组成:由多个处理器及处理器处理标志串联组成
作用:常用于处理流水线事务,利用多个处理器对同一个对象进行处理,可以利用各处理器开关
场景:常见逻辑层处理逻辑:获取参数、fetch数据、逻辑处理数据、返回参数一系列数据处理
优点:将复杂的流水线处理逻辑简化为一个个单元,操作较为便捷,可以随意在处理器之间串联穿插新处理器

package burden_chain
import "fmt"
/*
责任链模式
组成:由多个处理器及处理器处理标志串联组成
作用:常用于处理流水线事务,利用多个处理器对同一个对象进行处理,可以利用各处理器开关
场景:常见的获取参数、fetch数据、逻辑处理数据、返回参数一系列数据连续化处理
优点:将复杂的流水线处理逻辑简化为一个个单元,操作较为便捷,可以随意在处理器之间串联穿插新处理器
*/
// CalProcessor 处理器抽象接口
type CalProcessor interface {
SetNextProcessor(processor CalProcessor)
ProcessFor(calIdentity *CalIdentity)
}
// CalIdentity 处理对象实体
type CalIdentity struct {
A int
B int
sum int
hasGetA bool // GetAProcessor开关:是否获取到A
hasGetB bool // GetBProcessor开关:是否获取到B
hasAdd bool // SumProcessor开关:A与B是否相加
isComplete bool // CompleteProcessor开关:完成计算
}
// baseCalProcessor 基类实现CalProcessor
type baseCalProcessor struct {
nextCalProcessor CalProcessor
}
// SetNextProcessor 用于串联处理器
func (b *baseCalProcessor) SetNextProcessor(processor CalProcessor) {
b.nextCalProcessor = processor
}
// ProcessFor 用于承接处理器的执行逻辑
func (b *baseCalProcessor) ProcessFor(calIdentity *CalIdentity) {
if b.nextCalProcessor != nil {
b.nextCalProcessor.ProcessFor(calIdentity)
}
}
// GetAProcessor 获取数字A处理器
type GetAProcessor struct {
baseCalProcessor
}
func (g *GetAProcessor) ProcessFor(calIdentity *CalIdentity) {
if !calIdentity.hasGetA {
fmt.Println("getting number A.")
}
fmt.Println("A")
calIdentity.hasGetA = true
g.nextCalProcessor.ProcessFor(calIdentity)
}
// GetBProcessor 获取数字B处理器
type GetBProcessor struct {
baseCalProcessor
}
func (g *GetBProcessor) ProcessFor(calIdentity *CalIdentity) {
if !calIdentity.hasGetA {
fmt.Println("didn't get number A.")
return
}
fmt.Println("B")
calIdentity.hasGetB = true
g.nextCalProcessor.ProcessFor(calIdentity)
}
// SumProcessor 加法处理器
type SumProcessor struct {
baseCalProcessor
}
func (g *SumProcessor) ProcessFor(calIdentity *CalIdentity) {
if !calIdentity.hasGetA || !calIdentity.hasGetB {
fmt.Println("didn't get number A or B")
return
}
fmt.Println("A plus B")
calIdentity.hasAdd = true
g.nextCalProcessor.ProcessFor(calIdentity)
}
// CompleteProcessor 完成处理器
type CompleteProcessor struct {
baseCalProcessor
}
func (c *CompleteProcessor) ProcessFor(calIdentity *CalIdentity) {
if !calIdentity.hasGetA || !calIdentity.hasGetB || !calIdentity.hasAdd {
fmt.Println("cal not done.")
