sql语句group by使用详解
select 列名1,... , 列名n from 表
group by 列名1,... , 列名n
分组,顾名思义,分成小组。简而言之就是就是把相同的数据分到一个组。
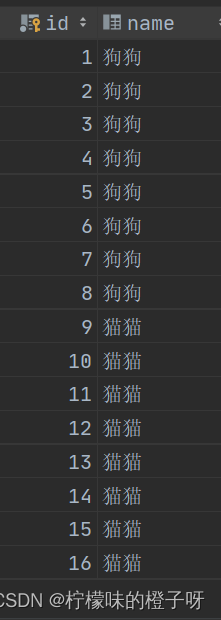
如下表(表名gb),里面有16条数据,前8条是狗狗,后8条是猫猫.
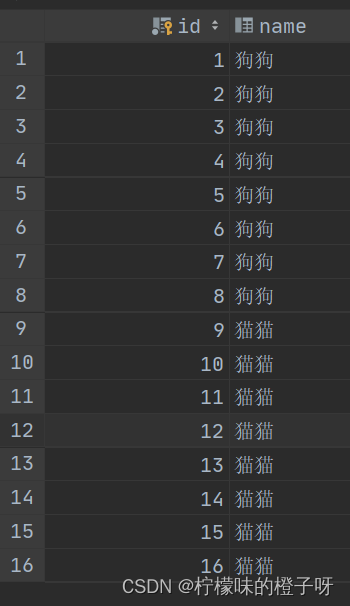
现在对name这个列进行分组查询
select name from gb group by name;
得到结果如下:
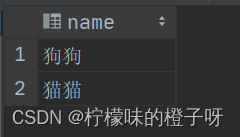
我们发现他把原始表分为了两个小组,狗狗小组和猫猫小组。从这可以看出分组查询就是把相同的数据分到一个组。
那么问题来了,我一直在说分组这个词,可是看见上面的结果明明是两行数据,哪里是组了,还不如说你这是去重得了(把重复的行筛选掉),虽然看似是两行数据(只有狗狗和猫猫两行),可实际上它是隐藏了,因为每个组里面都是相同的数据,所以它只显示一条数据,我们可以通过count()函数来统计每个组(也就是你看见的行)里面的个数,看一看每个组(行)里面到底包含了多少条数据。测试代码如下:
select name, count(name) as '每个组里的数量' from gb
group by name;
测试结果如下图:
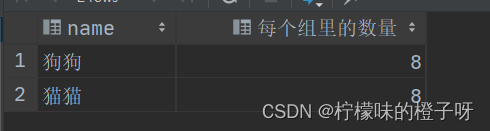
通过结果我们发现狗狗组里面有8条数据,猫猫组里面也有8条数据。所以我才说它是组而不是行。因为这个组里面有很多一样的数据,它只显示一条,所以我们很容易就误认为他是普通的行了。(关于这个结果我们可以认为他是一个嵌套表,就像我们编程语言中的嵌套数组一样)(大的套小的,小的里面还套着小的,有点俄罗斯套娃的梗了)。
首先准备如下表(表名gb):其中有name字段(动物的名称),colour字段 (动物的颜色)
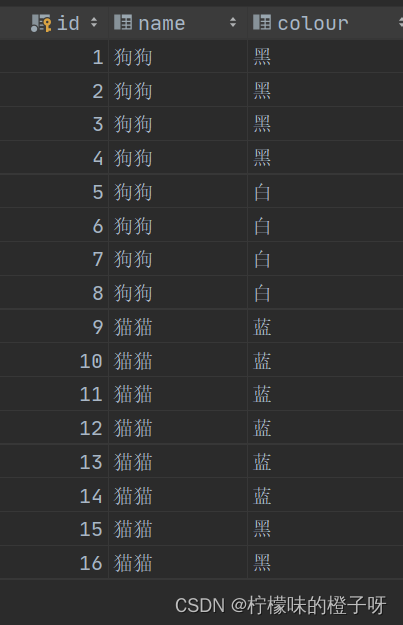
然后对该表的name和colour这两个字段进行分组聚合,代码如下:
select colour, name, count(*) as '数量' from gb
group by name, colour;
结果如下:
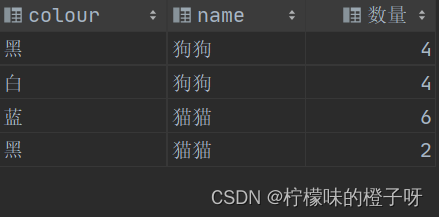
通过结果我们发现 两个字段进行分组和一个字段进行分组并无多大区别,两个字段分组就是要同时考虑两个列,两个列中都是一模一样的数据则分在同一个组中,就比如 黑色的狗狗是一个组、白色狗狗是一个组。 满足同一个动物名称的情况下还要满足动物的颜色,名称颜色都一样就是一个组的 。
如下表(表名gb):其中有name字段(动物的名称),colour字段 (动物的颜色), type字段(动物的类型或者叫动物的品种)
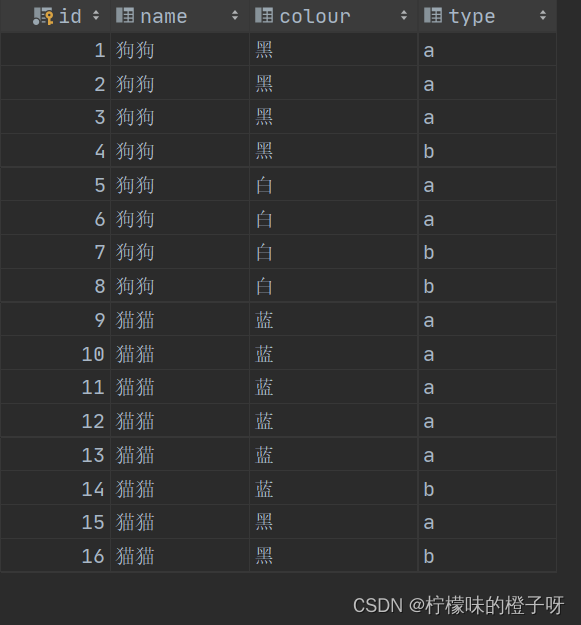
对name,colour,type这三个字段进行分组聚合,代码如下:
select type, colour, name, count(*) as '数量' from gb
