日志收集的目的:
日志收集的价值:
k8s常用的日志收集方式:
使用主机如下:
| IP | 主机名 | 角色 |
|---|---|---|
| 192.168.122.30 | es-1.linux.io | elasticsearch、kibana |
| 192.168.122.31 | es-2.linux.io | elasticsearch |
| 192.168.122.32 | es-3.linux.io | elasticsearch |
先下载Elastic安装包,下载地址:https://www.elastic.co/cn/downloads/elasticsearch
可以选择下载源码包,也可以选择下载rpm或deb包直接安装。这里选择下载deb包,然后使用dpkg进行安装
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.6-amd64.deb
dpkg -i elasticsearch-7.17.6-amd64.deb
node1:
root@es-1:~# cat /etc/elasticsearch/elasticsearch.yml |grep -Ev "^#"
cluster.name: log-cluster1
node.name: node1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.122.30
http.port: 9200
discovery.seed_hosts: ["192.168.122.30", "192.168.122.31", "192.168.122.32"]
cluster.initial_master_nodes: ["node1", "node2", "node3"]
action.destructive_requires_name: true
root@es-1:~#
node2:
root@es-2:~# cat /etc/elasticsearch/elasticsearch.yml |grep -Ev "^#"
cluster.name: log-cluster1
node.name: node2
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.122.31
http.port: 9200
discovery.seed_hosts: ["192.168.122.30", "192.168.122.31", "192.168.122.33"]
cluster.initial_master_nodes: ["node1", "node2", "node3"]
action.destructive_requires_name: true
root@es-2:~#
node3:
root@es-3:~# cat /etc/elasticsearch/elasticsearch.yml |grep -Ev "^#"
cluster.name: log-cluster1
node.name: node3
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.122.32
http.port: 9200
discovery.seed_hosts: ["192.168.122.30", "192.168.122.31", "192.168.122.32"]
cluster.initial_master_nodes: ["node1", "node2", "node3"]
action.destructive_requires_name: true
root@es-3:~#
在3个节点分别启动elastic服务
systemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearch
systemctl status elasticsearch
下载deb包,下载地址:https://www.elastic.co/cn/downloads/kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.6-amd64.deb
dpkg -i kibana-7.17.6-amd64.deb
修改kibana配置文件
root@es-1:~# cat /etc/kibana/kibana.yml |grep -Ev "^#|^$"
server.port: 5601
server.host: "192.168.122.30"
server.name: "kibana"
elasticsearch.hosts: ["http://192.168.122.30:9200", "http://192.168.122.31:9200", "http://192.168.122.32:9200"]
i18n.locale: "zh-CN"
root@es-1:~#
启动kibana
systemctl enable kibana
systemctl start kibana
systemctl status kibana
