目录
前段时间因为考研的原因一直没能更新,已经完成了农作物种植结构的提取,现在给大家分享一下。
主要也是结合前面写过的Google Earth Engine(GEE)使用土地利用数据(modis)上采样Landsat数据提取农田范围,将以上结果作为研究的基础,结合物候特征,光谱特征,地形特征,选择随机森林算法进行农作物的提取。
不想看后面的同学可以直接看代码:https://code.earthengine.google.com/3ed8a5303c610e063ae3a4517ca4e146
在这里主要通过不同农作物NDVI值的差异来选择合适的生长时间进行影像的选择。
通过构建典型地物的NDVI时序特征曲线,不同农作物随着时间的变化,NDVI值也在跟着变化,这种变化也反映了不同农作物在不同时期的光谱特征差异。因此,选择NDVI差异较大的越冬期和成熟期作为最佳识别期进行农作物分类,可以有效进行农作物种类的区分。
var winter = ee.ImageCollection('COPERNICUS/S2_SR')
.filterDate('2021-11-30', '2022-01-01')
.filterBounds(roi)
.filter(ee.Filter.lt('CLOUDY_PIXEL_PERCENTAGE', 10))
.map(maskS2clouds)
.map(mndwi)
.map(ndbi)
.map(ndvi)
.select(['B1','B2','B3','B4','B8','B12','QA60','MNDWI','NDBI','NDVI']);
var winter1=winter.median()
.addBands(elevation.rename("ELEVATION"))
.addBands(slope.rename("SLOPE"))
.clip(roi);
Map.addLayer(winter1, {bands: ['B4', 'B3', 'B2'],min:0, max: 0.3}, 'winter1',false);
var summer = ee.ImageCollection('COPERNICUS/S2_SR')
.filterDate('2022-03-01', '2022-04-01')
.filterBounds(roi)
.filter(ee.Filter.lt('CLOUDY_PIXEL_PERCENTAGE', 10))
.map(maskS2clouds)
.map(mndwi)
.map(ndbi)
.map(ndvi)
.select(['B1','B2','B3','B4','B8','B12','QA60','MNDWI','NDBI','NDVI']);
var summer1=summer.median()
.addBands(elevation.rename("sum_ELEVATION"))
.addBands(slope.rename("sum_SLOPE"))
.clip(roi);
这里我把基础影像根据农田范围进行了裁剪,只留下农田区域,能有效的排除一些非农田地物类型。
也就是构建NDVI、NDWI、NDBI等光谱指数,来区分植被、建筑,水体等。
//构建光谱特征
function mndwi(image){
return image.addBands(image.normalizedDifference(['B3', 'B8']).rename('MNDWI'))
}
function ndbi(image){
return image.addBands(image.normalizedDifference(['B12', 'B8']).rename('NDBI'))
}
function ndvi(image){
return image.addBands(image.normalizedDifference(['B8', 'B4']).rename('NDVI'))
}
将上面选择的越冬期和成熟期的多幅影像合并为一幅,在这里需要更改波段名,不然会出现波段名重复的情况。
//更改波段名称,合成一幅影像
var useimage = winter1.addBands([
summer1.select('B2').rename('sum_B2'),
summer1.select('B3').rename('sum_B3'),
summer1.select('B4').rename('sum_B4'),
summer1.select('B8').rename('sum_B8'),
summer1.select('B12').rename('sum_B12'),
summer1.select('MNDWI').rename('sum_MNDWI'),
summer1.select('NDBI').rename('sum_NDBI'),