group by name, colour, type;
结果如下:
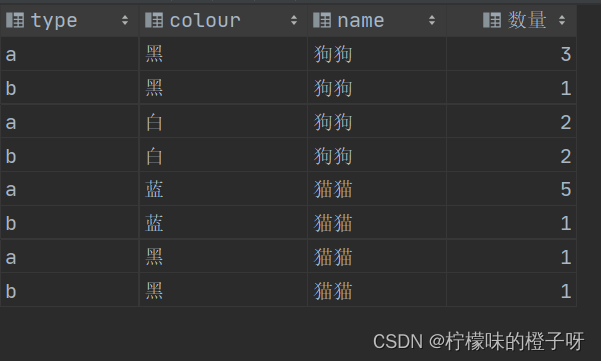
通过结果的发现,三个字段进行分组,那么就要同时考虑三个字段,首先考虑动物的名称name字段,它分为狗狗和猫猫两种组(注意: 这就是前面name分组的结果)。然后在考虑动物的颜色colour字段,狗狗有黑色和白色,猫猫有蓝色和黑色 , 他就分为了四种组(注意: 这就是前面name,colour分组的结果)。最后在考虑动物的类型type字段,黑色狗狗有a,b两个类型、白色狗狗有a,b两个类型、蓝色猫猫有a,b两个类型、黑色猫猫有a,b两个类型、它就分为了8种组(就是如上图的结果)。
总结 对N个字段进行分组聚合,那么同时要满足这N个字段,一层一层的往下分。
select 列名1,... , 列名n from 表
group by 列名1,... , 列名n
having 筛选规则
其实having很好理解 他的功能与where是一样的,都是为了写条件语句进行筛选数据。但是SQL语法规定,对于group by之后的组结果,想要对其结果进行筛选,必须使用having关键字,不能使用where。所以我们可以把having看成group by的搭档就行了,见了group by 想要对其结果筛选,后面就使用having关键字。就像我们吃饭要用筷子,喝汤要用勺子,筷子和勺子都是吃饭的工具。having与where都是筛选的关键词,只是应用的场景不同而已。
准备下表(表名gb):有动物名称name字段和动物颜色colour字段
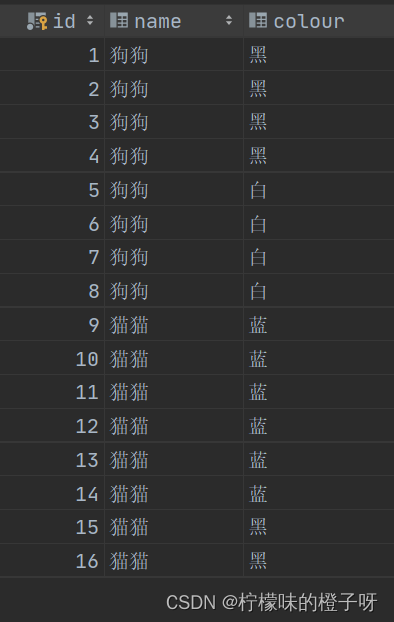
先看看同一个动物中同种颜色的各有多少个
select name, colour, count(*) as '数量' from gb
group by name, colour;
结果
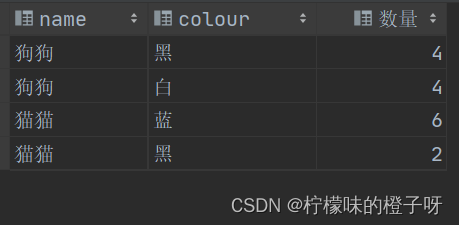
从结果中可以看出 黑色狗狗与白色狗狗各有4只,蓝色的猫猫有6只,黑色猫猫有2只。
然而现在我们只想看猫猫的数据,不想看狗狗的数据,所以现在我们就要对上图的结果进行筛选。
select name, colour, count(*) as '数量' from gb
group by name, colour
having name = '猫猫';
结果
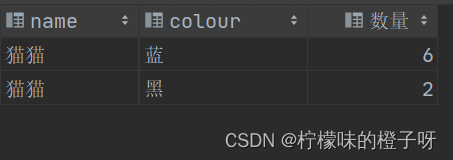
所以通过having关键词我们就进行了对group by分组结果的筛选了,选出了我们想要的结果。
然而对此结果我们还是不太满意,我想要选出猫猫中数量 >=6 的组,测试代码如下:
select name, colour, count(*) as '数量' from gb
group by name, colour
having name = '猫猫' and count(*) >= 6;
结果如下:
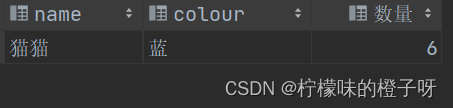