return
}
fmt.Println("done")
calIdentity.isComplete = true
return
}
测试类
package burden_chain
import "testing"
func TestChainResponsibility(t *testing.T) {
calProcessor := BuildCalProcessorChain()
calIdentity := &CalIdentity{
A: 0,
B: 0,
sum: 0,
hasGetA: false,
hasGetB: true,
hasAdd: false,
isComplete: false,
}
calProcessor.ProcessFor(calIdentity)
}
// BuildCalProcessorChain: GetAProcessor -> GetBProcessor -> SumProcessor -> CompleteProcessor
func BuildCalProcessorChain() CalProcessor {
completeCheckNode := &CompleteProcessor{}
sumCheckNode := &SumProcessor{}
sumCheckNode.SetNextProcessor(completeCheckNode)
getBCheckNode := &GetBProcessor{}
getBCheckNode.SetNextProcessor(sumCheckNode)
getACheckNode := &GetAProcessor{}
getACheckNode.SetNextProcessor(getBCheckNode)
return getACheckNode
}
组成:接受者、指令触发器
作用:将请求方法参数化,将指令抽象,便于在指令与指令之间建立独立的逻辑操作关系
场景:适用于任务定制需求,比如818活动等等,在特点的时间节点,使用特定的功能需求。
优点:将指令单元化,通过统一的的Execute接口方法进行调用,屏蔽各个请求的差异,便于多命令组装、回滚,屏蔽各个请求的差异

接受者
package order_pattern
type ReceiverA struct {
height int
width int
}
func (s *ReceiverA) SetHeight(height int) {
s.height = height
}
func (s *ReceiverA) SetWidth(width int) {
s.width = width
}
func (s *ReceiverA) Shutdown() string {
return "shut down this formulation."
}
指令触发器
package order_pattern
import "fmt"
/*
命令模式
组成:接受者、指令触发器
作用:将请求方法参数化,将指令抽象,便于在指令与指令之间建立独立的逻辑操作关系
优点:将指令单元化,通过统一的的Execute接口方法进行调用,屏蔽各个请求的差异,便于多命令组装、回滚,屏蔽各个请求的差异
*/
type CalCommand interface {
Execute() string
}
// CalCircleCommand 计算周长
type CalCircleCommand struct {
receiver *ReceiverA
}
// 指令将接受者内嵌
func NewCalCircleCommand(receiver *ReceiverA) *CalCircleCommand {
return &CalCircleCommand{receiver: receiver}
}
// 利用各个指令内置方法,将不同指令的执行过程屏蔽,便于扩展
func (c *CalCircleCommand) Execute() string {
c.receiver.SetWidth(2)
c.receiver.SetHeight(3)
return fmt.Sprintf("the circle of receiver is %.2f", float64(2*(c.receiver.width+c.receiver.height)))
}
// CalAreaCommand 计算面积
type CalAreaCommand struct {
receiver *ReceiverA
}
func NewCalAreaCommand(receiver *ReceiverA) *CalAreaCommand {
return &CalAreaCommand{receiver: receiver}
}
func (c *CalAreaCommand) Execute() string {
c.receiver.SetWidth(2)
c.receiver.SetHeight(3)
