本文基于 KubeSphere 可观测性与边缘计算负责人霍秉杰在北美 KubeCon 的 Co-located event Open Observability Day 闪电演讲的内容进行整理。
整理人:米开朗基杨、大飞哥
2019 年 1 月 21 日,KubeSphere 社区为了满足以云原生的方式管理 Fluent Bit 的需求开发了 FluentBit Operator,并在 2020 年 2 月 17 日发布了 v0.1.0 版本。此后产品不断迭代,一直维护到 v0.8.0,实现了 Fluent Bit 配置的热加载,而无需重启整个 Fluent Bit 容器。2021 年 8 月,Kubesphere 团队将该项目捐献给 Fluent 社区,并从 v0.9.0 一直持续迭代到 v0.13.0。
2022 年 3 月,FluentBit Operator 正式更名为 Fluent Operator,因为我们增加了对 Fluentd 的支持,而且把 FluentBit CRDs 定义范围从命名空间扩大到集群级别,并于 2022 年 3 月 25 日发布了里程碑版本 v1.0.0。
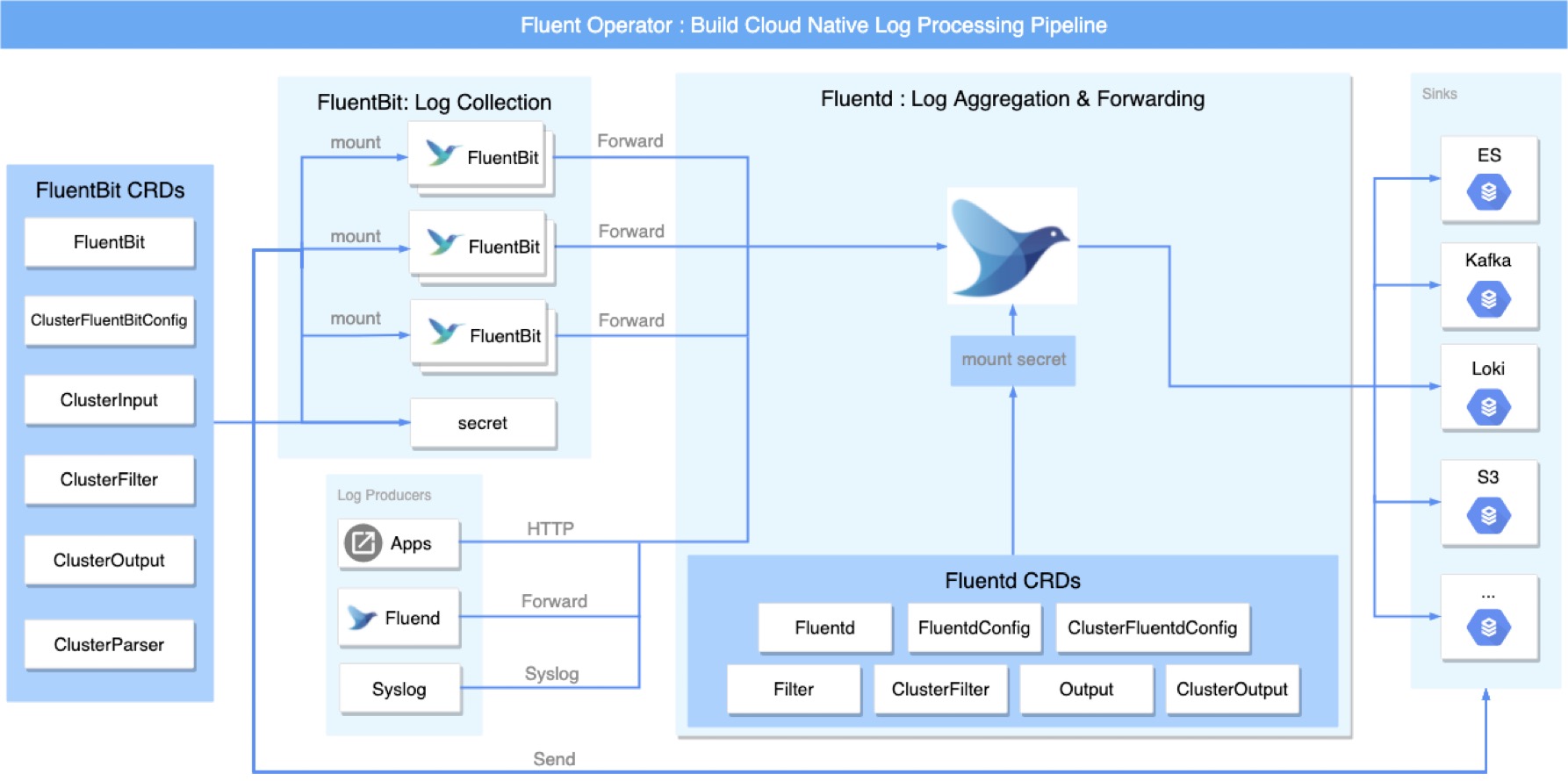
Fluent Operator 可以构建完整的云原生日志采集通道。FluentBit 小巧轻量,适合作为 Agent 收集日志;Fluentd 插件丰富功能强大,适合对日志进行集中处理,二者可以独立使用,也可以协作共存,使用方案非常灵活。