访问kibana测试
使用主机如下
| IP | hostname | 角色 |
|---|---|---|
| 192.168.122.33 | kafka-1.linux.io | zookeeper、kafka |
| 192.168.122.34 | kafka-2.linux.io | zookeeper、kafka |
| 192.168.122.35 | kafka-3.linux.io | zookeeper、kafka |
先在3个节点配置java环境
mkdir /usr/local/java
tar xf jdk-8u131-linux-x64.tar.gz -C /usr/local/java/
vim /etc/profile #配置环境变量,添加下面几行
export JAVA_HOME=/usr/local/java/jdk1.8.0_131
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source /etc/profile
java -version
下载安装包,下载地址:https://zookeeper.apache.org/releases.html
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
mkdir /apps
tar xf apache-zookeeper-3.6.3-bin.tar.gz -C /apps/ && cd /apps
ln -s apache-zookeeper-3.6.3-bin zookeeper
修改zookeeper配置,3个节点操作一致,只有myid不同
mkdir -p /data/zookeeper/{data,logs}
cd /apps/zookeeper/
cp conf/zoo_sample.cfg conf/zoo.cfg
cat conf/zoo.cfg
############################
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/logs
clientPort=2181
server.0=192.168.122.33:2288:3388
server.1=192.168.122.34:2288:3388
server.2=192.168.122.35:2288:3388
##############################
echo 0 >/data/zookeeper/data/myid #此处myid在3个节点分别为0,1,2
启动服务
cat /etc/systemd/system/zookeeper.service
#####################
[Unit]
Description=zookeeper.service
After=network.target
[Service]
Type=forking
ExecStart=/apps/zookeeper/bin/zkServer.sh start
ExecStop=/apps/zookeeper/bin/zkServer.sh stop
ExecReload=/apps/zookeeper/bin/zkServer.sh restart
[Install]
WantedBy=multi-user.target
#####################
system daemon reload
systemctl restart zookeeper
systemctl status zookeeper
检查zookeeper集群状态
/apps/zookeeper/bin/zkServer.sh status
3个节点,一个为leader,其余两个为follower



和zookeeper部署在相同的主机
下载安装包,下载地址:https://kafka.apache.org/downloads
wget https://archive.apache.org/dist/kafka/3.2.1/kafka_2.12-3.2.1.tgz
tar xf kafka_2.12-3.2.1.tgz -C /apps/ && cd /apps
ln -s kafka_2.12-3.2.1 kafka
修改kafka配置
node1:
mkdir -p /data/kafka/kafka-logs
cd /app/kafka
vim config/server.properties
#########################################
broker.id=0 #修改id,3个节点分别为0、1、2
listeners=PLAINTEXT://192.168.122.33:9092 #修改监听地址为本机地址
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/kafka-logs #修改数据存放目录
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.122.33:2181,192.168.122.34:2181,192.168.122.35:2181 #指定zookeeper地址
