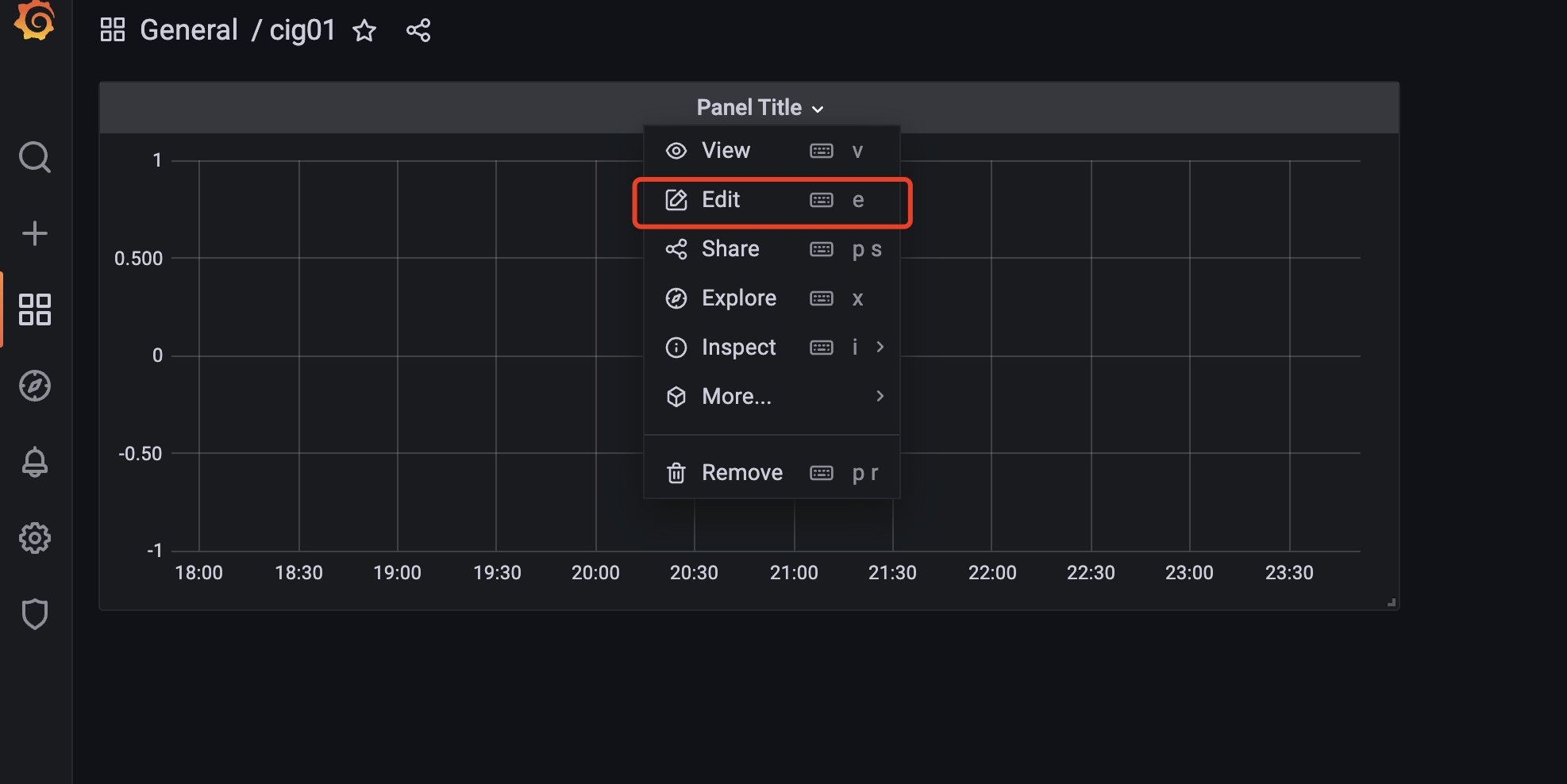
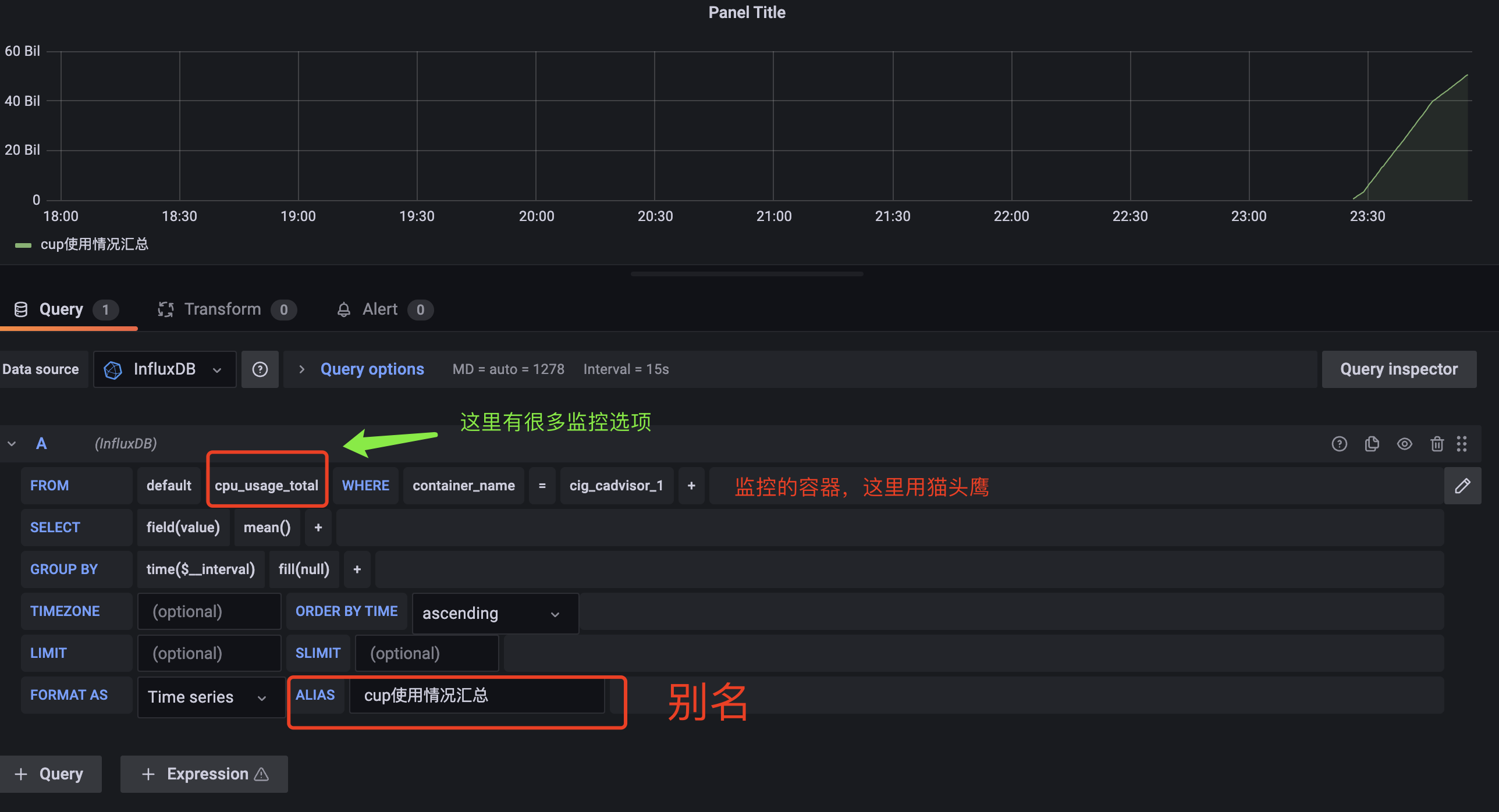
文章目录
docker stats
docker stats命令的结果
通过docker stats命令可以很方便的看到当前宿主机上所有容器的CPU,内存以及网络流量等数据,一般小公司够用。
- 但是,docker stats统计结果只能是当前宿主机的全部容器,数据资料是实时的,没有地方存储、没有健康指标过线预警等功能

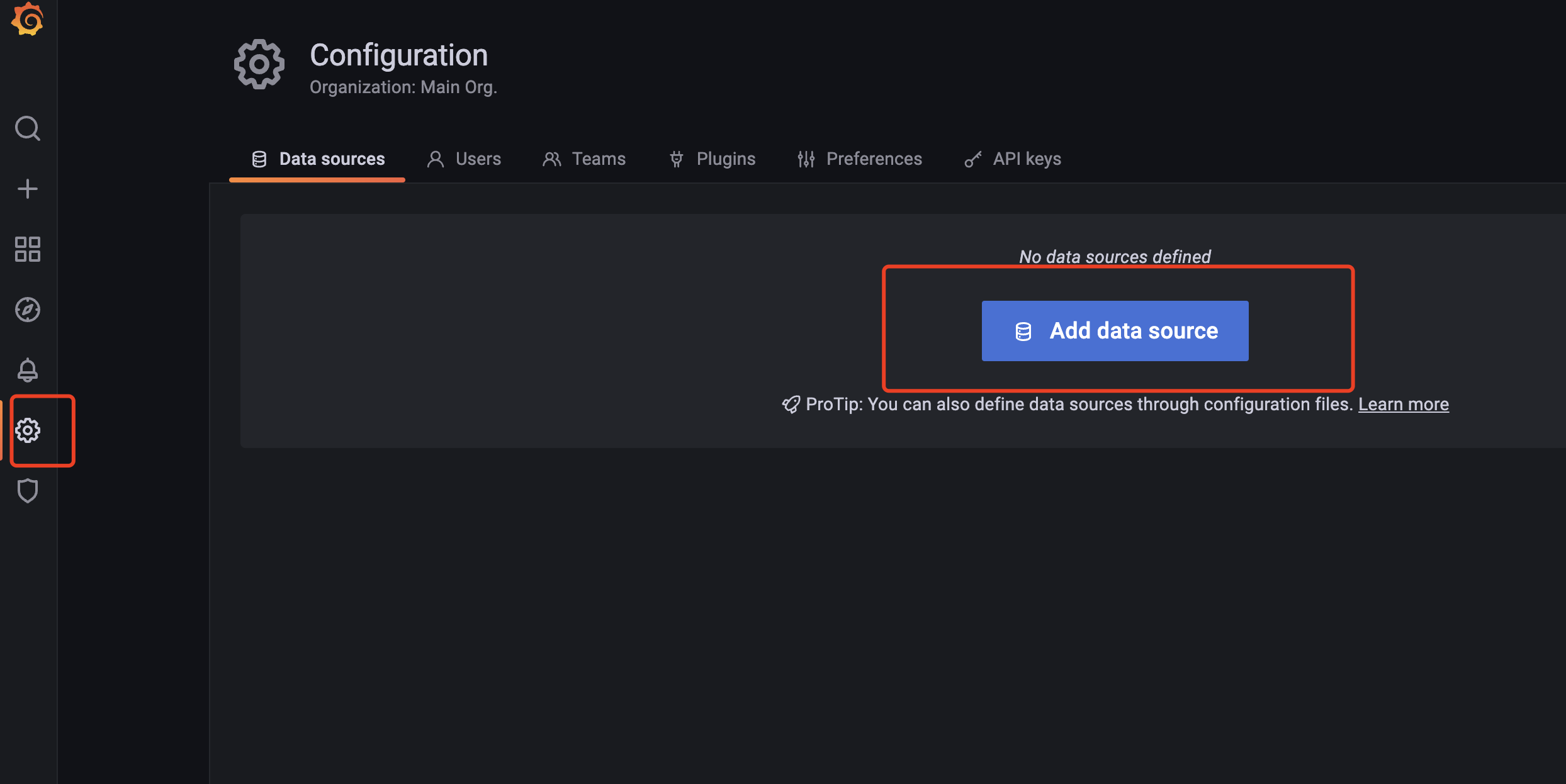
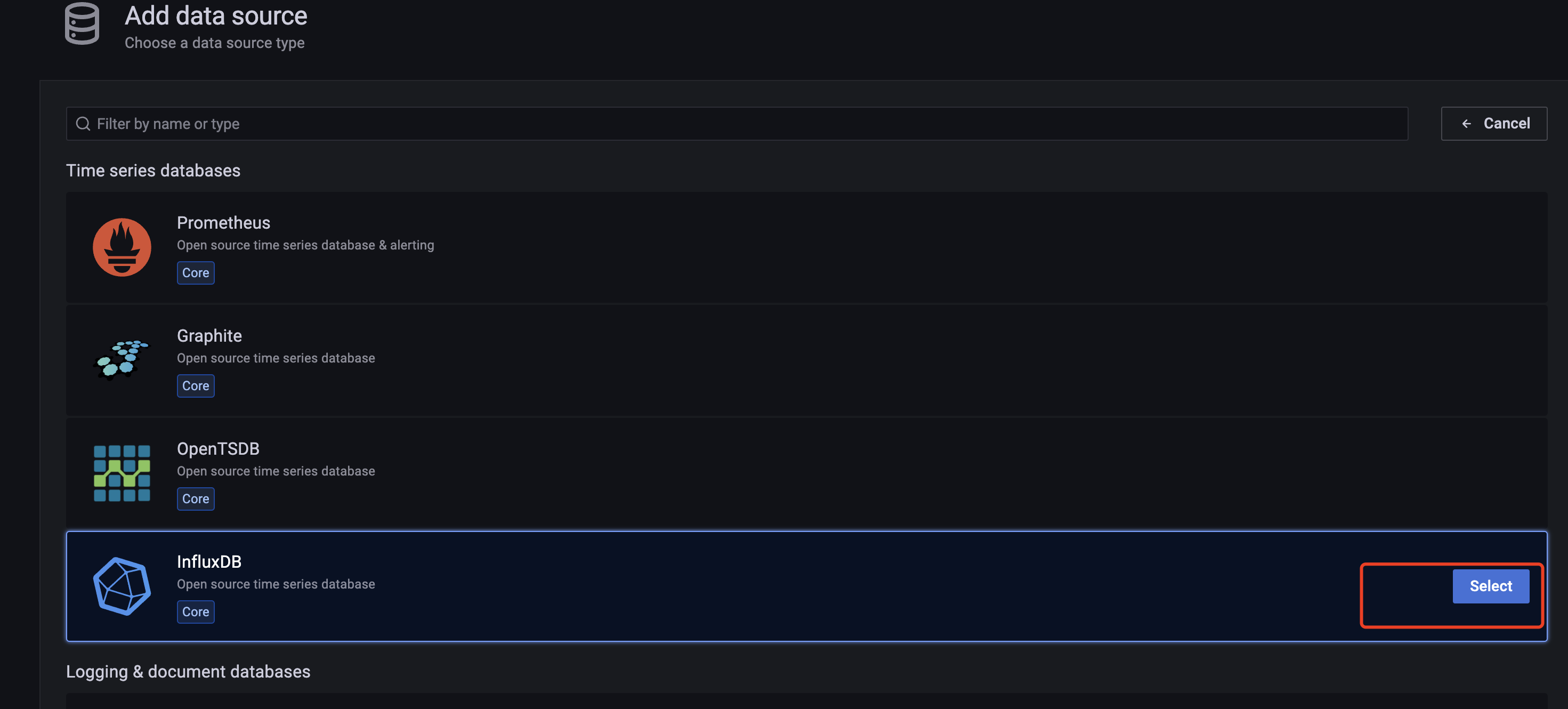
CAdvisor监控收集+InfluxDB存储数据+Granfana展示图表

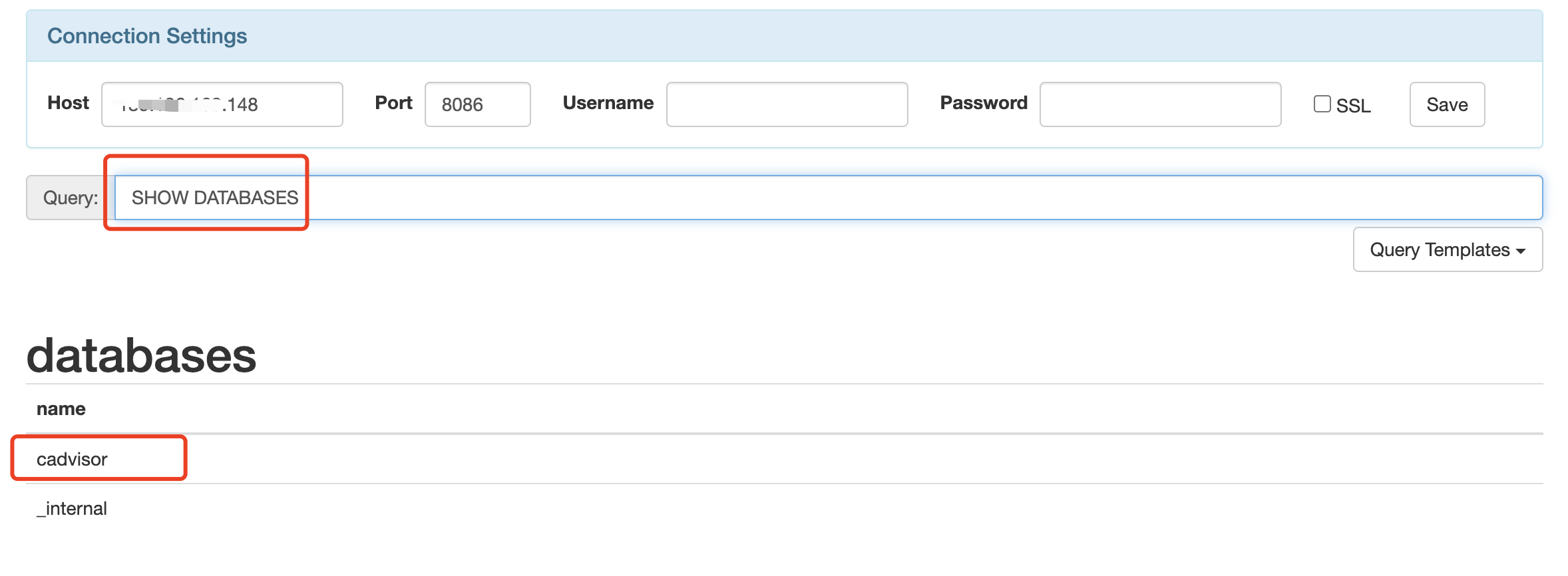
CAdvisor是一个容器资源监控工具包括容器的内存,CPU,网络IO,磁盘IO等监控,同时提供了一个WEB页面用于查看容器的实时运行状态。CAdvisor默认存储2分钟的数据,而且只是针对单物理机。不过,CAdvisor提供了很多数据集成接口,支持InfluxDB,Redis,Kafka,Elasticsearch等集成,可以加上对应配置将监控数据发往这些数据库存储起来。
lnfluxDB是用Go语言编写的一个开源分布式时序、事件和指标数据库,无需外部依赖。
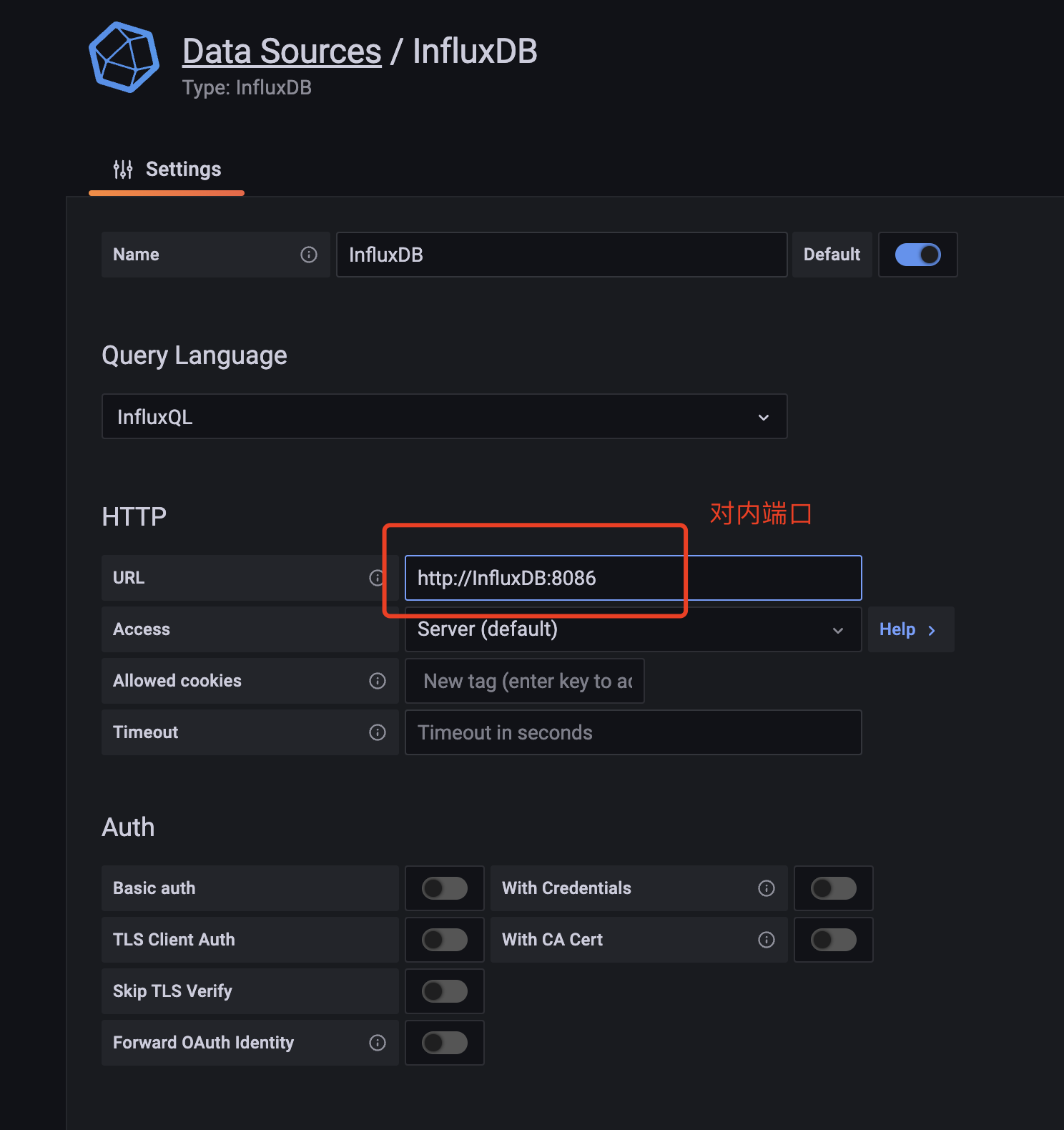
- CAdvisor默认只在本机保存最近2分钟的数据,为了持久化存储数据和统一收集展示监控数据,需要将数据存储到InfluxDB中。InfluxDB是一个时序数据库专门用于存储时序相关数据,很适合存储CAdvisor的教据。而且,CAdvisor本身已经提供了InfluxDB的集成方法,丰启动容器时指定配置即可。
Grafana是一个开源的数据监控分析可视化平台,支持多种数据源配置(支持的数据源包括InfluxDB,MySQLElasticsearch,OpenTSDB,Graphite等)和丰富的插件及模板功能,支持图表权限控制和报警。

version: '3.1'
volumes:
grafana_data: {}
services:
influxdb:
image: tutum/influxdb:0.9