return fmt.Sprintf("the area of receiver is %.2f", float64(c.receiver.height*c.receiver.width))
}
type CommandInvoker struct {
calCommand CalCommand
}
func (c *CommandInvoker) SetCommand(calCommand CalCommand) {
c.calCommand = calCommand
}
func (c *CommandInvoker) ExecuteCommand() string {
return c.calCommand.Execute()
}
测试类
package order_pattern
import (
"fmt"
"testing"
)
func TestOrderPattern(t *testing.T) {
receiver := new(ReceiverA)
commandInvoker := new(CommandInvoker)
circleCommand := NewCalCircleCommand(receiver)
commandInvoker.SetCommand(circleCommand)
fmt.Println(commandInvoker.ExecuteCommand())
areaCommand := NewCalAreaCommand(receiver)
commandInvoker.SetCommand(areaCommand)
fmt.Println(commandInvoker.ExecuteCommand())
}
组成:创建迭代器的工厂方法接口Iterable、迭代器本身本身的接口memberIterator
作用:用于在不暴露集合底层表现形式的情况下遍历集合中的所有元素,即在迭代器的帮助下,客户端可以用一个迭代器接口以相似的方法遍历不同集合中的元素
场景:适用于为迭代遍历来自两个及以上不同类型的集合中的元素,无视集合的底层类型,只通过暴露出的Next和HasNext来访问元素
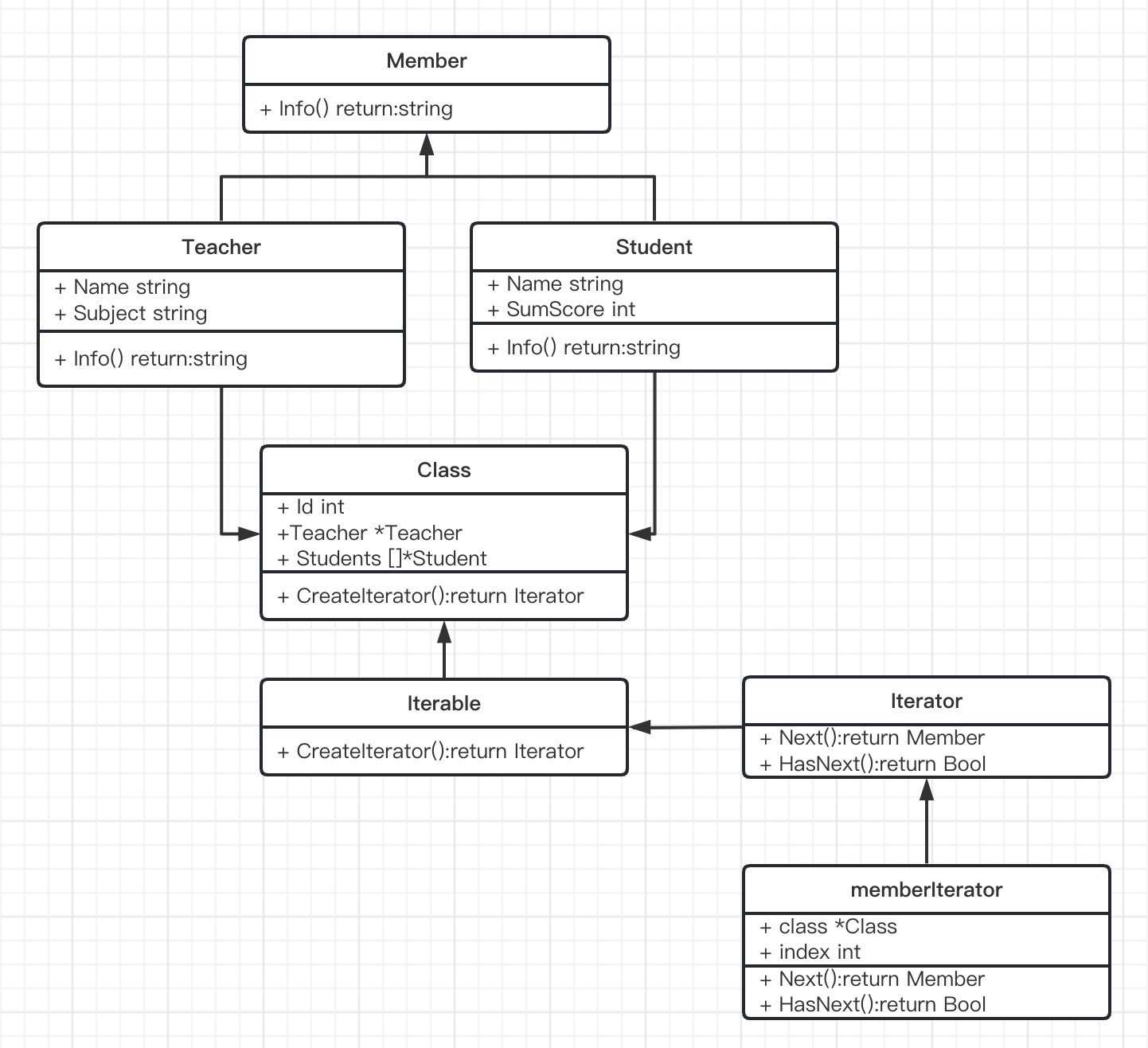
实体类
package iterator_pattern
import "fmt"
// Member 成员抽象接口
type Member interface {
Info() string
}
// Teacher 教师实体
type Teacher struct {
Name string
Subject string
}
// NewTeacher 创建教师实体
func NewTeacher(name, subject string) *Teacher {
return &Teacher{
Name: name,
Subject: subject,
}
}
// Info 返回教师信息
func (t *Teacher) Info() string {
return fmt.Sprintf("%s老师负责的科目-%s", t.Name, t.Subject)
}
// Student 学生实体
type Student struct {
Name string
SumScore int
}
// NewStudent 创建学生实体
func NewStudent(name string, score int) *Student {
return &Student{
Name: name,
SumScore: score,
}
}
// Info 返回学生信息
func (s *Student) Info() string {
return fmt.Sprintf("%s同学考试分数:%d", s.Name, s.SumScore)
}
迭代器
package iterator_pattern
/*
迭代器模式
组成:创建迭代器的工厂方法接口Iterable、迭代器本身本身的接口memberIterator
作用:用于在不暴露集合底层表现形式的情况下遍历集合中的所有元素,即在迭代器的帮助下,客户端可以用一个迭代器接口以相似的方法遍历不同集合中的元素
场景:适用于为迭代遍历来自两个及以上不同类型的集合中的元素,无视集合的底层类型,只通过暴露出的Next和HasNext来访问元素
*/
// Iterator 迭代器抽象接口
type Iterator interface {
Next() Member
HasNext() bool
}
// memberIterator 迭代器实现类
type memberIterator struct {
class *Class
index int
}
// Next 获取迭代器中的下一个元素
func (m *memberIterator) Next() Member {
if m.index == -1 { // 若游标是-1,则返回老师
m.index++
return m.class.Teacher
}
student := m.class.Students[m.index] // 游标大于等于0,则返回学生
m.index++
return student
}
// HasNext 判断是否存在下一个元素
func (m *memberIterator) HasNext() bool { // 判断是否还有剩余需要迭代的元素
return m.index < len(m.class.Students)
}
// Iterable 可迭代集合接口,实现此接口返回迭代器
type Iterable interface {
CreateIterator() Iterator
}
// Class 包括班级id、老师和同学
type Class struct {
Id int
Teacher *Teacher
Students []*Student
}
// NewClass 根据班级id、老师创建班级
func NewClass(id int, teacherName, subject string) *Class {
return &Class{
Id: id,
Teacher: NewTeacher(teacherName, subject),
}
}
// GetClassID 获取班级id
func (c *Class) GetClassID() int {
return c.Id
}
// AddStudent 增加学生
func (c *Class) AddStudent(students ...*Student) {
c.Students = append(c.Students, students...)
}
// CreateIterator 创建班级迭代器
// 迭代器两要素:班级实体、迭代索引
func (c *Class) CreateIterator() Iterator {
return &memberIterator{
class: c, // 待迭代容器
index: -1, // 迭代索引初始化为-1,从老师开始迭代
}
}
测试类
package iterator_pattern
import (
"fmt"
"testing"
)
func TestIterator(t *testing.T) {
class := NewClass(1, "cjh", "CS")
class.AddStudent(NewStudent("张三", 410),
NewStudent("李四", 400))
fmt.Printf("%d班级成员如下:\n", class.GetClassID())
classIterator := class.CreateIterator()
for classIterator.HasNext() {
member := classIterator.Next()
fmt.Println(member.Info())
}
}
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我将应用程序升级到Rails4,一切正常。我可以登录并转到我的编辑页面。也更新了观点。使用标准View时,用户会更新。但是当我添加例如字段:name时,它不会在表单中更新。使用devise3.1.1和gem'protected_attributes'我需要在设备或数据库上运行某种更新命令吗?我也搜索过这个地方,找到了许多不同的解决方案,但没有一个会更新我的用户字段。我没有添加任何自定义字段。 最佳答案 如果您想允许额外的参数,您可以在ApplicationController中使用beforefilter,因为Rails4将参数
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
我在我的项目中有一个用户和一个管理员角色。我使用Devise创建了身份验证。在我的管理员角色中,我没有任何确认。在我的用户模型中,我有以下内容:devise:database_authenticatable,:confirmable,:recoverable,:rememberable,:trackable,:validatable,:timeoutable,:registerable#Setupaccessible(orprotected)attributesforyourmodelattr_accessible:email,:username,:prename,:surname,:
我经常迷上ruby的一件事是递归模式。例如,假设我有一个数组,它可能包含无限深度的数组作为元素。所以,例如:my_array=[1,[2,3,[4,5,[6,7]]]]我想创建一个方法,可以将数组展平为[1,2,3,4,5,6,7]。我知道.flatten可以完成这项工作,但这个问题是作为我经常遇到的递归问题的一个例子-因此我试图找到一个更可重用的解决方案。简而言之-我猜这种事情有一个标准模式,但我想不出任何特别优雅的东西。任何想法表示赞赏 最佳答案 递归是一种方法,它不依赖于语言。您在编写算法时要考虑两种情况:再次调用函数的情