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
########################################
node2:
mkdir -p /data/kafka/kafka-logs
cd /apps/kafka
vim config/server.properties
#########################################
broker.id=1
listeners=PLAINTEXT://192.168.122.34:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.122.33:2181,192.168.122.34:2181,192.168.122.35:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
####################################
node3:
mkdir -p /data/kafka/kafka-logs
cd /apps/kafka
vim config/server.properties
#########################################
broker.id=2
listeners=PLAINTEXT://192.168.122.35:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.122.33:2181,192.168.122.34:2181,192.168.122.35:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
####################################
启动kafka
cat /etc/systemd/system/kafka.service
#####################################
[Unit]
Description=kafka.service
After=network.target remote-fs.target zookeeper.service
[Service]
Type=forking
Environment=JAVA_HOME=/usr/local/java/jdk1.8.0_131
ExecStart=/apps/kafka/bin/kafka-server-start.sh -daemon /apps/kafka/config/server.properties
ExecStop=/apps/kafka/bin/kafka-server-stop.sh
ExecReload=/bin/kill -s HUP $MAINPID
[Install]
WantedBy=multi-user.target
#####################################
systemctl daemon-reload
systemctl start kafka
systemctl status kafka
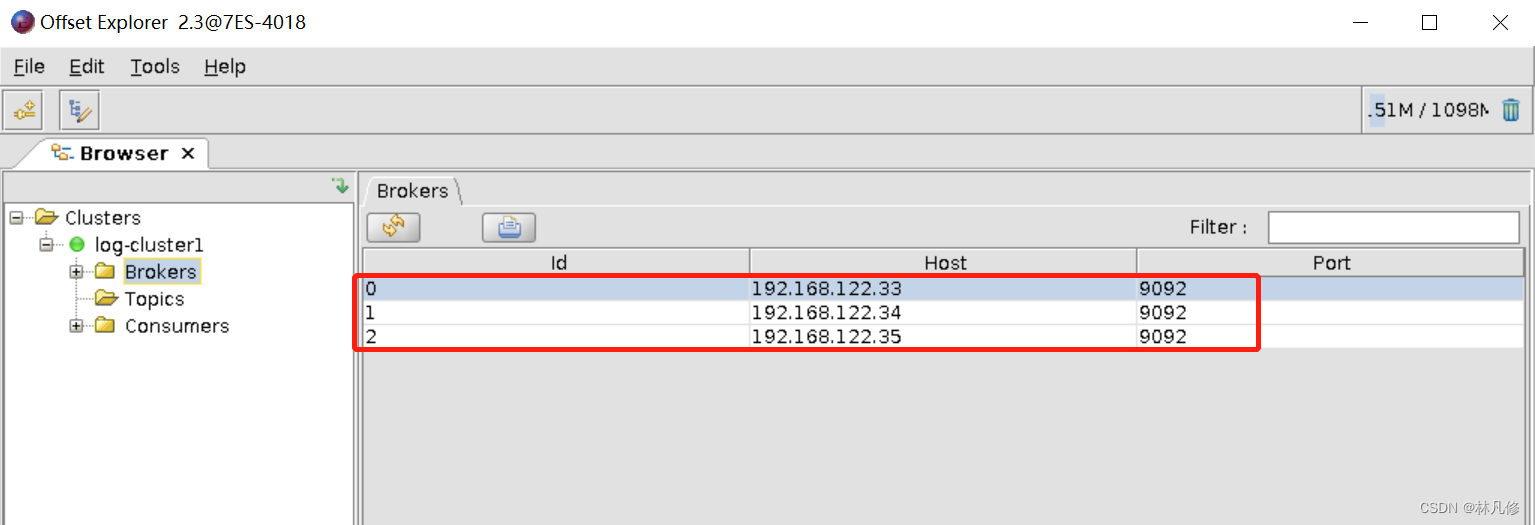
使用Kafka 客户端管理工具 Offset Explorer查看验证kafka集群状态,关于此工具的使用可以参考:https://blog.csdn.net/qq_39416311/article/details/123316904
使用主机如下:
| IP | hostname | 角色 |
|---|---|---|
| 192.168.122.36 | logstash-1.linux.io | logstash |
此logstash是用于从kafka获取日志然后写入es
下载安装包,下载地址:https://www.elastic.co/cn/downloads/logstash
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.17.6-amd64.deb
dpkg -i logstash-7.17.6-amd64.deb
启动logstash
systemctl startlogstash
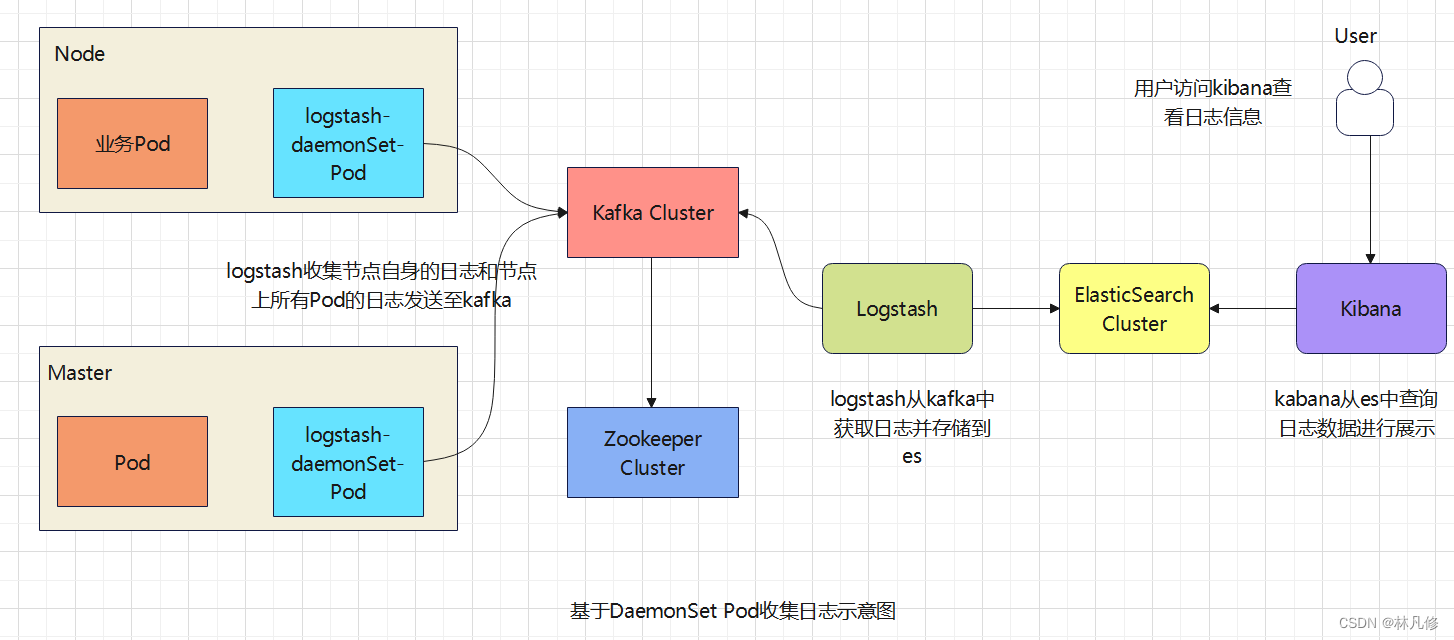
具体流程如下图:
Dockerfile如下:
FROM logstash:7.17.6
LABEL author="admin@163.com"
WORKDIR /usr/share/logstash
ADD logstash.yml /usr/share/logstash/config/logstash.yml
ADD logstash.conf /usr/share/logstash/pipeline/logstash.conf
USER root
RUN usermod -a -G root logstash #将logstash用户加入root组,避免因权限不足导致logstash无法读取日志文件