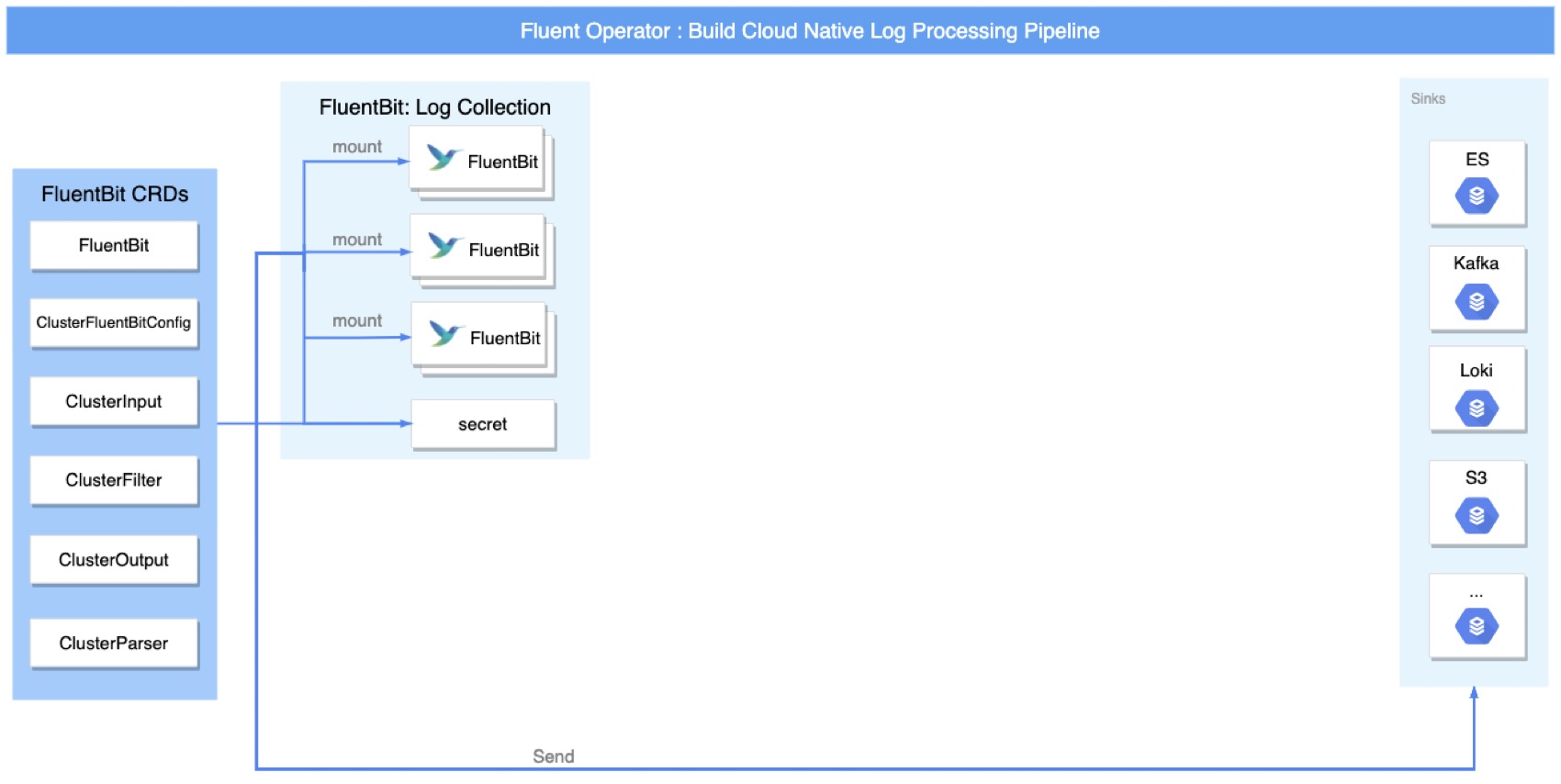
Fluent Operator 可以非常便捷地部署 FluentBit Daemonset 服务,运行于各计算节点。当然集群层级的 FluentBit CRD 也可以配置各种 Input,Filter,Parser,Output 等。Fluent Bit 支持将日志直接导出到 ElasticSearch,Kafka,Loki,S3 等众多目标服务,这些只需配置 CRD 即可。
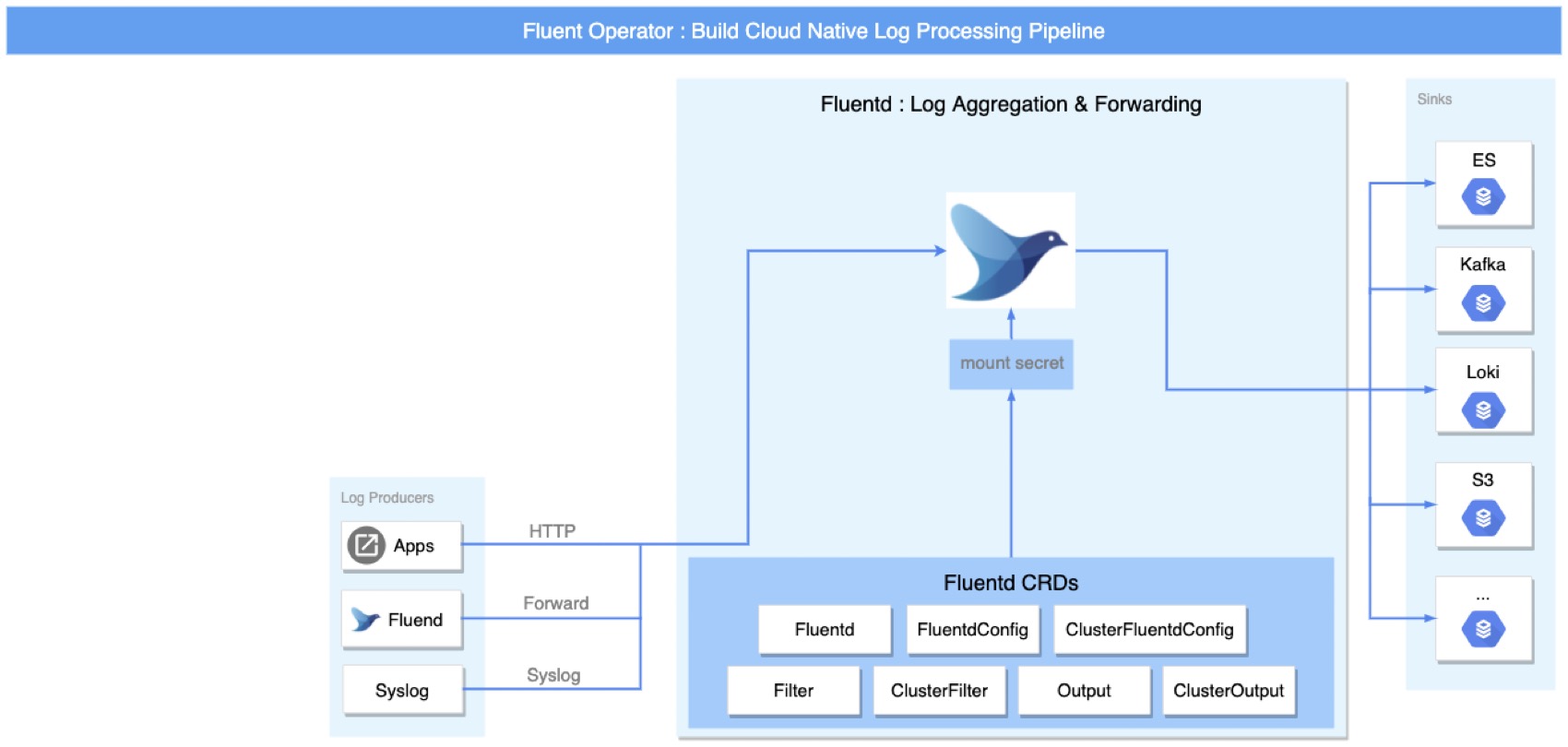
Fluent Operator 可以非常便捷地将 Fluentd 部署为 Statefulset 服务,应用可以通过 HTTP,Syslog 等方式发送日志,同时 Fluentd 还支持级联模式,即 Fluentd 可以接收来自另一个 Fluentd 服务的日志。类比于 Fluent Bit,Fluentd 也支持集群级别的 CRD 配置,可以方便的配置 Input,Filter,Parser,Output 等。Fluentd 内置支持上百种插件,输入输出都非常丰富。
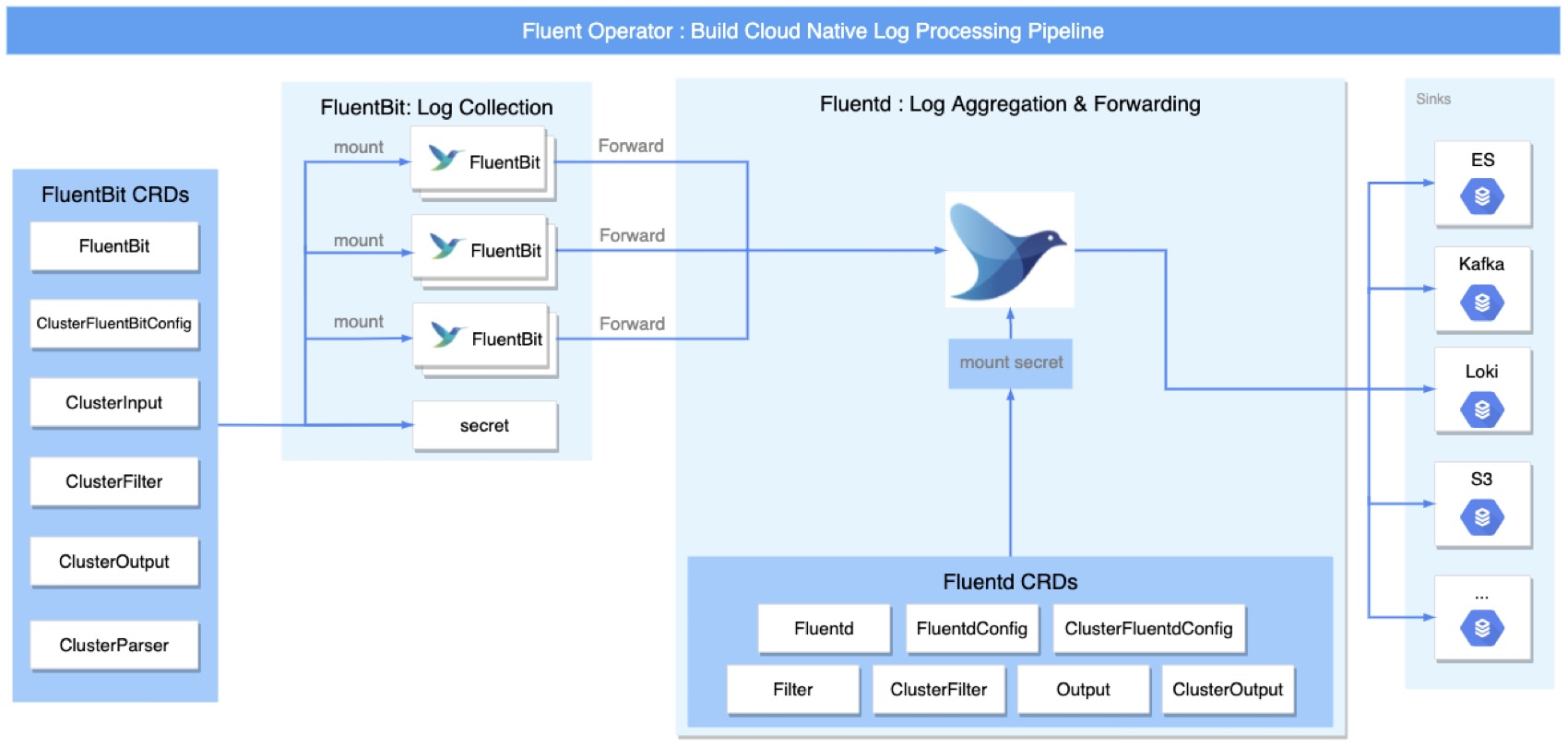
Fluentd 和 Fluent Bit 在设计架构上极为相似,都有着丰富的社区插件支持,但二者侧重的使用场景有所差异。Fluent Bit 小巧精致,资源消耗少,更适合作为 Agent 来采集日志,而 Fluentd 相对前者功能更加丰富,作为数据中转站或数据治理服务更为贴切。所以绝大多数场景中,二者配合可以构建出灵活高效且扩展性极强的日志收集流水线。
