最近在做JavaWeb课程的实验课,今天在尝试jsp通过jdbc连接数据库向MySQL中的user表插入数据后,表内数据出现了中文乱码的问题。下面将详细给出本次问题出现场景以及详细的解决方案。
在我的MySQL中的数据库db1里,有一个名为“user”的表,其属性值如下:
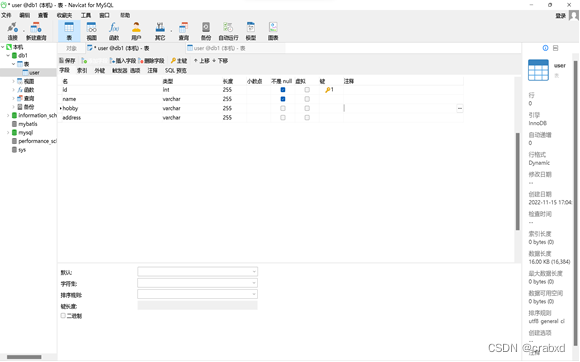
通过navicat向表格中添加一条记录,
用jsp文件查看,可以看到中文能够正常显示。

但是通过jsp文件向数据库插入记录时,便会出现乱码。
向数据库插入一条新记录的代码如下:
<%@ page language="java" contentType="text/html; charset=utf-8" pageEncoding="UTF-8"%>
<%@ page import="java.sql.*"%>
<html>
<head>
<title>通过JDBC连接对user表进行操作</title>
</head>
<%
try {
Class.forName("com.mysql.jdbc.Driver"); //驱动程序名
String url = "jdbc:mysql://127.0.0.1:3306/db1?useUnicode=true&characterEncoding=UTF-8"; //数据库名
String username = "root"; //数据库用户名
String password = xxxx; //数据库用户密码
Connection conn = DriverManager.getConnection(url, username, password); //连接状态
//各个value值
int id =2;
String name = "李四";
String hobby = "吃饭";
String address = "广州";
if(conn != null){
out.print("数据库连接成功!");
out.print("<br />");
String sql = "INSERT INTO USER(id,name,hobby,address) VALUES(?,?,?,?);"; //查询语句
//获取pstmt对象
PreparedStatement pstmt = conn.prepareStatement(sql);