restart: always
environment:
- PRE_CREATE_DB=cadvisor
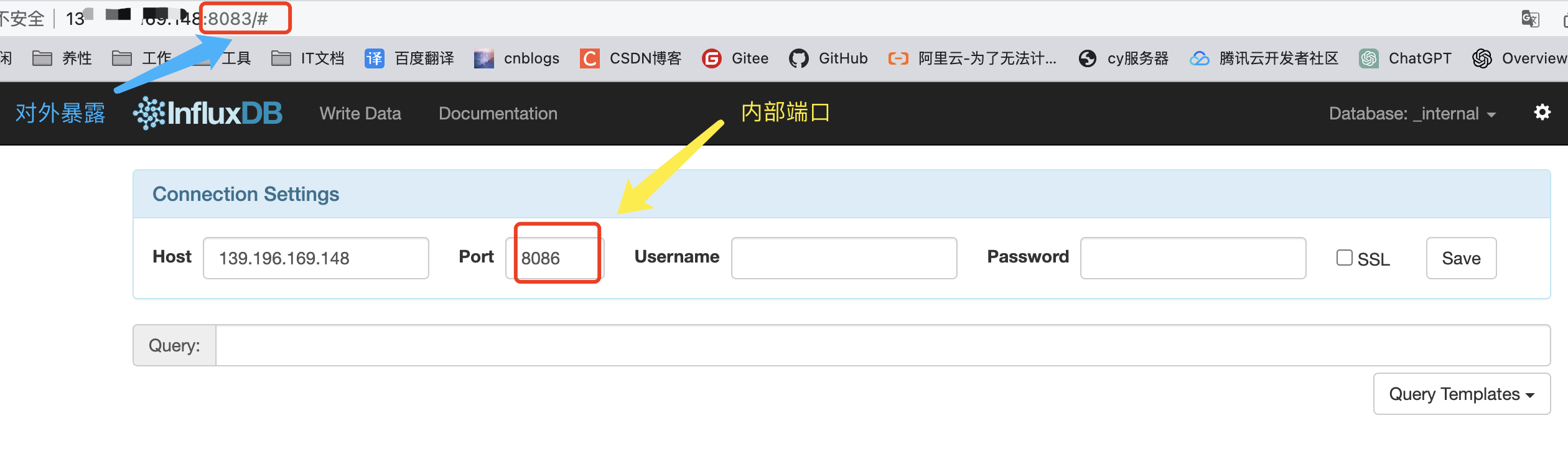
ports:
- "8083:8083"
- "8086:8086"
volumes:
- ./data/influxdb:/data
cadvisor:
image: google/cadvisor
links:
- influxdb:influxsrv
command: -storage_driver=influxdb -storage_driver_db=cadvisor -storage_driver_host=influxsrv:8086
restart: always
ports:
- "8080:8080"
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
grafana:
user: "104"
image: grafana/grafana
user: "104"
restart: always
links:
- influxdb:influxsrv
ports:
- "3000:3000"
volumes:
- grafana_data:/var/lib/grafana
environment:
- HTTP_USER=admin
- HTTP_PASS=admin
- INFLUXDB_HOST=influxsrv
- INFLUXDB_PORT=8086
- INFLUXDB_NAME=cadvisor
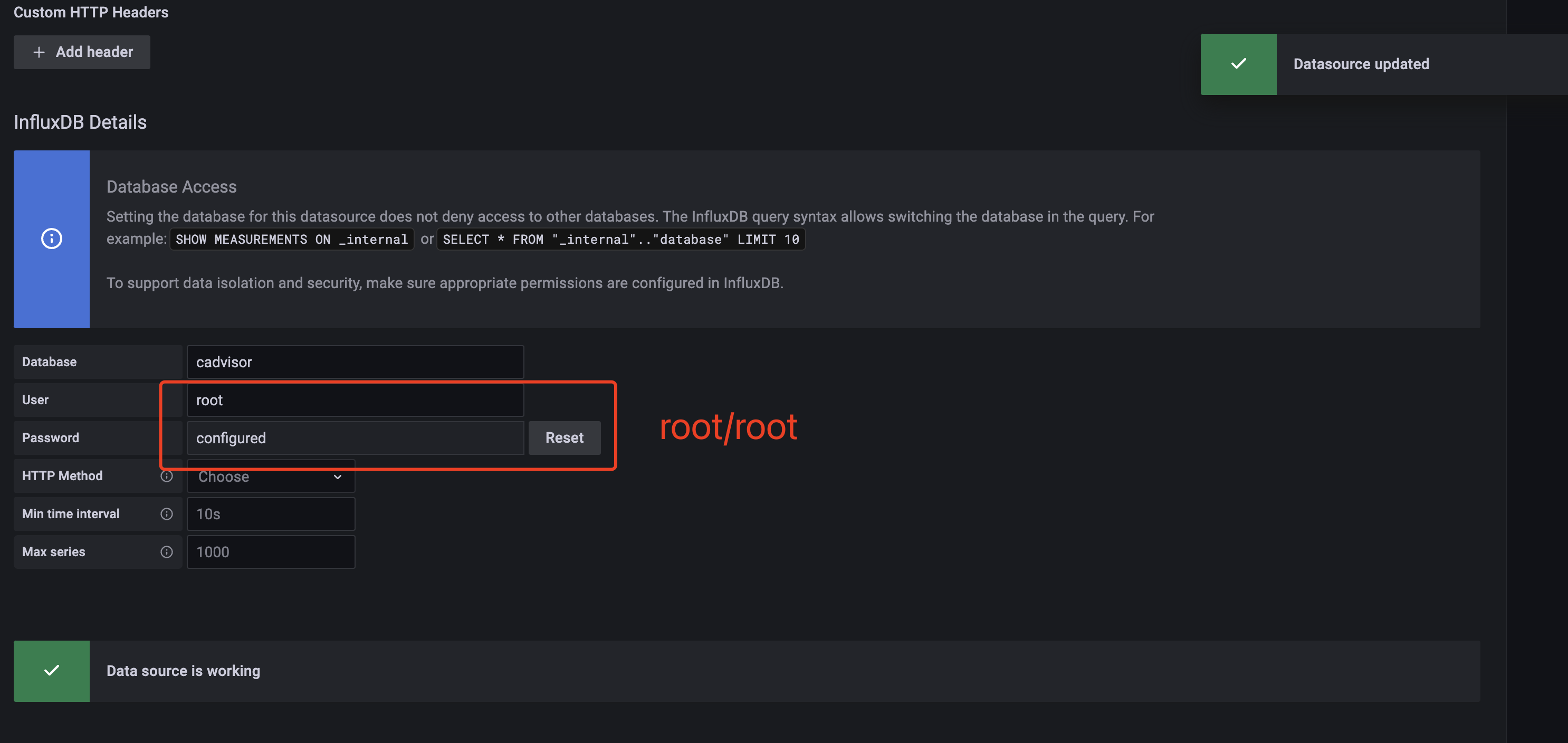
- INFLUXDB_USER=root
- INFLUXDB_PASS=root
docker-compose config -q
docker-compose up -d
docker-compose up -d

第一次访问慢,请稍等
cadvisor也有基础的图形展现功能,这里主要用它来作数据采集
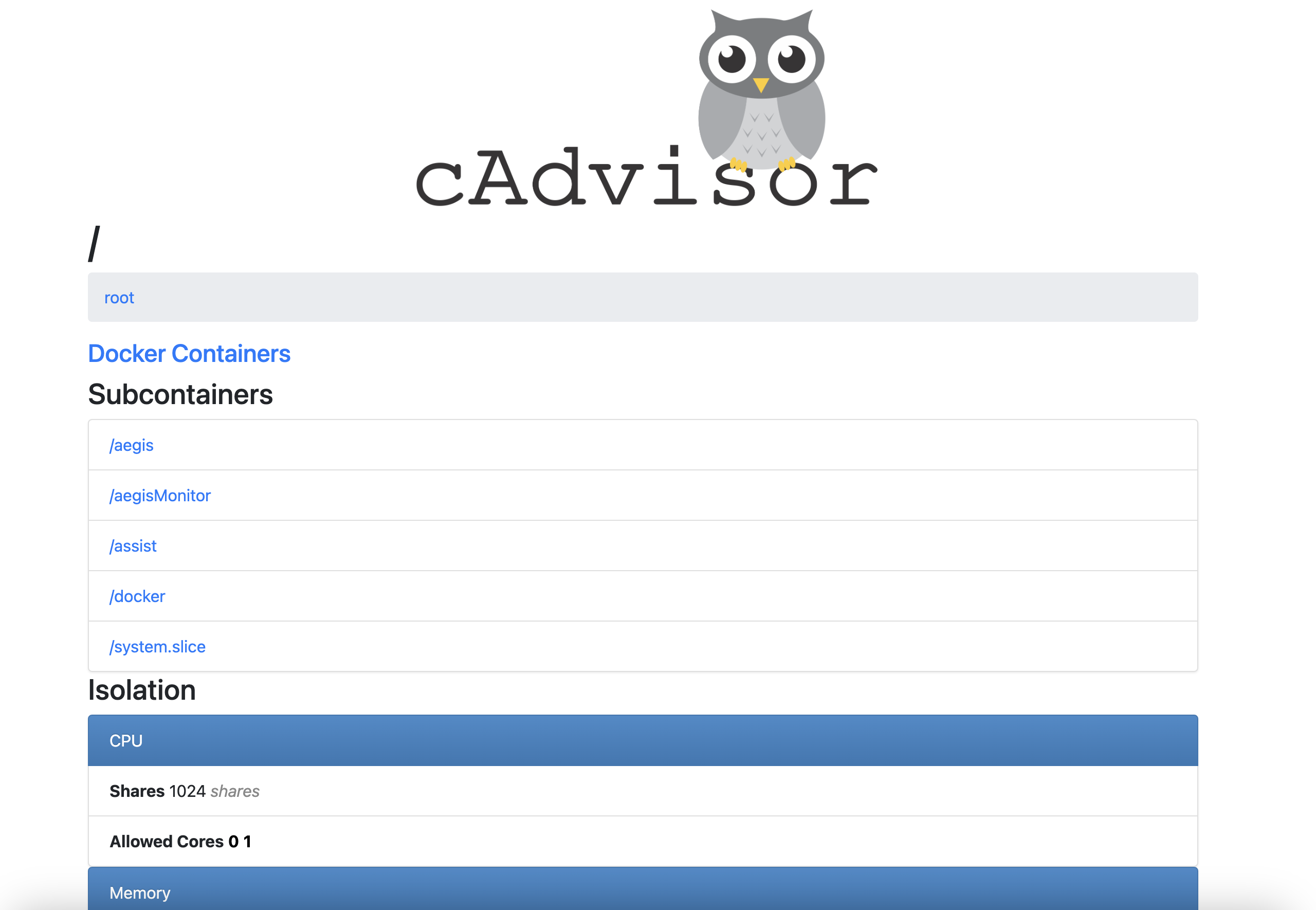
默认帐户密码(admin/admin)
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