通过上面sql语句发现,我们只是在筛选条件上增加了一个筛选条件 使用and 连接可以得出结果。但是这也引发一个新的问题。那就是在where后面我们写筛选条件好像没有用过聚合函数(如count函数等)当条件吧,然而having后面我们却使用了聚合函数(如count函数等)当条件,所以这里也有一个语法规定如下:
1.where后面的筛选规则是对整个表中的行进行筛选,所以不会直接使用聚合函数进行充当条件。
2.having后面是对group by分出的组的结果进行筛选,看似是对每一行进行筛选其实是对每一个组进行筛选,所以我们就可以 直接使用聚合函数充当条件。
SQL语法中规定, select关键字后面的列名 要么在group by 后面出现过,要么在selelct后面使用的聚合函数中出行过。没有出现过就不能使用。
如下表(表名gb):其中有动物的名称name字段。

如上如的sql语句 红色框书写的列名(select关键字后面的列名), 必须要在两个绿色框中出现过(聚合函数中 或 group by后 出现过),才能书写,没出现过就不能书写。
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion在首页我有:汽车:VolvoSaabMercedesAudistatic_pages_spec.rb中的测试代码:it"shouldhavetherightselect"dovisithome_pathit{shouldhave_select('cars',:options=>['volvo','saab','mercedes','audi'])}end响应是rspec./spec/request
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
假设我有一个在Ruby中看起来像这样的哈希:{:ie0=>"Hi",:ex0=>"Hey",:eg0=>"Howdy",:ie1=>"Hello",:ex1=>"Greetings",:eg1=>"Goodday"}有什么好的方法可以将它变成如下内容:{"0"=>{"ie"=>"Hi","ex"=>"Hey","eg"=>"Howdy"},"1"=>{"ie"=>"Hello","ex"=>"Greetings","eg"=>"Goodday"}} 最佳答案 您要求一个好的方法来做到这一点,所以答案是:一种您或同事可以在六个月后理解
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我几天前在我的rubyonrails2.3.2上安装了Sphinx和Thinking-Sphinx,基本搜索效果很好。这意味着,没有任何条件。现在,我想用一些条件过滤搜索。我有公告模型,索引如下所示:define_indexdoindexestitle,:as=>:title,:sortable=>trueindexesdescription,:as=>:description,:sortable=>trueend也许我错了,但我注意到只有当我将:sortable=>true语法添加到这些属性时,我才能将它们用作搜索条件。否则它找不到任何东西。现在,我还在使用acts_as_tag