//设置参数
pstmt.setInt(1,id);
pstmt.setString(2,name);
pstmt.setString(3,hobby);
pstmt.setString(4,address);
//执行sql
int count=pstmt.executeUpdate();//影响的行数
//处理结果
System.out.println(count>0);
//释放资源
pstmt.close();
conn.close();
}
else{
out.print("连接失败!");
}
}catch (Exception e) {
out.print("数据库连接异常!");
}
%>
</body>
</html>
通过navicat查看新插入的数据,发现传入的中文全部变成乱码(问号)了,如下图所示。

一般遇到出现乱码的情况,我们都会猜测是编码问题。于是我检查了一下,我的jsp文件使用的是utf-8编码,数据库db1使用的也是utf8,这两者是一样的,为何还会出现乱码的情况呢?
刚开始,我的代码中是的url是:
String url = "jdbc:mysql://127.0.0.1:3306/db1"
后来,我给它加上了参数,确保其是使用utf-8编码,如下:
String url = "jdbc:mysql://127.0.0.1:3306/db1?useUnicode=true&characterEncoding=UTF-8";
但是很遗憾,并没有解决问题,文件中的中文字符传入到user表中依旧是乱码,所以该方法不能行得通。
于是我新建了个查询,显示各部分所采用的编码方式,查询语句如下:
SHOW VARIABLES LIKE 'CHARACTER%';
查询的结果如下:
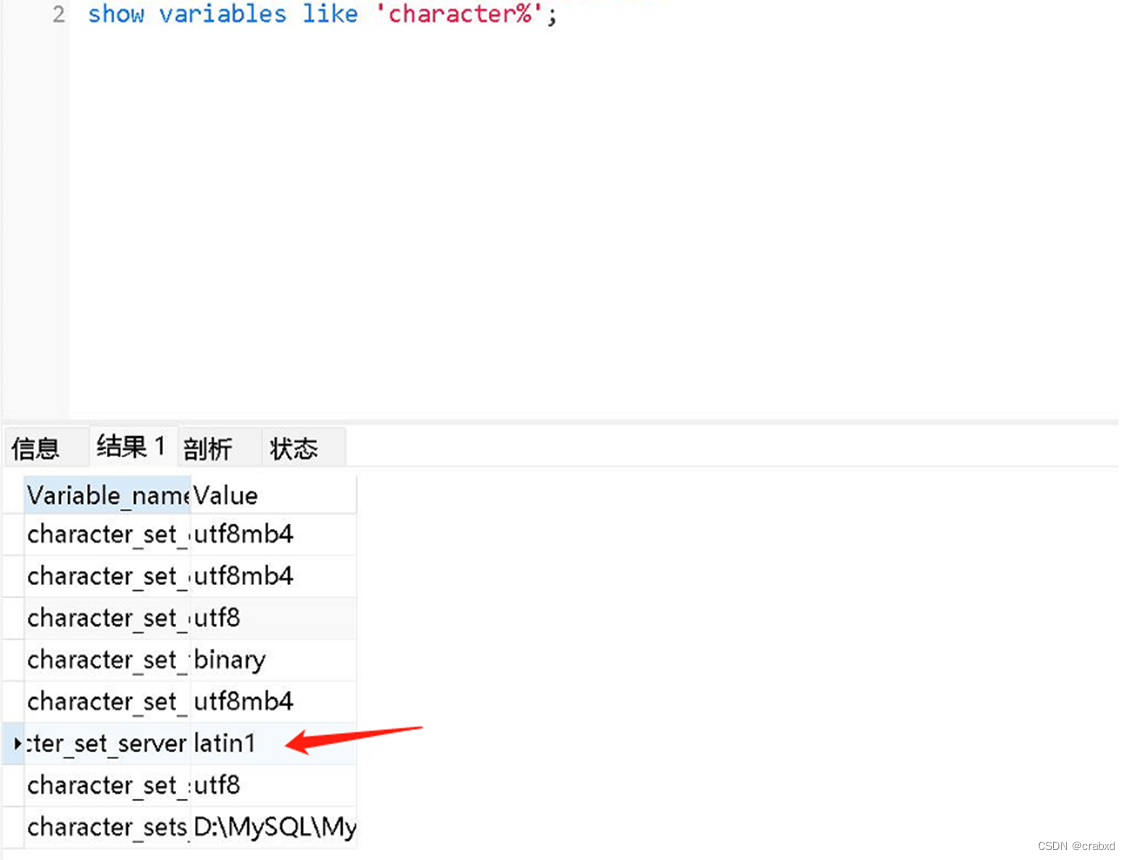
可以看到,这里面这个character_set_server鹤立鸡群,独独使用了Latin1(那个用binary的不算,那是bin文件用的)。
Latin1是MySQL的默认编码,ISO-8859-1的别名,单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。