logstash.yml内容如下:
http.host: "0.0.0.0"
logstash.conf内容如下:
input {
file {
#path => "/var/lib/docker/containers/*/*-json.log" #docker
path => "/var/log/pods/*/*/*.log" #使用containerd时,Pod的log的存放路径
start_position => "beginning"
type => "applog" #日志类型,自定义
}
file {
path => "/var/log/*.log" #操作系统日志路径
start_position => "beginning"
type => "syslog"
}
}
output {
if [type] == "applog" { #指定将applog类型的日志发送到kafka的哪个topic
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384 #logstash每次向ES传输的数据量大小,单位为字节
codec => "${CODEC}" #日志格式
} }
if [type] == "syslog" { ##指定将syslog类型的日志发送到kafka的哪个topic
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384
codec => "${CODEC}" #系统日志不是json格式
}}
}
执行构建,上传镜像到harbor
nerdctl build -t harbor-server.linux.io/n70/logstash-daemonset:7.17.6 .
harbor-server.linux.io/n70/logstash-daemonset:7.17.6
部署文件如下:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: logstash-daemonset
namespace: log
spec:
selector:
matchLabels:
app: logstash
template:
metadata:
labels:
app: logstash
spec:
containers:
- name: logstash
image: harbor-server.linux.io/n70/logstash-daemonset:7.17.6
imagePullPolicy: Always
env:
- name: KAFKA_SERVER
value: "192.168.122.33:9092,192.168.122.34:9092,192.168.122.35:9092"
- name: TOPIC_ID
value: "jsonfile-log-topic"
- name: CODEC
value: "json"
volumeMounts:
- name: varlog
mountPath: /var/log
readOnly: False
- name: varlogpods
mountPath: /var/log/pods
readOnly: False
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlogpods
hostPath:
path: /var/log/pods
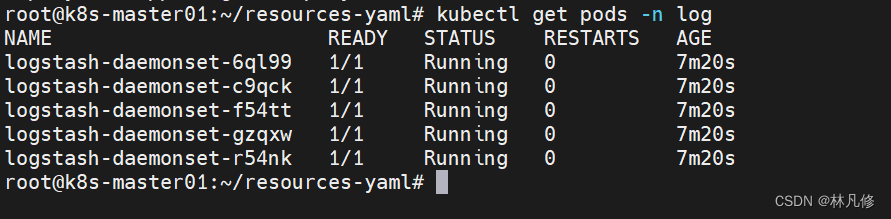
在kafka中进行查看,可以看到日志已经发送到kafka
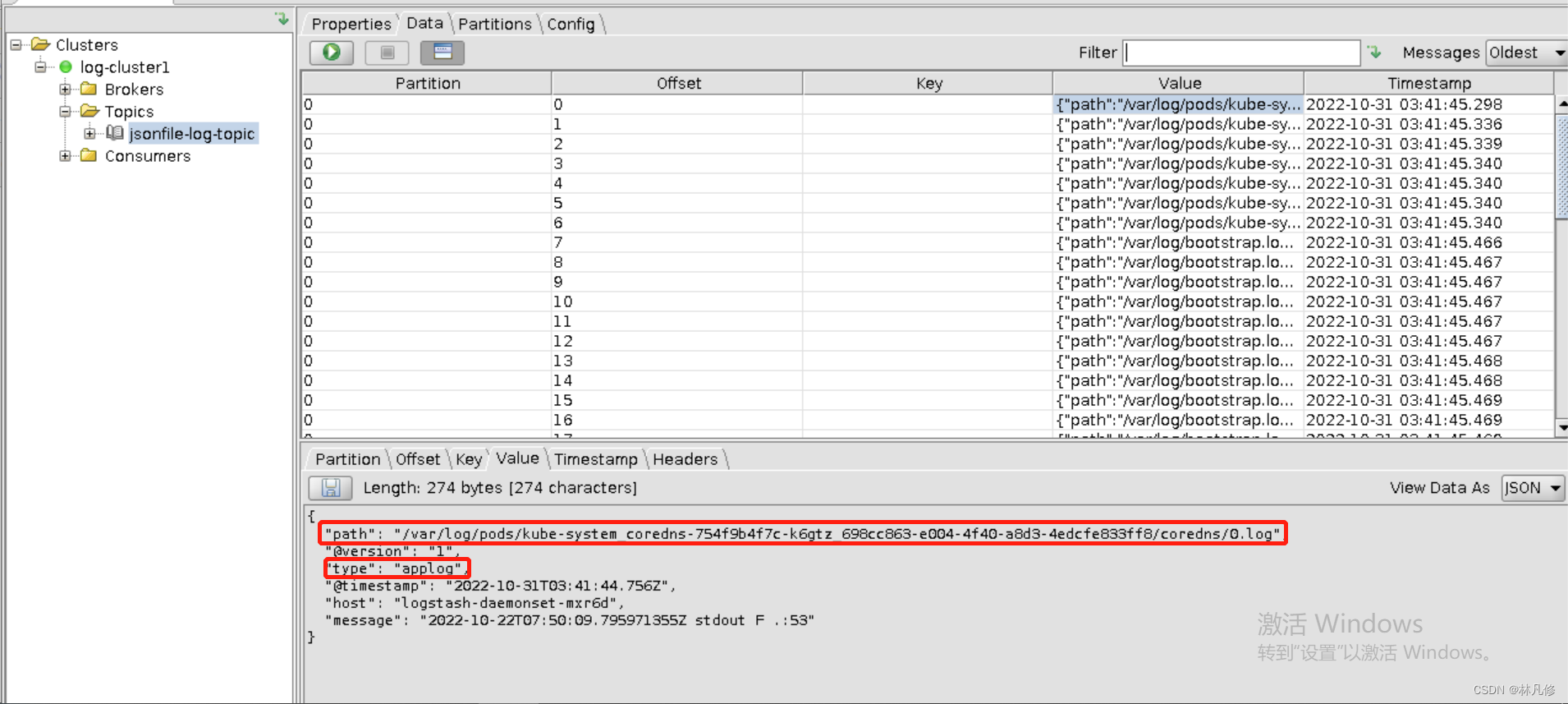
这里的logstash是之前部署在主机上的logstash,而不是Pod。配置其从kafka读取日志然后发送到es
cat /etc/logstash/conf.d/logstash-daemonset-kafka-to-es.conf
######################################
input {
kafka {
bootstrap_servers => "192.168.122.33:9092,192.168.122.34:9092,192.168.122.35:9092"
topics => ["jsonfile-log-topic"]
codec => "json"
}
}
output {
if [type] == "applog" {
elasticsearch {
hosts => ["192.168.122.30:9200","192.168.122.31:9200","192.168.122.32:9200"]
index => "applog-%{+YYYY.MM.dd}"
}}
if [type] == "syslog" {
elasticsearch {
hosts => ["192.168.122.30:9200","192.168.122.31:9200","192.168.122.32:9200"]
index => "syslog-%{+YYYY.MM.dd}"