summer1.select('NDVI').rename('sum_NDVI'),
summer1.select('sum_ELEVATION'),
summer1.select('sum_SLOPE')
])
print(useimage,'useimage')
//求交集,对影像进行掩膜
var useimage1 = useimage.updateMask(esamask)
// var useimage1 = useimage
Map.addLayer(useimage1, {bands: ['sum_B4', 'sum_B3', 'sum_B2'],min:0, max: 0.3}, 'useimage1');
var usebands = ['B2','B3','B4','B8','B12','MNDWI','NDBI','NDVI','ELEVATION','SLOPE',
'sum_B2','sum_B3','sum_B4','sum_B8','sum_B12','sum_MNDWI','sum_NDBI','sum_NDVI','sum_ELEVATION','sum_SLOPE']
构建算法也就是一些老套路了,无非就是建立样本,将样本分成训练样本和验证样本。
在这里想说一点,随机森林的决策树棵树选择不能随便选择,需要进行不同棵数的尝试,可以使用以下代码进行分析,选择准确率最高的颗数进行算法构建。
//选取森林棵树
var numTrees = ee.List.sequence(5, 50, 5);
var accuracies = numTrees.map(function(t)
{
var classifier = ee.Classifier.smileRandomForest(t)
.train({
features: trainingPartition,
classProperty: 'landcover',
inputProperties: usebands
});
return testingPartition
.classify(classifier)
.errorMatrix('landcover', 'classification')
.accuracy();
});
print(ui.Chart.array.values({
array: ee.Array(accuracies),
axis: 0,
xLabels: numTrees
}));
得到的结果大概是这样,选择准确率最高的就可以了。

因为我们上面已经训练好了算法,所以这个算法是可以运用在其他年份的,我们将它保存在个人assets里,当缺少其他年份的样本时,可以使用该算法进行分类,也就是算法复用。
var trees = ee.List(ee.Dictionary(testclassifier.explain()).get('trees'))
var dummy = ee.Feature(roi.geometry())
var col = ee.FeatureCollection(trees.map(function(x){return dummy.set('tree',x)}))
print(col)
Export.table.toAsset(col,'save_classifier','projects/dyb/assets/2022chuzhou')
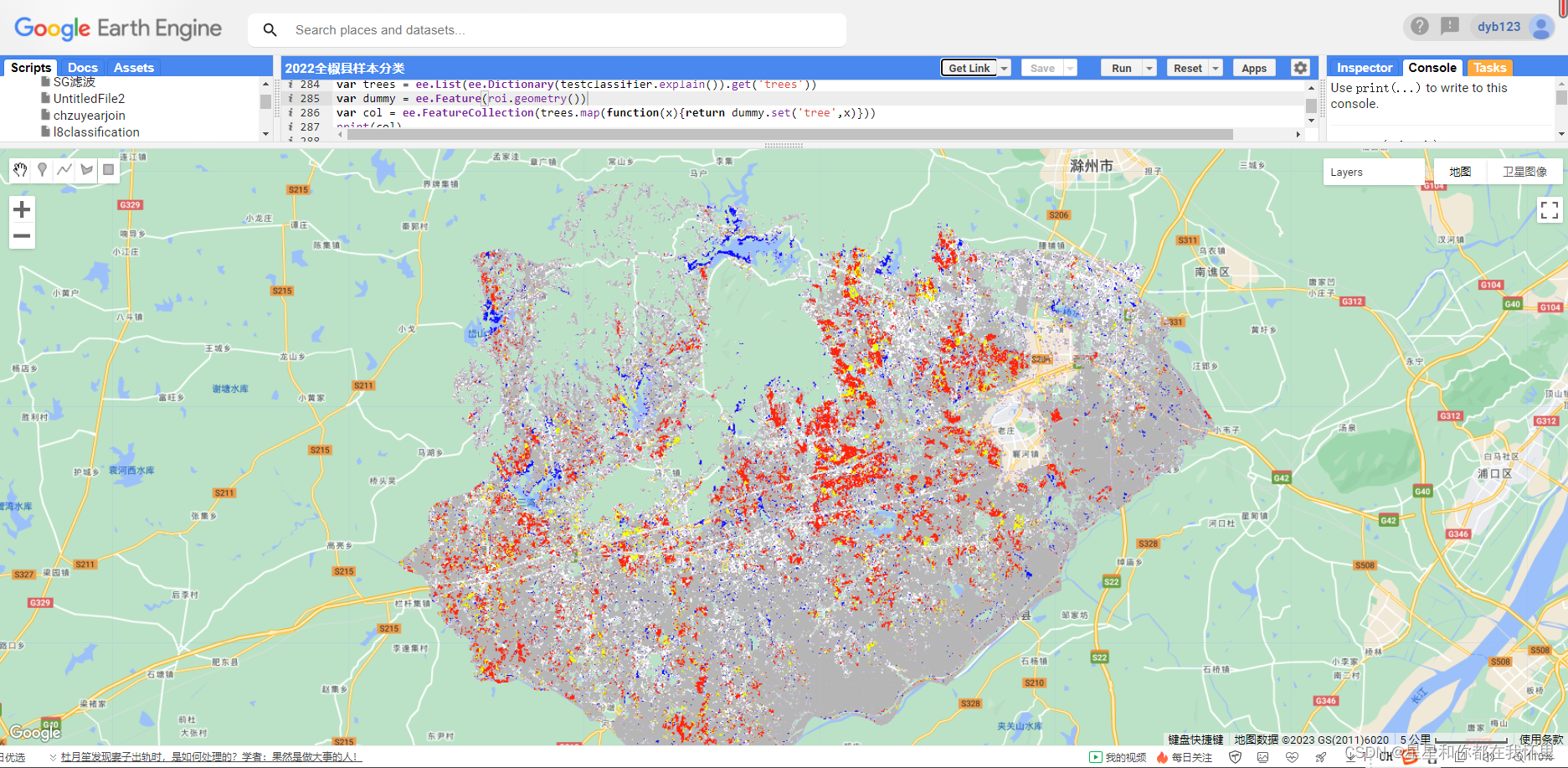
上面已经做好了农作物的分类,接下来可以对农作物的面积做一个统计。
var areaImage = ee.Image.pixelArea().addBands(classified)
var clsdArea = areaImage.reduceRegion({
'reducer': ee.Reducer.sum().group({
'groupField': 1,
'groupName': 'class'
}),
'geometry': roi.geometry(),
'scale': 10,
'maxPixels': 1e13
})
print('Kerala landcover clsArea:', clsdArea.getInfo())
最后把所有代码放在这里
https://code.earthengine.google.com/3ed8a5303c610e063ae3a4517ca4e146
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
您将如何构建一个简单的Sinatra应用程序?我正在制作,我希望该应用具有以下功能:“应用程序”更像是一个包含所有信息的管理仪表板。然后另一个应用程序将通过REST访问信息。我还没有创建仪表板,只是从数据库中获取东西session和身份验证(尚未实现)您可以上传图片,其他应用可以显示这些图片我已经使用RSpec创建了一个测试文件通过Prawn生成报告目前的设置是这样的:app.rbtest_app.rb因为我实际上只有应用程序和测试文件。到目前为止,我已经将Datamapper用于ORM,将SQLite用于数据库。这是我的第一个Ruby/Sinatra项目,所以欢迎任何和所有建议-我应