我正在尝试使用docker运行一个Rails应用程序。通过github的sshurl安装的gem很少,如下所示:Gemfilegem'swagger-docs',:git=>'git@github.com:xyz/swagger-docs.git',:branch=>'my_branch'我在docker中添加了keys,它能够克隆所需的repo并从git安装gem。DockerfileRUNmkdir-p/root/.sshCOPY./id_rsa/root/.ssh/id_rsaRUNchmod700/root/.ssh/id_rsaRUNssh-keygen-f/root/.ss
我在Heroku上构建了一个必须在Docker容器内运行的RoR应用程序。为此,我使用officialDockerfile.因为它在Heroku中很常见,所以我需要一些附加组件才能使这个应用程序完全运行。在生产中,变量DATABASE_URL在我的应用程序中可用。但是,如果我尝试其他一些使用环境变量(在我的例子中是Mailtrap)的加载项,变量不会在运行时复制到实例中。所以我的问题很简单:如何让docker实例在Heroku上执行时知道环境变量?您可能会问,我已经知道我们可以在docker-compose.yml中指定一个environment指令。我想避免这种情况,以便能够通过项目
我在开发和生产中都使用docker,真正困扰我的一件事是docker缓存的简单性。我的ruby应用程序需要bundleinstall来安装依赖项,因此我从以下Dockerfile开始:添加GemfileGemfile添加Gemfile.lockGemfile.lock运行bundleinstall--path/root/bundle所有依赖项都被缓存,并且在我添加新gem之前效果很好。即使我添加的gem只有0.5MB,从头开始安装所有应用程序gem仍然需要10-15分钟。由于依赖项文件夹的大小(大约300MB),然后再花10分钟来部署它。我在node_modules和npm上遇到了
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
测试环境对于任何一个软件公司来讲,都是核心基础组件之一。转转的测试环境伴随着转转的发展也从单一的几套环境发展成现在的任意的docker动态环境+docker稳定环境环境体系。