}}
}
##########################################
systemctl restart logstash
分别为applog和syslog创建日志索引模式


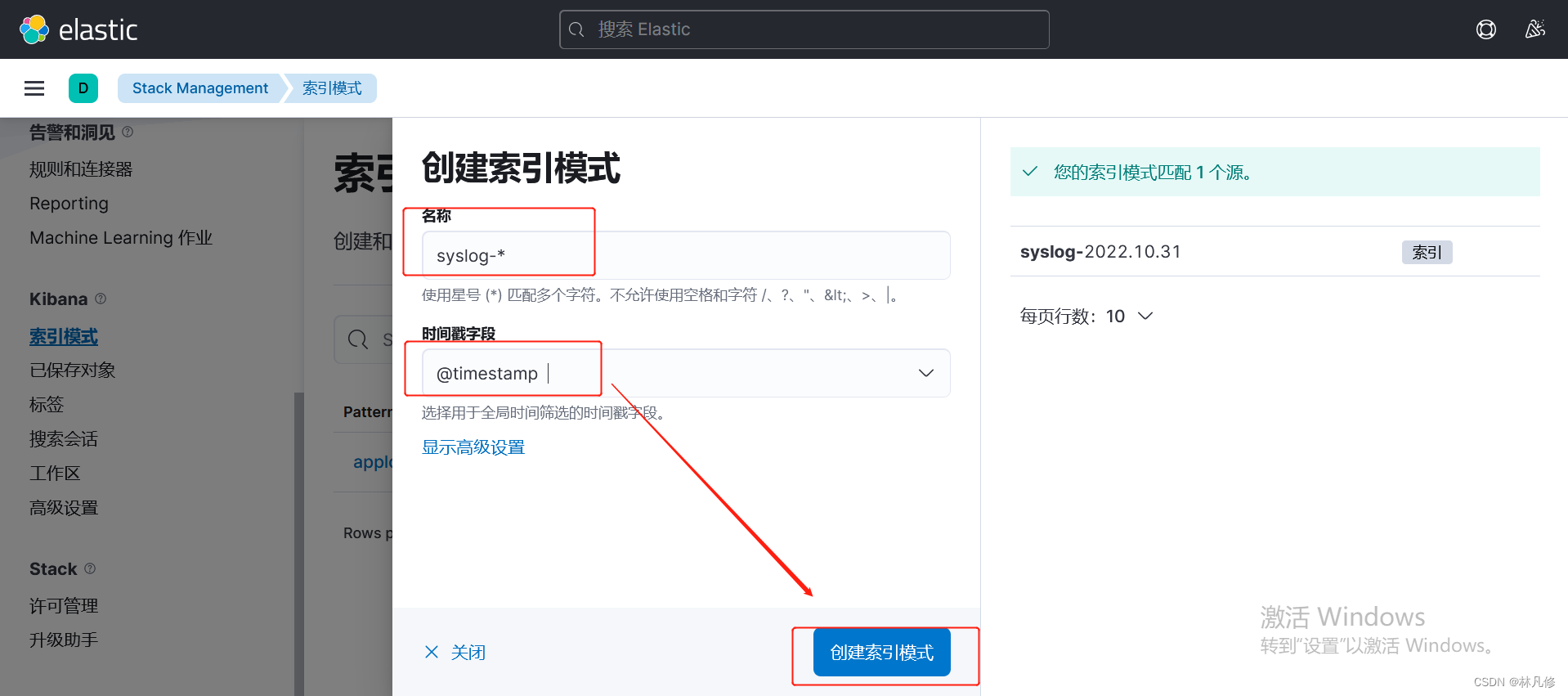
然后就可以在Discovery页面查看日志
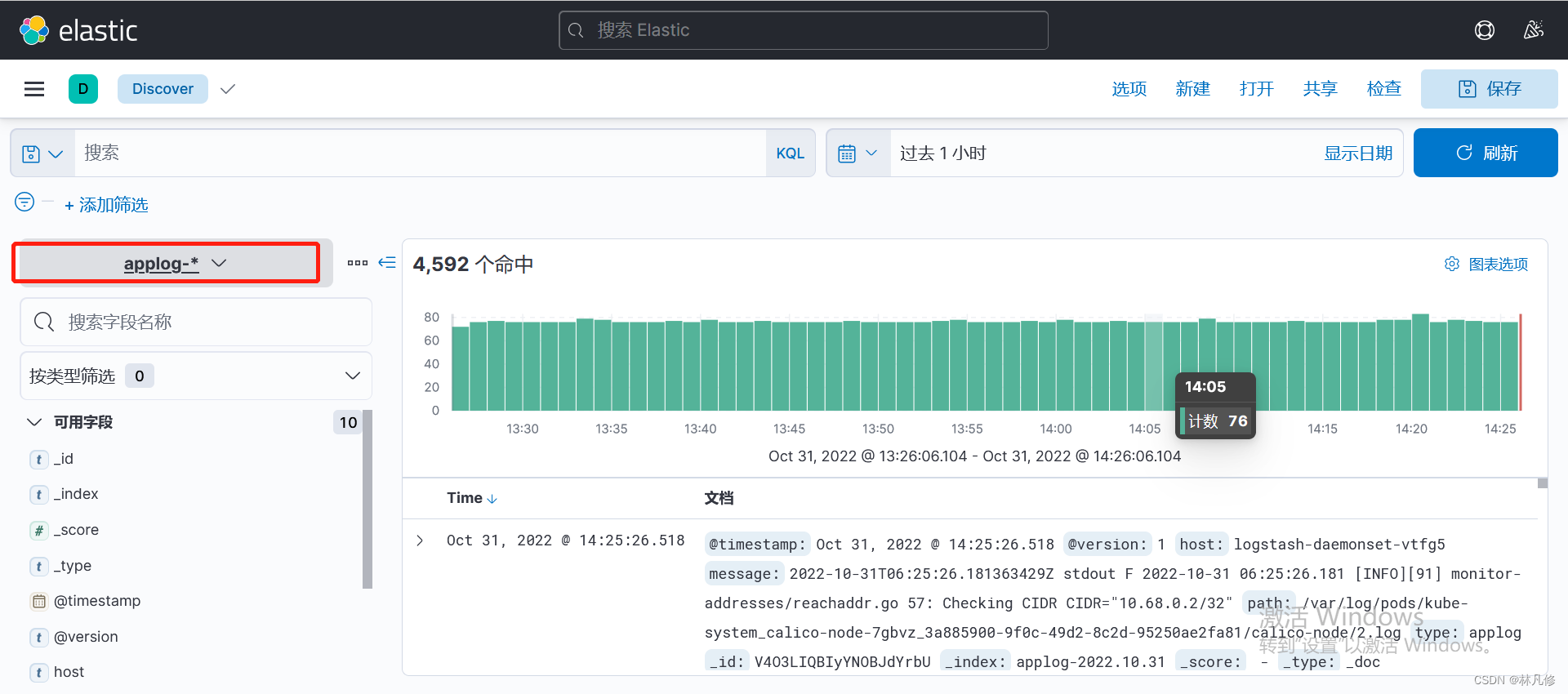
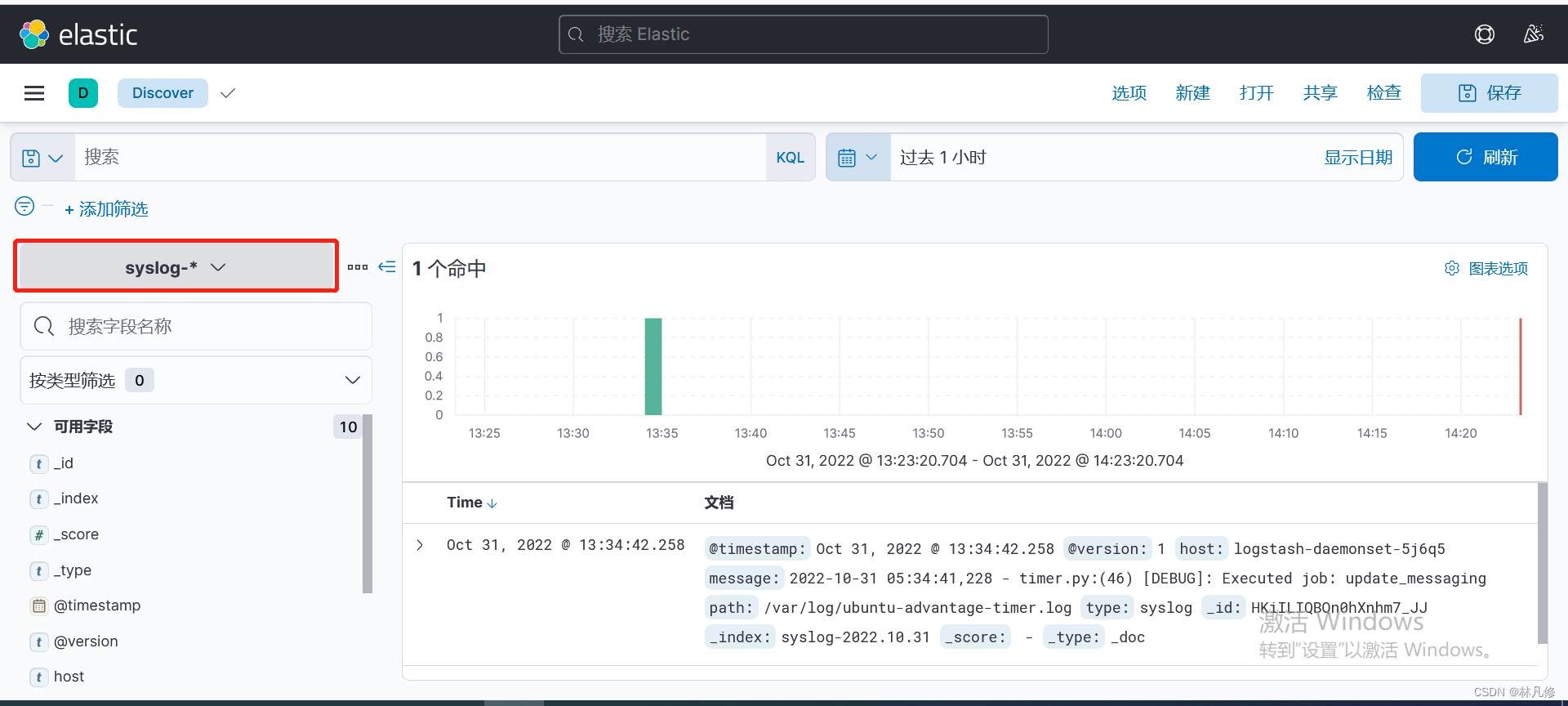
访问nginx Pod产生一些日志,然后使用关键字搜索,如下图,可以看到新产生的容器日志
整体流程如下图:
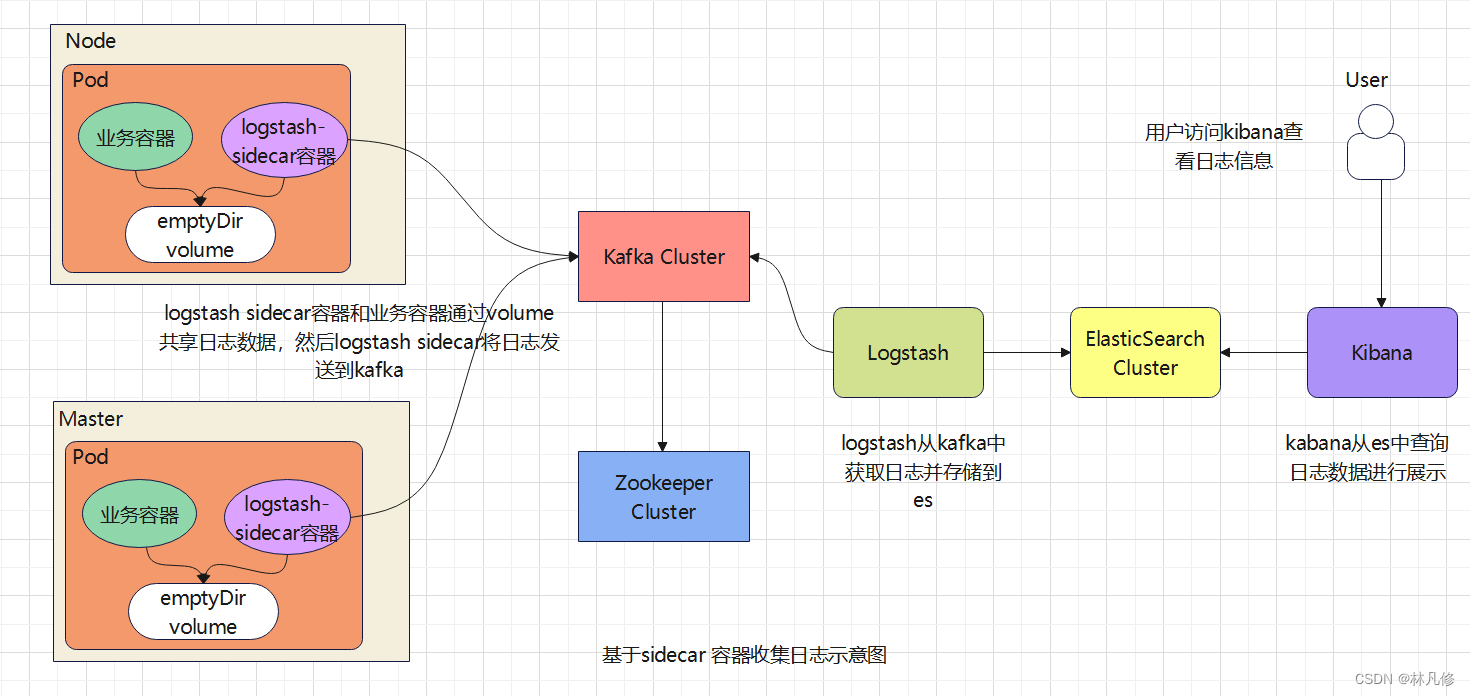
在这种方式下node节点上的日志还是需要部署额外的服务去收集
sidecar容器也是基于官方logstash镜像构建,Dockerfile如下:
FROM logstash:7.17.6
LABEL author="admin@163.com"
WORKDIR /usr/share/logstash
ADD logstash.yml /usr/share/logstash/config/logstash.yml
ADD logstash.conf /usr/share/logstash/pipeline/logstash.conf
USER root
RUN usermod -a -G root logstash
logstash.yaml内容如下:
http.host: "0.0.0.0"
logstash.conf内容如下:
input {
file {
path => "/var/log/applog/catalina.*.log"
start_position => "beginning"
type => "tomcat-app1-catalina-log"
}
file {
path => "/var/log/applog/localhost_access_log.*.txt"
start_position => "beginning"
type => "tomcat-app1-access-log"
}
}
output {
if [type] == "tomcat-app1-catalina-log" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384 #logstash每次向ES传输的数据量大小,单位为字节
codec => "${CODEC}"
} }
if [type] == "tomcat-app1-access-log" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384
codec => "${CODEC}" #系统日志不是json格式
}}
}
构建镜像,上传到harbor
nerdctl build -t harbor-server.linux.io/n70/logstash-sidecar:7.17.6 .
nerdctl push harbor-server.linux.io/n70/logstash-sidecar:7.17.6
部署文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: tomcat-app1
spec:
replicas: 2
selector:
matchLabels:
app: tomcat-app1
template:
metadata:
labels:
app: tomcat-app1
spec:
containers:
- name: logstash-sidecar
image: harbor-server.linux.io/n70/logstash-sidecar:7.17.6
imagePullPolicy: Always
env:
- name: KAFKA_SERVER
value: "192.168.122.33:9092,192.168.122.34:9092,192.168.122.34:9092"
- name: TOPIC_ID
value: "tomcat-app1-log"
- name: CODEC
value: "json"
volumeMounts:
- name: applog
mountPath: /var/log/applog
- name: tomcat
image: harbor-server.linux.io/n70/tomcat-myapp:v1
imagePullPolicy: IfNotPresent
volumeMounts:
- name: applog
mountPath: /app/tomcat/logs
volumes:
- name: applog
emptyDir: {}

在kafka中查看,sidecar容器已经将日志发送到kafka
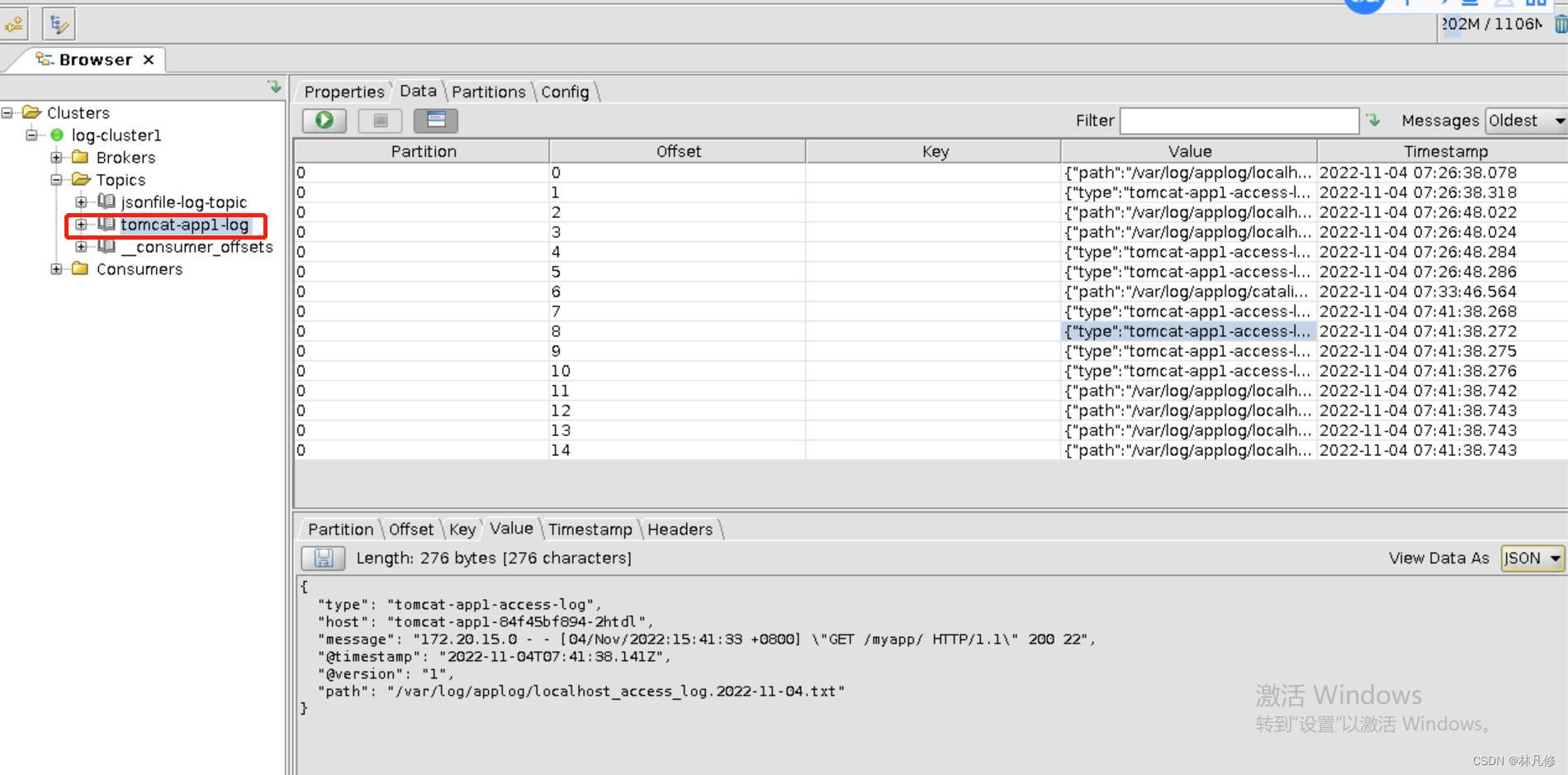
cat logstash-sidercat-kafka-to-es.conf