它包括西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号,但是它不支持中文。所以,直觉告诉我出现问题的地方找到了。
通过上网查询,我了解这是输入到数据库字符的编码,确定是因为此处编码问题导致出现。
于是我使用语句
set @@character_set_server='utf8';”
修改其编码,修改之后再次执行“show variables like ‘character%’;”语句,可以看到它的编码确实被改为utf8。
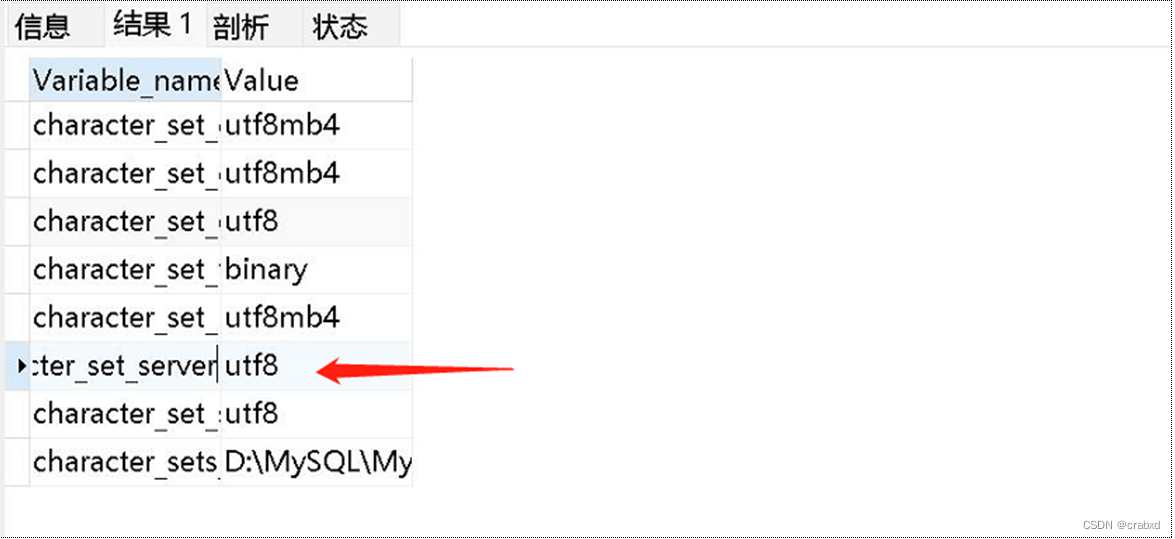
于是我以为问题解决了,便将原先乱码的记录删除,再次运行insert.jsp文件测试向user表插入数据是否会出现乱码。
出乎意料的是,插入的数据依旧是乱码。经过多次刷新和尝试后依旧如此。
于是我重启了我的MySQL,重启后再次查看character_set_server的编码,发现其再次变为Latin1。
我觉得可能是因为配置文件的原因,于是我找到了我的MySQL配置文件my.ini。
该文件是MySQL数据库的配置文件,可以通过修改它来更新MySQL的配置。找到其中character-set-server(如下图所示),可以看到其并未指定编码,所以其还是使用默认的编码,当我们重启后,做出的修改并没有在配置文件中,所以修改会失效。
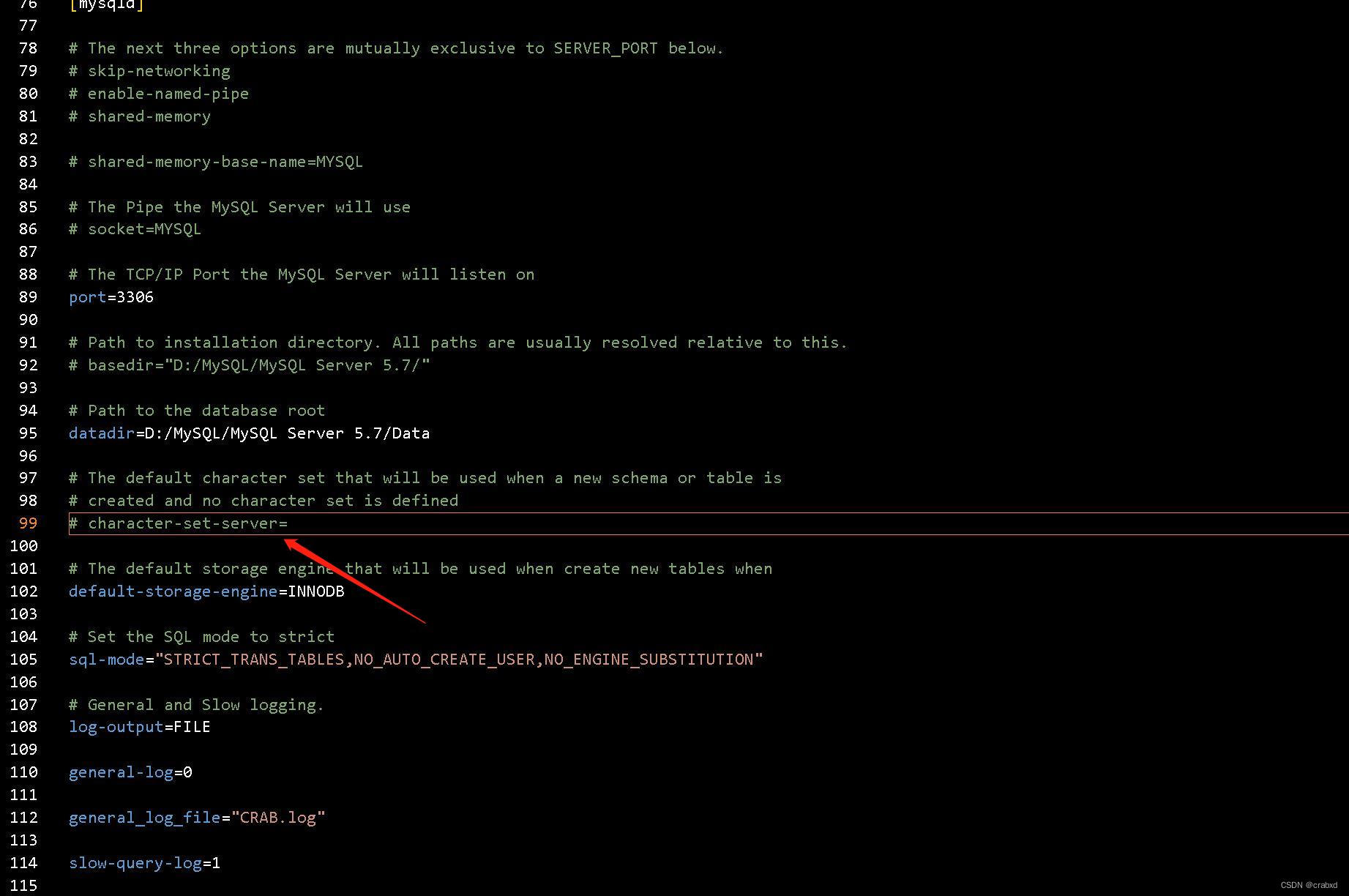
将其改为utf8,并且记得去除'#'号,否则它不会生效。
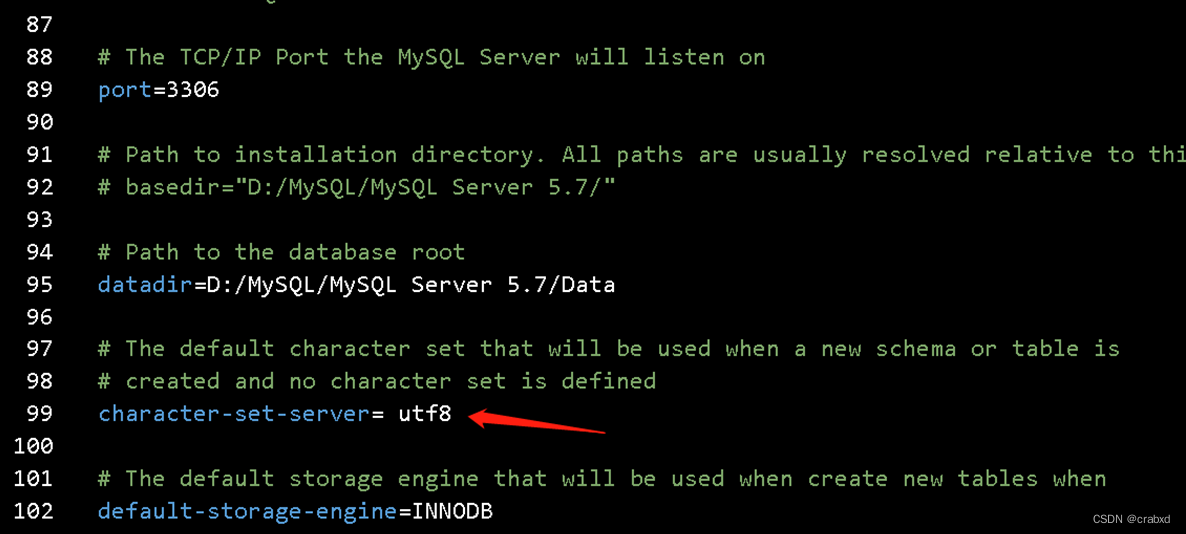
修改后保存文件,重启服务。
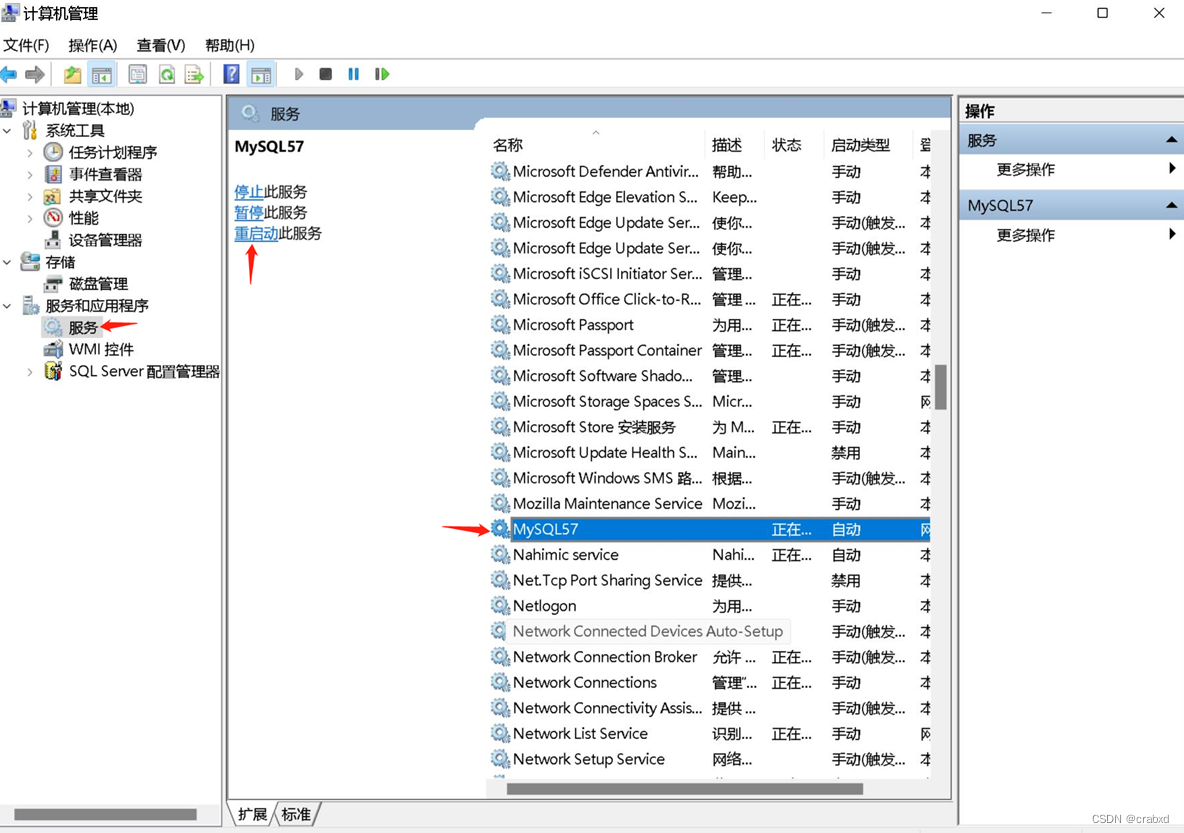
通过win+x快捷键或者右击开始栏,找到“计算机管理”这一选项,点击“服务和应用程序”->“服务”,找到MySQL对应的服务将其重启,如图16所示。
再次插入记录,此时不再出现乱码了,如下图所示。
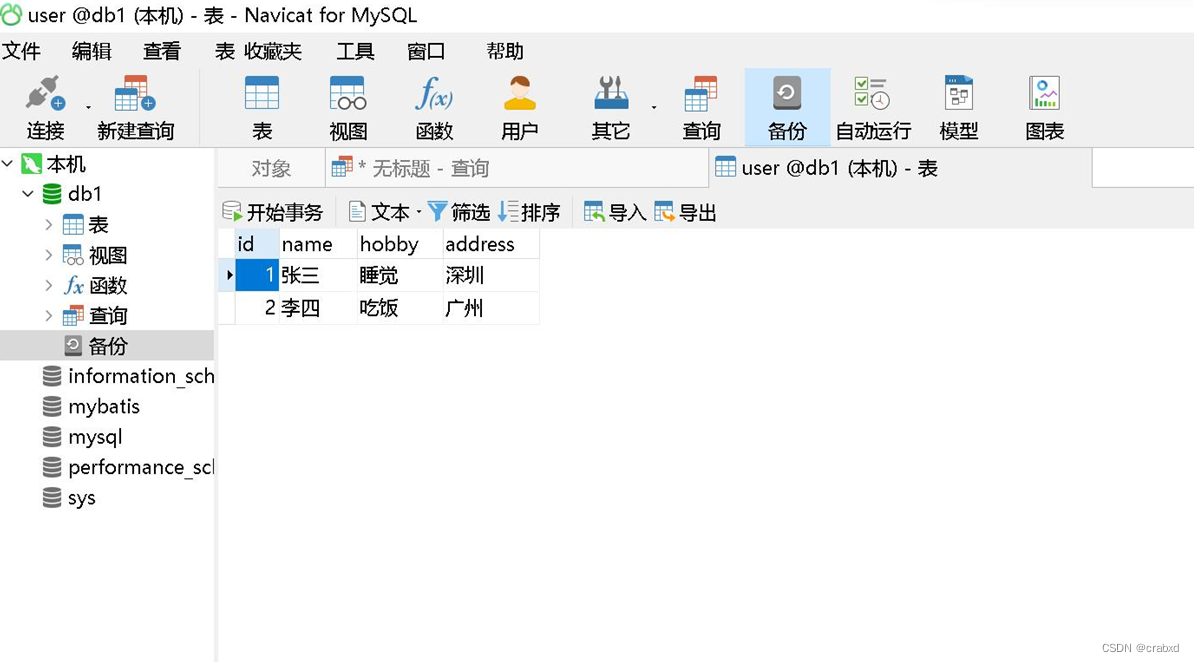
问题解决。
不过在网上查阅相应资料的时候,发现有些朋友在其MySQL的安装文件夹中并没有my.ini文件,所以可以新建一个my.ini文件,将下列内容拷贝进该文件中。