Rails中有没有一种方法可以提取与路由关联的HTTP动词?例如,给定这样的路线:将“users”匹配到:“users#show”,通过:[:get,:post]我能实现这样的目标吗?users_path.respond_to?(:get)(显然#respond_to不是正确的方法)我最接近的是通过执行以下操作,但它似乎并不令人满意。Rails.application.routes.routes.named_routes["users"].constraints[:request_method]#=>/^GET$/对于上下文,我有一个设置cookie然后执行redirect_to:ba
我有一个.pfx格式的证书,我需要使用ruby提取公共(public)、私有(private)和CA证书。使用shell我可以这样做:#ExtractPublicKey(askforpassword)opensslpkcs12-infile.pfx-outfile_public.pem-clcerts-nokeys#ExtractCertificateAuthorityKey(askforpassword)opensslpkcs12-infile.pfx-outfile_ca.pem-cacerts-nokeys#ExtractPrivateKey(askforpassword)o
我正在尝试提取方括号内的内容。到目前为止,我一直在使用它,它有效,但我想知道我是否可以直接在正则表达式中使用某些东西,而不是使用这个删除功能。a="Thisissuchagreatday[coolawesome]"a[/\[.*?\]/].delete('[]')#=>"coolawesome" 最佳答案 差不多。a="Thisissuchagreatday[coolawesome]"a[/\[(.*?)\]/,1]#=>"coolawesome"a[/(?"coolawesome"第一个依赖于提取组而不是完全匹配;第二个利用前瞻和
我想编写一个ruby脚本来递归复制目录结构,但排除某些文件类型。因此,给定以下目录结构:folder1folder2file1.txtfile2.txtfile3.csfile4.htmlfolder2folder3file4.dll我想复制这个结构,但不包含.txt和.cs文件。因此,生成的目录结构应如下所示:folder1folder2file4.htmlfolder2folder3file4.dll 最佳答案 您可以使用查找模块。这是一个代码片段:require"find"ignored_extensions=[".cs"
对于我正在编写的Rails3应用程序,我正在考虑从本地文件系统上的XML、YAML或JSON文件中读取一些配置数据。重点是:我应该把这些文件放在哪里?Rails应用程序中是否有用于存储此类内容的默认位置?附带说明一下,我的应用程序部署在Heroku上。 最佳答案 我经常做的是:如果文件是通用配置文件:我在目录/config中创建一个YAML文件,每个环境有一个上层key如果我为每个环境(大项目)创建一个文件:我为每个环境创建一个YAML并将它们存储在/config/environments/然后我在加载YAML的地方创建了一个初始化
如何获取外部命令的输出并从中提取值?我有这样的东西:stdin,stdout,stderr,wait_thr=Open3.popen3("#{path}/foobar",configfile)if/exit0/=~wait_thr.value.to_srunlog.puts("Foobarexitednormally.\n")puts"Testcompleted."someoutputvalue=stdout.read("TX.*\s+(\d+)\s+")puts"Outputvalue:"+someoutputvalueend我没有在标准输出上使用正确的方法,因为Ruby告诉我它不能
在我的mac上安装几个东西时遇到这个问题,我认为这个问题来自将我的豹子升级到雪豹。我认为这个问题也与macports有关。/usr/local/lib/libz.1.dylib,filewasbuiltfori386whichisnotthearchitecturebeinglinked(x86_64)有什么想法吗?更新更具体地说,这发生在安装nokogirigem时日志看起来像:xslt_stylesheet.c:127:warning:passingargument1of‘Nokogiri_wrap_xml_document’withdifferentwidthduetoproto