RepVGG是2021年发表于CVPR,它和resnet一样是一种图像分类网络,在目标检测中被用作backbone,论文提出一种新型技术称之结构重参数化,简单来说就是对训练出的模型进行等价替换成一个简单的模型,然后用这个简单的模型进行推理(也就是testing),目的就是加快推理速度,提高模型实用性。
论文地址:https://arxiv.org/abs/2101.03697
论文源码:https://github.com/megvii-model/RepVGG
目录
这两部分提出了RepVGG网络出现的背景以及大致功能优点,由于当前的网络架构都非常的庞大推理速度慢如ResNet-101,论文提出一个简单又高效的网络,推理时结构像VGG一样只有3x3卷积和ReLU,训练时有多个残差边。并且在ImageNet上的有一个非常不错的成绩

复杂的多分支模型虽然可以达到比较高的准确率,但是也有一些明显的缺点。1)会降低模型的推理速度并且减少内存利用率(后面会提到),2)有些节点会增加内存消耗并且对别的设备不友好。但是在工业中,VGG和ResNet还是非常的受欢迎。论文中提到,大部分学者提到FLOPs会影响推理速度,但是论文中作者做了实验发现FLOPs对模型的速度好像没太大关系,如RepVGG-B3的FLOPs比EfficientNet大但是Speed更快
针对以上缺点,作者提出decouple the training-time multi branch and inference-time plain architecture via structural re-parameterization,通过结构重参数化将训练多分支模型解耦成推理平滑模型,又因为推理模型结构和VGG很像被称之RepVGG,这个技术简单来说,因为模型是由一组参数构建而成,那么是否能够找出另一组参数与其效果相同,而新的这组参数对应的模型用于推理,这就是结构重参数化。
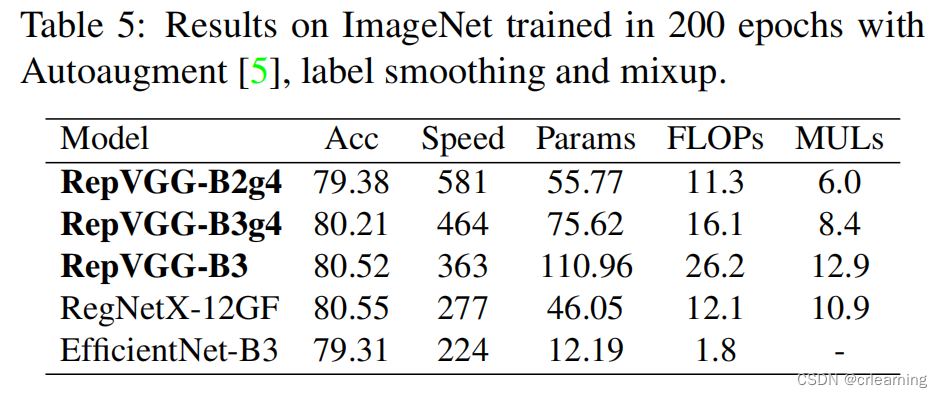
RepVGG沿用ResNet的残差边,只不过RepVGG在每一层都使用了残差连接,3x3卷积接上一个identity和1x1的卷积,图中B代表在训练时所使用的模型结构,图中C代表推理时所用的模型结构,在训练模型当中,在每一分支输出前加一个BN层,如何将B->C就是重参数化的重要体现,下面会谈到实现细节,先了解大概流程
1、网络从单一到多分支的发展)VGG是一种单路径网络结构也就是没有残差边,精度在当年也还不错,但是在ResNet和DenseNet提出后精度就被比下去了,但是想DenseNet超大型网络不一定能在普通GPU上训练,因此限制了它的实用性,此外还存在这推理速度慢的问题,并行度低。
2、单一模型训练的有效性)作者做了一些对比实验,在单一模型和多分支模型上,显然是多分支模型在训练上的效果更好并且预测结果更精确,因此作者设计网络时并没有抛弃多分支结构,而是在推理时将其融合成单一路径。
3、模型重参数化)作者提到在DiracNet当中使用的重参数化方式和RepVGG不同,DiracNet在训练时将网络进行调整,换句话说RepVGG训练时还是一个多分支结构,但是DiracNet不是。
4、为什么使用3x3卷积)在GPU上3x3卷积被封装优化,计算密度对比其他卷积高,作者也做了相关实验
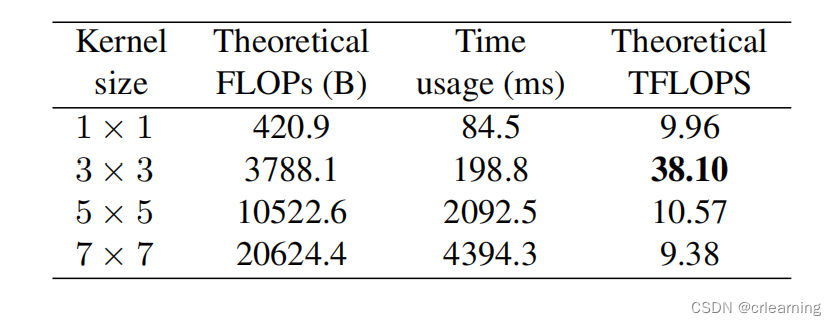
1)Fast,使用重参数化后,在推理上速度会有非常大的提升,并且有助于模型部署提高实用性。2)节省内存,采用多分支模型,在每次计算都需要多份内存分别保存每条分支的结果,所以导致内存消耗大

3)修改模型会更加方便,使用多分支存在一个问题,就是每条分支的输入通道和输出通道要保持一致,那么对模型的修改产生不便,如果是单路径就不存在这个问题
在上述提到,RepVGG在训练时每一层都有三个分支,分别是identify,1x1,3x3,模型训练时,输出,每一层就需要3个参数块,对于n层网络,就需要
个参数块。所以我们需要重参数化,会使得推理时模型参数量小。
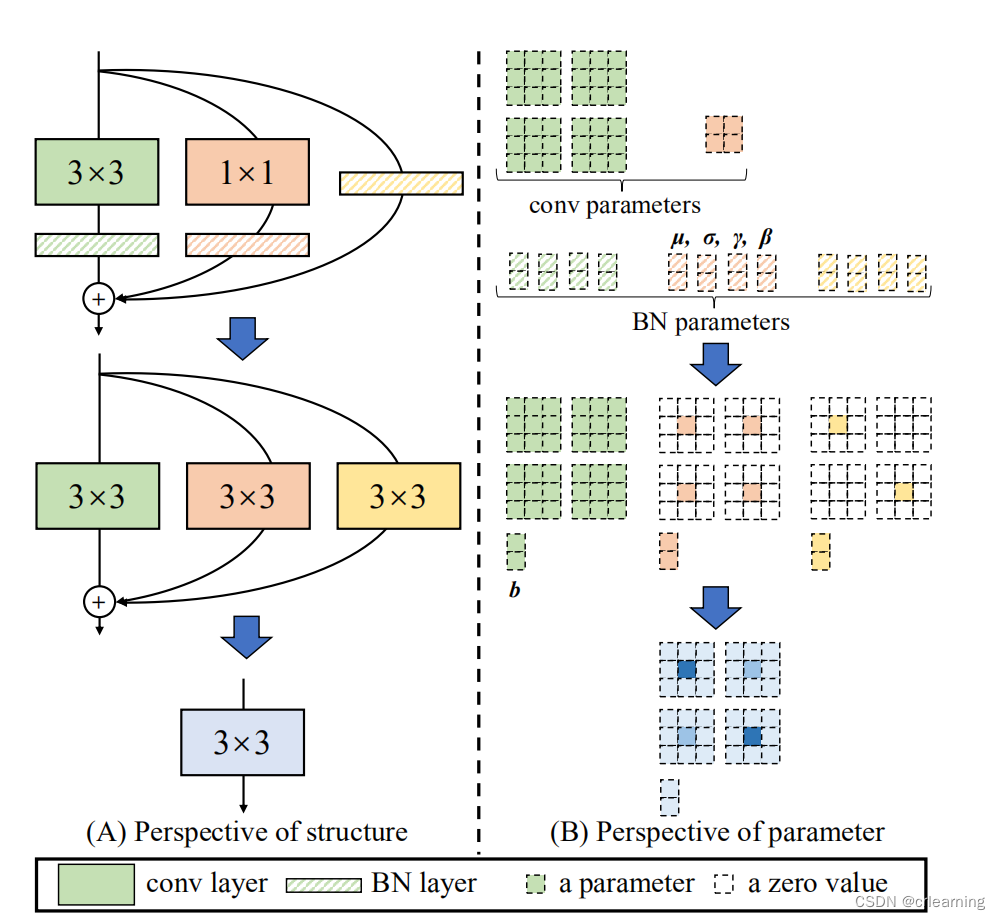
第一个问题,在每个卷积后都接上一个BN,怎么将卷积和BN融合。第二个问题,存在不同大小的卷积,怎么将几个不同大小的卷积融合在一起。
对于第一个问题,假如输入为M(1),卷积核为W,BN后的输出为:
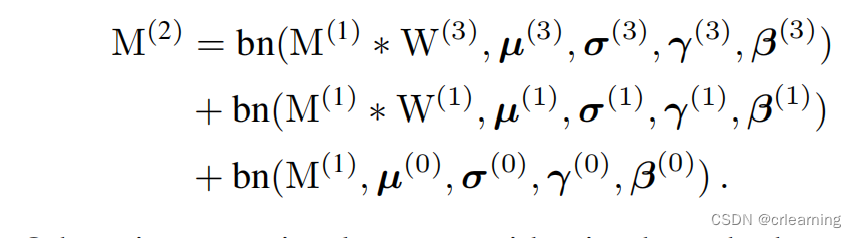
BN是怎么计算的:

提出其中的M特征图和偏移量:
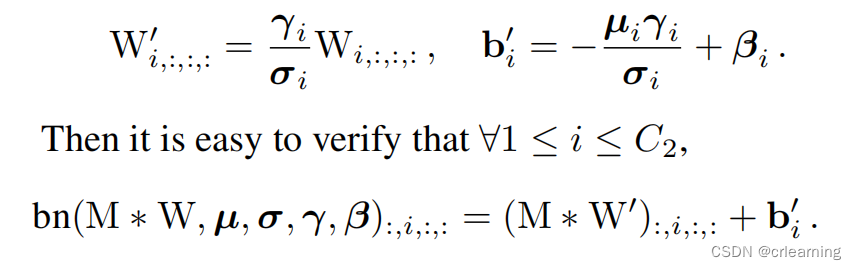
所以卷积加上BN等于三个卷积核的融合对M进行卷积再加上偏置
第二个问题,对于1x1的卷积,对1x1扩充为3x3,多余部分补0,而identify也可转化成1x1,所以将三个3x3累加就形成新的3x3卷积,至此完成整个重参数化操作
作者针对小模型和大模型对RepVGG进行设计,层数分别为[1, 2, 4, 14, 1]和[1, 4, 6, 16, 1],小模型称之RepVGG-A,大模型RepVGG-B,对于每层的通道数[64a, 128a, 256a, 512b],

为什么这样设计,作者提到因为第一层输入的图片分辨率高,所以通道数不能太大,可能导致计算量过大。最后stage设计了512b是因为最后只有一层,所以大一点有助于存储参数。其中在4stage中有14层block,这是借鉴ResNet的架构布局
作者提出7个模型和主流模型在Imagenet上进行对比: 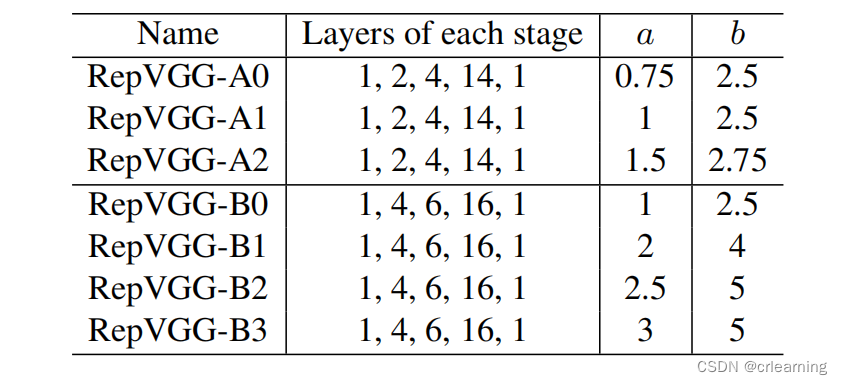
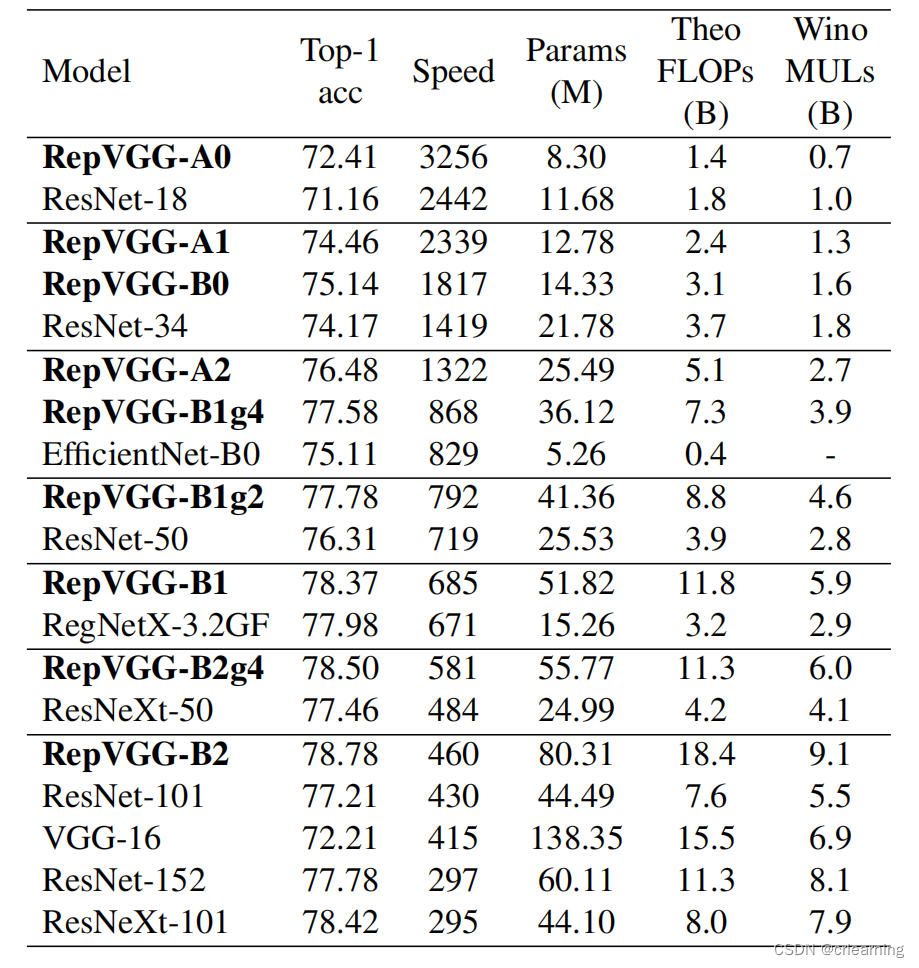
从实验可以看出,RepVGG的推理速度是比较快的,虽然参数比ResNet大,但是使用重参数化替换成推理模型,说明这个工作是非常有效果的。下图RepVGG-B0不做重参数化的速度,比起上图的速度有一个很大的降低,提升将近50%
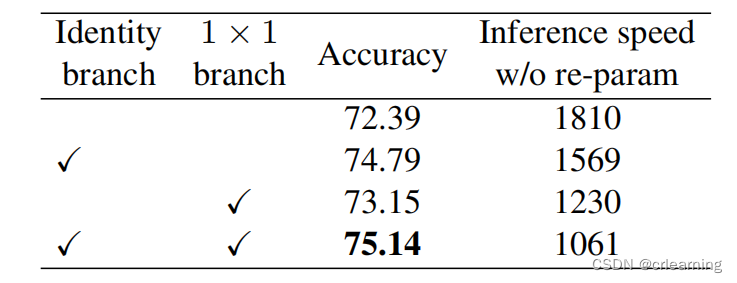
总之,RepVGG当中的结构重参数化这个方法值得我们去学习,对模型的部署非常友好,在未来的发展中,重参数化会越来越受欢迎(YOLOv6使用了这个方式)。
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
目录一、安装包链接二、安装详细步骤1.安装Wireshark和WinPcap2.安装OracleVMVirtualBox3.安装ensp三、安装后注册四、启动路由器出现40错误怎么解决一、安装包链接二、安装详细步骤链接:https://pan.baidu.com/s/1QbUUYMOMIV2oeIKHWP1SpA?pwd=xftx提取码:xftx1.安装Wireshark和WinPcap找到Wireshark安装包所在文件夹,双击它,按照以下步骤安装。2.安装OracleVMVirtualBox找到OracleVMVirtualBox安装包所在文件夹,双击它,按照以下步骤安装。注:可自定义安装
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
Nginx安装1.官网下载Nginx2.使用XShell和Xftp将压缩包上传到Linux虚拟机中3.解压文件nginx-1.20.2.tar.gz4.配置nginx5.启动nginx6.拓展(修改端口和常用命令)(一)修改nginx端口(二)常用命令1.官网下载Nginxhttp://nginx.org/en/download.html这里我下载的是1.20.2版本,大家按需下载对应稳定版即可2.使用XShell和Xftp将压缩包上传到Linux虚拟机中没有XShell可以参考《Linux操作系统CentOS7连接XShell》3.解压文件nginx-1.20.2.tar.gz1)检查是否存
HTTP缓存是指浏览器或者代理服务器将已经请求过的资源保存到本地,以便下次请求时能够直接从缓存中获取资源,从而减少网络请求次数,提高网页的加载速度和用户体验。缓存分为强缓存和协商缓存两种模式。一.强缓存强缓存是指浏览器直接从本地缓存中获取资源,而不需要向web服务器发出网络请求。这是因为浏览器在第一次请求资源时,服务器会在响应头中添加相关缓存的响应头,以表明该资源的缓存策略。常见的强缓存响应头如下所述:Cache-ControlCache-Control响应头是用于控制强制缓存和协商缓存的缓存策略。该响应头中的指令如下:max-age:指定该资源在本地缓存的最长有效时间,以秒为单位。例如:Ca