#{}和${}的区别
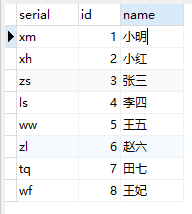
数据库数据
图片:
一、先说#{}
例:mapper.xml如下
1、#{}是一个占位符,相当于JDBC中的一个?,会对一些敏感的字符进行过滤
2、#{}底层采用的是PreparedStatement,会预编译(主要是里面的setString方法,对一些特殊的字符,例如’'单引号,会在值后面加上一个\右斜线进行转义,让值无效),因此不会产生sql注入
例:
请求:
http://localhost:8001/payment/get?name=‘小明’
debug运行查看
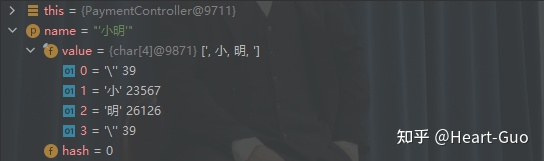
value = {char[4]@9719} [‘, 小, 明, ‘] 0 = ‘’’ 39 1 = ‘小’ 23567 2 = ‘明’ 26126 3 = ‘’’ 39
结果:
{“code”:444,“message”:“查询数据失败,name:‘小明’”,“data”:null}
3、#{}不会产生字符串拼接,
4、#{}在使用时会根据传递进来的值来选择是否加上双引号(例:#{name} 传入sql中就是"小明"),因此我们在传递参数时一般都是直接传递,不用加双引号
例:
http://localhost:8001/payment/get?name=小明
5、在传递参数时#{}中可以传递任意值
例:
得出的结果都是:
{“code”:200,“message”:“查询数据成功,serverPort:8001”,“data”:{“id”:1,“serial”:“xm”,“name”:“小明”}}
注意在dao层改一下
Payment getPaymentByName2(@Param(“随便写”) String name);
6、#{}的应用场景是为sql语句中where字句传递条件值
二、再说
1
、
{} 1、
1、{}匹配的是真是传递的值,传递后会与sql语句进行字符拼接
2、${}会与其他sql进行字符串拼接,不能预防sql注入
例:mapper.xml如下
请求:
http://localhost:8001/payment/get?name=小明
报错:
SQL: select * from payment where name = 小明;
in ‘where clause’
3、
不会主动加
"
"
双引号,需要我们手动加入例:请求:
h
t
t
p
:
/
/
l
o
c
a
l
h
o
s
t
:
8001
/
p
a
y
m
e
n
t
/
g
e
t
?
n
a
m
e
=
"
小明
"
结果:
"
c
o
d
e
"
:
200
,
"
m
e
s
s
a
g
e
"
:
"
查询数据成功
,
s
e
r
v
e
r
P
o
r
t
:
8001
"
,
"
d
a
t
a
"
:
"
i
d
"
:
1
,
"
s
e
r
i
a
l
"
:
"
x
m
"
,
"
n
a
m
e
"
:
"
小明
"
4
、
{}不会主动加""双引号,需要我们手动加入 例: 请求: http://localhost:8001/payment/get?name="小明" 结果: {"code":200,"message":"查询数据成功,serverPort:8001","data":{"id":1,"serial":"xm","name":"小明"}} 4、
不会主动加""双引号,需要我们手动加入例:请求:http://localhost:8001/payment/get?name="小明"结果:"code":200,"message":"查询数据成功,serverPort:8001","data":"id":1,"serial":"xm","name":"小明"4、{}作为普通传值,不能进行字符过滤
5、${}的应用场景是为了传递一些需要参与SQL语句语法生成的值
例:
请求:
http://localhost:8001/payment/get?table=payment
结果:
{“code”:200,“message”:“查询数据成功,serverPort:8001”, “data”:[ {“id”:1,“serial”:“xm”,“name”:“小明”}, {“id”:2,“serial”:“xh”,“name”:“小红”}, {“id”:3,“serial”:“zs”,“name”:“张三”}, {“id”:4,“serial”:“ls”,“name”:“李四”}, {“id”:5,“serial”:“ww”,“name”:“王五”}, {“id”:6,“serial”:“zl”,“name”:“赵六”}, {“id”:7,“serial”:“tq”,“name”:“田七”}, {“id”:8,“serial”:“wf”,“name”:“王妃”}]}
三、最后统一总结一下(感觉自己写的乱糟糟的o(╥﹏╥)o)
1、#{}是一个占位符,KaTeX parse error: Expected 'EOF', got '#' at position 12: {}只是普通传值 2、#̲{}在使用时,会根据传递进来的…{}则不会,我们需要手动加
3、在传递一个参数时,我们在#{}中可以写任意值
4、#{}针对SQL注入进行了字符过滤,KaTeX parse error: Expected 'EOF', got '#' at position 26: …值,并没有考虑到这些问题 5、#̲{}的应用场景是为给SQL语句…{}的应用场景是为了传递一些需要参与SQL语句语法生成的值
请帮助我理解范围运算符...和..之间的区别,作为Ruby中使用的“触发器”。这是PragmaticProgrammersguidetoRuby中的一个示例:a=(11..20).collect{|i|(i%4==0)..(i%3==0)?i:nil}返回:[nil,12,nil,nil,nil,16,17,18,nil,20]还有:a=(11..20).collect{|i|(i%4==0)...(i%3==0)?i:nil}返回:[nil,12,13,14,15,16,17,18,nil,20] 最佳答案 触发器(又名f/f)是
我正在检查一个Rails项目。在ERubyHTML模板页面上,我看到了这样几行:我不明白为什么不这样写:在这种情况下,||=和ifnil?有什么区别? 最佳答案 在这种特殊情况下没有区别,但可能是出于习惯。每当我看到nil?被使用时,它几乎总是使用不当。在Ruby中,很少有东西在逻辑上是假的,只有文字false和nil是。这意味着像if(!x.nil?)这样的代码几乎总是更好地表示为if(x)除非期望x可能是文字false。我会将其切换为||=false,因为它具有相同的结果,但这在很大程度上取决于偏好。唯一的缺点是赋值会在每次运行
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev
打印1:defsum(i)i=i+[2]end$x=[1]sum($x)print$x打印12:defsum(i)i.push(2)end$x=[1]sum($x)print$x后者是修改全局变量$x。为什么它在第二个例子中被修改而不是在第一个例子中?类Array的任何方法(不仅是push)都会发生这种情况吗? 最佳答案 变量范围在这里无关紧要。在第一段代码中,您仅使用赋值运算符=为变量i赋值,而在第二段代码中,您正在修改$x(也称为i)使用破坏性方法push。赋值从不修改任何对象。它只是提供一个名称来引用一个对象。方法要么是破坏性
Ruby中的Fixnum方法.next和.succ有什么区别?看起来它的工作原理是一样的:1.next=>21.succ=>2如果有什么不同,为什么有两种方法做同样的事情? 最佳答案 它们是等价的。Fixnum#succ只是Fixnum#next的同义词。他们甚至在thereferencemanual中共享同一block. 关于ruby-Ruby中.next和.succ的区别,我们在StackOverflow上找到一个类似的问题: https://stacko
我明白了defa(&block)block.call(self)end和defa()yieldselfend导致相同的结果,如果我假设有这样一个blocka{}。我的问题是-因为我偶然发现了一些这样的代码,它是否有任何区别或者是否有任何优势(如果我不使用变量/引用block):defa(&block)yieldselfend这是一个我不理解&block用法的具体案例:defrule(code,name,&block)@rules=[]if@rules.nil?@rules 最佳答案 我能想到的唯一优点就是自省(introspecti
由于匿名block和散列block看起来大致相同。我正在玩它。我做了一些严肃的观察,如下所示:{}.class#=>Hash好的,这很酷。空block被视为Hash。print{}.class#=>NilClassputs{}.class#=>NilClass为什么上面的代码和NilClass一样,下面的代码又显示了Hash?puts({}.class)#Hash#=>nilprint({}.class)#Hash=>nil谁能帮我理解上面发生了什么?我完全不同意@Lindydancer的观点你如何解释下面几行:print{}.class#NilClassprint[].class#A
在Ruby中,我试图理解to_enum和enum_for方法。在我提出问题之前,我提供了一些示例代码和两个示例来帮助理解上下文。示例代码:#replicatesgroup_bymethodonArrayclassclassArraydefgroup_by2(&input_block)returnself.enum_for(:group_by2)unlessblock_given?hash=Hash.new{|h,k|h[k]=[]}self.each{|e|hash[input_block.call(e)]示例#1:irb(main)>puts[1,2,3].group_by2.ins
关于SSHkit-Github它说:Allbackendssupporttheexecute(*args),test(*args)&capture(*args)来自SSHkit-Rubydoc,我明白execute实际上是test的别名?test之间有什么区别?,execute,capture在Capistrano/SSHKit中我应该什么时候使用? 最佳答案 执行只是执行命令。使用非0退出引发错误。测试方法的行为与execute完全相同,但是它返回bool值(true如果命令以0退出,而false否则)。它通常用于控制任务中的流程