es读写性能及优化
| 资源 | 数值 |
|---|---|
| 服务器 | 华为 |
| 系统 | centos7.9 |
| cpu | Intel® Core™ i5-10500 CPU @ 3.10GHz、6核12线程 |
| mem | 62G |
| disk | 机械硬盘、3.6T |
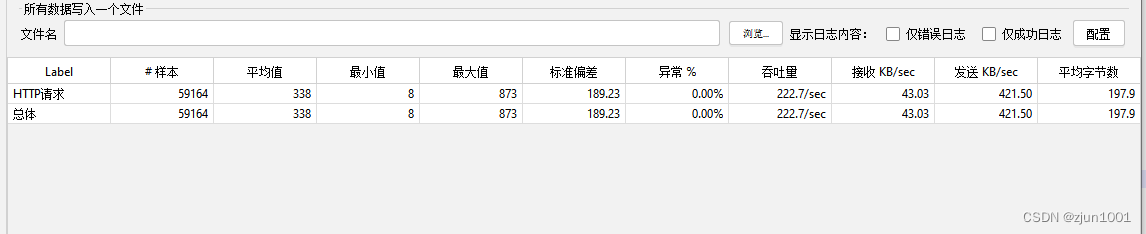
将es堆内存增大到20G,其余配置不做任何修改,数据单条写入。测试结果如下
| 线程 | 线程延迟时间(ms) | 数据量(W) | 平均响应时间(ms) | QPS |
|---|---|---|---|---|
| 300 | 0 | 5.9 | 338 | 222 |
| 300 | 0 | 81 | 369 | 217 |
附件一:
附件二:

从上面测试结果来看,在不做优化前提下,es并发写入单条耗时约在360ms。这个性能相比大多数场景都已满足,不过如果项目对数据存储和周转的实时性要求高,那么还是要对写入性能做优化。
方案一:业务优化
在业务上,最常见的优化手段就是变单条写入为批量写入。而es本身支持批量插入,就是bulk操作。我在第三章“Elasticsearch专栏-3.es基本用法-基础api”中也提到了bulk的使用方法。
本次测试,我的优化方式是:数据接入时,先不写库,而是直接推送到消息队列中(这里我使用的是rabbitmq)。然后监听该队列,批量拿消息。测试时,是一次拿去1000条。最后将这1000条数据批量写入es。实测结果是,1000条批量写入耗时和单条写入耗时相差不大。附图略。
除了按数量批量写入外,还可以按照时间。比如每秒写入一次,有多少数量就写入多少。其实这种方法应该更合理,像mysql底层数据和日志落盘的策略,其中就有每秒落盘一次的策略。上篇文章中,也做了图说明,有兴趣可以参考下。
方案二:底层优化
除了业务优化外,还有就是从底层优化。而底层优化,最常见的就是刷盘策略。因为我们都知道,正在的耗时就是磁盘IO。
这里我直接贴出优化的参数,如下:
| 参数 | 优化后值 | 含义 |
|---|---|---|
| index.refresh_interval | 10s | 缓存刷新时间,即10s后数据才能被搜索 |
| index.translog.durability | async | 异步 |
| index.translog.flush_threshold_size | 1024mb | translog大小达到多大时落盘 |
| index.translog.sync_interval | 30s | translog每隔多久落盘 |
其中,效果最明显的就是index.translog.durability。它表示的是日志持久化策略,默认情况下是同步策略,即写一条数据要等日志落盘后才返回。这种效率慢,但能保证数据安全性。
将index.translog.durability改为async后,就是异步策略。数据写入缓存后,里面返回,不会等待日志是否落盘成功。这种效率很快,但数据安全性差。
测试结果如下:(后台无报错,es入库数据量和jemter发送量一致)
| 线程 | 线程延迟时间(ms) | 数据量(W) | 平均响应时间(ms) | QPS |
|---|---|---|---|---|
| 500 | 100 | 1000 | 13 | 4100 |
附件:
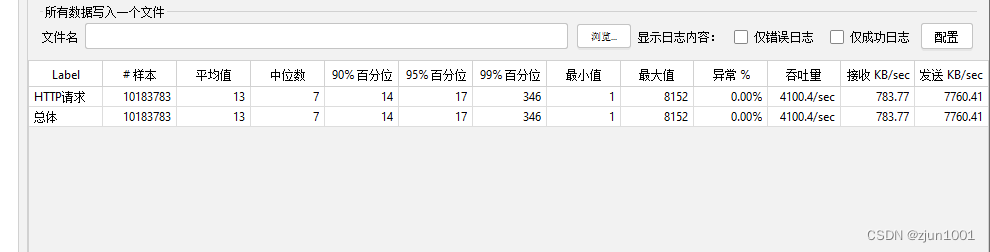
从上面测试结果来看,改同步为异步后,写入性能有了量级的提升。这个平均耗时(13ms)和吞吐量(4100)已经相当于消息队列了。
因为业务需要,有考虑从mysql切换到es。所以查询性能,我采用es和mysql做对比。数据量选用680w,1050w,2000w。查询内容包括:总和统计、多条件列表查询、分页查询、详情查询等多个维度。下面列出对比的数据。(数据结构和查询逻辑后续专门章节说明,本次只展示比对结果。)
1.总和统计耗时:ms
| 数据量 | 680w | 1050w | 2000w |
|---|---|---|---|
| es | 18 | 29 | 45 |
| mysql | 36 | 52 | 144 |
2.近5天数量趋势统计耗时:ms
| 数据量 | 680w | 1050w | 2000w |
|---|---|---|---|
| es | 71 | 62 | 450 |
| mysql | 2.7s | 4.2s | 8s |
3.分组统计耗时:ms
| 数据量 | 680w | 1050w | 2000w |
|---|---|---|---|
| es | 20 | 74 | 54 |
| mysql | 2.8s | 4.3s | 8.4s |
4.es列表查询及分页耗时:ms
| 数据量 | 第一页 | 第10页 | 第100页 | 第1000页 |
|---|---|---|---|---|
| 1050w | 79 | 35 | 30 | 34 |
5.详情查询耗时:ms
| 数据量 | 680w | 1050w | 2000w |
|---|---|---|---|
| es | 61 | 55 | 62 |
| mysql | 37 | 35 | 60 |
从对比结果来看,es整体性能要优于mysql。总结如下:
1.数据量从百万级到千万级,对es的查询耗时影响不大,基本每次查询都在几十毫秒。但对mysql影响很大,数据量越多,查询越慢,这也符合实际情况。
2.es分页没有想象的那样,越靠后翻页越慢。整个分页查询都很稳定。
3.查询单条数据时,mysql如果走索引情况下,速度是非常快的,有可能比es都要快。
4.总的来说,es的性能和稳定性要比mysql好。无论查询条件变化如何,数据量多少,es的查询耗时都不会相差很大。
cpu
| 线程 | 300t | 500t |
|---|---|---|
| es | 9% | 9% |
| mysql | 64% | 112% |
随着线程的增加,mysql占用CPU明显比es高
mem
| 数据量 | 680w | 1050w | 2000w |
|---|---|---|---|
| es | 23G | 23G | 23G |
| mysql | 24G | - | 48G |
随着压测数据量的增加,es内存并没有增大,而mysql增加了很多。因为mysql innodb_buff我设置的是40G,所以增加这么多内存也不难理解,都被mysql底层缓存占用了。
disk
| 数据量 | 680w | 1050w | 2000w |
|---|---|---|---|
| es | 2.1G | 2.9G | 5G |
| mysql | 1.9G | 2.7G | 5.3G |
从结果来看,mysql存储数据占用磁盘还是比es多。
总结:es对cpu、mem、disk等资源占用,相比mysql来说要少。
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
LL库和HAL库简介LL:Low-Layer,底层库HAL:HardwareAbstractionLayer,硬件抽象层库LL库和hal库对比,很精简,这实际上是一个精简的库。LL库的配置选择如下:在STM32CUBEMX中,点击菜单的“ProjectManager”–>“AdvancedSettings”,在下面的界面中选择“AdvancedSettings”,然后在每个模块后面选择使用的库总结:1、如果使用的MCU是小容量的,那么STM32CubeLL将是最佳选择;2、如果结合可移植性和优化,使用STM32CubeHAL并使用特定的优化实现替换一些调用,可保持最大的可移植性。另外HAL和L
是否存在GC.disable会降低性能的情况?只要我使用的是真正的RAM而不是交换内存,就可以这样做吗?我正在使用MRIRuby2.0,据我所知,它是64位的,并且使用的是64位的Ubuntu:ruby2.0.0p0(2013-02-24revision39474)[x86_64-linux]Linux[redacted]3.2.0-43-generic#68-UbuntuSMPWedMay1503:33:33UTC2013x86_64x86_64x86_64GNU/Linux 最佳答案 GC.disable将禁用垃圾回收。像rub