######################################
input {
kafka { #从kafka tomcat-app1-log topic中读取日志
bootstrap_servers => "192.168.122.33:9092,192.168.122.34:9092,192.168.122.35:9092"
topics => ["tomcat-app1-log"]
codec => "json"
}
}
output {
if [type] == "tomcat-app1-access-log" { #tomcat访问日志存储到es的tomcat-app1-accesslog-%{+YYYY.MM.dd}索引中
elasticsearch {
hosts => ["192.168.122.30:9200","192.168.122.31:9200","192.168.122.32"]
index => "tomcat-app1-accesslog-%{+YYYY.MM.dd}"
}
}
if [type] == "tomcat-app1-catalina-log" { #tomcat启动日志存储到es的tomcat-app1-catalinalog-%{+YYYY.MM.dd}索引中
elasticsearch {
hosts => ["192.168.122.30:9200","192.168.122.31:9200","192.168.122.32"]
index => "tomcat-app1-catalinalog-%{+YYYY.MM.dd}"
}
}
}
########################################
systemctl restart logstash
为tomcat-app1-catalinalog和tomcat-app1-accesslog创建索引
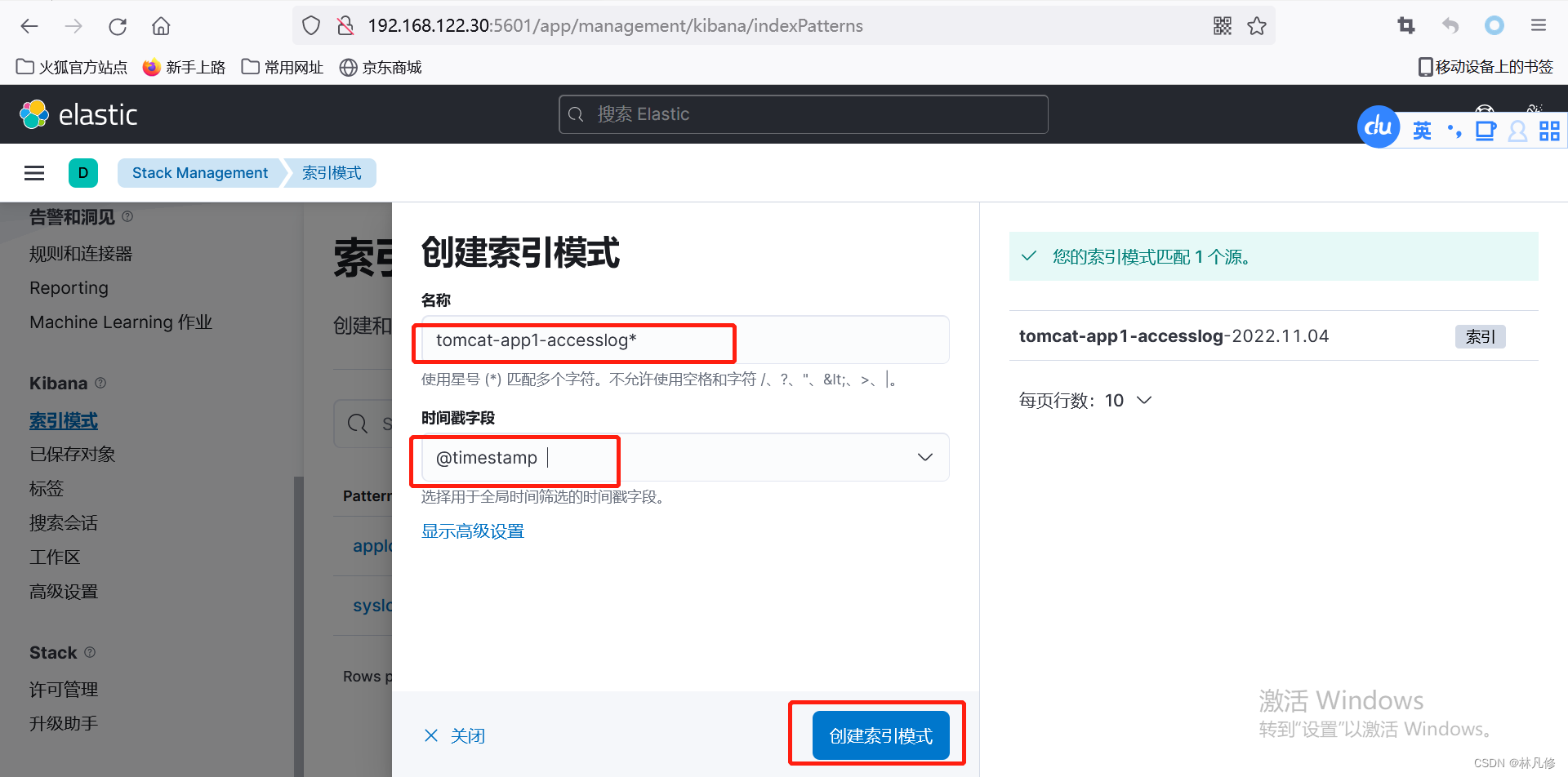
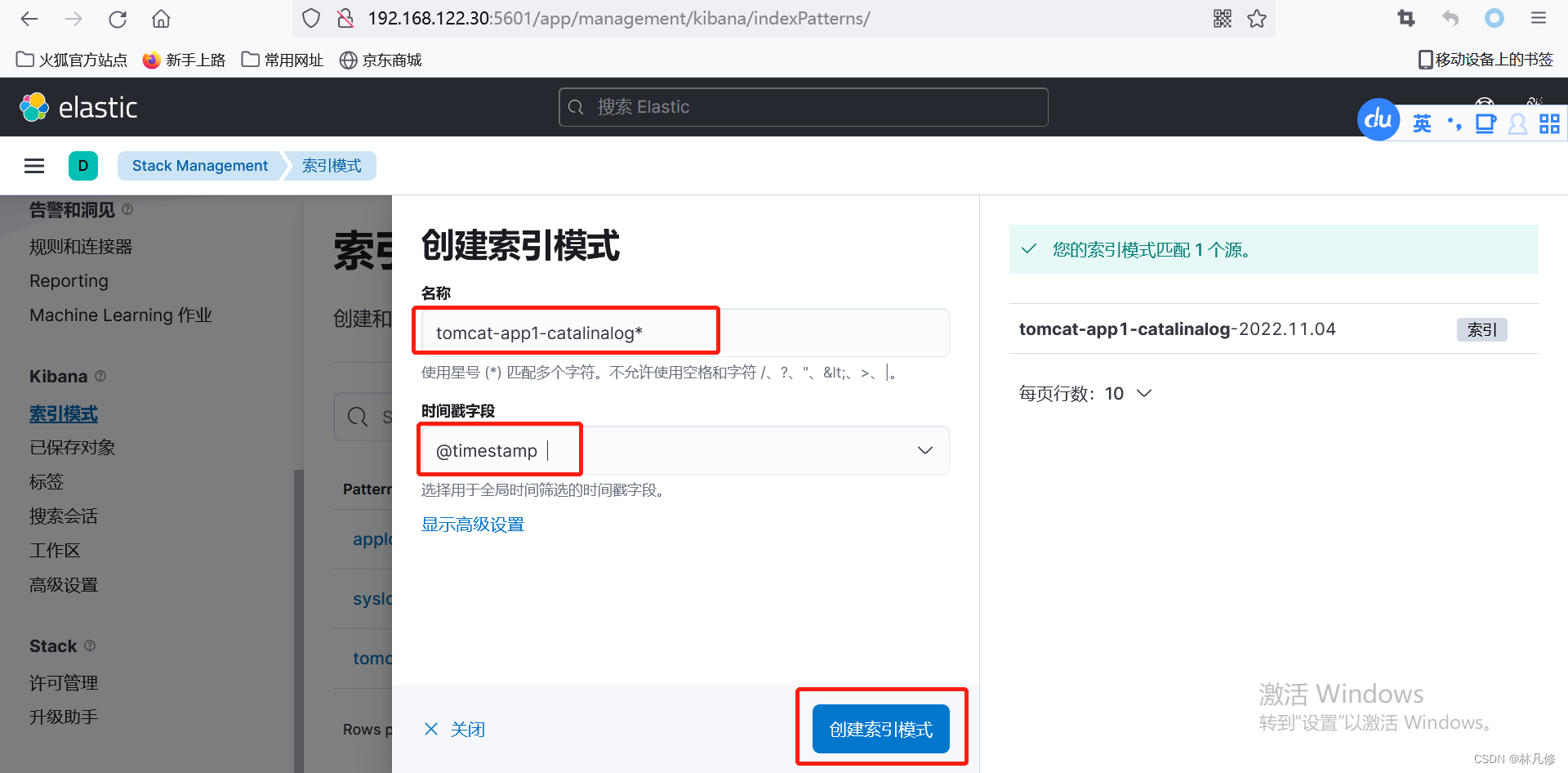
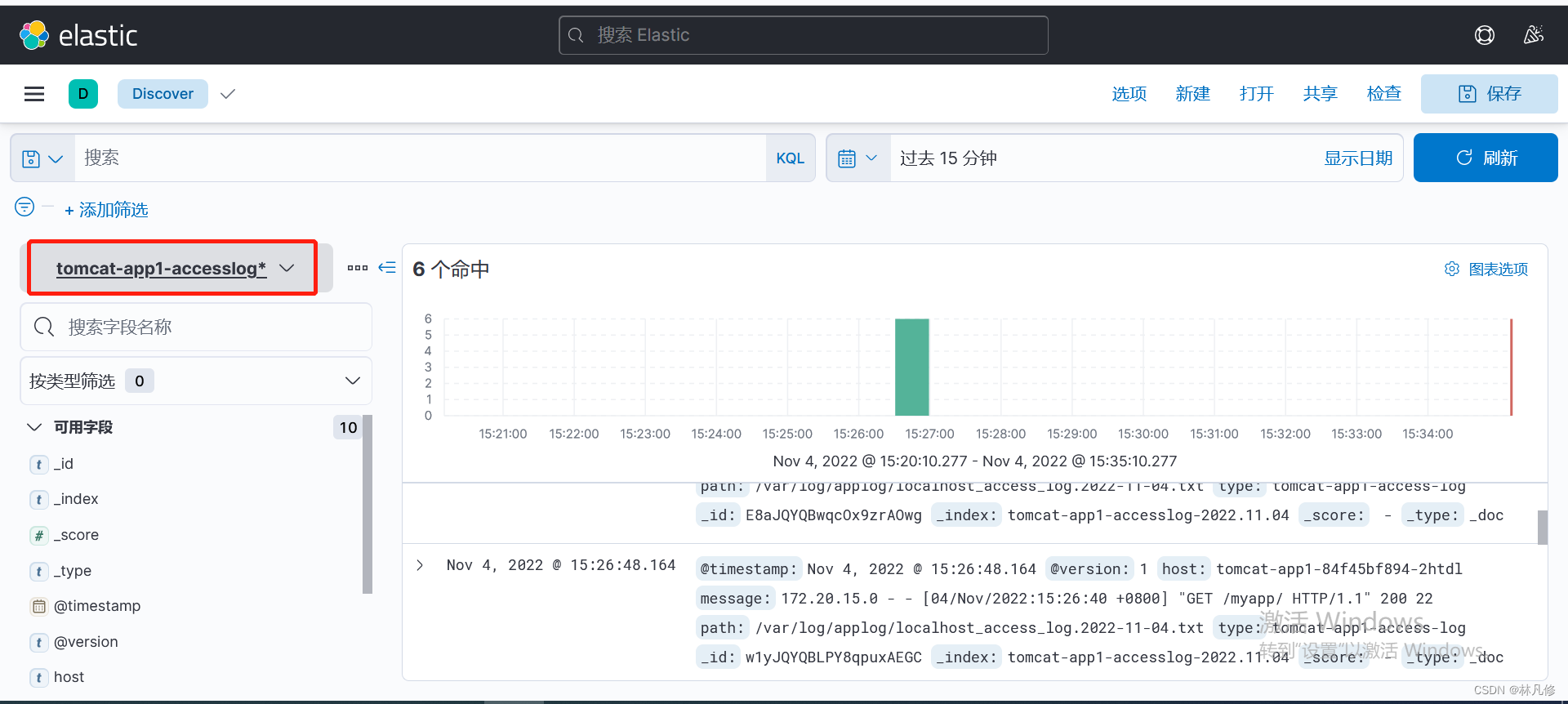
然后就可以在Discovery页面查看相关日志

整体流程如下图:
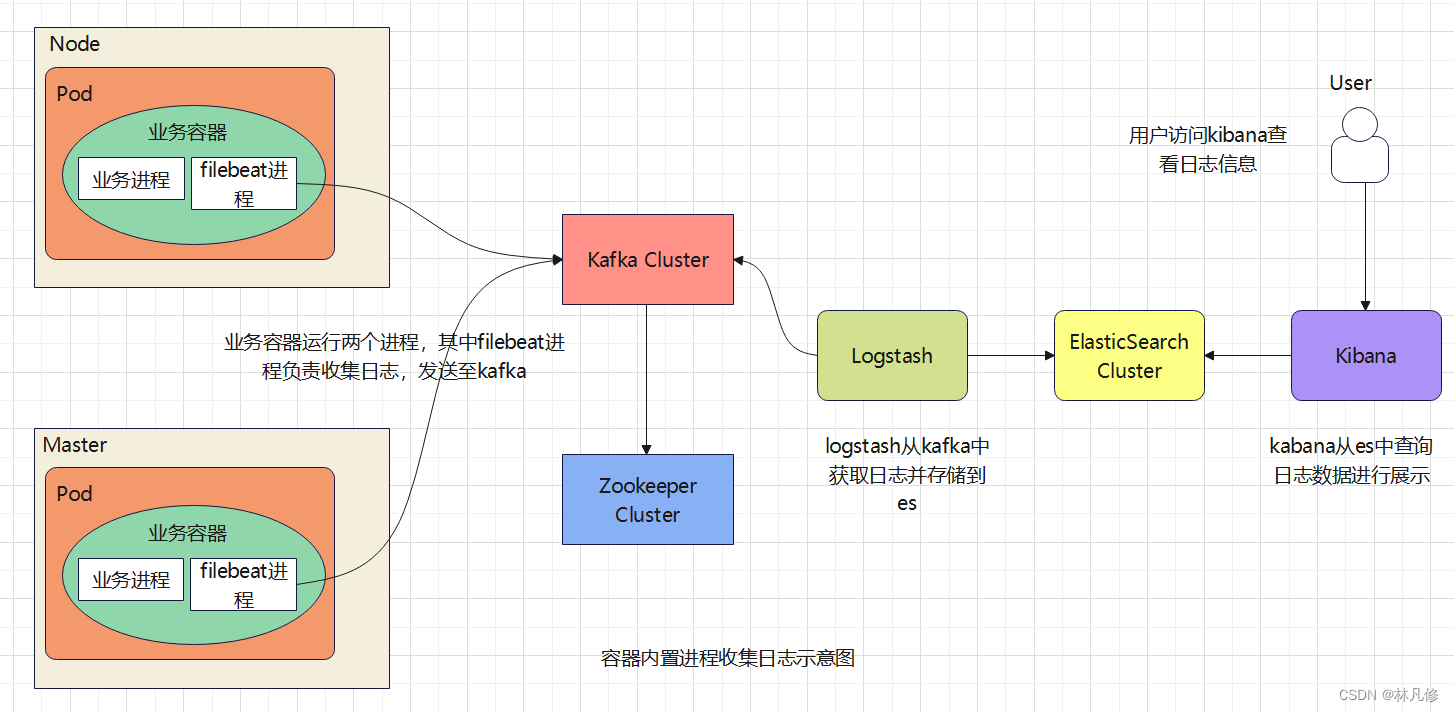
业务镜像内需要运行两个进程,一个是tomcat提供web服务,另一个是filebeat负责收集日志。Dockerfile如下:
FROM harbor-server.linux.io/n70/tomcat-myapp:v1
LABEL author="admin@163.com"
ADD filebeat-7.17.6-amd64.deb /tmp/
RUN cd /tmp/ && dpkg -i filebeat-7.17.6-amd64.deb && rm -f filebeat-7.17.6-amd64.deb
ADD filebeat.yml /etc/filebeat/
ADD run.sh /usr/local/bin/
EXPOSE 8443 8080
CMD ["/usr/local/bin/run.sh"]
filebeat.yml内容如下:
filebeat.inputs:
- type: log
enabled: true
paths:
- /apps/tomcat/logs/catalina.*.log
fields:
type: filebeat-tomcat-catalina
- type: log
enabled: true
paths:
- /apps/tomcat/logs/localhost_access_log.*.txt
fields:
type: filebeat-tomcat-accesslog
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
setup.kibana:
output.kafka:
hosts: ["192.168.122.33:9092", "192.168.122.34:9092", "192.168.122.35:9092"]
required_acks: 1
topic: "filebeat-tomcat-app1"
compression: gzip
max_message_bytes: 1000000
run.sh内容如下:
#!/bin/bash
/usr/share/filebeat/bin/filebeat -e -c /etc/filebeat/filebeat.yml --path.home /usr/share/filebeat --path.config /etc/filebeat --path.data /var/lib/filebeat --path.logs /var/log/filebeat &
su - tomcat -c "/apps/tomcat/bin/catalina.sh run"
执行构建,上传镜像
nerdctl build -t harbor-server.linux.io/n70/tomcat-myapp:v2 .
