:\\MVS\Development\Samples\C# (你的mvs安装目录),用VS打开这个叫“CSharpDotNetSamples_VS2008”的文件。是这个界面:
我好奇的点击“启动”按钮等待惊喜的到来,然后我就忙了一个半小时。。。
bug来了!弹出了这个提示:(由于我的问题解决了就找不到自己的图了借鉴了这个帖子的图,侵权请联系删)

然后我就找了半天解决方法。
原来是我没装SDK。。。
再次打开上面的官网地址,下载这个:
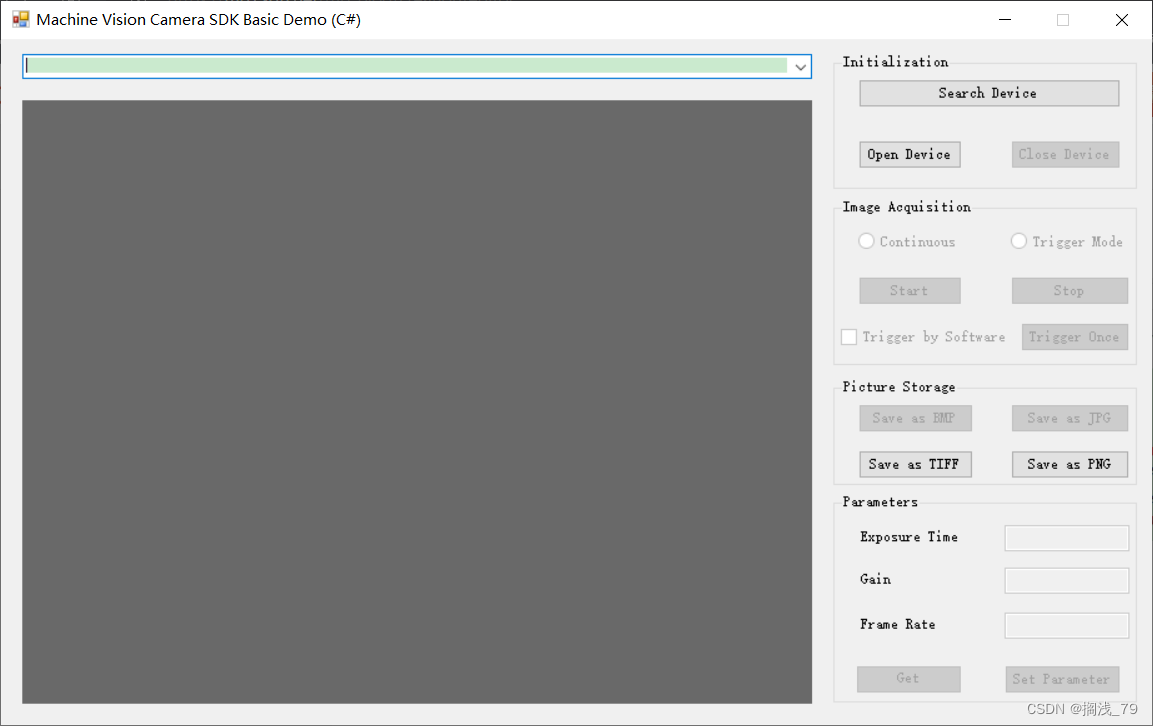
 下载安装完成后查看有没有多出两个系统变量:
下载安装完成后查看有没有多出两个系统变量:
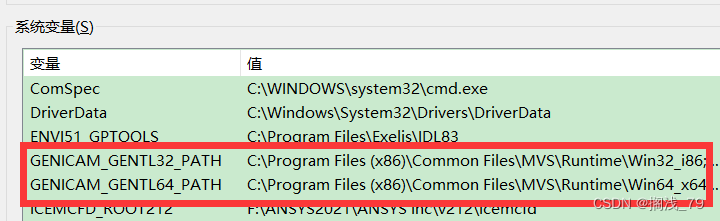
如果有那么问题就解决了,如果还是异常就重启一下VS软件。
正常运行的结果是这样:
系统变量的查找方法顺便附上吧:
1.找到“此电脑”右键点击“属性”就跳到了:
2.下滑到这里就有了:
3.打开“高级系统设置”点击“环境变量就有了” 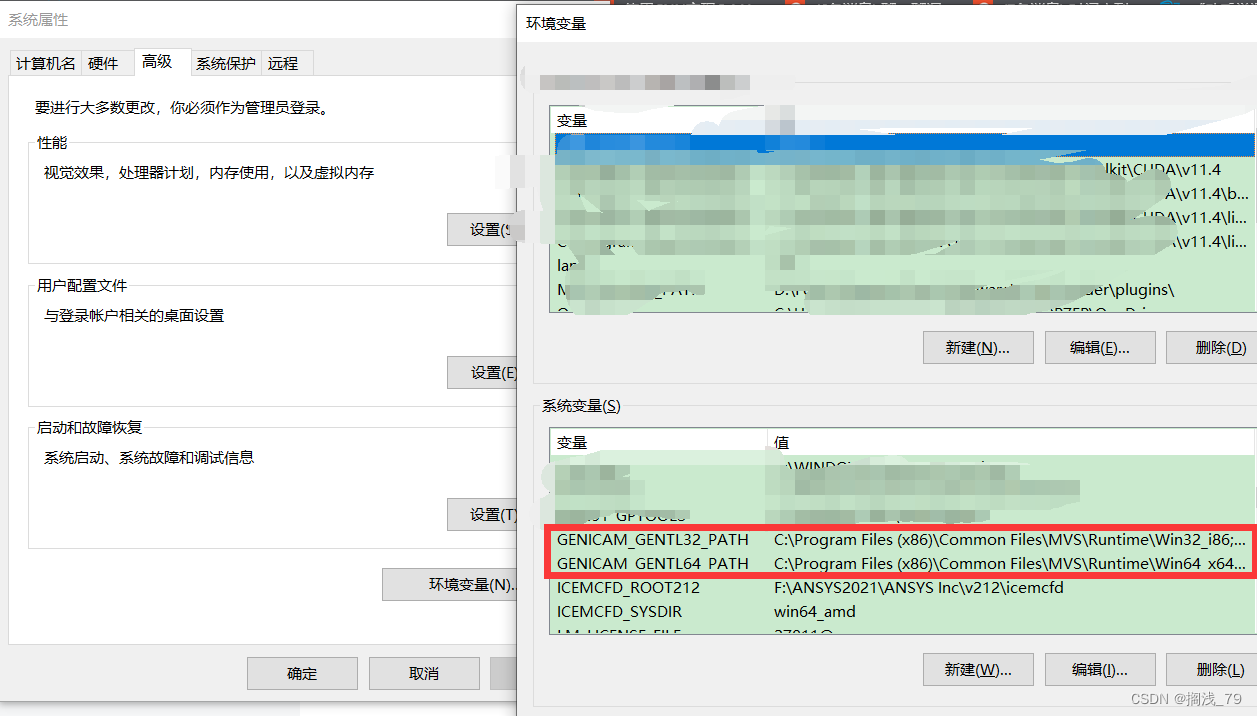
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
在railstutorial中,作者为什么选择使用这个(代码list10.25):http://ruby.railstutorial.org/chapters/updating-showing-and-deleting-usersnamespace:dbdodesc"Filldatabasewithsampledata"task:populate=>:environmentdoRake::Task['db:reset'].invokeUser.create!(:name=>"ExampleUser",:email=>"example@railstutorial.org",:passwo
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI