大家好,我是带我去滑雪!
本期使用爬取到的有关房价数据集data.csv,使用支持向量回归(SVR)方法预测房价。该数据集中“y1”为响应变量,为房屋总价,而x1-x9为特征变量,依次表示房屋的卧室数量、客厅数量、面积、装修情况、有无电梯、、房屋所在楼层位置、有无地铁、关注度、看房次数共计9项。数据集data.csv可在文末获取。
(ps,往期出过一个利用SVR预测房价,但代码没有分开讲,许多童鞋复制代码运行,总会出现各种问题,所以应童鞋要求,出一篇更为仔细的博客,大部分博主讲解SVR都采用python自带波士顿房价数据集,但很多童鞋大多都需要用到自己的数据集进行SVR建模,我想这也许对部分童鞋有一定帮助)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import preprocessing
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import KFold,StratifiedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.svm import LinearSVR
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import r2_score
get_ipython().run_line_magic('matplotlib', 'inline')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all'
import warnings
如果是第一次运行上述模块,报错 ModuleNotFoundError:Nomodulenamed'xxx'情况,需安装相应xxx名称的库,若使用jupyter notebook可以使用pip install xxx,若使用pycharm可以在设置里的packages里安装对应的包或者在控制台里使用pip install xxx。若都不行,可以上网浏览一下其他方法。
data=pd.read_csv('data.csv')
data输出结果:
x1 x2 x3 x4 x5 x6 x7 x8 x9 y1 0 2 2 78.60 0 1 2 1 58 14 210.0 1 4 2 98.00 0 1 0 1 2337 18 433.0 2 2 1 58.10 2 1 1 1 25 18 255.0 3 4 2 118.00 3 0 1 0 2106 6 195.0 4 3 1 97.70 2 0 2 0 1533 7 150.0 ... ... ... ... ... ... ... ... ... ... ... 2979 3 2 132.51 0 1 1 0 28 5 375.0 2980 2 1 80.30 2 1 1 1 8 0 375.0 2981 2 2 64.81 2 1 1 1 2 0 268.0 2982 2 1 57.26 0 0 0 1 0 0 235.0 2983 2 1 75.38 2 1 2 0 0 0 300.0 2984 rows × 10 columns
本文采用 “pd.read_csv” 导入数据,也可以采用 ”pd.read_excel“ 。使用pd.read_csv('data.csv')表示在工作路径直接读取data.csv文件,所以需要提前将数据集放入工作路径中。若不好找工作路径,也可以使用data = pd.read_csv(r'E:\工作\硕士\博客\博客19-SVR预测房价\data.csv')读取数据,效果是一样的。
data = pd.read_csv(r'E:\工作\硕士\博客\博客19-SVR预测房价\data.csv')
data输出结果:
x1 x2 x3 x4 x5 x6 x7 x8 x9 y1 0 2 2 78.60 0 1 2 1 58 14 210.0 1 4 2 98.00 0 1 0 1 2337 18 433.0 2 2 1 58.10 2 1 1 1 25 18 255.0 3 4 2 118.00 3 0 1 0 2106 6 195.0 4 3 1 97.70 2 0 2 0 1533 7 150.0 ... ... ... ... ... ... ... ... ... ... ... 2979 3 2 132.51 0 1 1 0 28 5 375.0 2980 2 1 80.30 2 1 1 1 8 0 375.0 2981 2 2 64.81 2 1 1 1 2 0 268.0 2982 2 1 57.26 0 0 0 1 0 0 235.0 2983 2 1 75.38 2 1 2 0 0 0 300.0 2984 rows × 10 columns
y=data.y1#将响应变量y1赋值给y
data_train,data_test,y_train,y_test=train_test_split(data,y,test_size=0.3,random_state=1)
由于特征变量的取值范围不尽相同,使用sklearn的StandardScaler类,将训练集和测试集中的所有特征变量进行标准化(即,均值为0,标准差为1)。"values.reshape(-1,1)"是将数据中的所有元素按照一列的形式重新排列,其中,-1 表示自动计算行数,1 表示只有一列。
scaler = StandardScaler()
scaler.fit(data_train)
data_train_s=scaler.fit_transform(data_train)#对训练集中的特征变量进行标准化
data_test_s=scaler.fit_transform(data_test)#对测试集的特征变量进行标准化
使用sklearn的SVR类分别进行径向核(rbf)、二次多项式核(poly,2)、三次多项式核(poly,3)、S型核进行支持向量回归。使用 fit()方法对SVR进行估计,在这里使用默认参数”epsilon=0.1“,即SVR的调节参数为0.1。使用score()方法,计算测试集的拟合优度。
model=SVR(kernel='rbf')#使用径向核(rbf)
model.fit(data_train_s,y_train)#模型估计
model.score(data_test_s,y_test)#计算拟合优度输出结果:
0.28217697180917056model=SVR(kernel='poly',degree=2)#使用二次多项式核
model.fit(data_train_s,y_train)#模型估计
model.score(data_test_s,y_test)#计算拟合优度输出结果:
0.35607964447352425model=SVR(kernel='poly',degree=3)#使用三次多项式核
model.fit(data_train_s,y_train)#模型估计
model.score(data_test_s,y_test)#计算拟合优度输出结果:
0.5944110925400512model=SVR(kernel='sigmoid')#使用S型核
model.fit(data_train_s,y_train)#模型估计
model.score(data_test_s,y_test)#计算拟合优度输出结果:
0.7219197626971094
| 本模型采用不同核的测试集拟合优度表 | ||||
| 径向核 | 二次多项式核 | 三次多项式核 | S型核 | |
| 测试集拟合优度 | 0.2821 | 0.3561 | 0.5944 | 0.7219 |
通过对比,我们发现采用S型核效果最好,测试集的拟合优度达到0.7219,故本文采取S型核。由于截至目前,超参数都是选用,默认的设置,下面选择最优超参数组合,进一步提升模型效果。
param_grid={'C':[0.01,0.1,1,10,50,100,150],'epsilon':[0.01,0.1,1,10],'gamma':[0.01,0.1,1,10]}#定义参数网格
kfold=KFold(n_splits=10,shuffle=True,random_state=1)#定义10折随机分组
model=GridSearchCV(SVR(),param_grid,cv=kfold)
model.fit(data_train_s,y_train)
model.best_params_输出结果:
{'C': 150, 'epsilon': 10, 'gamma': 0.01}
