在ES中有很重要的一个概念就是分词,ES的全文检索也是基于分词结合倒排索引做的。所以这一文我们来看下何谓之分词。如何分词。
Analysis和Analyzer是两个单词,第一个是动词,第二个是名字。
Analysis是指的文本分析,把一个文档全文文本按照规则转换成一系列的单词(term/token)的过程,也就是分词。
Analyzer是名词,他就是分词器,文本分析就是由他来完成的。ES内置有分词器,你也可以自己定制自己的分词器。
当我们写入一个文档的时候,ES的分词器会把文档分词,然后形成每个词的倒排索引结构。当我们再去查这个词的时候,还是要走一样的分析过程,这样才能达到分词检索的效果。
分词器是专门处理分词的组件,在很多中间件设计中每个组件的职责都划分的很清楚,单一职责原则,以后改的时候好扩展。
分词器由三部分组成。
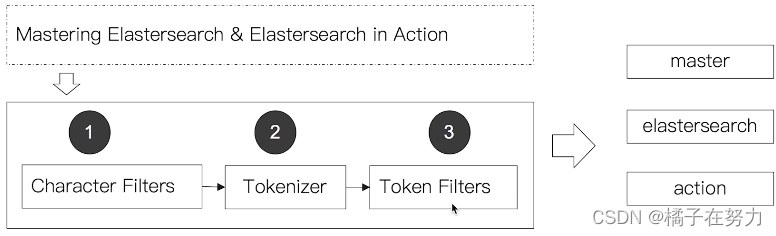
你可以自己扩展自己的分词器,比如 IK中文分词器,以前还听说还有个梵文分词器真是牛逼。当然了,ES内部也内置了很多种分词器供使用。具体如下。

一般测试分词效果有以下三种方式:
GET /_analyze
{
"analyzer": "standard", 指定分词器
"text":"if you miss the train I am on,you will know that I am gone" 你要测试的文本
}
GET /_analyze
{
"analyzer": "standard",
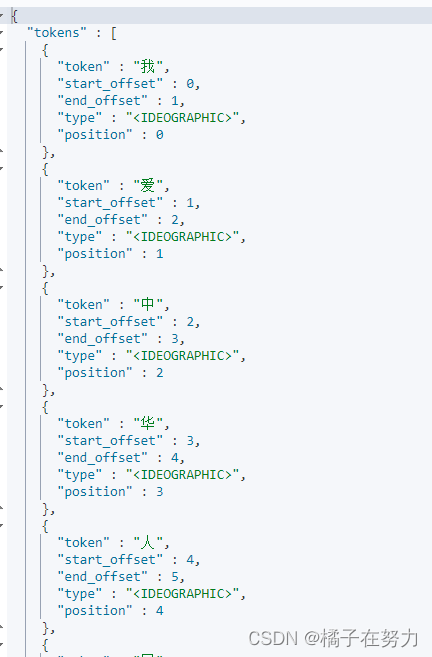
"text":"我爱中华人民共和国"
}
效果如下:我们指定的标准分词器,分析的结果就是每个文本都被以一个个词汇拆开了,他就是这么简单的分词。

GET /movies/_mapping
POST movies/_analyze 指定索引
{
"field": "title", 分析你索引中字段的分析结果,分词器是你创建索引的时候指定的,各个字段可以不同分词器
"text": "god father"
}
效果如下:

POST /_analyze
{
"tokenizer": "standard", 指定分词组件
"filter": ["lowercase"], 指定分词组件
"text": "我爱中国共产党" 测试文本内容
}
测试效果如下:还是一个个词汇,因为本身都是默认的那个标准的,这个组合分词效果如下。

#Simple Analyzer – 按照非字母切分(符号被过滤),小写处理
#Stop Analyzer – 小写处理,停用词过滤(the,a,is)
#Whitespace Analyzer – 按照空格切分,不转小写
#Keyword Analyzer – 不分词,直接将输入当作输出
#Patter Analyzer – 正则表达式,默认 \W+ (非字符分隔)
#Language – 提供了30多种常见语言的分词器
标注分词器,ES中默认的分词器就是这个东西。他的各个组件的构成如下。
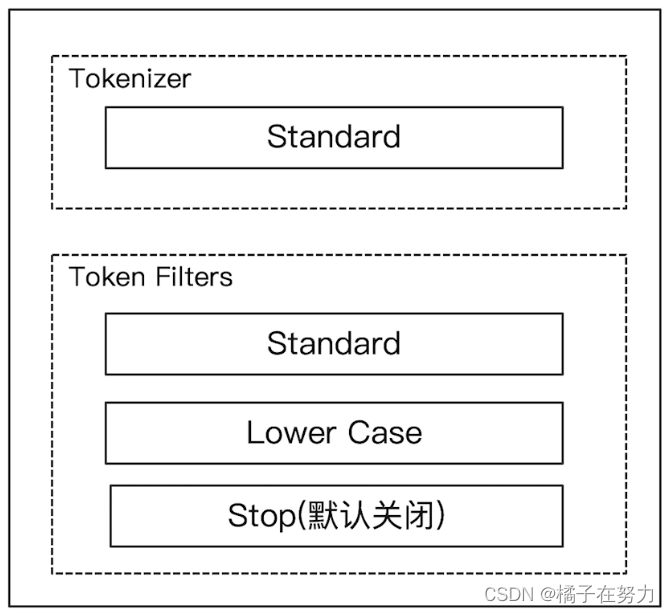
其特点就是按照词汇切分,不管什么文本都是一个一个词汇切开的。
对单词做了小写处理,也就是大小写一样的。
其停用词默认是关闭的。
#standard
GET _analyze
{
"analyzer": "standard",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
标准分词器就是按照一个个的词汇来拆分,然后大写转成了小写。

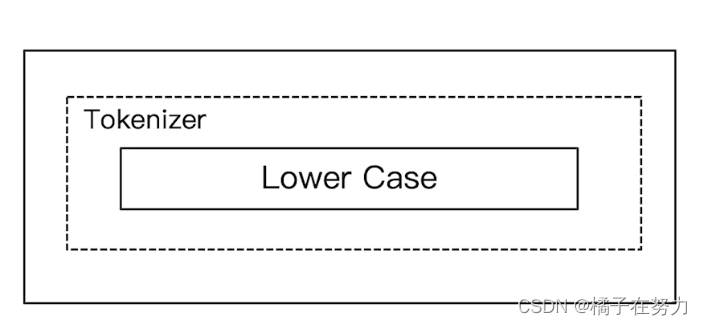
他的特点是按照非字母进行切分,把非字母去除剩下的一个个词汇进行按词汇切分。
最后大写转小写。
#simpe
GET _analyze
{
"analyzer": "simple",
"text": "2 running Quick 3 brown-foxes leap."
}
他把数字去掉了,剩下的按词汇切分。把中划线也去掉了,去掉之后brown foxes成为两个词。

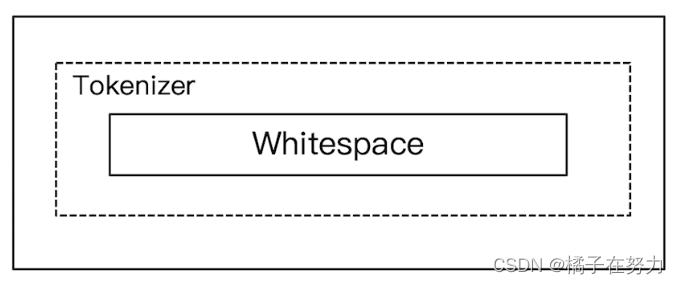
他的特点就是按照空格切分,然后剩余的都是一个个词。
不转小写。
#whitespace
GET _analyze
{
"analyzer": "whitespace",
"text": "2 running Quick brown-foxes leap over ."
}
结果就是按照空格拆分的,数字什么的都保留。不转小写。

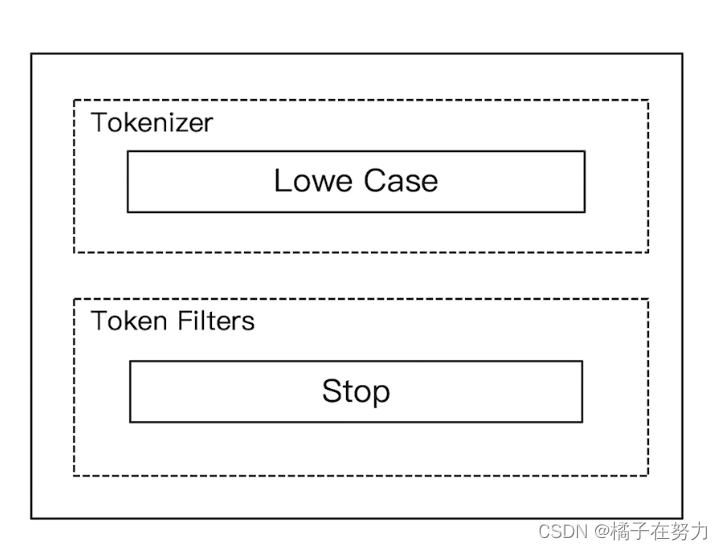
我们看到他多了一个组件stop,这个的作用就是去掉一些修饰词汇 is the a以及阿拉伯数字之类的。当成了停用词。
# stop
GET _analyze
{
"analyzer": "stop",
"text": "2 he is sb 5"
}
数字和is会被去掉

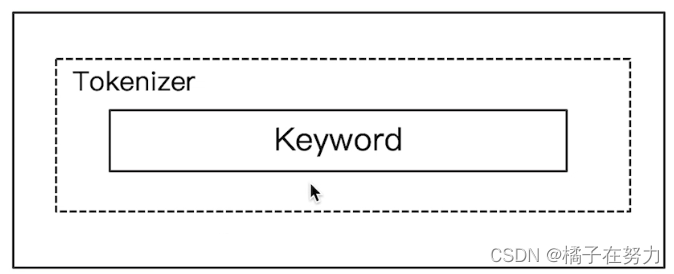
他的特点就是不分词,虽然是个分词器,但是不分词,他会把文档不做处理,原封不动。
如果你不需要分词就用这个。
#keyword
GET _analyze
{
"analyzer": "keyword",
"text": "2 what is you name fuck you"
}
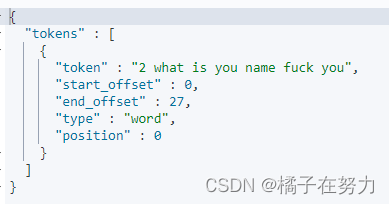
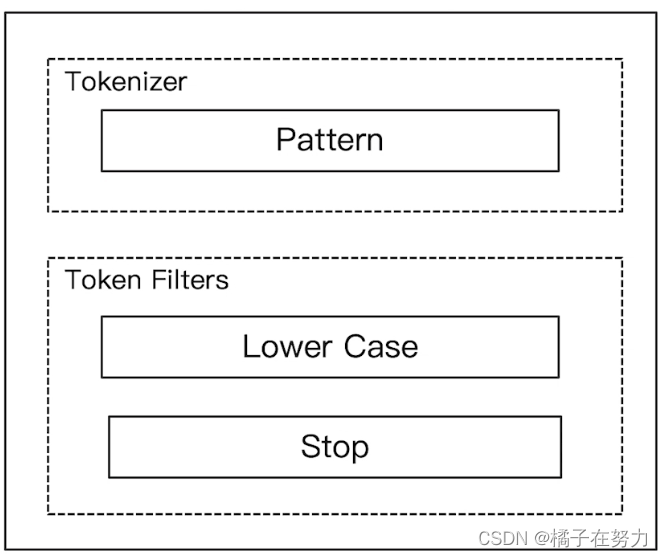
他的组件组成如上,他的特点就是通过正则表达式分词。有转小写,没有停用词。
默认是通过\W+这个正则,也就是非字母的符号进行分割。
GET _analyze
{
"analyzer": "pattern",
"text": "2 running Quick brown-foxes "
}
因为那个中划线和空格都不是字母,所以被切开了。其余的就是转小写,以及is am a那些没被停用。

ES提供language分词器,为各个不同国家的语言进行分词具体的语言支持有以下几种。你可以指定语言。

他的特点就是比如我指定英文分词,有is am the那些停用了,然后什么进行时,过去式都会被去掉,没有时态,复数也会转为单数。
#english
GET _analyze
{
"analyzer": "english", 指定英文
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}

中文分词和上面的英文分词不一样,英文文档中每个词都会按照空格分开,你只需要按照空格分词就行了。但是中文限制很多,受限于语境,受限于词性。自然语言的限制,可以了解一下自然语言。
举个例子:
这个苹果,不大好吃 -----这个苹果不大,好吃。
这就很难顶,中文语言很麻烦。
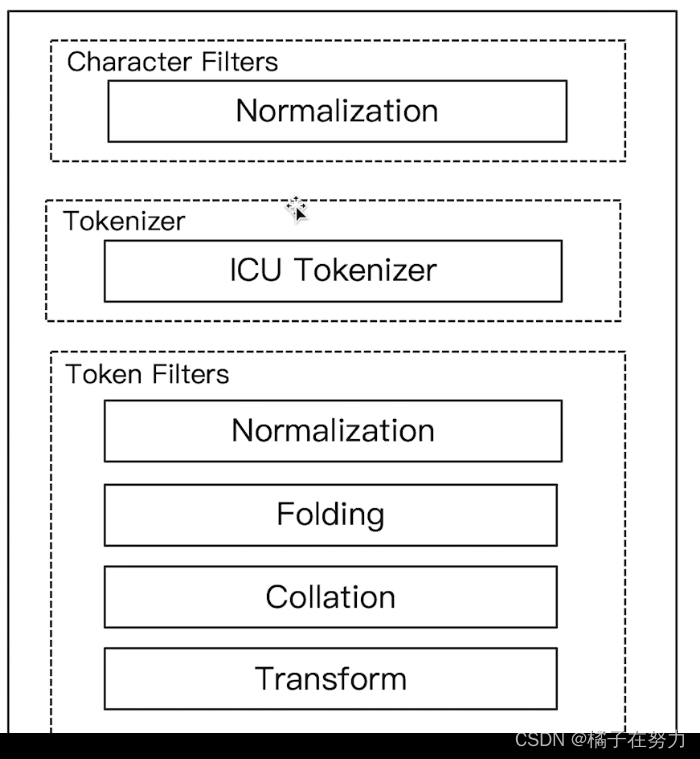
这个插件需要安装,ES不自带这个,该插件体提供了Unicode的支持,更好的支持亚洲语言。
具体怎么安装可以百度,贼简单。
测试语句在这里:
POST _analyze
{
"analyzer": "icu_analyzer",
"text": "他说的确实在理”"
}
POST _analyze
{
"analyzer": "standard",
"text": "他说的确实在理”"
}
这个分词器分的还是不太好,中文分词器,我推荐IK分词器。

下面我来处理一下如何使用IK分词器。
目前我是docker启动的,所以需要先去下载一下这个IK分词器的包。
操作步骤:
1、查看一下当前环境的docker容器运行情况
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3b11fe0f1e23 docker.elastic.co/elasticsearch/elasticsearch:7.1.0 "/usr/local/bin/dock…" 3 days ago Up 2 hours 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 9300/tcp es7_01
9d2b07a931e5 lmenezes/cerebro:0.8.3 "/opt/cerebro/bin/ce…" 3 days ago Up 2 hours 0.0.0.0:9000->9000/tcp, :::9000->9000/tcp cerebro
ca73ab08d5fb docker.elastic.co/kibana/kibana:7.1.0 "/usr/local/bin/kiba…" 3 days ago Up 2 hours 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana7
1fbf619f7735 docker.elastic.co/elasticsearch/elasticsearch:7.1.0 "/usr/local/bin/dock…" 3 days ago Up 2 hours 9200/tcp, 9300/tcp es7_02
2、进入容器中
docker exec -it es7_01 /bin/bash
3、执行下载拉取IK分词器的指令,注意版本和ES保持一致
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.7.0/elasticsearch-analysis-ik-7.7.0.zip
4、下载中点yes就行了,下载完后,退出容器
exit;
因为我有两个节点组成集群,所以每个节点都要安装一下,重复操作就行了。
5、重启docker容器
docker restart 1fbf619f7735
docker restart 3b11fe0f1e23
先看普通的分词器效果:
POST _analyze
{
"analyzer": "standard",
"text": "他的话确实有道理”"
}
我们看到就是按字拆分的,一个字一个字的,没啥语境可言。

再看IK分词器效果:IK分词器提供两种分词方式ik_smart和 ik_max_word
ik_smart:称为智能分词,网上还有别的称呼:最少切分,最粗粒度划分.分词的时候只分一次,句子里面的每个字只会出现一次。
ik_max_word:称为最细粒度划分,句子的字可以反复出现。 只要在词库里面出现过的 就拆分出来。如果没有出现的单字。如果已经在词里面出现过,那么这个就不会以单字的形势出现。尽可能细粒度的分。
ik_max_word:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "他的话确实有道理”"
}
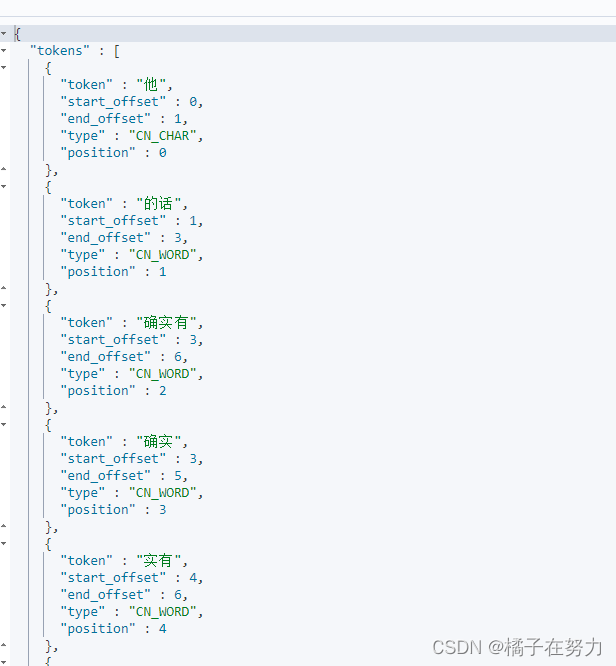
这个其实也没分好。
ik_smart:
POST _analyze
{
"analyzer": "ik_smart",
"text": "他的话确实有道理”"
}

这个就分的很好了。自己选吧。此外IK分词器支持配置停用词,近义词等等操作,我们后面来处理。
ES的分词机制是建立在几个组件上面的。
分词器由三部分组成。
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我的ruby脚本从命令行参数获取某些输入。它检查是否缺少任何命令行参数,然后提示用户输入。但是我无法使用gets从用户那里获得输入。示例代码:test.rbname=""ARGV.eachdo|a|ifa.include?('-n')name=aputs"Argument:#{a}"endendifname==""puts"entername:"name=getsputsnameend运行脚本:rubytest.rbraghav-k错误结果:test.rb:6:in`gets':Nosuchfileordirectory-raghav-k(Errno::ENOENT)fromtes
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
FPGA时钟和时钟域时钟树所谓时钟树为FPGA内部资源,分:全局时钟树,区域时钟树,IO时钟树原则上优先使用全局时钟树,在GT接口上使用IO时钟树,一般工具也会对GT时钟加以限制;时钟树使用方式正确的物理连接FPGA会由物理管脚专门用于全局时钟设置,通过查询数据手册可以在PCB设计阶段进行确认,当外部时钟接入此管脚时,工具会自动占有全局时钟树资源,当接入普通信号时不会分配时钟树资源;恰当的代码描述原语的使用,即BUFG的使用,可以将PLL的输出等内部时钟进行全局时钟资源的分配;IO时钟资源需要参考相应接口手册,以ultrascale的GTH为例,其JESD204的时钟方案针对不同的子类会由不同
集成背景我们当前集群使用的是ClouderaCDP,Flink版本为ClouderaVersion1.14,整体Flink安装目录以及配置文件结构与社区版本有较大出入。直接根据Streampark官方文档进行部署,将无法配置FlinkHome,以及后续整体Flink任务提交到集群中,因此需要进行针对化适配集成,在满足使用需求上,尽量提供完整的Streampark使用体验。集成步骤版本匹配问题解决首先解决无法识别Cloudera中的FlinkHome问题,根据报错主要明确到的事情是无法读取到Flink版本、lib下面的jar包名称无法匹配。修改对象:修改源码:(解决无法匹配clouderajar
Feign微服务调用传递文件以及MultipartFile多媒体参数对象上游服务提供者测试服务提供者下游消费者异常原因错误解决方案通过Feign调用接口,来到jdk动态代理的invoke方法,拿到分发器,执行invoke逻辑。invoke方法:构建ReuqestTemplate以及请求报文,执行并解密,执行请求拦截器。可行的解决方案寻找SpringEncoder来源注册自定义Encoder编写自定义Encoder自定义文件上传接口标识注解编写encode逻辑测试总结上游服务提供者使用spring接收文件可以使用MultipartFile对象,并同时使用RequestPart注解标识这个一个多媒