nerdctl push harbor-server.linux.io/n70/tomcat-myapp:v2
部署文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: tomcat-myapp
spec:
replicas: 3
selector:
matchLabels:
app: tomcat-myapp
template:
metadata:
labels:
app: tomcat-myapp
spec:
containers:
- name: tomcat-myapp
image: harbor-server.linux.io/n70/tomcat-myapp:v2
imagePullPolicy: Always
ports:
- name: http
containerPort: 8080
- name: https
containerPort: 8443

cat /etc/logstash/conf.d/filebeat-process-kafka-to-es.conf
#########################################################
input {
kafka {
bootstrap_servers => "192.168.122.33:9092,192.168.122.34:9092,192.168.122.35:9092"
topics => ["filebeat-tomcat-app1"]
codec => "json"
}
}
output {
if [fields][type] == "filebeat-tomcat-catalina" {
elasticsearch {
hosts => ["192.168.122.30:9200","192.168.122.31:9200","192.168.122.32:9200"]
index => "filebeat-tomcat-catalina-%{+YYYY.MM.dd}"
}}
if [fields][type] == "filebeat-tomcat-accesslog" {
elasticsearch {
hosts => ["172.31.2.101:9200","172.31.2.102:9200"]
index => "filebeat-tomcat-accesslog-%{+YYYY.MM.dd}"
}}
}
###################################################
systemctl restart logstash
创建索引模式
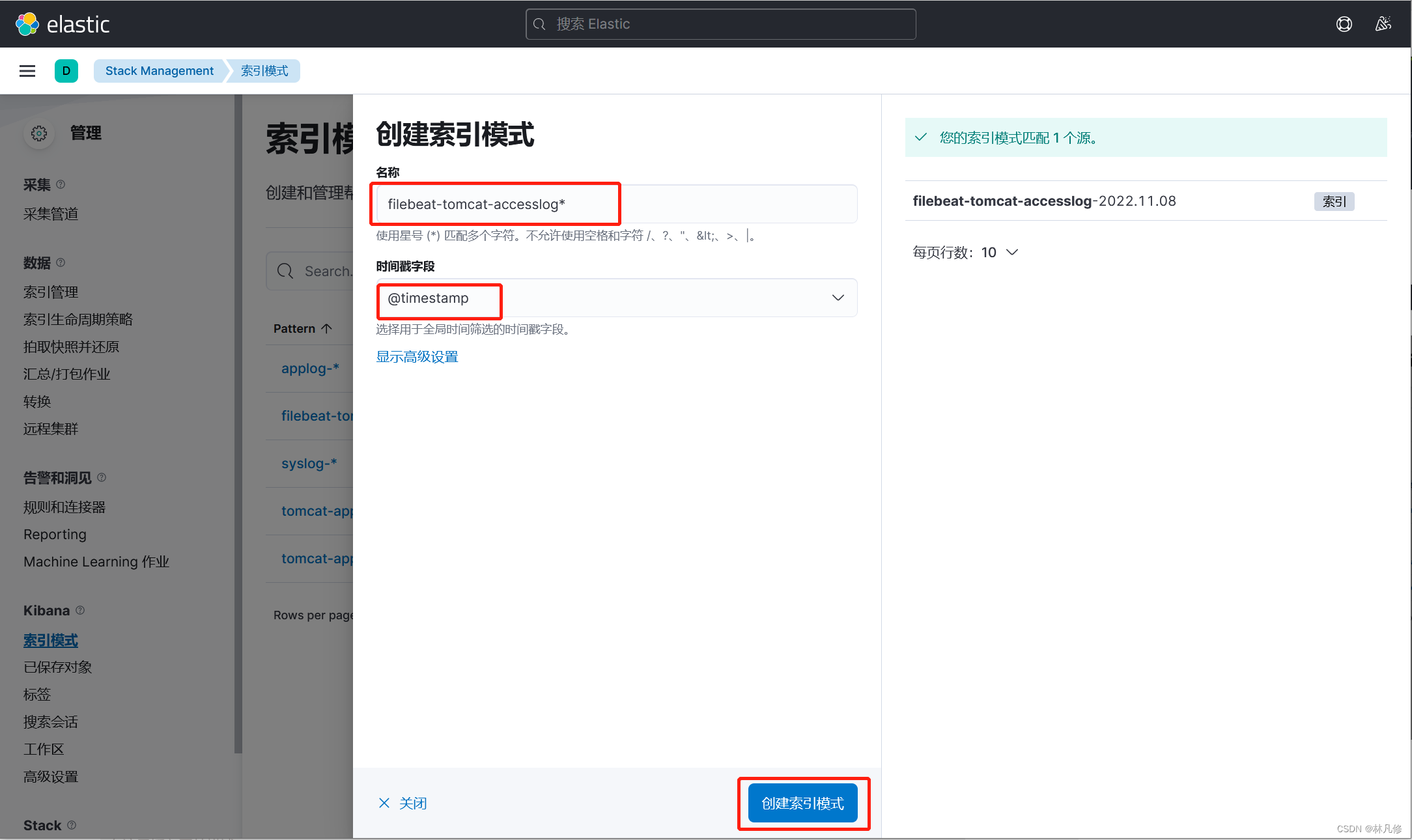
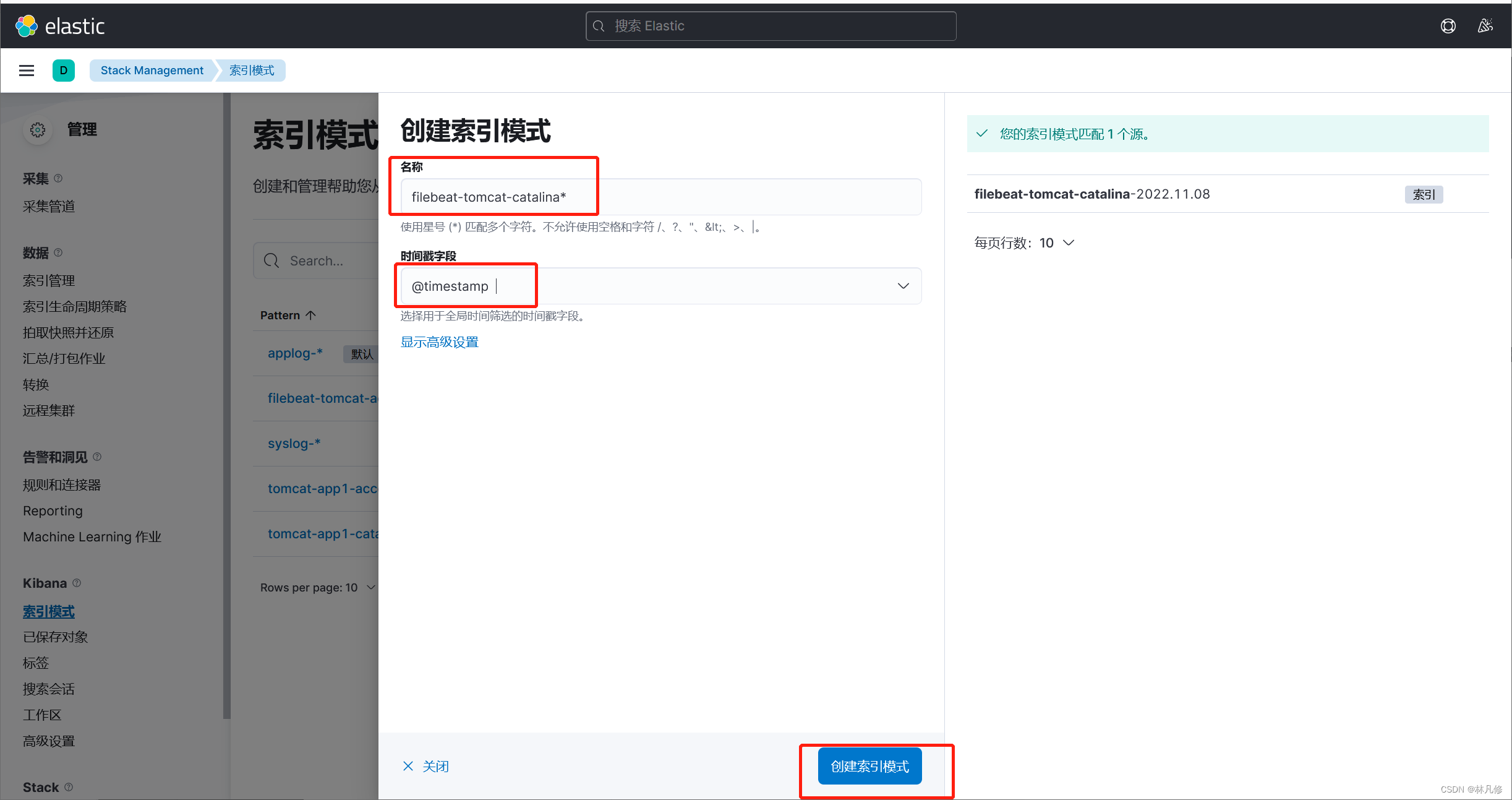
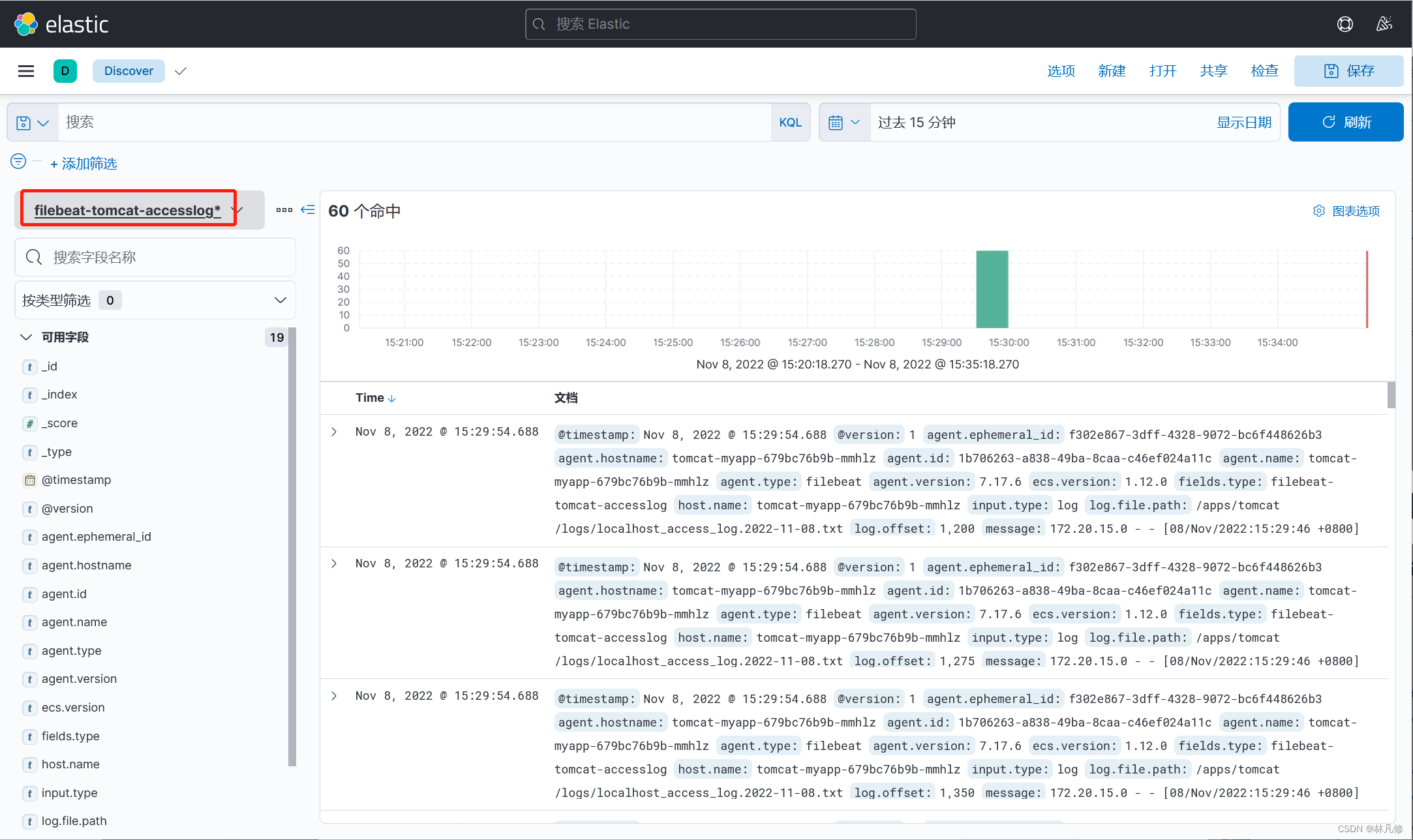
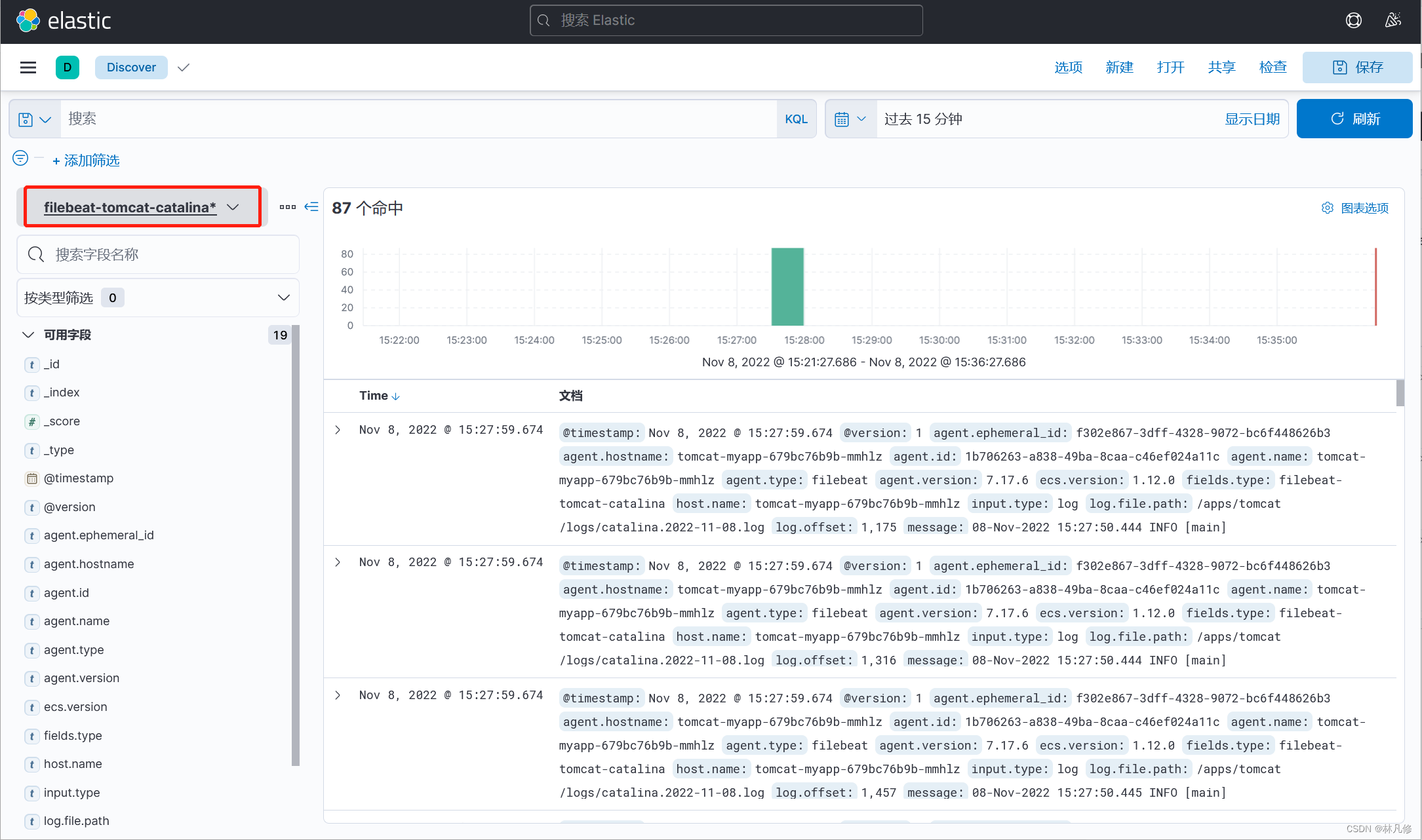
在Discovery界面查看日志
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
在运行Cucumber测试时,我得到(除了测试结果)大量调试/日志相关的输出形式:D,[2013-03-06T12:21:38.911829#49031]DEBUG--:SOAPrequest:D,[2013-03-06T12:21:38.911919#49031]DEBUG--:Pragma:no-cache,SOAPAction:"",Content-Type:text/xml;charset=UTF-8,Content-Length:1592W,[2013-03-06T12:21:38.912360#49031]WARN--:HTTPIexecutesHTTPPOSTusingt
