最近在看《算法图解》,其中第七章狄克斯特拉算法个人感觉并没有讲的清楚,比如看完7.1节给人的感觉是狄克斯特拉算法会遍历图中的每一条边,后续狄克斯特拉不适用负权边的说法就站不住脚了。后续在查阅诸多资料之后,总结文章一篇,尽可能以通俗易懂且思路清晰的方式来讲解狄克斯特拉算法。
狄克斯特拉算法用于寻找在加权图中前往目标节点的最短路径,加权图是对边进行加权的图。
设想这样一个场景——在一个没有负权边的有向图中,如果从起点直接到节点A的开销小于从起点直接到节点B的开销,那么即使从起点出发经过节点B还有其他路径可以到达节点A,其总开销也会大于从起点到节点A的开销。
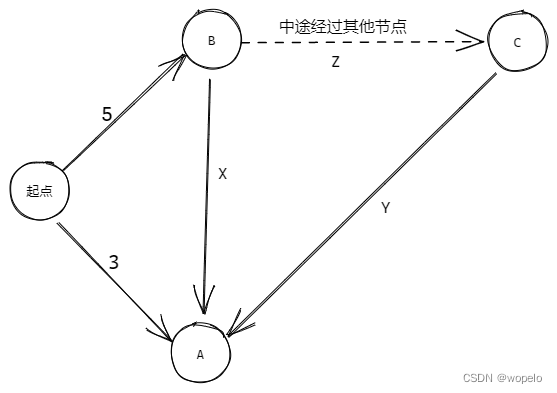
比如在上图中,起点到A的开销为3,这个开销一定小于从起点开始经其他节点到A的总开销,因为从起点到B的开销就已经大于从起点到A的开销。
上面推论的结果就是——最短路径的子路径仍然是最短路径 。比如在上图中,如果最短路径经过了A,那么在最短路径中从起点到A的子路径一定是所有从起点到A的路径中最短的那条。
这个结论可能有点反直觉,因为我们可能会认为虽然前面的子路径不是最短的,但只要后面的子路径选的好,加起来仍然可以得到最短路径。但我们可以这样理解,在当前的最短路径中,点A到终点的路径保持不变,将起点到点A的路径设为L1。如果L1不是起点到点A最短的路径,则存在起点到点A的另外一条路径L2使得L2 < L1,将L1替换成L2,即可得到一条比当前最短路径还要短的路径,那么当前路径就不是最短路径了。路径上的每个点都能以此类推。由此可以证明在没有负权边的情况下,最短路径的子路径仍然是最短路径。
这也解释了为什么狄克斯特拉算法每次都从当前节点开销最少的邻居节点开始下一轮处理。
狄克斯特拉算法可分为5步:
我们通过两个例子来体验上述步骤。
找出下图中,从起点到终点的最短路径
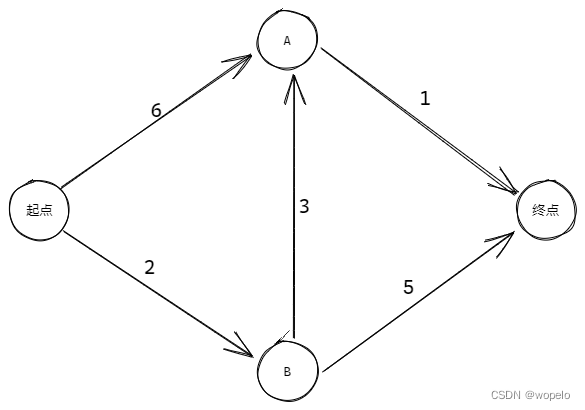
准备一张表,存储从起点到各个节点的开销及其父节点,作用是方便最后找出最短路径和最短路径的长度。
初始化时,设起点开销为0,其他节点开销为 inf (无限大),算法结束的条件就是除终点外的所有节点都被处理了。
| 节点 | 父节点 | 开销 | 是否已处理 |
|---|---|---|---|
| 起点 | - | 0 | 否 |
| A | - | inf | 否 |
| B | - | inf | 否 |
| 终点 | - | inf | - |
找出当前开销最小的未处理节点,得到起点。起点的邻居是A和B,将其他不能直接到达的节点开销保持为 inf ,更新表:
| 节点 | 父节点 | 开销 | 是否已处理 |
|---|---|---|---|
| 起点 | - | 0 | 是 |
| A | 起点 | 6 | 否 |
| B | 起点 | 2 | 否 |
| 终点 | - | inf | - |
继续找出当前开销最小的未处理节点,得到节点B,计算经节点B前往其各个邻居的开销:
更新表:
| 节点 | 父节点 | 开销 | 是否已处理 |
|---|---|---|---|
| 起点 | - | 0 | 是 |
| A | B | 5 | 否 |
| B | 起点 | 2 | 否 |
| 终点 | B | 7 | - |
至此B节点的所有邻居处理完毕,将B标识为已处理:
| 节点 | 父节点 | 开销 | 是否已处理 |
|---|---|---|---|
| 起点 | - | 0 | 是 |
| A | B | 5 | 否 |
| B | 起点 | 2 | 是 |
| 终点 | B | 7 | - |
重复上面的过程,找出当前开销最小的未处理节点,得到A,计算经节点A前往其各个邻居的开销:
更新表:
| 节点 | 父节点 | 开销 | 是否已处理 |
|---|---|---|---|
| 起点 | - | 0 | 是 |
| A | B | 5 | 否 |
| B | 起点 | 2 | 是 |
| 终点 | A | 6 | - |
至此A节点的所有邻居处理完毕,将A标识为已处理:
| 节点 | 父节点 | 开销 | 是否已处理 |
|---|---|---|---|
| 起点 | - | 0 | 是 |
| A | B | 5 | 是 |
| B | 起点 | 2 | 是 |
| 终点 | A | 6 | - |
到此所有除了终点的节点都经过检查,得出从起点到终点最短距离为6,最短路径通过终点的父节点逐级向上追溯为:起点 -> B -> A -> 终点。
示例2由示例1改变节点B到节点A路径的方向而来,通过该示例可以更好的理解狄克斯特拉算法的处理过程。
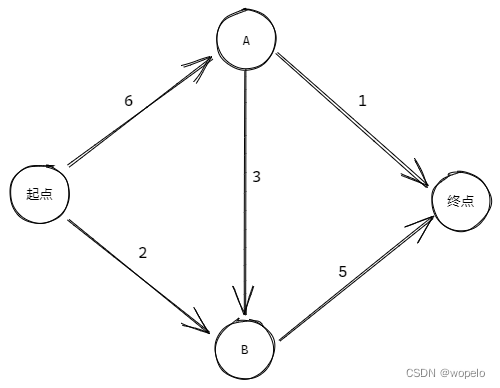
同样的操作,准备一张表:
| 节点 | 父节点 | 开销 | 是否已处理 |
|---|---|---|---|
| 起点 | - | 0 | 否 |
| A | - | inf | 否 |
| B | - | inf | 否 |
| 终点 | - | inf | - |
找出当前开销最小的未处理节点,得到起点,起点的邻居是A和B,更新表:
| 节点 | 父节点 | 开销 | 是否已处理 |
|---|---|---|---|
| 起点 | - | 0 | 是 |
| A | 起点 | 6 | 否 |
| B | 起点 | 2 | 否 |
| 终点 | - | inf | - |
找出当前开销最小的未处理节点,得到节点B,更新表:
| 节点 | 父节点 | 开销 | 是否已处理 |
|---|---|---|---|
| 起点 | - | 0 | 是 |
| A | 起点 | 6 | 否 |
| B | 起点 | 2 | 是 |
| 终点 | B | 7 | - |
找出下一个开销最小的未处理节点,得到节点A,对节点A的处理就和示例1有所不同了。
节点A有两个邻居:节点B和终点。但节点B已经处理过了,这意味着当前由起点前往节点B的开销最少的路径已经被发现了,结合之前的定理,这意味着两点:
综上,不必要检查 A-> B 这条路径的开销,只需要检查 A -> 终点 这条路径的开销。
由于 起点 -> A -> 终点 这条路径的开销没有小于 7,所以不更新A邻居节点的开销,只将A置为已处理即可:
| 节点 | 父节点 | 开销 | 是否已处理 |
|---|---|---|---|
| 起点 | - | 0 | 是 |
| A | 起点 | 6 | 是 |
| B | 起点 | 2 | 是 |
| 终点 | B | 7 | - |
到此所有除了终点的节点都经过检查,得出从起点到终点最短距离为7,最短路径通过终点的父节点逐级向上追溯为:起点 -> B -> 终点
需要注意的是,这次我们只找到了其中一条最短路径,因为 起点 -> A -> 终点 这条路径的开销也是 7。
下面用python展示从下图中找出用乐谱交换钢琴需要额外支付费用最少的路径
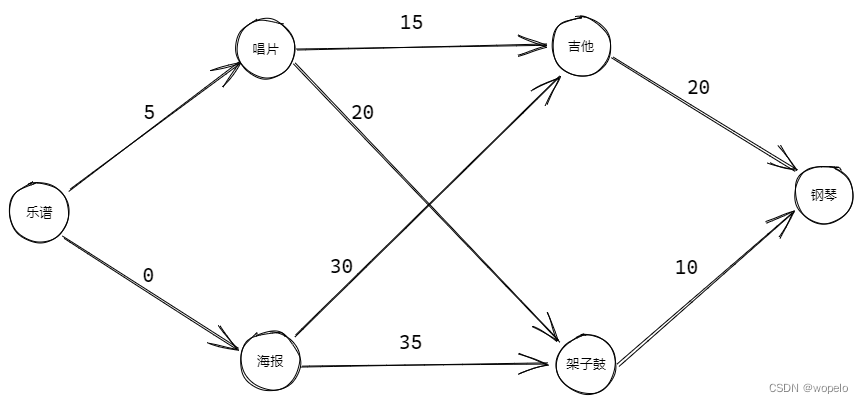
# 使用狄克斯特拉在加权有向图中寻找最短路径
from cmath import inf
# 构建图
map = {}
map['乐谱'] = {}
map['乐谱']['唱片'] = 5
map['乐谱']['海报'] = 0
map['唱片'] = {}
map['唱片']['吉他'] = 15
map['唱片']['架子鼓'] = 20
