最近跟导师做的项目是关于BP,LSTN神经网络的,数据集对象是一些Excel表格类型的,我使用pytorch进行训练,读取Excel表格数据的时候统一进行一些处理,所以我想把它封装到函数,以后处理其它数据集,直接调用函数实现,这不就方便了吗。
我将以鸢尾花数据集作为例子进行展示:
我已经编写了2.0版本,方法更加集成化,建议使用2.0版本:2.0
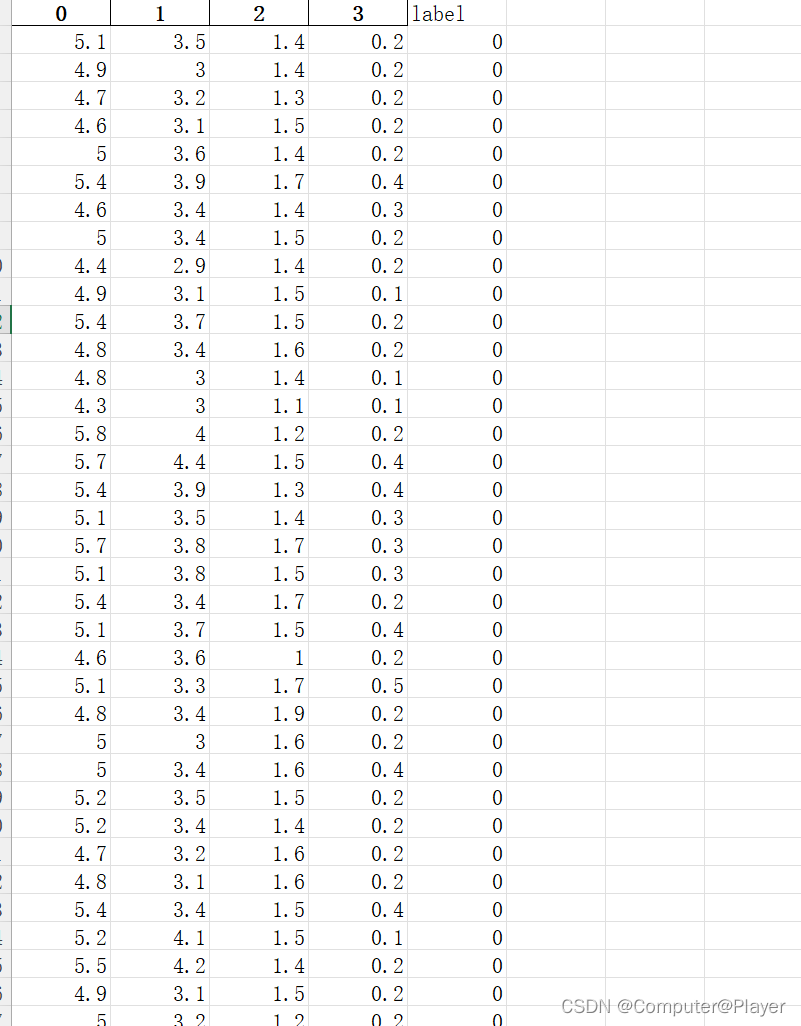
可以看到鸢尾花数据集有四个特征,分别是0,1,2,3,label是鸢尾花种类,共三种,分别以0,1,2表示。
首先第一部分是读取Excel数据(需要主要的是标签需要在最后一列,函数默认最后一列为标签,前边的为特征值):
def open_excel(filename):
"""
打开数据集,进行数据处理
:param filename:文件名
:return:特征集数据、标签集数据
"""
readbook = pd.read_excel(f'{filename}.xlsx', engine='openpyxl')
nplist = readbook.T.to_numpy()
data = nplist[0:-1].T
data = np.float64(data)
target = nplist[-1]
return data, target
def open_csv(filename):
"""
打开数据集,进行数据处理
:param filename:文件名
:return:特征集数据、标签集数据
"""
readbook = pd.read_csv(f'{filename}.csv')
nplist = readbook.T.to_numpy()
data = nplist[0:-1].T
data = np.float64(data)
target = nplist[-1]
return data, target
使用方法为feature, label = open_excel('iris'),输入为Excel名字,返回值为numpy类型的特征值和标签。
第二个函数是将数据划分为训练集和测试集:
def random_number(data_size, key):
"""
使用shuffle()打乱
"""
number_set = []
for i in range(data_size):
number_set.append(i)
if key == 1:
random.shuffle(number_set)
return number_set
def split_data_set(data_set, target_set, rate, ifsuf):
"""
说明:分割数据集,默认数据集的rate是测试集
:param data_set: 数据集
:param target_set: 标签集
:param rate: 测试集所占的比率
:return: 返回训练集数据、测试集数据、训练集标签、测试集标签
"""
# 计算训练集的数据个数
train_size = int((1 - rate) * len(data_set))
# 随机获得数据的下标
data_index = random_number(len(data_set), ifsuf)
# 分割数据集(X表示数据,y表示标签),以返回的index为下标
# 训练集数据
x_train = data_set[data_index[:train_size]]
# 测试集数据
x_test = data_set[data_index[train_size:]]
# 训练集标签
y_train = target_set[data_index[:train_size]]
# 测试集标签
y_test = target_set[data_index[train_size:]]
return x_train, x_test, y_train, y_test
使用方法很简单,输入为特征值,标签,划分比例,是否打乱,返回值为训练集,测试集的特征值和标签。
# 数据划分为训练集和测试集和是否打乱数据集
split = 0.3 # 测试集占数据集整体的多少
ifshuffle = 1 # 1为打乱数据集,0为不打乱
x_train, x_test, y_train, y_test = split_data_set(feature, label, split, ifshuffle)
第三个函数为numpy转为tensor:
def inputtotensor(inputtensor, labeltensor):
"""
将数据集的输入和标签转为tensor格式
:param inputtensor: 数据集输入
:param labeltensor: 数据集标签
:return: 输入tensor,标签tensor
"""
inputtensor = np.array(inputtensor)
inputtensor = torch.FloatTensor(inputtensor)
labeltensor = np.array(labeltensor)
labeltensor = labeltensor.astype(float)
labeltensor = torch.LongTensor(labeltensor)
return inputtensor, labeltensor
输入为numpy的特征值和标签,返回值为tensor格式的特征值和标签。
# 将数据转为tensor格式
traininput, trainlabel = inputtotensor(x_train, y_train)
testinput, testlabel = inputtotensor(x_test, y_test)
第四部分是归一化处理,使用的是torch中的nn
# 归一化处理
traininput = nn.functional.normalize(traininput)
testinput = nn.functional.normalize(testinput)
你只需要调用函数就可以实现,可以说非常方便。
下面我用以上函数实现后实现一下BP神经网络:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import random
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
def open_excel(filename):