# Other default tuning values
# MySQL Server Instance Configuration File
# ----------------------------------------------------------------------
# Generated by the MySQL Server Instance Configuration Wizard
#
#
# Installation Instructions
# ----------------------------------------------------------------------
#
# On Linux you can copy this file to /etc/my.cnf to set global options,
# mysql-data-dir/my.cnf to set server-specific options
# (@localstatedir@ for this installation) or to
# ~/.my.cnf to set user-specific options.
#
# On Windows you should keep this file in the installation directory
# of your server (e.g. C:\Program Files\MySQL\MySQL Server X.Y). To
# make sure the server reads the config file use the startup option
# "--defaults-file".
#
# To run the server from the command line, execute this in a
# command line shell, e.g.
# mysqld --defaults-file="C:\Program Files\MySQL\MySQL Server X.Y\my.ini"
#
# To install the server as a Windows service manually, execute this in a
# command line shell, e.g.
# mysqld --install MySQLXY --defaults-file="C:\Program Files\MySQL\MySQL Server X.Y\my.ini"
#
# And then execute this in a command line shell to start the server, e.g.
# net start MySQLXY
#
#
# Guidelines for editing this file
# ----------------------------------------------------------------------
#
# In this file, you can use all long options that the program supports.
# If you want to know the options a program supports, start the program
# with the "--help" option.
#
# More detailed information about the individual options can also be
# found in the manual.
#
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
#
#
# CLIENT SECTION
# ----------------------------------------------------------------------
#
# The following options will be read by MySQL client applications.
# Note that only client applications shipped by MySQL are guaranteed
# to read this section. If you want your own MySQL client program to
# honor these values, you need to specify it as an option during the
# MySQL client library initialization.
#
[client]
# pipe=
# socket=MYSQL
port=3306
[mysql]