map['海报'] = {}
map['海报']['吉他'] = 30
map['海报']['架子鼓'] = 35
map['吉他'] = {}
map['吉他']['钢琴'] = 20
map['架子鼓'] = {}
map['架子鼓']['钢琴'] = 10
# 初始化table中的行
def initRow(costs, key, cost):
costs[key] = {}
costs[key]['father'] = None
costs[key]['cost'] = cost
costs[key]['isChecked'] = False
# 获取当前开销最少的节点
def findLowerCostNode(costs):
key = None
cost = float(inf)
for name in costs:
item = costs[name]
if (item['isChecked'] == False and item['cost'] < cost ):
cost = item['cost']
key = name
return key
def dijkstra(map, start, end):
# 初始化表
costs = {}
initRow(costs, start, 0)
key = findLowerCostNode(costs)
while (key != None and key != end):
# 获取邻居
neighbors = map[key].keys()
# 检查到邻居的开销
for neighbor in neighbors:
# 如果邻居不在costs中,则添加
if (neighbor not in costs):
initRow(costs, neighbor, float(inf))
# 获取到key的开销
newCost = map[key][neighbor] + costs[key]['cost']
# 如果经key到邻居的开销小于已有开销
if (newCost < costs[neighbor]['cost']):
costs[neighbor]['cost'] = newCost
costs[neighbor]['father'] = key
# key的所有邻居都检查过了
costs[key]['isChecked'] = True
key = findLowerCostNode(costs)
# 打印结果
key = end
routes = []
while (key != None):
node = costs[key]
routes.insert(0, key)
father = node['father']
key = father
print(f'最短路径为: {"->".join(routes)},开销{costs[end]["cost"]}')
# print(costs)
dijkstra(map, '乐谱', '钢琴')
负权边即权重为负的边,如果有负权边,则不能使用狄克斯特拉算法,而应该使用贝尔曼-福德算法。

还是用这张图举例,如果X、Y、Z中有负数,那经过B到的A的开销可能就比3小了,即使从起点到B的开销大于从起点到A开销。
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
我一直在尝试用Ruby实现Luhn算法。我一直在执行以下步骤:该公式根据其包含的校验位验证数字,该校验位通常附加到部分帐号以生成完整帐号。此帐号必须通过以下测试:从最右边的校验位开始向左移动,每第二个数字的值加倍。将乘积的数字(例如,10=1+0=1、14=1+4=5)与原始数字的未加倍数字相加。如果总模10等于0(如果总和以零结尾),则根据Luhn公式该数字有效;否则无效。http://en.wikipedia.org/wiki/Luhn_algorithm这是我想出的:defvalidCreditCard(cardNumber)sum=0nums=cardNumber.to_s.s