"""
打开数据集,进行数据处理
:param filename:文件名
:return:特征集数据、标签集数据
"""
readbook = pd.read_excel(f'{filename}.xlsx', engine='openpyxl')
nplist = readbook.T.to_numpy()
data = nplist[0:-1].T
data = np.float64(data)
target = nplist[-1]
return data, target
def open_csv(filename):
"""
打开数据集,进行数据处理
:param filename:文件名
:return:特征集数据、标签集数据
"""
readbook = pd.read_csv(f'{filename}.csv')
nplist = readbook.T.to_numpy()
data = nplist[0:-1].T
data = np.float64(data)
target = nplist[-1]
return data, target
def random_number(data_size, key):
"""
使用shuffle()打乱
"""
number_set = []
for i in range(data_size):
number_set.append(i)
if key == 1:
random.shuffle(number_set)
return number_set
def split_data_set(data_set, target_set, rate, ifsuf):
"""
说明:分割数据集,默认数据集的rate是测试集
:param data_set: 数据集
:param target_set: 标签集
:param rate: 测试集所占的比率
:return: 返回训练集数据、测试集数据、训练集标签、测试集标签
"""
# 计算训练集的数据个数
train_size = int((1 - rate) * len(data_set))
# 随机获得数据的下标
data_index = random_number(len(data_set), ifsuf)
# 分割数据集(X表示数据,y表示标签),以返回的index为下标
# 训练集数据
x_train = data_set[data_index[:train_size]]
# 测试集数据
x_test = data_set[data_index[train_size:]]
# 训练集标签
y_train = target_set[data_index[:train_size]]
# 测试集标签
y_test = target_set[data_index[train_size:]]
return x_train, x_test, y_train, y_test
def inputtotensor(inputtensor, labeltensor):
"""
将数据集的输入和标签转为tensor格式
:param inputtensor: 数据集输入
:param labeltensor: 数据集标签
:return: 输入tensor,标签tensor
"""
inputtensor = np.array(inputtensor)
inputtensor = torch.FloatTensor(inputtensor)
labeltensor = np.array(labeltensor)
labeltensor = labeltensor.astype(float)
labeltensor = torch.LongTensor(labeltensor)
return inputtensor, labeltensor
# 定义BP神经网络
class BPNerualNetwork(torch.nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, output_size),
nn.LogSoftmax(dim=1)
)
def forward(self, x):
x = self.model(x)
return x
def addbatch(data_train, data_test, batchsize):
"""
设置batch
:param data_train: 输入
:param data_test: 标签
:param batchsize: 一个batch大小
:return: 设置好batch的数据集
"""
data = TensorDataset(data_train, data_test)
data_loader = DataLoader(data, batch_size=batchsize, shuffle=False)
return data_loader
def train_test(traininput, trainlabel, testinput, testlabel, batchsize):
"""
函数输入为:训练输入,训练标签,测试输入,测试标签,一个batch大小
进行BP的训练,每训练一次就算一次准确率,同时记录loss
:return:训练次数list,训练loss,测试loss,准确率
"""
# 设置batch
traindata = addbatch(traininput, trainlabel, batchsize) # shuffle打乱数据集
for epoch in range(1001):
for step, data in enumerate(traindata):
net.train()
inputs, labels = data
# 前向传播
out = net(inputs)
# 计算损失函数
loss = loss_func(out, labels)
# 清空上一轮的梯度
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 测试准确率
net.eval()
testout = net(testinput)
testloss = loss_func(testout, testlabel)
prediction = torch.max(testout, 1)[1] # torch.max
pred_y = prediction.numpy() # 事先放在了GPU,所以必须得从GPU取到CPU中!!!!!!
