模糊PI控制(从simulink仿真到C代码实现)
PI控制是根据误差进行调节,利用比例Kp与积分KI实现反馈调节。但传统PI控制固定比例系数Kp与积分系数KI不是我们想要的,我们按照经验想:
所以模糊PI控制就是来实时控制改变Kp与Ki,由E误差及EC误差变化率来控制输出detal_Kp和detal_Ki;得到最终PI控制系数
解释:Critical_Kp 、Critical_Ki 为原来采用PI控制的临界值,detal_Kp 、detal_Ki为模糊控制器修改的P、I增量,Kp 、Ki为最总PI控制器的比例与积分系数。如下图以模糊PI控制cuk变换器电压的例子:

模糊控制器又称FC控制器,是FC控制系统与其他各类控制系统的最大区别,是模糊控制系统的核心.
如图4-1 所示,按照输入的维数划分,模糊控制器结构可以分为3类。

一个完整的二维 FC模糊控制过程包括:模糊化过程、模糊化推理过程和清晰化过程。

量化因子:就是输入量归一化到一个范围的因子,打个比方,如果是让你设计一个模糊控制器,你的标准输入是限制在[-3,3]之间,但是你现在实际输入却是在[-300,300]之间,你如何处理?最简单办法就是将 实际输入/100 作为标准输入 给到模糊控制器标准输入,1/100就是你的量化因子。当然这1/100是线性量化,如果你要做一个非线性量化因子也可以。
比例因子:就是输出标准量放大到你实际需要的因子,打个比方,如果是让你设计一个模糊控制器,你的标准输出是限制在[-3,3]之间,但你实际需要的输出却是在[-30,30]之间,你如何处理?最简单办法就是将 标准输出*10 作为实际输出,10就是你的比例因子。
总体关系如下图:

从上文不难发觉到,论域是我们规定一个输入或输出标准范围,所有输入或输出都必须规定在其中范围,那论域的作用是用来干什么的?体现在哪里?隶属函数又有啥作用?我们来看下面这张图。

图中:[0 100]为论域,有三条隶属度曲线S(0-40-100),M(0-10-50-90-100),L(0-60-100)
如果给你输入为20,你是不是能轻易得到与[S,M,L]曲线分别交点为[0.5、0.25、0.0]
如果给你输入为50,你是不是能轻易得到与[S,M,L]曲线分别交点为[0.0、1.00、0.0]
如果给你输入为80,你是不是能轻易得到与[S,M,L]曲线分别交点为[0.0、0.25、0.5]
其实S、M、L分别代表小、中、大,你输出得到0-1之间的比值,为他们各种占比,以输入20为例,你得到S小的隶属度占50%,M中隶属度为25%,L大隶属度为0%,这个操作也就是模糊化处理
那如果给你一个输入110或者-10,你能得到什么?会出现错误,因为三条隶属度就只规定了0-100的区间,这就是你要规划的论域。
上面只是一个三条三角隶属度例子,理论你可以随意规划论域大小,规划N条隶属度,隶属度形式也可以多种多样,如下图:

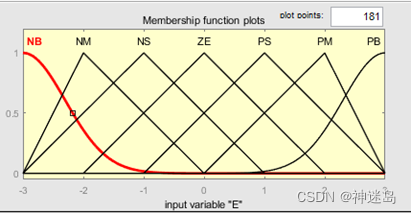
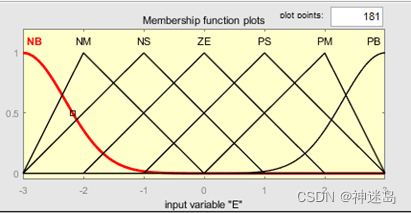
这是一个论域在[-3 3]之间,有七条隶属函数[NB、NM、NS、ZE、PS、PM、PB],代表{负大、负中、负小、零、正小、正中、正大}。
当然有输入隶属度,输入论域,当然也有输出的论域,输出隶属度,其本质跟输入类似,但是它就不是按一个输入得到一组隶属度数据,也不是简单反向操作由一组隶属度得到一个输出值,具体后面在1.2.4点再说明
上一点我们也可以又一个输入模糊化成一组数据占各自隶属度大小,那该如何利用这组数据,就得利用到模糊规则表,下面我们来看一个简单的(二输入一输出)模糊规则表:
二输入一输出系统模型:

模糊控制规则表

假设输入oil=20%:mud=80%
输入到oil隶属函数曲线可以得到:当oid=20%,与[S,M,L]曲线分别交点为[0.5、0.25、0.0];
输入到mud隶属函数曲线可以得到:当mud=80%,与[S,M,L]曲线分别交点为[0.0、0.25、0.5];
此时:【oil激活S、M】,【mud激活M、L】,对应规则表激活四条规则
分别是:
oil含油量少(oil:S[0.5]),mud含泥量中(mud:M[0.25]),time洗涤时间少(time:S[0.25]])
oil含油量少(oil:S[0.5]]),mud含泥量多(mud:L[0.5]),time洗涤时间中(time:M[0.5]])
oil含油量中(oil:M[0.25]]),mud含泥量中(mud:M[0.25]),time洗涤时间中(time:M[0.25])
oil含油量中(oil:M[0.25]),mud含泥量多(mud:L[0.5]]),time洗涤时间中长(time:ML[0.25])
可以看出:time激化比例是两者最小决定的。

哪激化洗涤时间有三种:time:【S,M,ML】,这就是模糊控制规则表作用,哪最终洗涤时间是多少?你想想得采用什么方式才能将激活time:【S,M,ML】变成一个数字时间输出,这类做法叫做清晰化/解模糊。
这里是个关键点,如何把前面模糊规则表规则变化成一个具体标准数值。模糊控制清晰化输出量的判决方式有常见的三种:最大隶属度法、面积中心法(即重心法)和加权平均法:
实际工程应用最长见的就是采用面积中心法,其他两种方式感兴趣的可以网上搜搜一大堆解释。下面我们来详细介绍什么是面积中心法:
面积中心法顾名思义就是,寻找一个面积的质点,下面我们直接上图,根据假设输入oil=20%:mud=80%,规则表,隶属度按上一例子讲的哪有,如何解模糊化。

当输入oil=20%:mud=80%只激化图中第(2,3,5,6)条对应着激化四条规则
第2规则:oil含油量少(oil:S[0.5]),mud含泥量中(mud:M[0.25]),time洗涤时间少(time:S[0.25]])
第3规则:oil含油量少(oil:S[0.5]]),mud含泥量多(mud:L[0.5]),time洗涤时间中(time:M[0.5]])
第5规则:oil含油量中(oil:M[0.25]]),mud含泥量中(mud:M[0.25]),time洗涤时间中(time:M[0.25])
第6规则:oil含油量中(oil:M[0.25]),mud含泥量多(mud:L[0.5]]),time洗涤时间中长(time:ML[0.25])
注意看time的面子是怎么来的?其实就是每个激化隶属曲线与激化隶属度大小相交的面积!!!!