我最近将我的http客户端切换到faraday,一切都按预期工作。我有以下代码来创建连接:@connection=Faraday.new(:url=>base_url)do|faraday|faraday.useCustim::Middlewarefaraday.request:url_encoded#form-encodePOSTparamsfaraday.request:jsonfaraday.response:json,:content_type=>/\bjson$/faraday.response:loggerfaraday.adapterFaraday.default_ada
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
像这样转换数组的最快/单行方法是什么:[1,1,1,1,2,2,3,5,5,5,8,13,21,21,21]...进入像这样的对象数组:[{1=>4},{2=>2},{3=>1},{5=>3},{8=>1},{13=>1},{21=>3}] 最佳答案 要获得所需的格式,您可以附加一个调用以映射到您的解决方案:array.inject({}){|h,v|h[v]||=0;h[v]+=1;h}.map{|k,v|{k=>v}}虽然它仍然是单行的,但它开始变得凌乱了。 关于ruby-在Ruby
我正在使用此代码在我的Sinatra应用程序中启用日志记录:log_file=File.new('my_log_file.log',"a")$stdout.reopen(log_file)$stderr.reopen(log_file)$stdout.sync=true$stderr.sync=true实际的日志记录是使用:logger.debug("Startingcall.Params=#{params.inspect}")事实证明,只有INFO或更高级别的日志消息被记录,而DEBUG消息没有被记录。我正在寻找一种将日志级别设置为DEBUG的方法。 最佳
我有这段代码来跟踪远程日志文件:defdo_tail(session,file)session.open_channeldo|channel|channel.on_datado|ch,data|puts"[#{file}]->#{data}"endchannel.exec"tail-f#{file}"endNet::SSH.start("host","user",:password=>"passwd")do|session|do_tailsession,"/path_to_log/file.log"session.loop我只想在file.log中检索带有ERROR字符串的行,我正在尝
当我为Daemons(1.1.0)gem设置日志记录参数时,我将如何实现与此行类似的行为?logger=Logger.new('foo.log',10,1024000)守护进程选项:options={:ARGV=>['start'],:dir_mode=>:normal,:dir=>log_dir,:multiple=>false,:ontop=>false:mode=>:exec,:backtrace=>true,:log_output=>true} 最佳答案 不幸的是,Daemonsgem不使用Logger。它将STDOUT和S
在Rails3.x应用程序中,我正在使用net::ssh并向远程pc运行一些命令。我想向用户的浏览器显示实时日志。比如,如果两个命令在net中运行::ssh执行即echo"Hello",echo"Bye"被传递然后"Hello"应该在执行后立即显示在浏览器中。这是代码我在rubyonrails应用程序中使用ssh连接和运行命令Net::SSH.start(@servers['local'],@machine_name,:password=>@machine_pwd,:timeout=>30)do|ssh|ssh.open_channeldo|channel|channel.requ