目录
现在所有人都知道万能的Python可以做机器学习,可以做人工智能,可以爬取各种小网站,但是你不知道,基于C++的正则表达式早就能够爬取各种网络数据啦!!你没猜错,阿玥将在这篇文章中简介怎么用C++基于Regex的库写一个爬虫~
正则表达式Regex(regular expression)是一种强大的描述字符序列的工具。在许多语言中都存在着正则表达式,C++11中也将正则表达式纳入了新标准的一部分,不仅如此,它还支持了6种不同的正则表达式的语法,分别是:ECMASCRIPT、basic、extended、awk、grep和egrep。其中ECMASCRIPT是默认的语法,具体使用哪种语法我们可以在构造正则表达式的时候指定。
注:ECMAScript是一种由Ecma国际(前身为欧洲计算机制造商协会,英文名称是European Computer Manufacturers Association)通过ECMA-262标准化的脚本程序设计语言。它往往被称为JavaScript,但实际上后者是ECMA-262标准的实现和扩展。
1. 确保你的编译器支持Regex
如果你的编译器是GCC-4.9.0或者VS2013以下版本,请升级后,再使用。我之前使用的C++编译器,是GCC 4.8.3,有regex头文件,但是GCC很不厚道的没有实现,语法完全支持,但是库还没跟上,所以编译的时候是没有问题的,但是一运行就会直接抛出异常,非常完美的一个坑有木有!具体错误如下:
| 1 2 3 |
|
如果你也遇到了这个问题,请不要先怀疑自己,GCC这一点是非常坑爹的!!!我在这个上面浪费了半天的时间才找了出来。所以在尝鲜C++的正则表达式之前,请升级你的编译器,确保你的编译器支持它。

2. regex库概览
在头文件<regex>中包含了多个我们使用正则表达式时需要用到的组件,大致有:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
1. ECMASCRIPT正则表达式语法
正则表达式式的语法基本大同小异,在这里就浪费篇幅细抠了。ECMASCRIPT正则表达式的语法知识可以参考W3CSCHOOL。
2. 构造正则表达式
构造正则表达式用到一个类:basic_regex。basic_regex是一个正则表达式的通用类模板,对char和wchar_t类型都有对应的特化:
| 1 2 |
|
构造函数比较多,但是非常简单:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
以上除默认构造之外的构造函数,都有一个flag_type类型的参数用于指定正则表达式的语法,ECMASCRIPT、basic、extended、awk、grep和egrep均是可选的值。除此之外还有其他几种可能的的标志,用于改变正则表达式匹配时的规则和行为:
| 1 2 3 4 5 6 7 8 |
|
有了构造函数之后,现在我们就可以先构造出一个提取http链接的正则表达式:
| 1 2 |
|
值得一提的是在C++中’\’这个字符需要转义,因此所有ECMASCRIPT正则表达式语法中的’\’都需要写成“\”的形式。我测试的时候,这段regex如果没有加转义,在gcc中会给出警告提示,vs2013编译后后运行直接崩溃了。
3. 正确地处理输入
先扯一个题外话,假设我们不是使用了网络库自动在程序中下载的网页,在我们手动下载了网页并保存到文件后,首先我们要做的还是先把网页的内容(html源码)存入一个std::string中,我们可能会使用这样的错误方式:
| 1 2 3 4 5 6 |
|
这样一来源代码中所有的空白字符就无意中被我们全处理了,这显然不合适。这里我们还是使用getline()这个函数来处理:
| 1 2 3 4 5 6 7 8 9 |
|
这样一来原来的文本才能得到正确的输入。当然个人以为这些小细节还是值得注意的,到时候出错debug的时候,我想我们更多地怀疑的是自己的正则表达式是否是有效。
4. regex_search() 只查找到第一个匹配的子序列
根据函数的字面语义,我们可能会错误的选择regex_search()这个函数来进行匹配。其函数原型也有6个重载的版本,用法也是大同小异,函数返回值是bool值,成功返回true,失败返回false。鉴于篇幅,我们只看我们下面要使用的这个:
| 1 2 3 |
|
第一个参数s是std::basic_string类型的,它是我们待匹配的字符序列,参数m是一个match_results的容器用于存放匹配到的结果,参数e则是用来存放我们之前构造的正则表达式对象。flags参数值得一提,它的类型是std::regex_constants::match_flag_type,语义上匹配标志的意思。正如在构造正则表达式对象时我们可以指定选项如何处理正则表达式一样,在匹配的过程中我们依然可以指定另外的标志来控制匹配的规则。这些标志的具体含义,可以参考下表,用的时候查一下就可以了:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
根据参数类型,于是我们构造了这样的调用:
| 1 2 |
|
不过,标准库规定regex_search()在查找到第一个匹配的子串后,就会停止查找!在本程序中,results参数只带回了第一个满足条件的http链接。这显然并不能满足我们要提取网页中所有HTTP链接需要。
5. 使用 regex_iterator 匹配所有子串
严格意义上regex_iterator是一种迭代器适配器,它用来绑定要匹配的字符序列和regex对象。regex_iterator的默认构造函数比较特殊,就直接构造了一个尾后迭代器。另外一个构造函数原型:
| 1 2 3 |
|
和上边的regex_search()一样,regex_iterator的构造函数中也有std::regex_constants::match_flag_type类型的参数,用法一样。其实regex_iterator的内部实现就是调用了regex_search(),这个参数是用来传递给regex_search()的。用gif或许可以演示的比较形象一点,具体是这样工作的(颜色加深部分,表示可以匹配的子序列):
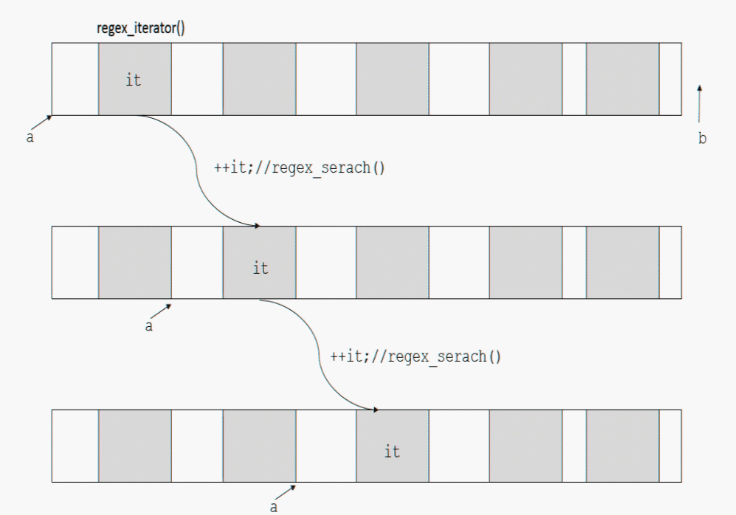
首先在构造regex_iterator的时候,构造函数中首先就调用一次regex_search()将迭代器it指向了第一个匹配的子序列。以后的每一次迭代的过程中(++it),都会在以后剩下的子序列中继续调用regex_search(),直到迭代器走到最后。it就一直“指向”了匹配的子序列。
知道了原理,我们写起来代码就轻松多了。结合前面的部分我们,这个程序就基本写好了:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
到这里各位小伙伴们就已经可以去找自己喜欢的各种网站去爬爬爬了!!!
3. regex 和异常处理
如果我们的正则表达式存在错误,则在运行的时候标准库会抛出一个regex_error异常,他有一个名为code的成员,用于标记错误的类型,具体错误值和语义如下表所示:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
新星计划2023【C/C++领域基础】学习方向报名入口:
大家参加本次计划就可以获得100积分哦!
可以学习C/c++的许多知识,大家要踊跃参加哦!!!
希望大家可以踊跃报名以上新星计划哦,不但可以学习好多知识,还有许多海量奖品等你来拿!!!
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
我想让一个yaml对象引用另一个,如下所示:intro:"Hello,dearuser."registration:$introThanksforregistering!new_message:$introYouhaveanewmessage!上面的语法只是它如何工作的一个例子(这也是它在thiscpanmodule中的工作方式。)我正在使用标准的rubyyaml解析器。这可能吗? 最佳答案 一些yaml对象确实引用了其他对象:irb>require'yaml'#=>trueirb>str="hello"#=>"hello"ir
这个问题在这里已经有了答案:Arraysmisbehaving(1个回答)关闭6年前。是否应该这样,即我误解了,还是错误?a=Array.new(3,Array.new(3))a[1].fill('g')=>[["g","g","g"],["g","g","g"],["g","g","g"]]它不应该导致:=>[[nil,nil,nil],["g","g","g"],[nil,nil,nil]]
我的问题的一个例子是体育游戏。一场体育比赛有两支球队,一支主队和一支客队。我的事件记录模型如下:classTeam"Team"has_one:away_team,:class_name=>"Team"end我希望能够通过游戏访问一个团队,例如:Game.find(1).home_team但我收到一个单元化常量错误:Game::team。谁能告诉我我做错了什么?谢谢, 最佳答案 如果Gamehas_one:team那么Rails假设您的teams表有一个game_id列。不过,您想要的是games表有一个team_id列,在这种情况下