目录
书接上篇Spring Batch批处理-作业Job简介,上篇带小伙伴们了解色作业Job对象,那这篇就看一下作业参数是啥一回事,同时要怎么设置参数并获取参数的。
前面提到,作业的启动条件是作业名称 + 识别参数,Spring Batch使用JobParameters类来封装了所有传给作业参数。
看下JobParameters 源码
public class JobParameters implements Serializable {
private final Map<String,JobParameter> parameters;
public JobParameters() {
this.parameters = new LinkedHashMap<>();
}
public JobParameters(Map<String,JobParameter> parameters) {
this.parameters = new LinkedHashMap<>(parameters);
}
.....
}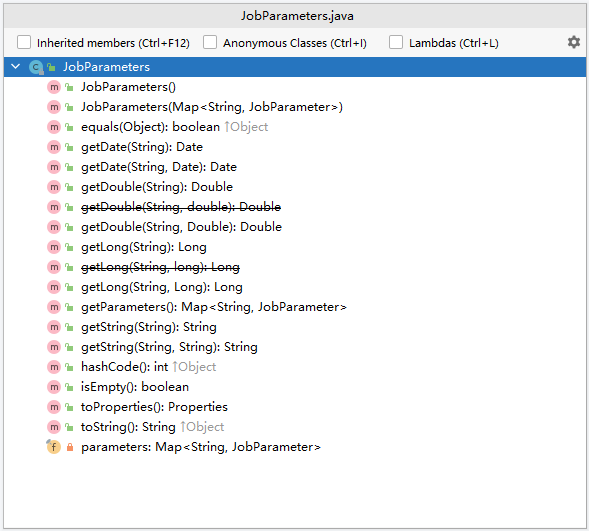
从上面代码/截图来看,JobParameters 类底层维护了Map<String,JobParameter>,是一个Map集合的封装器,提供了不同类型的get操作。
回顾Spring Batch 入门案例,我们通过debug可以看到,job作业最终是执行靠的JobLauncher(job启动器)接口的实现类:SimpleJobLauncher run方法启动。
JobLauncher启动器接口run方法约定:
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters) throws JobExecutionAlreadyRunningException,
JobRestartException, JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}在JobLauncher 启动器执行run方法时,直接传入即可。
jobLauncher.run(job, params);目前我们使用SpringBoot 方式启动Spring Batch那该怎么传值呢?
1>定义ParamJob类,准备好要执行的job
package com.langfeiyes.batch._02_params;
import org.springframework.batch.core.*;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
@EnableBatchProcessing
public class ParamJob {
//job构造器工厂
@Autowired
private JobBuilderFactory jobBuilderFactory;
//step构造器工厂
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public Tasklet tasklet(){
return new Tasklet() {
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
System.out.println("param SpringBatch....");
return RepeatStatus.FINISHED;
}
};
}
@Bean
public Step step1(){
return stepBuilderFactory.get("step1")
.tasklet(tasklet())
.build();
}
@Bean
public Job job(){
return jobBuilderFactory.get("param-job")
.start(step1())
.build();
}
public static void main(String[] args) {
SpringApplication.run(HelloJob.class, args);
}
}2>使用idea的命令传值的方式设置job作业参数
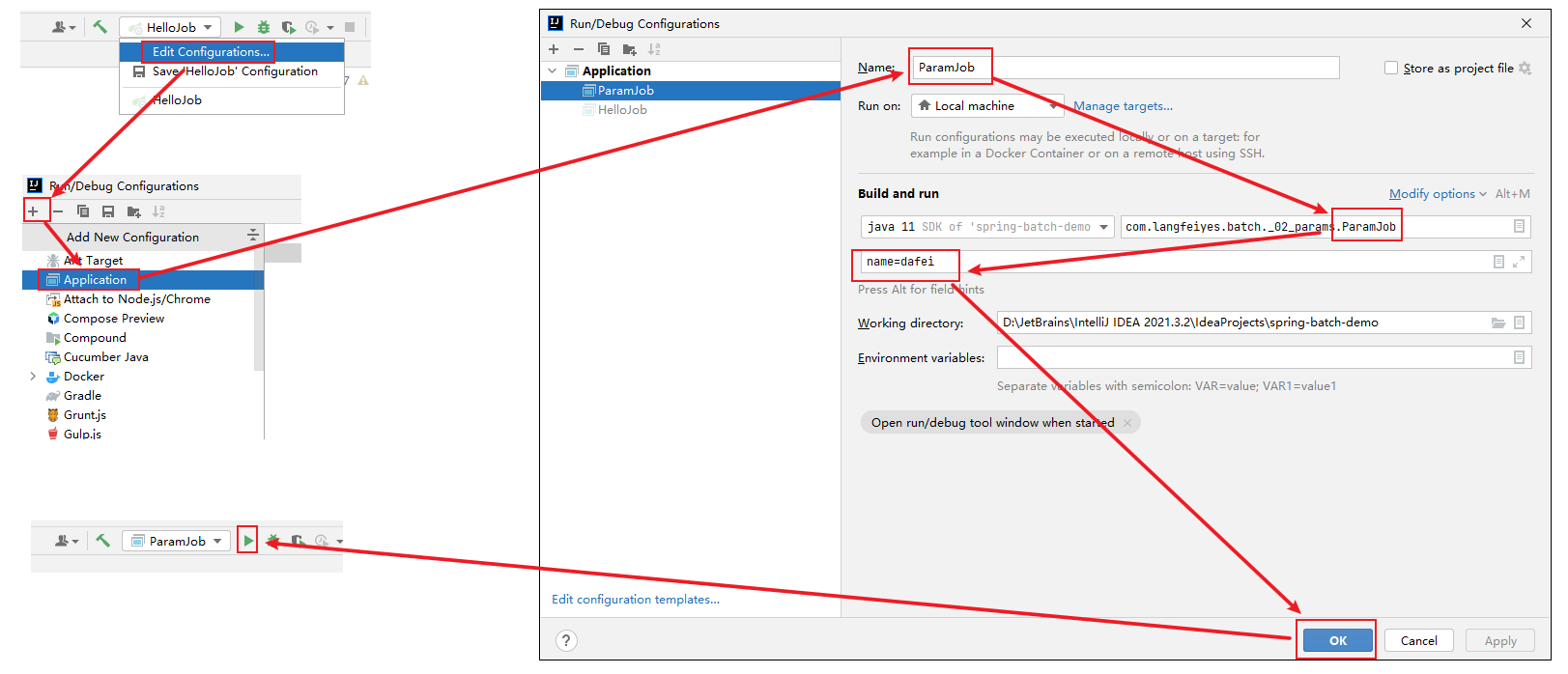
注意:如果不行这么麻烦,其实也可以,先空参数执行一次,然后指定参数后再执行。
点击绿色按钮,启动SpringBoot程序,作业运行之后,会在batch_job_execution_params 增加一条记录,用于区分唯一的Job Instance实例
 注意:如果不改动JobParameters 参数内容,再执行一次批处理,会直接报错。
注意:如果不改动JobParameters 参数内容,再执行一次批处理,会直接报错。

原因:Spring Batch 相同Job名与相同标识参数只能成功执行一次。
当将作业参数传入到作业流程,该如何获取呢?
Spring Batch 提供了2种方案:
修改ParamConfig 配置类中tasklet写法
@Bean
public Tasklet tasklet(){
return new Tasklet() {
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
Map<String, Object> parameters = chunkContext.getStepContext().getJobParameters();
System.out.println("params---name:" + parameters.get("name"));
return RepeatStatus.FINISHED;
}
};
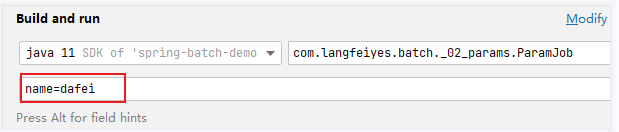
}注意:job名:param-job job参数:name=dafei 已经执行了,再执行会报错
所以要么改名字,要么改参数,这里选择改job名字(拷贝一份job实例方法,然后注释掉,修改Job名称)
// @Bean
// public Job job(){
// return jobBuilderFactory.get("param-job")
// .start(step1())
// .build();
// }
@Bean
public Job job(){
return jobBuilderFactory.get("param-chunk-job")
.start(step1())
.build();
}@StepScope
@Bean
public Tasklet tasklet(@Value("#{jobParameters['name']}")String name){
return new Tasklet() {
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
System.out.println("params---name:" + name);
return RepeatStatus.FINISHED;
}
};
}
@Bean
public Step step1(){
return stepBuilderFactory.get("step1")
.tasklet(tasklet(null))
.build();
}step1调用tasklet实例方法时不需要传任何参数,Spring Boot 在加载Tasklet Bean实例时会自动注入。
// @Bean
// public Job job(){
// return jobBuilderFactory.get("param-chunk-job")
// .start(step1())
// .build();
// }
@Bean
public Job job(){
return jobBuilderFactory.get("param-value-job")
.start(step1())
.build();
}这里要注意,必须贴上@StepScope ,表示在启动项目的时候,不加载该Step步骤bean,等step1()被调用时才加载,这就是所谓延时获取。
到这,参数设置与获取就ok啦,下一篇,来看下作业参数校验怎么玩~
看文字不过瘾可以切换视频版:Spring Batch高效批处理框架实战
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我在使用omniauth/openid时遇到了一些麻烦。在尝试进行身份验证时,我在日志中发现了这一点:OpenID::FetchingError:Errorfetchinghttps://www.google.com/accounts/o8/.well-known/host-meta?hd=profiles.google.com%2Fmy_username:undefinedmethod`io'fornil:NilClass重要的是undefinedmethodio'fornil:NilClass来自openid/fetchers.rb,在下面的代码片段中:moduleNetclass
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"