至 Fluent Operator 发布 v1.0.0 至今,仍然在高速迭代。v1.1.0 版本新增了对 OpenSearch 输出的支持;v1.5.0 新增了对 Loki 输出的支持,同时还增加了对监控指标(Metrics)采集的支持,支持清单如下:
正是基于对监控指标采集的支持,Fluent Operator 才可以完美构建云边统一的可观测性。
以上内容关注的是对云端资源的数据采集,下面我们来看看 Fluent Operator 在边缘计算场景下的支持情况。
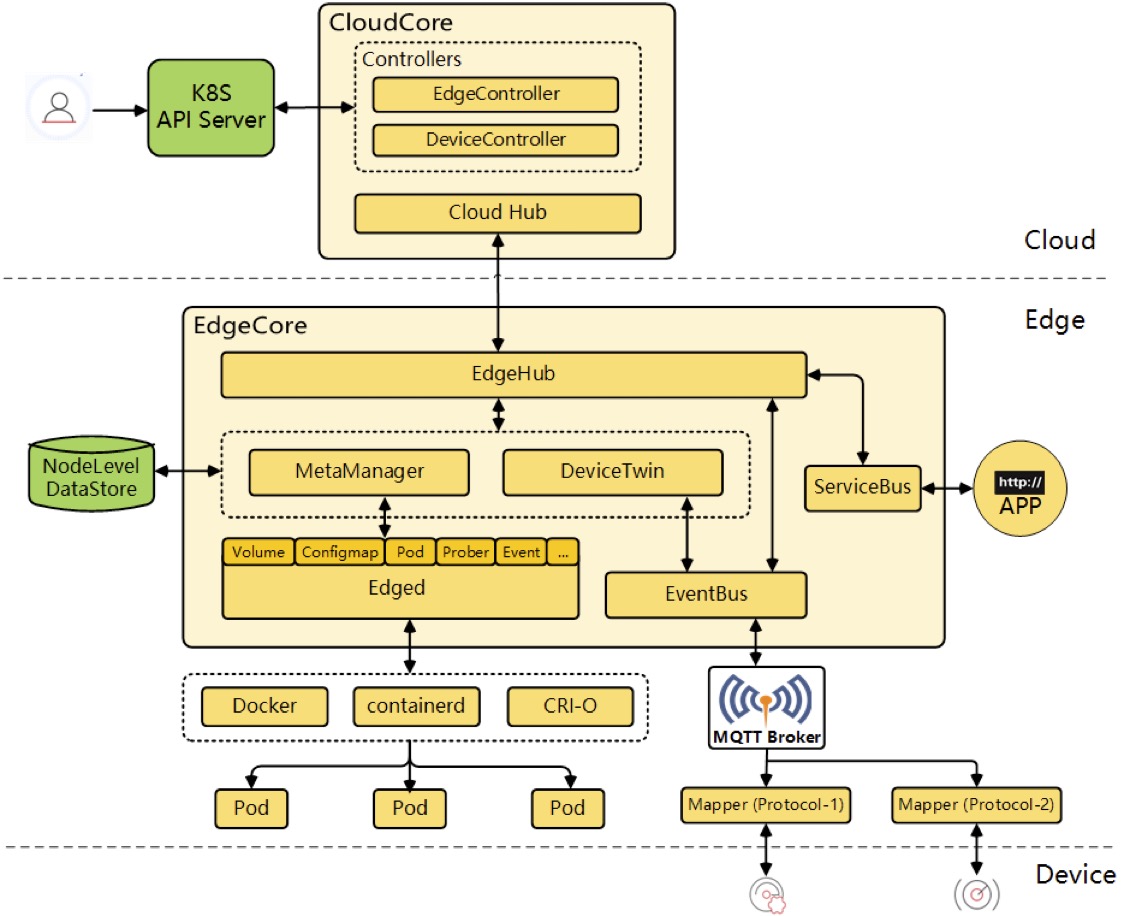
我们使用的边缘计算框架是 KubeEdge,下面我给大家介绍下 KubeEdge 这个项目。
KubeEdge 是 CNCF 孵化的面向边缘计算场景、专为边云协同设计的云原生边缘计算框架,除了 KubeEdge 之外还有很多其他的边缘计算框架,比如 K3s。K3s 会在边缘端创建完整的 K8s 集群,而 KubeEdge 只是在边缘端创建几个边缘节点(Edge Node),边缘节点通过加密隧道连接到云端的 K8s 集群,这是 KubeEdge 与 K3s 比较明显的差异。
KubeEdge 的边缘节点会运行一个与 Kubelet 类似的组件叫 Edged,比 Kubelet 更轻量化,用来管理边缘节点的容器。Edged 也会暴露 Prometheus 格式的监控指标,而且暴露方式和 Kubelet 保持一致,都是这种格式:127.0.0.1:10350/metrics/cadvisor。
下面着重讲解如何使用 Fluent Bit 来实现云边统一的可观测性。
直接来看架构图,云端部署了一个 K8s 集群,边缘端运行了一系列边缘节点。云端通过 Prometheus Agent 从 Node Exporter、Kubelet 和 kube-state-metrics 等组件中收集监控指标,同时还部署了一个 Fluent Operator 用来同时管理和部署云端和边缘端的 Fluent Bit Daemonset 实例。
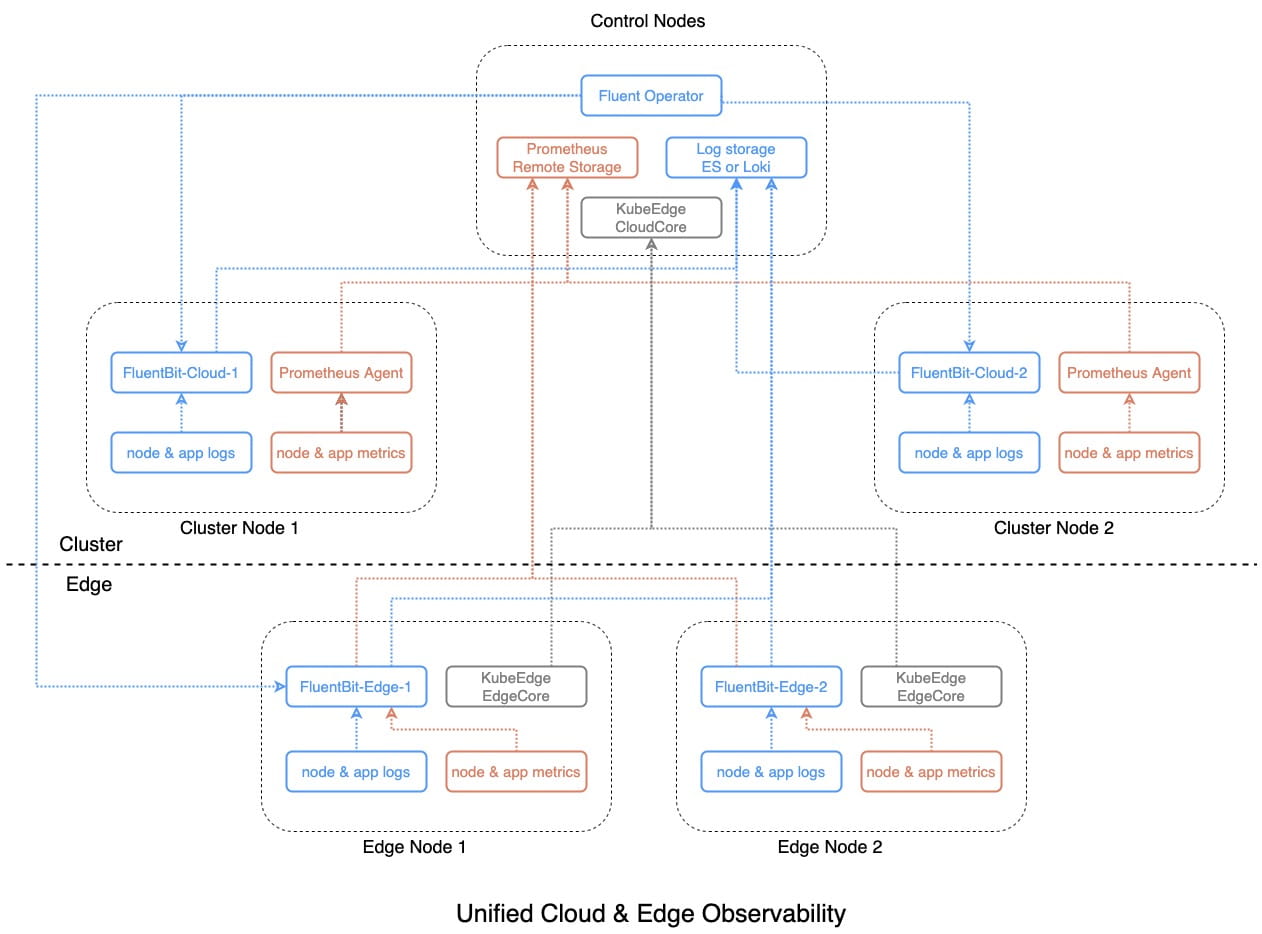
对于边缘节点来说,情况就不那么乐观了,因为边缘节点资源有限,无法部署以上这些组件来收集可观测性数据。因此我们对边缘端的监控指标收集方案进行了改良,将 Prometheus (Agent) 替换为 Fluent Bit,并移除了 Node Expoter,使用更轻量的 Fluent Bit Node Exporter Metrics 插件来替代,同时使用 Fluent Bit Prometheus Scrape Metrics 插件来收集边缘端 Edged 和工作负载的监控指标。
这个架构的优点是只需要在边缘端部署一个组件 Fluent Bit,而且可以同时收集边缘节点和边缘应用的日志和监控指标,对于资源紧张的边缘节点来说,这是一个非常完美的方案。
最后给大家演示下如何在边缘端部署 Fluent Bit,并使用它来收集边缘节点的监控指标和日志数据。Fluent Bit 的部署方式通过自定义资源(CR)FluentBit 来声明,内容如下:
apiVersion: fluentbit.fluent.io/v1alpha2
kind: FluentBit
metadata:
name: fluentbit-edge
namespace: fluent
labels:
app.kubernetes.io/name: fluent-bit
spec:
image: kubesphere/fluent-bit:v1.9.9
positionDB:
hostPath:
path: /var/lib/fluent-bit/
resources:
requests:
cpu: 10m
memory: 25Mi
limits:
cpu: 500m
memory: 200Mi
fluentBitConfigName: fluent-bit-config-edge
tolerations:
- operator: Exists
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-role.kubernetes.io/edge
operator: Exists
hostNetwork : true
volumes:
- name: host-proc
hostPath:
path: /proc/
- name: host-sys
hostPath:
path: /sys/
volumesMounts:
- mountPath: /host/sys
mountPropagation: HostToContainer
name: host-sys
readOnly: true
- mountPath: /host/proc
mountPropagation: HostToContainer
name: host-proc
readOnly: true
我们通过 Node Affinity 将 Fluent Bit 指定部署到边缘节点。为了能够替代 Node Exporter 组件的功能,还需要将 Node Exporter 用到的主机路径映射到容器中。
接下来需要通过自定义资源 ClusterInput 创建一个 Fluent Bit Prometheus Scrape Metrics 插件来收集边缘端工作负载的监控指标:
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterInput
metadata:
name: prometheus-scrape-metrics-edge
labels:
fluentbit.fluent.io/enabled: "true"
node-role.kubernetes.io/edge: "true"
spec:
prometheusScrapeMetrics:
tag: kubeedge.*
host: 127.0.0.1
port: 10350