期间环境系统不断的演进,去适应转转集群扩张、新业务的扩展,走了一些弯路,但最终我们将系统升级到了我们认为的终极方案。下面我们介绍一下转转环境的演进和最终的解决方案。1测试环境演进1.1单体环境 转转在2017年成立之初,5台64G内存的机器,搭建5个完整的测试环境。就满足了转转的日常所需。一台分给开发,几台分给测试。通过沟通协调就能解决多分支并行开发下冲突问题。1.2动态环境+稳定环境 随着微服务化的进
是否可以在我的服务器上运行任何工具来监控多个Rails应用程序?我需要监控每个应用程序收到的请求数、每个应用程序使用了多少内存、使用了多少CPU以及其他类似的统计信息。我需要查看每个单独的Rails应用程序的统计信息。 最佳答案 我建议你试试NewRelicRPM.免费版:RPMLiteisthemostwidelyusedsolutionforbasicwebapplicationmonitoring.RPMLiteprovidesapplicationmonitoringforunlimitedJava,RubyorJRubya
我正在寻找一种方法来监视流上的事件,以便我可以确定是否有任何内容通过流。如果有,我将开始使用rtmpdump进行录制。我想象这是通过运行一个每60秒检查一次流的cron任务来实现的。如果它确定流正在通过,则调用rtmpdump开始记录它。如果没有,则什么都不做,并在60秒后再次检查。由于rtmpdump只是在没有流数据时出现错误,因此尝试使用它来监视流似乎不是一个好主意,但也许我错了。如果我在逐个案例的基础上手动执行此操作会很容易,但我正在尝试自动执行自动录制流的任务(如果它们可用)。有没有人遇到过这样做的方法?也许我可以在命令行(linux)中使用其他一些工具?如果有帮助,我正在使用
每5分钟(例如)ping20个网站的列表以了解该网站是否响应HTTP202的最佳方法是什么?最简单的想法是将20个URLS保存在数据库中,然后运行数据库并对每个URL执行ping操作。但是,当一个人不回答时会发生什么?之后的人会怎样?此外,是否有更好但更简单的解决方案?恐怕该列表会增长到20000个网站,然后没有足够的时间在我需要ping的5分钟内全部ping通它们。基本上,我是在描述PingDom、UptimeRobot等的工作原理。我正在使用node.js和RubyonRails构建这个系统。我也倾向于使用MongoDB来保存所有ping和监控结果的历史记录。建议?非常感谢!