target_y = testlabel.data.numpy()
j = 0
for i in range(pred_y.size):
if pred_y[i] == target_y[i]:
j += 1
acc = j / pred_y.size
if epoch % 10 == 0:
print("训练次数为", epoch, "的准确率为:", acc)
if __name__ == "__main__":
feature, label = open_excel('iris')
# 数据划分为训练集和测试集和是否打乱数据集
split = 0.3 # 测试集占数据集整体的多少
ifshuffle = 1 # 1为打乱数据集,0为不打乱
x_train, x_test, y_train, y_test = split_data_set(feature, label, split, ifshuffle)
# 将数据转为tensor格式
traininput, trainlabel = inputtotensor(x_train, y_train)
testinput, testlabel = inputtotensor(x_test, y_test)
# 归一化处理
traininput = nn.functional.normalize(traininput)
testinput = nn.functional.normalize(testinput)
Epoch = 1000
input_size = 4
hidden_size = 5
output_size = 3
LR = 0.005
batchsize = 30
net = BPNerualNetwork()
optimizer = torch.optim.Adam(net.parameters(), LR)
# 设定损失函数
loss_func = torch.nn.CrossEntropyLoss()
# 训练并且记录每次准确率,loss 函数输入为:训练输入,训练标签,测试输入,测试标签,一个batch大小
train_test(traininput, trainlabel, testinput, testlabel, batchsize)
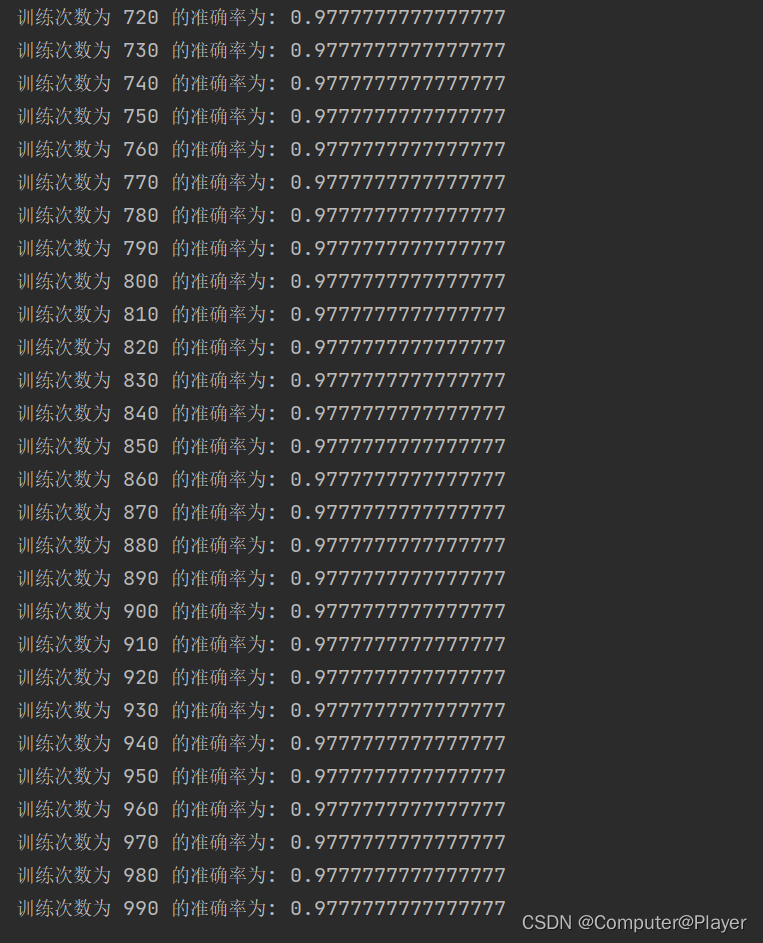
轻轻松松到达0.9777,这不是主要的,本次主要是进行简化一下Excel数据集操作。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
这是一道面试题,我没有答对,但还是很好奇怎么解。你有N个人的大家庭,分别是1,2,3,...,N岁。你想给你的大家庭拍张照片。所有的家庭成员都排成一排。“我是家里的friend,建议家庭成员安排如下:”1岁的家庭成员坐在这一排的最左边。每两个坐在一起的家庭成员的年龄相差不得超过2岁。输入:整数N,1≤N≤55。输出:摄影师可以拍摄的照片数量。示例->输入:4,输出:4符合条件的数组:[1,2,3,4][1,2,4,3][1,3,2,4][1,3,4,2]另一个例子:输入:5输出:6符合条件的数组:[1,2,3,4,5][1,2,3,5,4][1,2,4,3,5][1,2,4,5,3][
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI