我说下我的版本,首先要安装
mysql5.6
es 7.12
es-head
canal-adapter 1.1.5
canal-deployer1.1.5
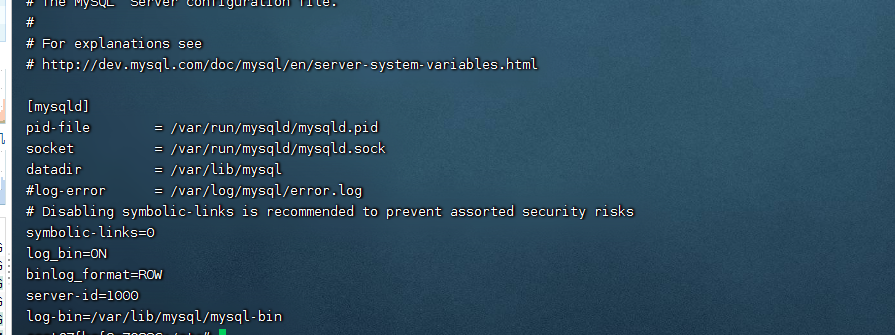
第一步: 安装mysql 修改mysql配置文件 开启binlog日志,并且以ROW方式,开启主从模式 以及logbin的文件位置
log_bin=ON
binlog_format=ROW
server-id=1000
log-bin=/var/lib/mysql/mysql-bin记得重新启动mysql
创建一个给canal用的一个用户
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;查看值得配置是否开启
SHOW VARIABLES LIKE 'binlog-format'; -- 结果应该是ROW
SHOW VARIABLES LIKE 'log_bin'; -- 结果应该是 ON
SHOW VARIABLES LIKE '%log%'; -- 所有binlog信息创建一个库和一个测试表,为了去canal同步到es 的一个测试表
-- 库的名称为 canal-test
-- 表
CREATE TABLE `product` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`title` varchar(255) DEFAULT NULL,
`sub_title` varchar(255) DEFAULT NULL,
`price` decimal(10,2) DEFAULT NULL,
`pic` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC
-- 加入数据
INSERT INTO product ( id, title, sub_title, price, pic ) VALUES ( 7, '小米8', ' 全面屏游戏智能手机 6GB+64GB', 1999.00, NULL );
INSERT INTO product ( id, title, sub_title, price, pic ) VALUES ( 8, '小米8', ' 全面屏游戏智能手机 6GB+64GB', 1999.00, NULL );
INSERT INTO product ( id, title, sub_title, price, pic ) VALUES ( 9, '小米8', ' 全面屏游戏智能手机 6GB+64GB', 1999.00, NULL );
INSERT INTO product ( id, title, sub_title, price, pic ) VALUES ( 10, '小米8', ' 全面屏游戏智能手机 6GB+64GB', 1999.00, NULL );第二步: 安装es 和es-header ,具体在之前的一篇文章中;https://www.jianshu.com/p/a542a11debf6
第三步: 下载canal 的两个文件,并上传的服务器解压
canal下载地址: https://github.com/alibaba/canal/releases
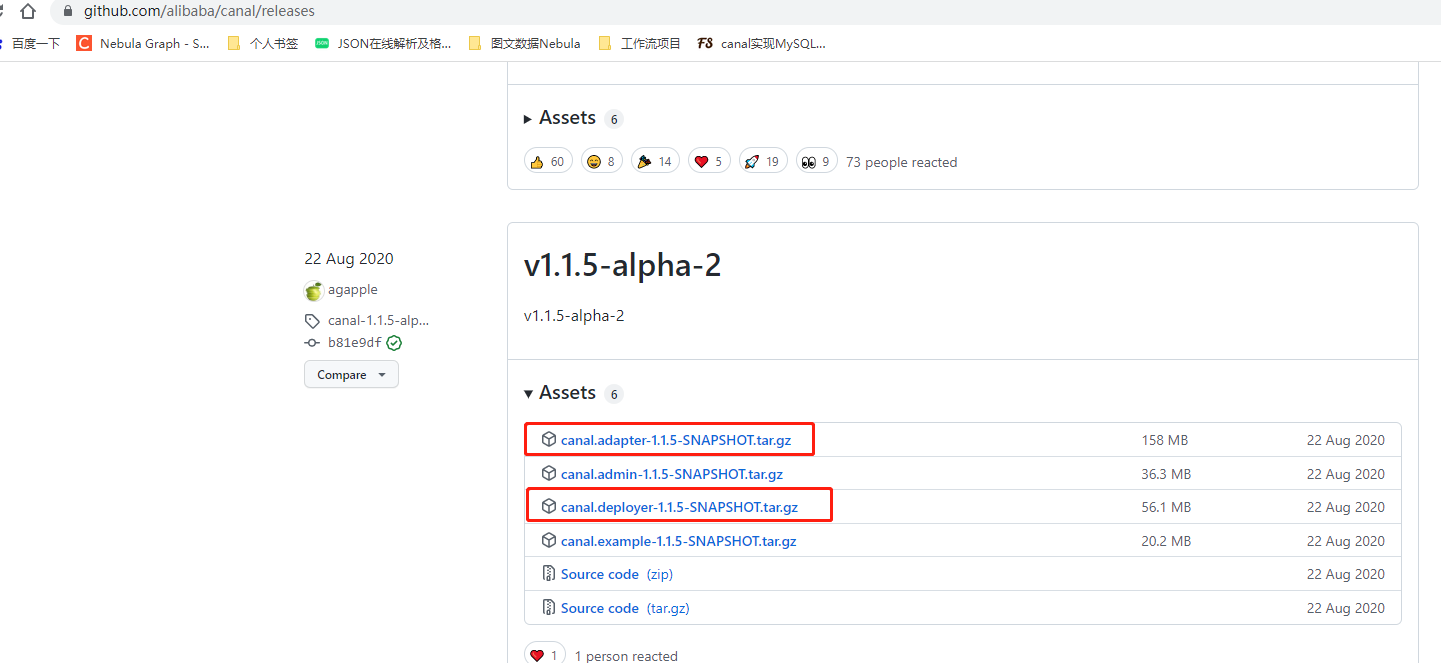
下载完成后,上传到服务器解压,分别为解压文件位置
第四步: 配置cancel 关键步骤!!!!
1 解压canal.deployer-1.1.5 到 /opt/canal-server 后目录为
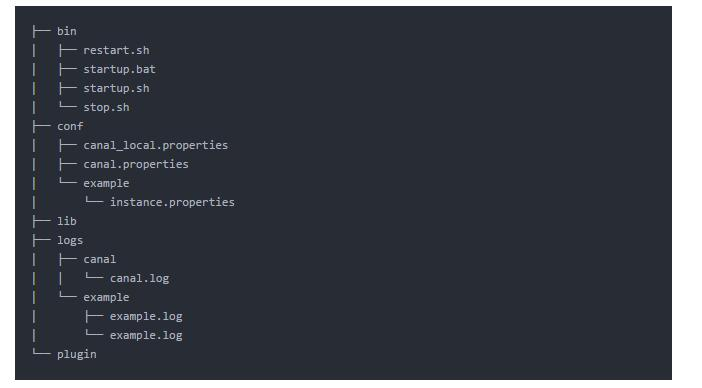
修改配置文件conf/example/instance.properties,按如下配置即可,主要是修改数据库相关配置;
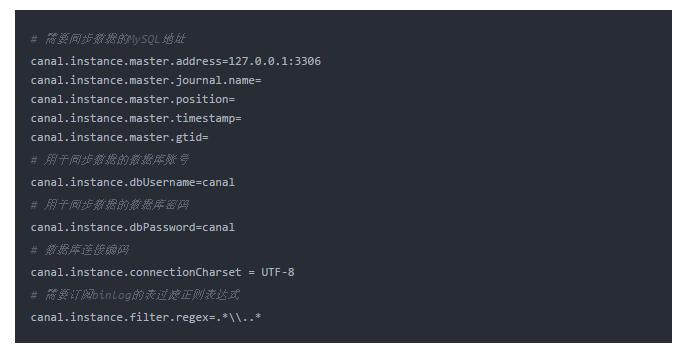
由于我都是安装在同一台机器上,所以为127.0.0.1:3306
进入 当前的bin文件下 运行命令,启动canal服务
sh startup.sh2 解压 canal.adapter-1.1.5 到 /opt/canal-adpter 目录为
修改配置文件conf/application.yml,按如下配置即可,主要是修改canal-server配置、数据源配置和客户端适配器配置;
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
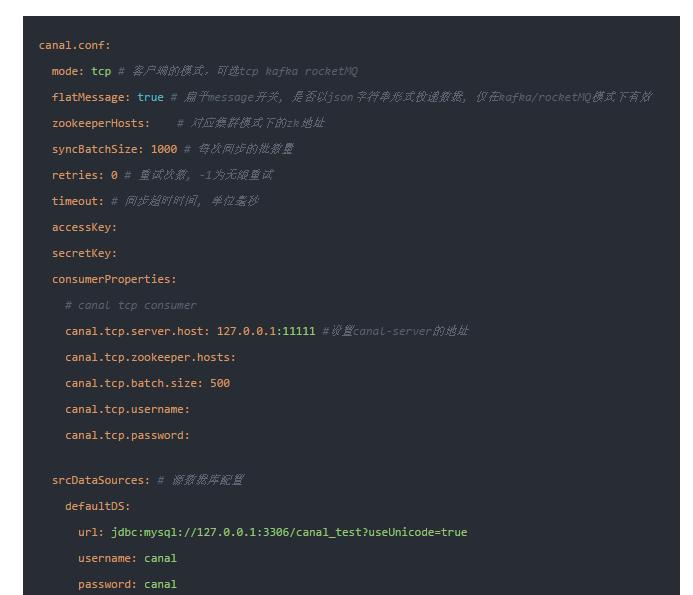
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
zookeeperHosts:
syncBatchSize: 1000
retries: 0
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: 127.0.0.1:11111
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
# kafka consumer
kafka.bootstrap.servers: 127.0.0.1:9092
kafka.enable.auto.commit: false
kafka.auto.commit.interval.ms: 1000
kafka.auto.offset.reset: latest
kafka.request.timeout.ms: 40000
kafka.session.timeout.ms: 30000
kafka.isolation.level: read_committed
kafka.max.poll.records: 1000
# rocketMQ consumer
rocketmq.namespace:
rocketmq.namesrv.addr: 127.0.0.1:9876
rocketmq.batch.size: 1000
rocketmq.enable.message.trace: false
rocketmq.customized.trace.topic:
rocketmq.access.channel:
rocketmq.subscribe.filter:
# rabbitMQ consumer
rabbitmq.host:
rabbitmq.virtual.host:
rabbitmq.username:
rabbitmq.password:
rabbitmq.resource.ownerId:
srcDataSources:
defaultDS:
url: jdbc:mysql://127.0.0.1:3306/canal-test?useUnicode=true
username: canal
password: canal
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
# - name: es7
# key: mysql1
# properties:
# jdbc.driverClassName: com.mysql.jdbc.Driver
# jdbc.url: jdbc:mysql://127.0.0.1:3306/mytest2?useUnicode=true
# jdbc.username: root
# jdbc.password: 121212
# - name: rdb
# key: oracle1
# properties:
# jdbc.driverClassName: oracle.jdbc.OracleDriver
# jdbc.url: jdbc:oracle:thin:@localhost:49161:XE
# jdbc.username: mytest
# jdbc.password: m121212
# - name: rdb
# key: postgres1
# properties:
# jdbc.driverClassName: org.postgresql.Driver
# jdbc.url: jdbc:postgresql://localhost:5432/postgres
# jdbc.username: postgres
# jdbc.password: 121212
# threads: 1
# commitSize: 3000
# - name: hbase
# properties:
# hbase.zookeeper.quorum: 127.0.0.1
# hbase.zookeeper.property.clientPort: 2181
# zookeeper.znode.parent: /hbase
- name: es7
hosts: 127.0.0.1:9200 # 127.0.0.1:9200 for rest mode
properties:
mode: rest # or rest
# # security.auth: test:123456 # only used for rest mode
cluster.name: docker-cluster
# - name: kudu
# key: kudu
# properties:
# kudu.master.address: 127.0.0.1 # ',' split multi address下面是配置说明
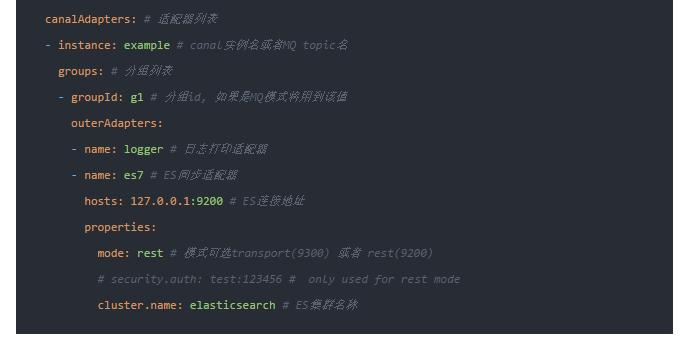
配置重点 一个是 jdbc:mysql://127.0.0.1:3306/canal-test?useUnicode=true 中的 数据库名称
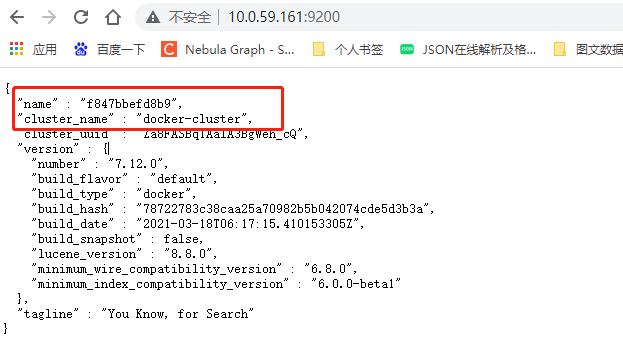
第二个是es集群名称根据自己的实际的配置,我的是 docker-cluster
第三个 - name: es7 这个很重要一会儿要用
其他全部照搬即可
添加配置文件canal-adapter/conf/es7/product.yml,用于配置MySQL中的表与Elasticsearch中索引的映射关系;
dataSourceKey: defaultDS
destination: example
groupId: g1
esMapping:
_index: canal_product
_id: id
sql: "SELECT
p.id,
p.title,
p.sub_title,
p.price,
p.pic
FROM`product` p"
etlCondition: "where p.id > {}"
commitBatch: 30其中 _index: canal_product 为要在es中创建的索引名称,很重要
_id: id 其中的id很重要 需要与 sql语句中的 p.id 中的id一致
etlCondition: "where p.id > {} 这个 {} 为入参 后续同步重要接受参数
至此,配置完毕,启动canal-adapter,
执行 sh startup.sh接下来,在es中创建相应索引
put http://10.0.59.161:9200/canal_product
入参body
{
"mappings":{
"properties":{
"title":{
"type":"text"
},
"sub_title":{
"type":"text"
},
"pic":{
"type":"text"
},
"price":{
"type":"double"
}
}
}
}访问截图
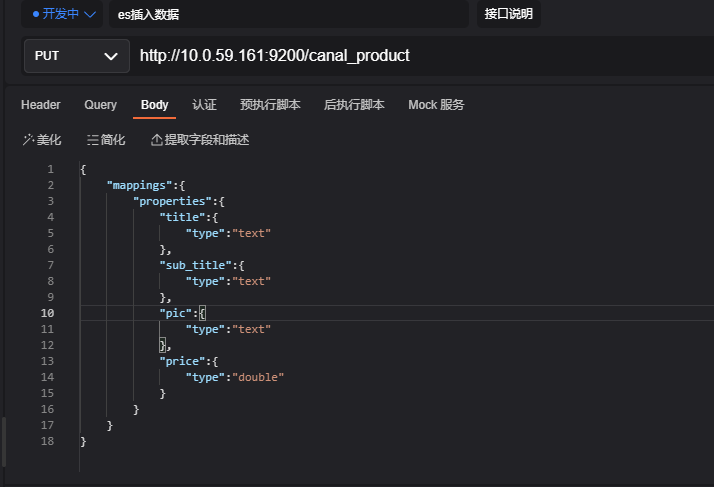
与数据库字段一一对应,所以名称与之前配置的 canal_product 必须一致
至此全部配置完毕
接下来,看着canal-adapter 的日志
在mysql数据库中反复执行 删除数据,添加数据操作
可以看到 canal-adapter 中已经接受到了mysql 的dml操作语句!!!!!!!
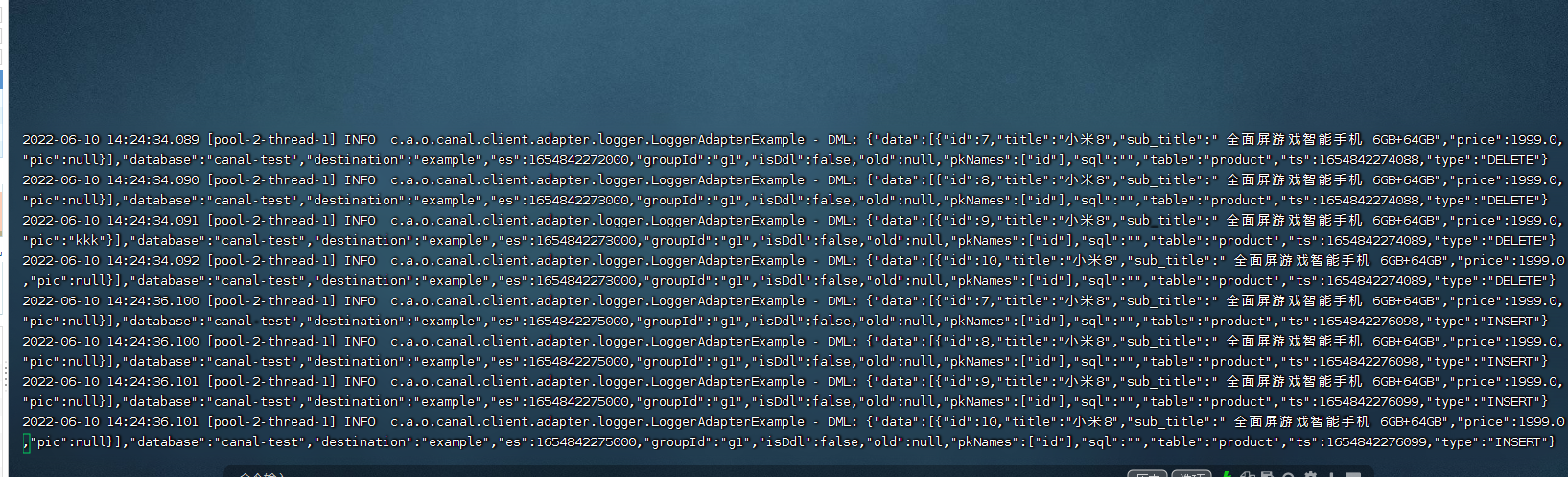
接下来,通过命令触发,让canal-adapter读取到的dml日志,同步到es的库中;
curl http://127.0.0.1:8081/etl/es7/product.yml -X POST -d "params=1"etl 固定的
es7 之前起的名字必须对应,后续配置文件也在这里面
product.yml 配置文件名称
-d "params=1" 同步数据的条件 1 入参
查看es中的数据
get http://10.0.59.161:9200/canal_product/_search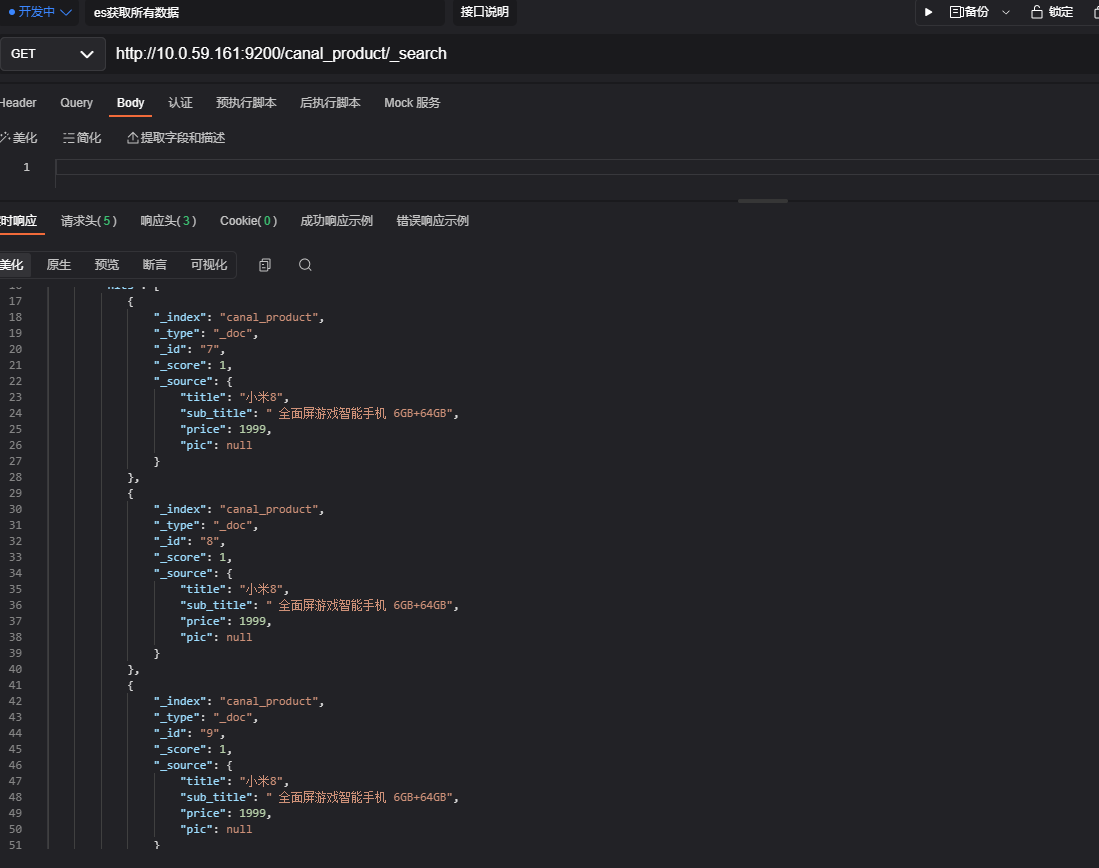
可以看到es中已经同步到了mysql数据;
哇哇哇~~~~~~~~~~~~~~~~~~~~~~~~~~~至此,大功告成!!!!!!!!!!!!!!!!!!!!!!!!!
说实话这次实践遇到了很多问题
1 docker 中vim是没有的要安装
2 es-header 和es链接是要配置跨域的
3 canal 的 数据同步不是自动的,需要触发!!!!!!!!!!!!!
3 canal 的配置很复杂~~一个不小心就会导致同步数据的时候错误,要很小心
4 当看到canal-adapter的日志中有mysql的dml日志的时候,说明已经离成功很近了
5 当触发同步的时候报错, 找不到任务,仔细检查触发中与配置相关的每一个,一定是哪里错了
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
我在理解Enumerator.new方法的工作原理时遇到了一些困难。假设文档中的示例:fib=Enumerator.newdo|y|a=b=1loopdoy[1,1,2,3,5,8,13,21,34,55]循环中断条件在哪里,它如何知道循环应该迭代多少次(因为它没有任何明确的中断条件并且看起来像无限循环)? 最佳答案 Enumerator使用Fibers在内部。您的示例等效于:require'fiber'fiber=Fiber.newdoa=b=1loopdoFiber.yieldaa,b=b,a+bendend10.times.m
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
从MB升级到新的MBP后,Apple的迁移助手没有移动我的gem。我这次是通过macports安装rubygems,希望在下次升级时避免这种情况。有什么我应该注意的陷阱吗? 最佳答案 如果你想把你的gems安装在你的主目录中(在传输过程中应该复制过来,作为一个附带的好处,会让你以你自己的身份运行geminstall,而不是root),将gemhome:键设置为您在~/.gemrc中的主目录中的路径. 关于通过MacPorts的RubyGems是个好主意吗?,我们在StackOverf
当我执行>rvminstall1.9.2时一切顺利。然后我做>rvmuse1.9.2也很顺利。但是当涉及到ruby-v时..sam@sjones:~$rvminstall1.9.2/home/sam/.rvm/rubies/ruby-1.9.2-p136,thismaytakeawhiledependingonyourcpu(s)...ruby-1.9.2-p136-#fetchingruby-1.9.2-p136-#downloadingruby-1.9.2-p136,thismaytakeawhiledependingonyourconnection...%Total%Rece