下面是我写的一个计算斐波那契数列中的值的方法:deffib(n)ifn==0return0endifn==1return1endifn>=2returnfib(n-1)+(fib(n-2))endend它工作到n=14,但在那之后我收到一条消息说程序响应时间太长(我正在使用repl.it)。有人知道为什么会这样吗? 最佳答案 Naivefibonacci进行了大量的重复计算-在fib(14)fib(4)中计算了很多次。您可以将内存添加到您的算法中以使其更快:deffib(n,memo={})ifn==0||n==1returnnen
为了防止在迁移到生产站点期间出现数据库事务错误,我们遵循了https://github.com/LendingHome/zero_downtime_migrations中列出的建议。(具体由https://robots.thoughtbot.com/how-to-create-postgres-indexes-concurrently-in概述),但在特别大的表上创建索引期间,即使是索引创建的“并发”方法也会锁定表并导致该表上的任何ActiveRecord创建或更新导致各自的事务失败有PG::InFailedSqlTransaction异常。下面是我们运行Rails4.2(使用Acti
我正在开发一个类似微论坛的项目,其中一个特殊用户发布一条快速(接近推文大小)的主题消息,订阅者可以用他们自己的类似大小的消息来响应。直截了当,没有任何形式的“挖掘”或投票,只是每个主题消息的响应按时间顺序排列。但预计会有很高的流量。我们想根据它们引起的响应嗡嗡声来标记主题消息,使用0到10的等级。在谷歌上搜索了一段时间的趋势算法和开源社区应用示例,到目前为止已经收集到两个有趣的引用资料,但我还没有完全理解它们:Understandingalgorithmsformeasuringtrends,关于使用基线趋势算法比较维基百科页面浏览量的讨论,在SO上。TheBritneySpearsP
我收到错误:unsupportedcipheralgorithm(AES-256-GCM)(RuntimeError)但我似乎具备所有要求:ruby版本:$ruby--versionruby2.1.2p95OpenSSL会列出gcm:$opensslenc-help2>&1|grepgcm-aes-128-ecb-aes-128-gcm-aes-128-ofb-aes-192-ecb-aes-192-gcm-aes-192-ofb-aes-256-ecb-aes-256-gcm-aes-256-ofbRuby解释器:$irb2.1.2:001>require'openssl';puts
文章目录一.Dijkstra算法想解决的问题二.Dijkstra算法理论三.java代码实现一.Dijkstra算法想解决的问题解决的问题:求解单源最短路径,即各个节点到达源点的最短路径或权值考察其他所有节点到源点的最短路径和长度局限性:无法解决权值为负数的情况二.Dijkstra算法理论参数:S记录当前已经处理过的源点到最短节点U记录还未处理的节点dist[]记录各个节点到起始节点的最短权值path[]记录各个节点的上一级节点(用来联系该节点到起始节点的路径)Dijkstra算法步骤:(1)初始化:顶点集S:节点A到自已的最短路径长度为0。只包含源点,即S={A}顶点集U:包含除A外的其他顶