结果显示,最优参数组合为C=150, epsilon=10, gamma=0.01。
model1=model.best_estimator_#结合最优超参数,重新定义最优model
len(model1.support_)#展示支持向量数目
data_train_s.shape#展示训练集形状输出结果:
270 (2088, 10)model1.score(data_test_s,y_test)#计算测试集拟合优度
输出结果:
0.984653838741239
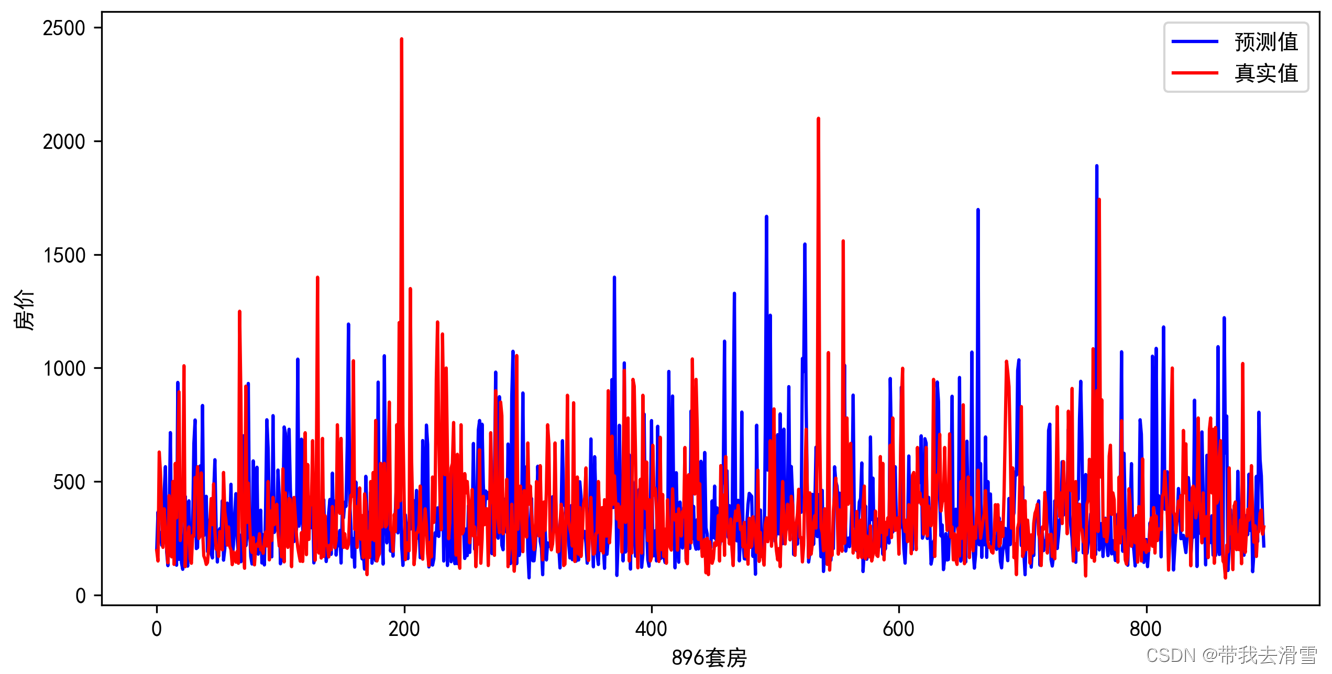
结果显示,模型采用最优参数组合后,共有270个支持向量,测试集的拟合优度也由原来的0.7219提高到了0.9847。
sigmoid_pred=model1.predict(data_test_s)#使用测试集预测房价
sigmoid_pred.shape#展示输出预测值形状输出结果:
(896,)
model1_rmse = np.sqrt(mean_squared_error(y_test,sigmoid_pred)) #RMSE
model1_mae = mean_absolute_error(y_test,sigmoid_pred) #MAE
model1_r2 = r2_score(y_test, sigmoid_pred) # R2
print("The RMSE of RBF_SVR: ", model1_rmse)
print("The MAE of RBF_SVR: ",model1_mae)
print("R^2 of RBF_SVR: ",model1_r2)输出结果:
The RMSE of RBF_SVR: 28.973562943677987 The MAE of RBF_SVR: 11.142043434442739 R^2 of RBF_SVR: 0.984653838741239
sigmoid_pred_true=pd.concat([pd.DataFrame(sigmoid_pred),pd.DataFrame(y_test)],axis = 1)#axis=1 表示按照列的方向进行操作,也就是对每一行进行操作。
sigmoid_pred_true.columns=['predictvalues', 'realvalues']
sigmoid_pred_true.to_excel(r'E:\工作\硕士\博客\博客19-SVR预测房价\预测值与真实值.xlsx',index = False)输出结果:
链接:https://pan.baidu.com/s/1p4HDhBH4QNtFLv-1UIoZ9Q?pwd=7qc5
提取码:7qc5
博主保存预测值与真实值时发现 ,真实值在excel里一列里没有连续保存,导致真实值与预测值没有一一对应,所以需要将数据处理一下,选中realvalues列,复制到新表里,然后按住ctrl+G,定位条件选择空白行,点击确定,在选中空白行删除,则将真实值变为连续序列,在复制回去与真实值一一对应。
data1= pd.read_csv(r'E:\工作\硕士\博客\博客19-SVR预测房价\data1.csv')#导入真实值与预测值数据
plt.subplots(figsize=(10,5))
plt.xlabel('896套房', fontsize =10)
plt.ylabel('房价', fontsize =10)
plt.plot(data1.predictvalues, color = 'b', label = '预测值')
plt.plot(data1.realvalues, color = 'r', label = '真实值')
plt.legend(loc=0)
plt.savefig("squares.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:
需要数据集的家人们可以去百度网盘(永久有效)获取:
链接:https://pan.baidu.com/s/173deLlgLYUz789M3KHYw-Q?pwd=0ly6
提取码:0ly6
更多优质内容持续发布中,请移步主页查看。
点赞+关注,下次不迷路!
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称