no-beep
# default-character-set=
# SERVER SECTION
# ----------------------------------------------------------------------
#
# The following options will be read by the MySQL Server. Make sure that
# you have installed the server correctly (see above) so it reads this
# file.
#
# server_type=3
[mysqld]
# The next three options are mutually exclusive to SERVER_PORT below.
# skip-networking
# enable-named-pipe
# shared-memory
# shared-memory-base-name=MYSQL
# The Pipe the MySQL Server will use
# socket=MYSQL
# The TCP/IP Port the MySQL Server will listen on
port=3306
# Path to installation directory. All paths are usually resolved relative to this.
# basedir="D:/MySQL/MySQL Server 5.7/"
# Path to the database root
datadir=D:/MySQL/MySQL Server 5.7/Data
# The default character set that will be used when a new schema or table is
# created and no character set is defined
character-set-server= utf8
# The default storage engine that will be used when create new tables when
default-storage-engine=INNODB
# Set the SQL mode to strict
sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
# General and Slow logging.
log-output=FILE
general-log=0
general_log_file="CRAB.log"
slow-query-log=1
slow_query_log_file="CRAB-slow.log"
long_query_time=10
# Binary Logging.
# log-bin
# Error Logging.
log-error="CRAB.err"
# Server Id.
server-id=1
# Specifies the on how table names are stored in the metadata.
# If set to 0, will throw an error on case-insensitive operative systems
# If set to 1, table names are stored in lowercase on disk and comparisons are not case sensitive.
# If set to 2, table names are stored as given but compared in lowercase.
# This option also applies to database names and table aliases.
lower_case_table_names=1
# Secure File Priv.
secure-file-priv="C:/ProgramData/MySQL/MySQL Server 5.7/Uploads"
# The maximum amount of concurrent sessions the MySQL server will
# allow. One of these connections will be reserved for a user with
# SUPER privileges to allow the administrator to login even if the
# connection limit has been reached.
max_connections=151
# The number of open tables for all threads. Increasing this value
# increases the number of file descriptors that mysqld requires.
# Therefore you have to make sure to set the amount of open files
# allowed to at least 4096 in the variable "open-files-limit" in
# section [mysqld_safe]
table_open_cache=2000
# Maximum size for internal (in-memory) temporary tables. If a table
# grows larger than this value, it is automatically converted to disk
# based table This limitation is for a single table. There can be many
# of them.
tmp_table_size=85M
# How many threads we should keep in a cache for reuse. When a client
# disconnects, the client's threads are put in the cache if there aren't
# more than thread_cache_size threads from before. This greatly reduces
# the amount of thread creations needed if you have a lot of new
# connections. (Normally this doesn't give a notable performance
# improvement if you have a good thread implementation.)
thread_cache_size=10
#*** MyISAM Specific options
# The maximum size of the temporary file MySQL is allowed to use while
# recreating the index (during REPAIR, ALTER TABLE or LOAD DATA INFILE.
# If the file-size would be bigger than this, the index will be created
# through the key cache (which is slower).
myisam_max_sort_file_size=100G
# If the temporary file used for fast index creation would be bigger
# than using the key cache by the amount specified here, then prefer the
# key cache method. This is mainly used to force long character keys in
# large tables to use the slower key cache method to create the index.
myisam_sort_buffer_size=161M
# Size of the Key Buffer, used to cache index blocks for MyISAM tables.
# Do not set it larger than 30% of your available memory, as some memory
# is also required by the OS to cache rows. Even if you're not using
# MyISAM tables, you should still set it to 8-64M as it will also be
# used for internal temporary disk tables.
key_buffer_size=8M
# Size of the buffer used for doing full table scans of MyISAM tables.
# Allocated per thread, if a full scan is needed.
read_buffer_size=64K
read_rnd_buffer_size=256K
#*** INNODB Specific options ***
# innodb_data_home_dir=
# Use this option if you have a MySQL server with InnoDB support enabled
# but you do not plan to use it. This will save memory and disk space
# and speed up some things.
# skip-innodb
# If set to 1, InnoDB will flush (fsync) the transaction logs to the
# disk at each commit, which offers full ACID behavior. If you are
# willing to compromise this safety, and you are running small
# transactions, you may set this to 0 or 2 to reduce disk I/O to the
# logs. Value 0 means that the log is only written to the log file and
# the log file flushed to disk approximately once per second. Value 2
# means the log is written to the log file at each commit, but the log
# file is only flushed to disk approximately once per second.
innodb_flush_log_at_trx_commit=1
# The size of the buffer InnoDB uses for buffering log data. As soon as
# it is full, InnoDB will have to flush it to disk. As it is flushed
# once per second anyway, it does not make sense to have it very large
# (even with long transactions).
innodb_log_buffer_size=1M
# InnoDB, unlike MyISAM, uses a buffer pool to cache both indexes and
# row data. The bigger you set this the less disk I/O is needed to
# access data in tables. On a dedicated database server you may set this
# parameter up to 80% of the machine physical memory size. Do not set it
# too large, though, because competition of the physical memory may
# cause paging in the operating system. Note that on 32bit systems you
# might be limited to 2-3.5G of user level memory per process, so do not
# set it too high.
innodb_buffer_pool_size=8M
# Size of each log file in a log group. You should set the combined size
# of log files to about 25%-100% of your buffer pool size to avoid
# unneeded buffer pool flush activity on log file overwrite. However,
# note that a larger logfile size will increase the time needed for the
# recovery process.
innodb_log_file_size=48M
# Number of threads allowed inside the InnoDB kernel. The optimal value
# depends highly on the application, hardware as well as the OS
# scheduler properties. A too high value may lead to thread thrashing.
innodb_thread_concurrency=33
# The increment size (in MB) for extending the size of an auto-extend InnoDB system tablespace file when it becomes full.