scrapeInterval: 30s
metricsPath : /metrics/cadvisor
并通过自定义资源 ClusterInput 再创建一个 Fluent Bit Node Exporter Metrics 插件来收集边缘节点的监控指标(替代 Node Exporter):
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterInput
metadata:
name: node-exporter-metrics-edge
labels:
fluentbit.fluent.io/enabled: "true"
node-role.kubernetes.io/edge: "true"
spec:
nodeExporterMetrics:
tag: kubeedge.*
scrapeInterval: 30s
path :
procfs: /host/proc
sysfs : /host/sys
最后还需要通过自定义资源 ClusterOutput 创建一个 Fluent Bit Prometheus Remote Write 插件,用来将边缘端收集到的监控指标写入到 K8s 集群的 Prometheus 长期存储中。
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterOutput
metadata:
name: prometheus-remote-write-edge
labels:
fluentbit.fluent.io/enabled: "true"
node-role.kubernetes.io/edge: "true"
spec:
matchRegex: (?:kubeedge|service)\.(.*)
prometheusRemoteWrite:
host: <cloud-prometheus-service-host>
port: <cloud-prometheus-service-port>
uri: /api/v1/write
addLabels :
app : fluentbit
node: ${NODE_NAME}
job : kubeedge
基于上述步骤,最终我们通过 Fluent Bit 实现了云边统一的可观测性。
虽然 Fluent Bit 的初衷是收集日志,但最近也开始支持收集 Metrics 和 Tracing 数据,这一点很令人兴奋,这样就可以使用一个组件来同时收集所有的可观测性数据(Log、Metrics、Tracing)了。如今 Fluent Operator 也支持了这些功能,并通过自定义资源提供了简单直观的使用方式,想要使用哪些插件直接通过自定义资源声明即可,一目了然。
当然,Fluent Operator 这个项目还很年轻,也有很多需要改进的地方,欢迎大家参与到该项目中来,为其添砖加瓦。
本文由博客一文多发平台 OpenWrite 发布!
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po