innodb_autoextend_increment=64
# The number of regions that the InnoDB buffer pool is divided into.
# For systems with buffer pools in the multi-gigabyte range, dividing the buffer pool into separate instances can improve concurrency,
# by reducing contention as different threads read and write to cached pages.
innodb_buffer_pool_instances=8
# Determines the number of threads that can enter InnoDB concurrently.
innodb_concurrency_tickets=5000
# Specifies how long in milliseconds (ms) a block inserted into the old sublist must stay there after its first access before
# it can be moved to the new sublist.
innodb_old_blocks_time=1000
# It specifies the maximum number of .ibd files that MySQL can keep open at one time. The minimum value is 10.
innodb_open_files=300
# When this variable is enabled, InnoDB updates statistics during metadata statements.
innodb_stats_on_metadata=0
# When innodb_file_per_table is enabled (the default in 5.6.6 and higher), InnoDB stores the data and indexes for each newly created table
# in a separate .ibd file, rather than in the system tablespace.
innodb_file_per_table=1
# Use the following list of values: 0 for crc32, 1 for strict_crc32, 2 for innodb, 3 for strict_innodb, 4 for none, 5 for strict_none.
innodb_checksum_algorithm=0
# The number of outstanding connection requests MySQL can have.
# This option is useful when the main MySQL thread gets many connection requests in a very short time.
# It then takes some time (although very little) for the main thread to check the connection and start a new thread.
# The back_log value indicates how many requests can be stacked during this short time before MySQL momentarily
# stops answering new requests.
# You need to increase this only if you expect a large number of connections in a short period of time.
back_log=80
# If this is set to a nonzero value, all tables are closed every flush_time seconds to free up resources and
# synchronize unflushed data to disk.
# This option is best used only on systems with minimal resources.
flush_time=0
# The minimum size of the buffer that is used for plain index scans, range index scans, and joins that do not use
# indexes and thus perform full table scans.
join_buffer_size=256K
# The maximum size of one packet or any generated or intermediate string, or any parameter sent by the
# mysql_stmt_send_long_data() C API function.
max_allowed_packet=4M
# If more than this many successive connection requests from a host are interrupted without a successful connection,
# the server blocks that host from performing further connections.
max_connect_errors=100
# Changes the number of file descriptors available to mysqld.
# You should try increasing the value of this option if mysqld gives you the error "Too many open files".
open_files_limit=4161
# If you see many sort_merge_passes per second in SHOW GLOBAL STATUS output, you can consider increasing the
# sort_buffer_size value to speed up ORDER BY or GROUP BY operations that cannot be improved with query optimization
# or improved indexing.
sort_buffer_size=256K
# The number of table definitions (from .frm files) that can be stored in the definition cache.
# If you use a large number of tables, you can create a large table definition cache to speed up opening of tables.
# The table definition cache takes less space and does not use file descriptors, unlike the normal table cache.
# The minimum and default values are both 400.
table_definition_cache=1400
# Specify the maximum size of a row-based binary log event, in bytes.
# Rows are grouped into events smaller than this size if possible. The value should be a multiple of 256.
binlog_row_event_max_size=8K
# If the value of this variable is greater than 0, a replication slave synchronizes its master.info file to disk.
# (using fdatasync()) after every sync_master_info events.
sync_master_info=10000
# If the value of this variable is greater than 0, the MySQL server synchronizes its relay log to disk.
# (using fdatasync()) after every sync_relay_log writes to the relay log.
sync_relay_log=10000
# If the value of this variable is greater than 0, a replication slave synchronizes its relay-log.info file to disk.
# (using fdatasync()) after every sync_relay_log_info transactions.
sync_relay_log_info=10000
# Load mysql plugins at start."plugin_x ; plugin_y".
# plugin_load
# The TCP/IP Port the MySQL Server X Protocol will listen on.
# loose_mysqlx_port=33060
但单纯复制添加了该文件还不行,此时mysql的注册表中的路径指向的并不是我们刚刚创建的那个my.ini。
win+r,输入regedit查看注册表,如图所示。

找路径:

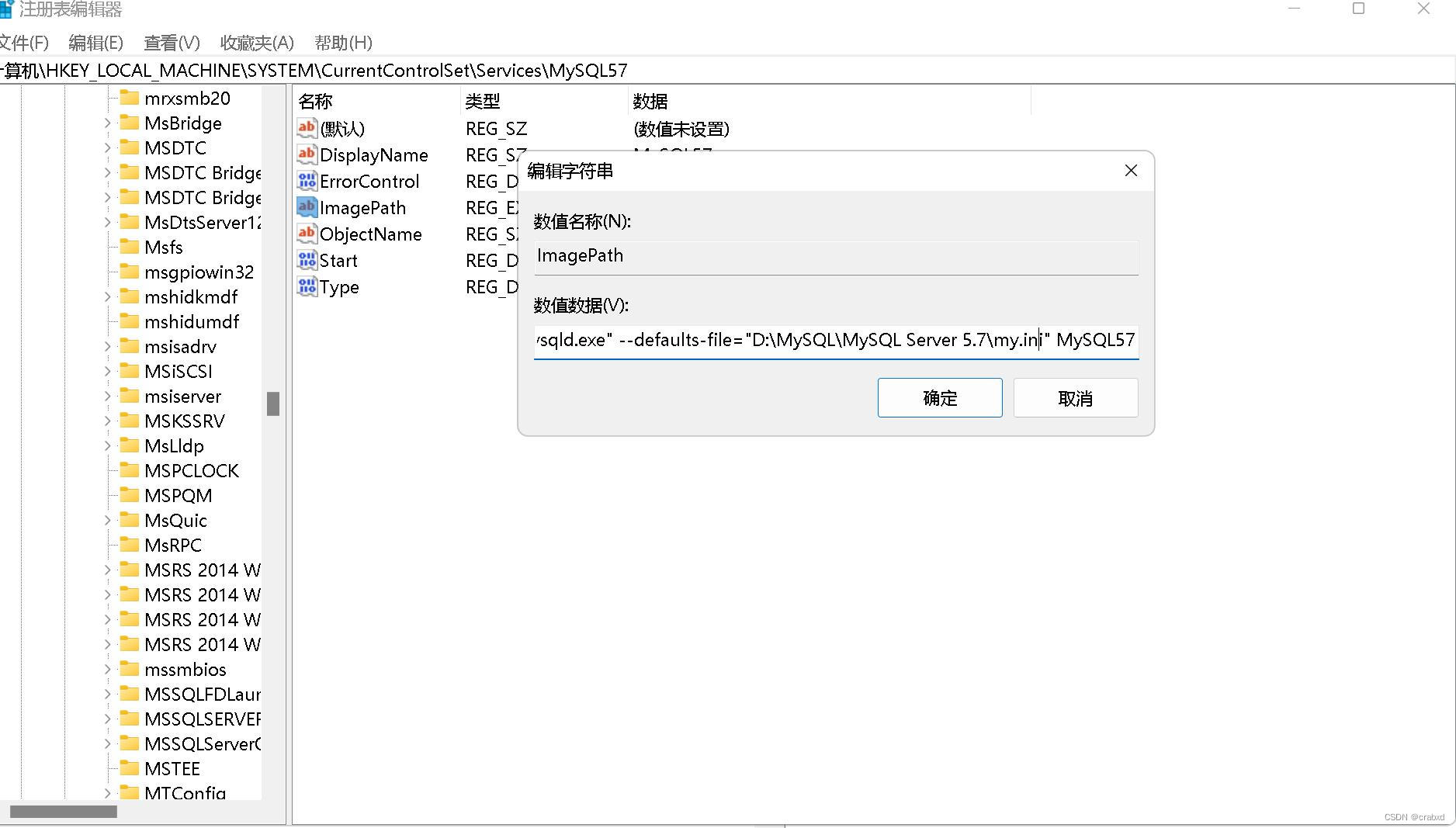
修改ImagePath路径,修改为我们所创建的my.ini便可以了。
java向Mysql数据库添加中文数据,在数据库显示乱码
关于mysql修改character_set_server = utf8不生效的问题
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
在我的Rails(2.3,Ruby1.8.7)应用程序中,我需要将字符串截断到一定长度。该字符串是unicode,在控制台中运行测试时,例如'א'.length,我意识到返回了双倍长度。我想要一个与编码无关的长度,以便对unicode字符串或latin1编码字符串进行相同的截断。我已经了解了Ruby的大部分unicode资料,但仍然有些一头雾水。应该如何解决这个问题? 最佳答案 Rails有一个返回多字节字符的mb_chars方法。试试unicode_string.mb_chars.slice(0,50)
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我有一大串格式化数据(例如JSON),我想使用Psychinruby同时保留格式转储到YAML。基本上,我希望JSON使用literalstyle出现在YAML中:---json:|{"page":1,"results":["item","another"],"total_pages":0}但是,当我使用YAML.dump时,它不使用文字样式。我得到这样的东西:---json:!"{\n\"page\":1,\n\"results\":[\n\"item\",\"another\"\n],\n\"total_pages\":0\n}\n"我如何告诉Psych以想要的样式转储标量?解
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',