例如第2规则,time激化隶属度是S[0.25],就是S隶属函数曲线与直线x=0.25先交以下的面积大小
最后如何得到time=29.9呢?就是激活四个面积区域相或面积,求该面积质点就是模糊要输出的值。
B站有位老师讲的非常不错,20分钟左右,大家可以看一下:模糊洗衣机控制系统: link
看完也能对上面所学进行一次复习,虽然这例子不是模糊PI空载原理,但模糊控制原理主要原理都是相似的,可以帮你更好了解什么是模糊控制,了解整个控制流程,对你设计模糊控制器很有帮助。
默认前面全部学会了,直接给图了
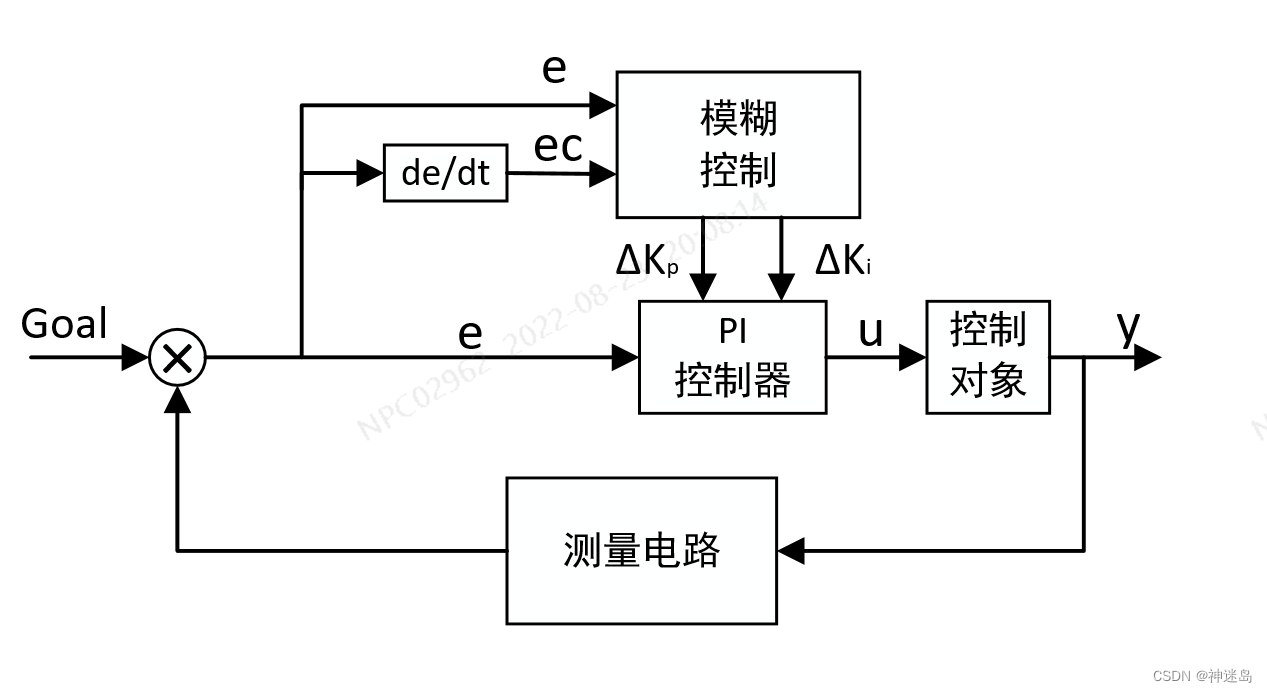
本文中模糊控制为双输入双输出结构,假定输入误差的变化范围为[e_min,e_max],输入误差变化率的变化范围为[ec_min,ec_max],模糊控制器输出分别为△K_p和△K_i。设误差论域范围选取[e_min*, e_max*], 误差变化率论域范围选取[ec_min*, ec_max*], △K_p和△K_i论域也分别设置为[K_pmin*, K_pmax*] 与[K_imin*, K_imax*],表示可以在初始参数点上下调节。由此可以确定量化因子和比例因子系数为:
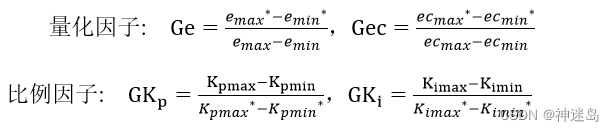
实验中输入考虑在正负范围内对称,所以误差论域范围选取[-3,3],误差变化率论域范围选取[-3,3]。输出也考虑到正负变化,所以△K_p和△K_i论域也设置为[-3,3],表示可以在初始参数点上下调节。
根据工程实际情况,输入变量e和ec的模糊子集为{负大,负中,负小,零,正小,正中,正大},记为{NB,NM,NS,ZE,PS,PM,PB},将偏差e和偏差变化率ec量化到{-3,3}论域范围(其他范围都可以)。同时,输出变量△K_p和△K_i的模糊子集{负大,负中,负小,零,正小,正中,正大},记为{NB,NM,NS,ZE,PS,PM,PB},分别量化到{-3,3}的论域内,其隶属函数曲线分别如下图所示。
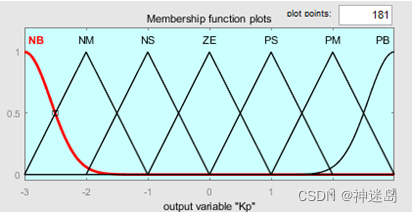
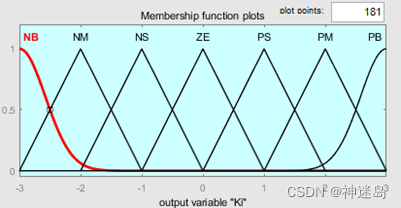
原理:当e误差在最大值时候,需要将后续Kp比例系数增加,减少误差,而Kp增加时候需要将Ki积分系数减少,减少积分饱和同时增加系统稳定性。当ec误差变化率最大时候,需要将Ki积分系数减少,减少积分饱和,同时增加比例系数Kp。
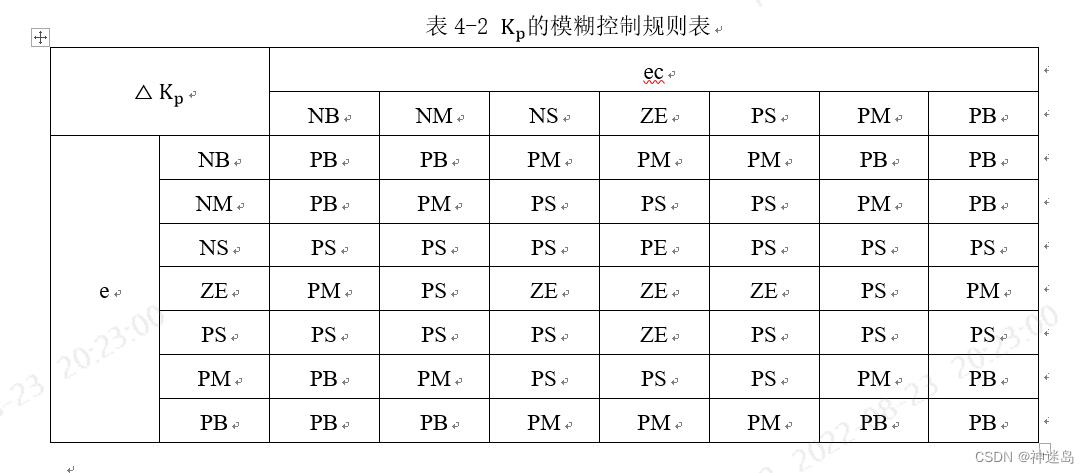
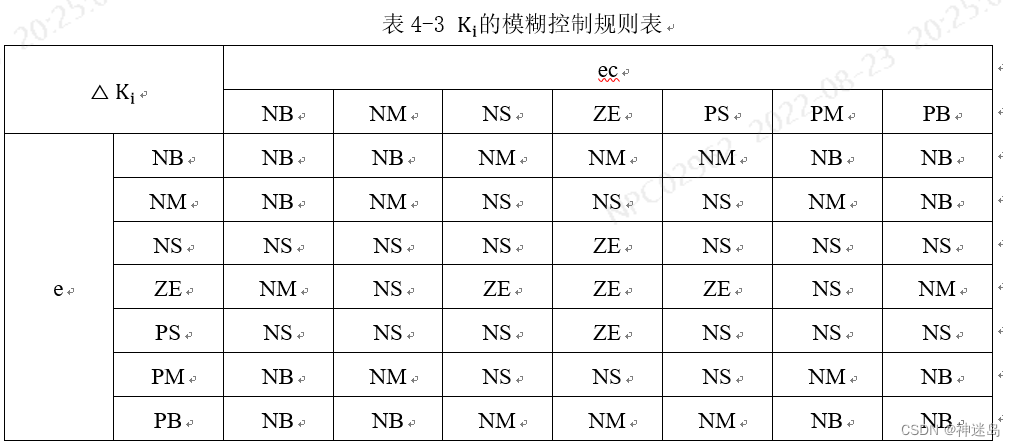
根据各模糊子集的隶属度赋值表和各参数的模糊控制模型,应用模糊合成推理设计PI参数模糊矩阵表,模糊控制器将清晰化得到结果与比例因子相乘以后,输出△K_p和△K_i对PI参数进行整定。 其计算公式如下:
其中,K_p0与K_i0为常用常规PI控制器选取的参数,K_p与K_i为整定后的参数。
这一步很简单,matlab的simulink有专门的工具可以用来实现,现在我们来根据前面说的第二大点来做simulink仿真。下图为总体框架
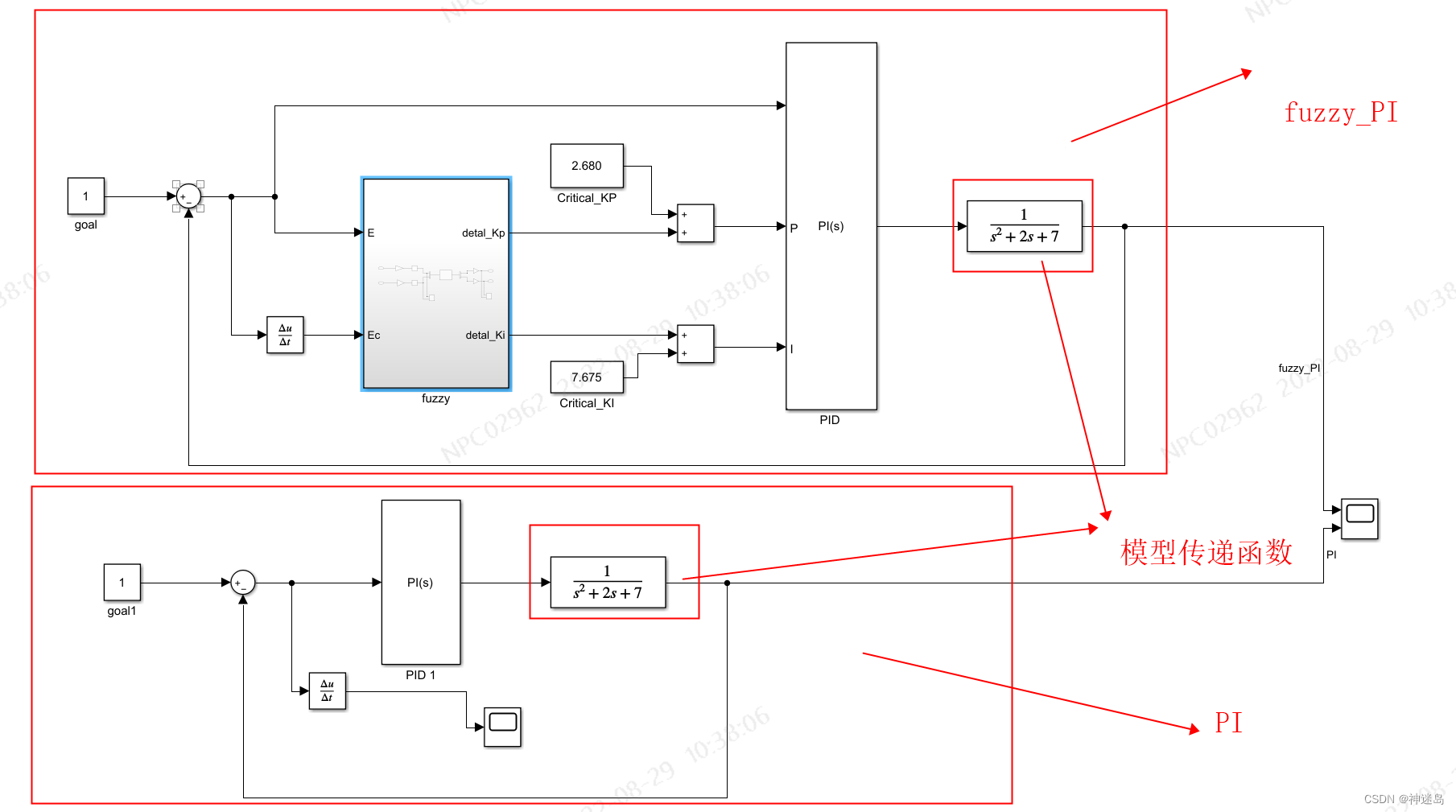
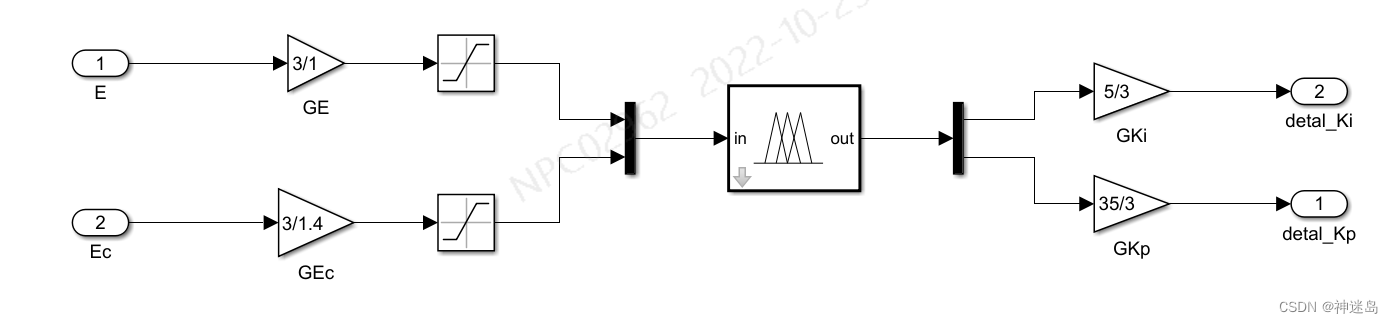
fuzzy内部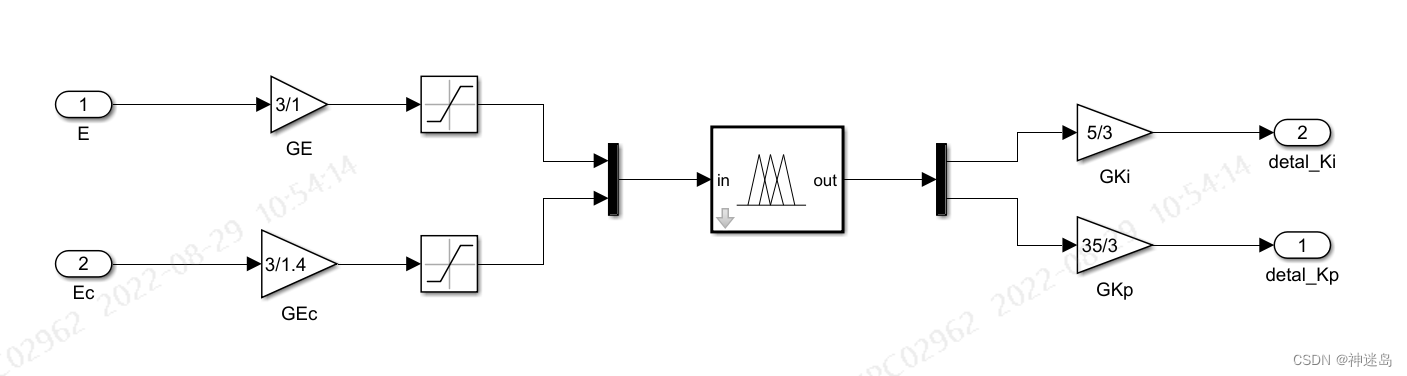 输入:E为误差,Ec为误差变化率,输出:detal_Kp为△KP,detal_Ki为△Ki; 中间: GE、GEc为误差和误差变化率的量化因子,GKP,GKi为detal_Kp和detal_Ki的比例因子
输入:E为误差,Ec为误差变化率,输出:detal_Kp为△KP,detal_Ki为△Ki; 中间: GE、GEc为误差和误差变化率的量化因子,GKP,GKi为detal_Kp和detal_Ki的比例因子
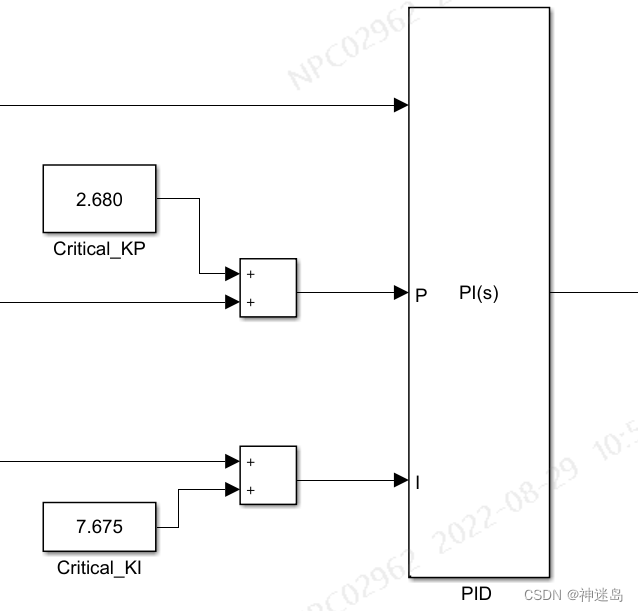
输入:E为误差,Critical_KP为PI临界比例系数,Critical_KI为临界积分系数;
输出:U为PI控制输出;
中间:detal_Kp和detal_Ki为上图模糊输出△Kp与△Ki;
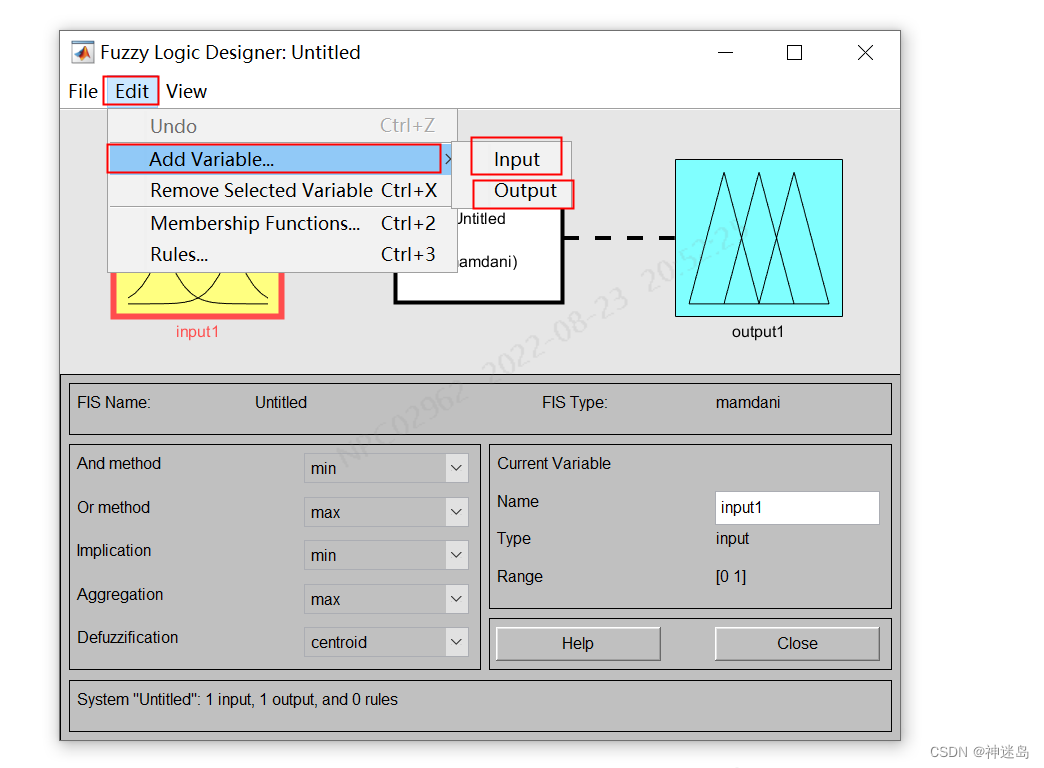
在命令行直接输入:fuzzy
系统会打开模糊控制器设计页面

按下面操作生产两输入两输出结构
最终结构
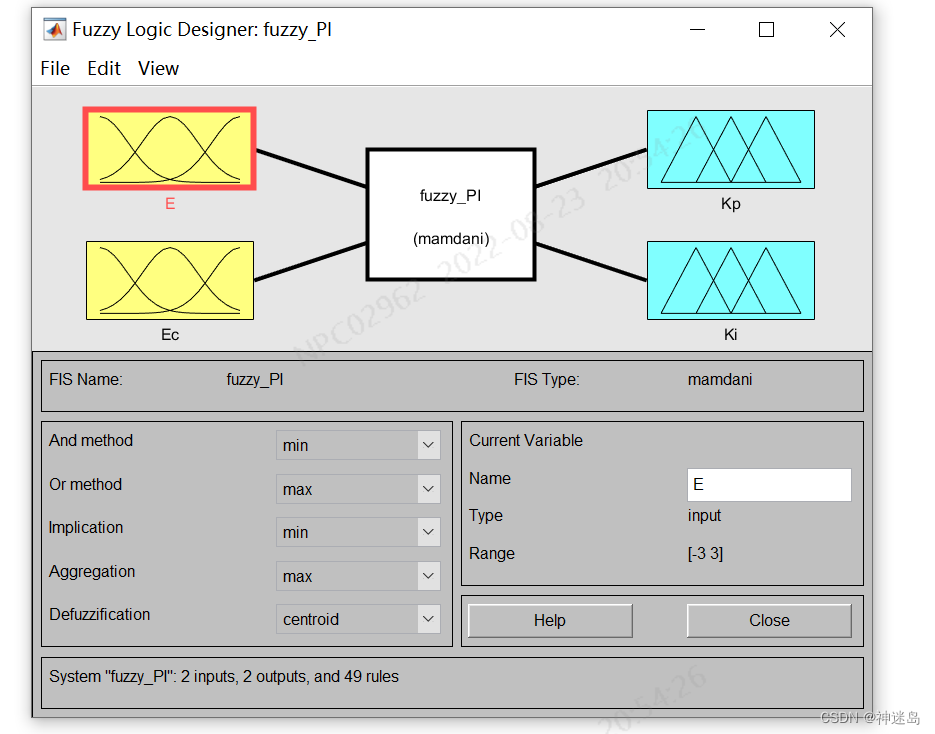
点开一个
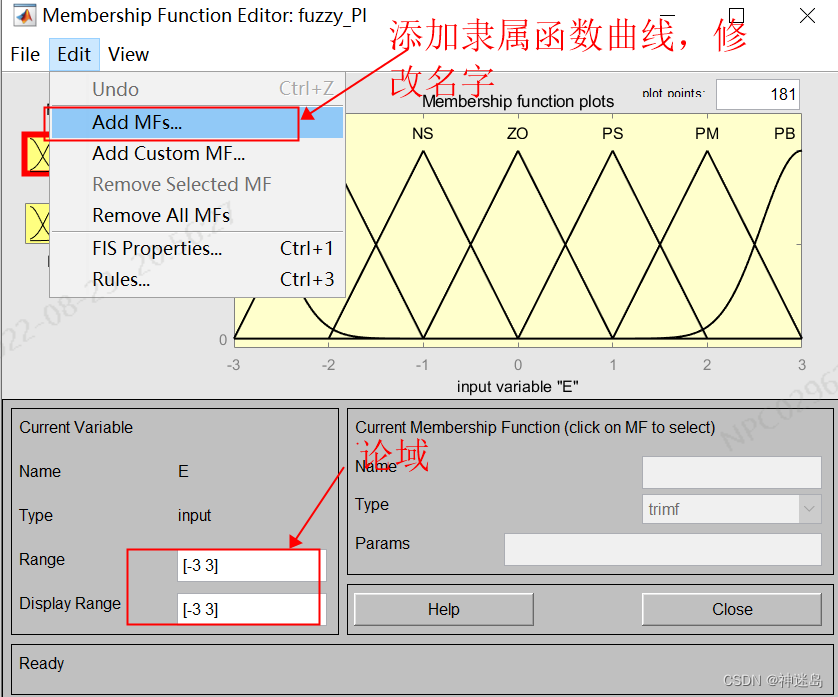
最总呈现:2.1 模糊PI隶属函数、量化因子、比例因子中四个隶属曲线图一致
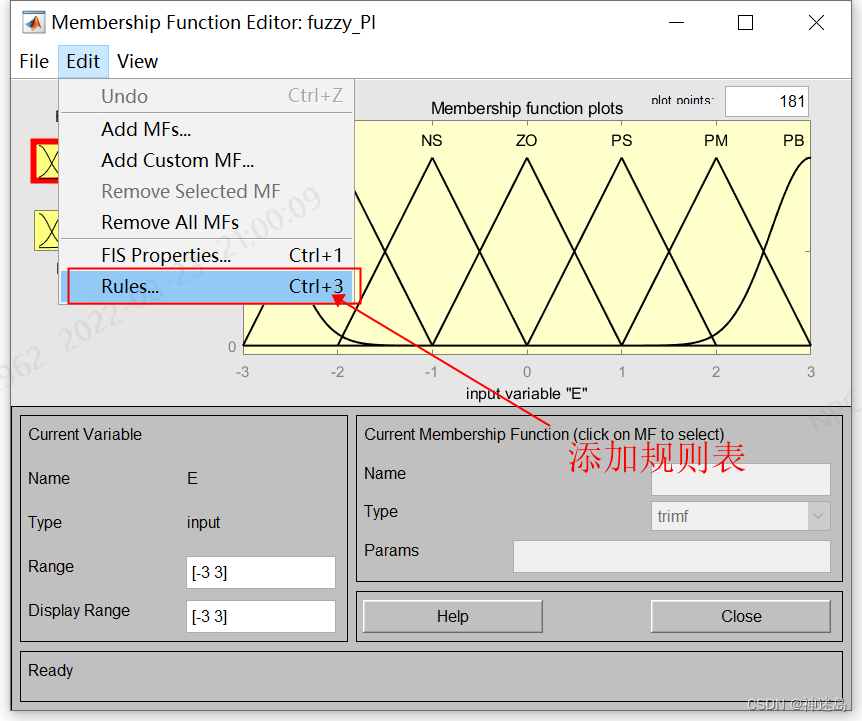
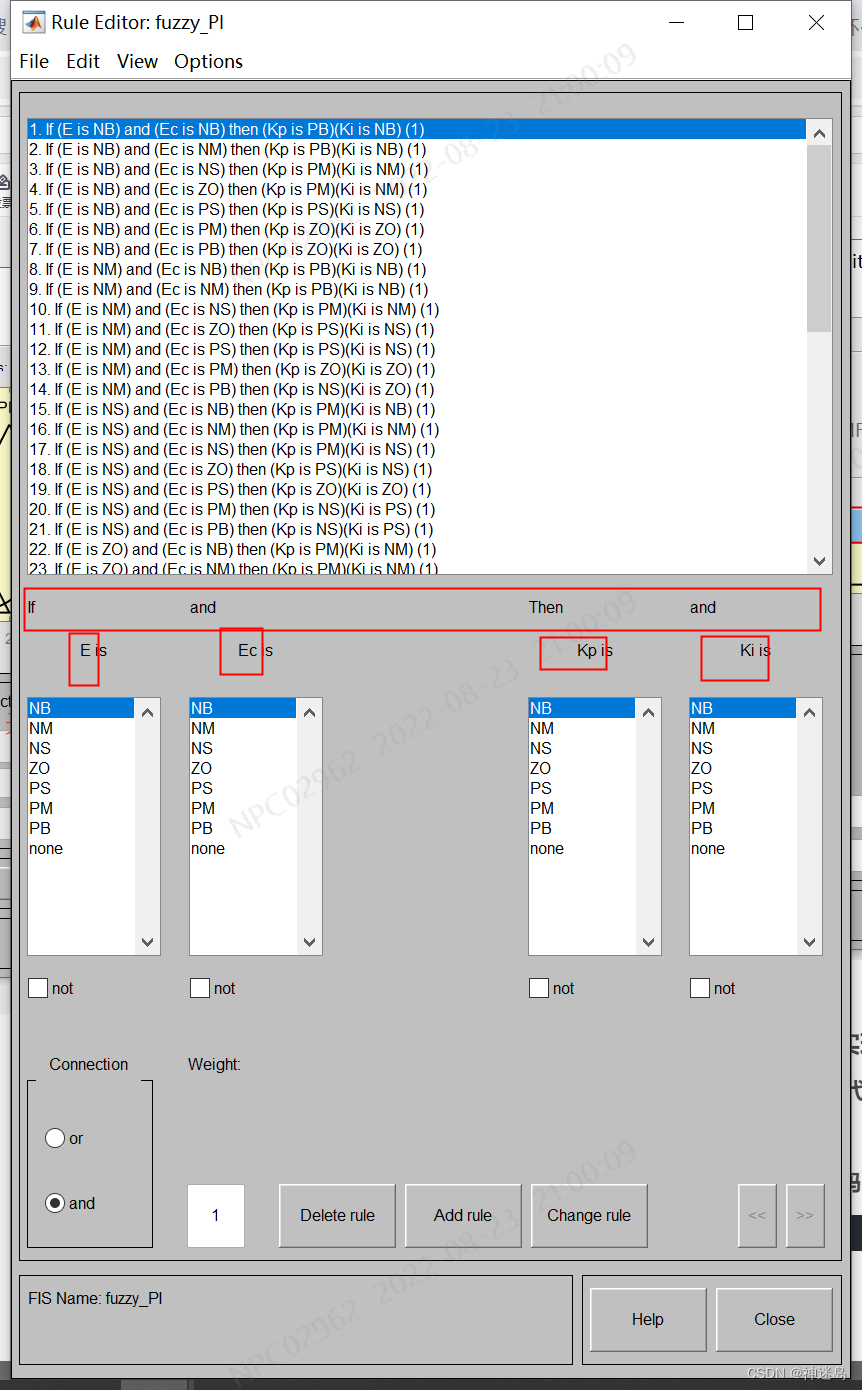
按照:2.1 Kp与△Ki模糊控制规则表添加49条规则,具体部分如图下显示:注意他们关系是:if E is XX EC is XX then Kp is XX and Ki is XX
搞定保存后,当前matlab的工作目录下有一个:xxx.fis ,我这里因为名字起来fuzzy_PI,所以才会是fuzzy_PI.fis
整体框架
实验对比
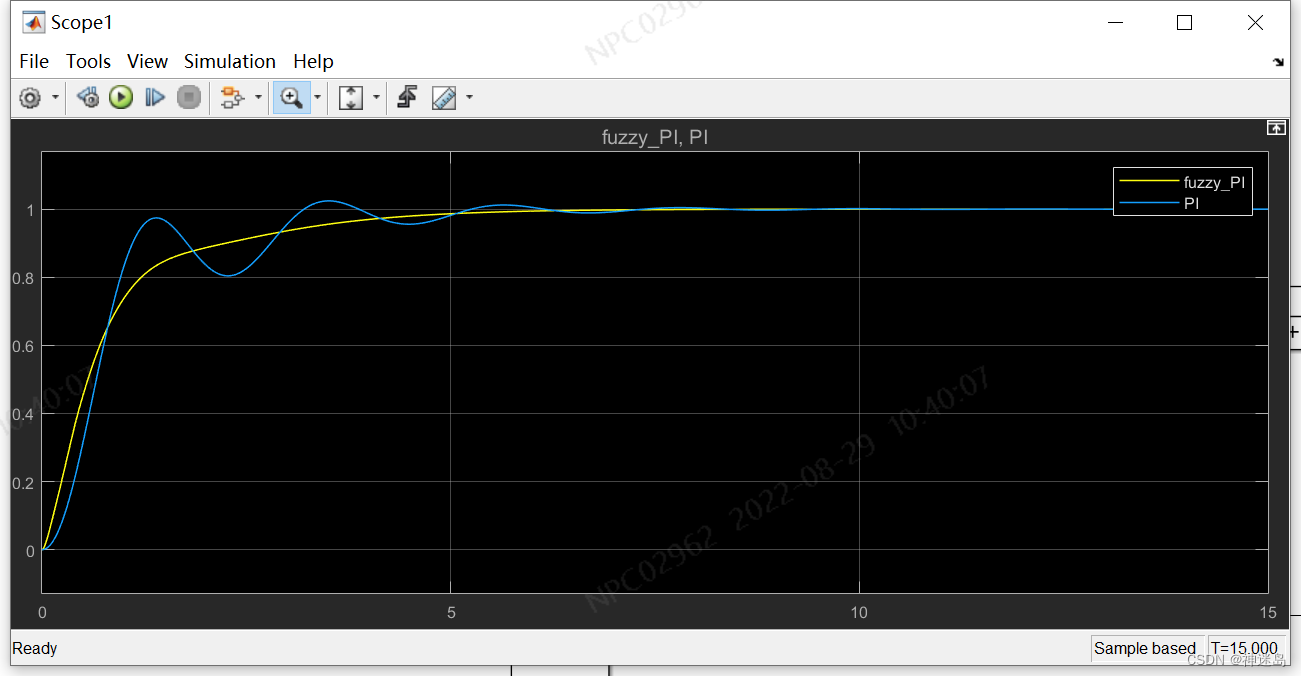
明显可以看出fuzzy_PI比PI,反应时间更加快速,基本无超调量
资源:链接:https://download.csdn.net/download/pengrunxin/86502151 : link,[matlab版本2018A],低于这个版本自己解决
走到这一步,模糊PI控制原理跟流程都很熟悉了,根据自己想法写一个模糊控制器相对来说也很容易。我们只要完成模糊PI的模糊控制器部分代码,PI控制部分代码网上很多版本。
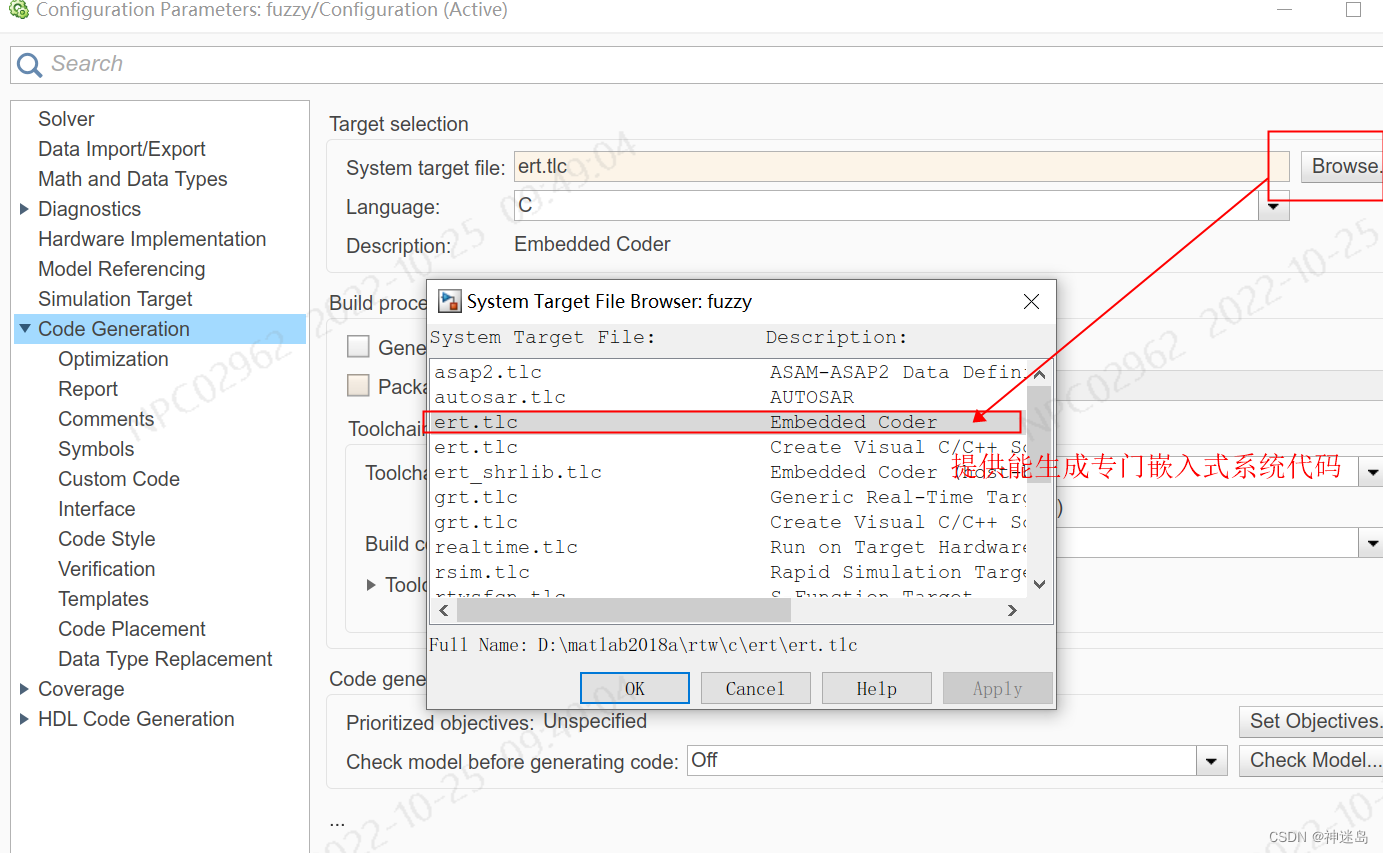
simulink直接导出c语言是最方便快捷的方案,可是代码可阅读性就够呛。
1.将模糊PI控制部分单独拎出来一个工程,像这样:
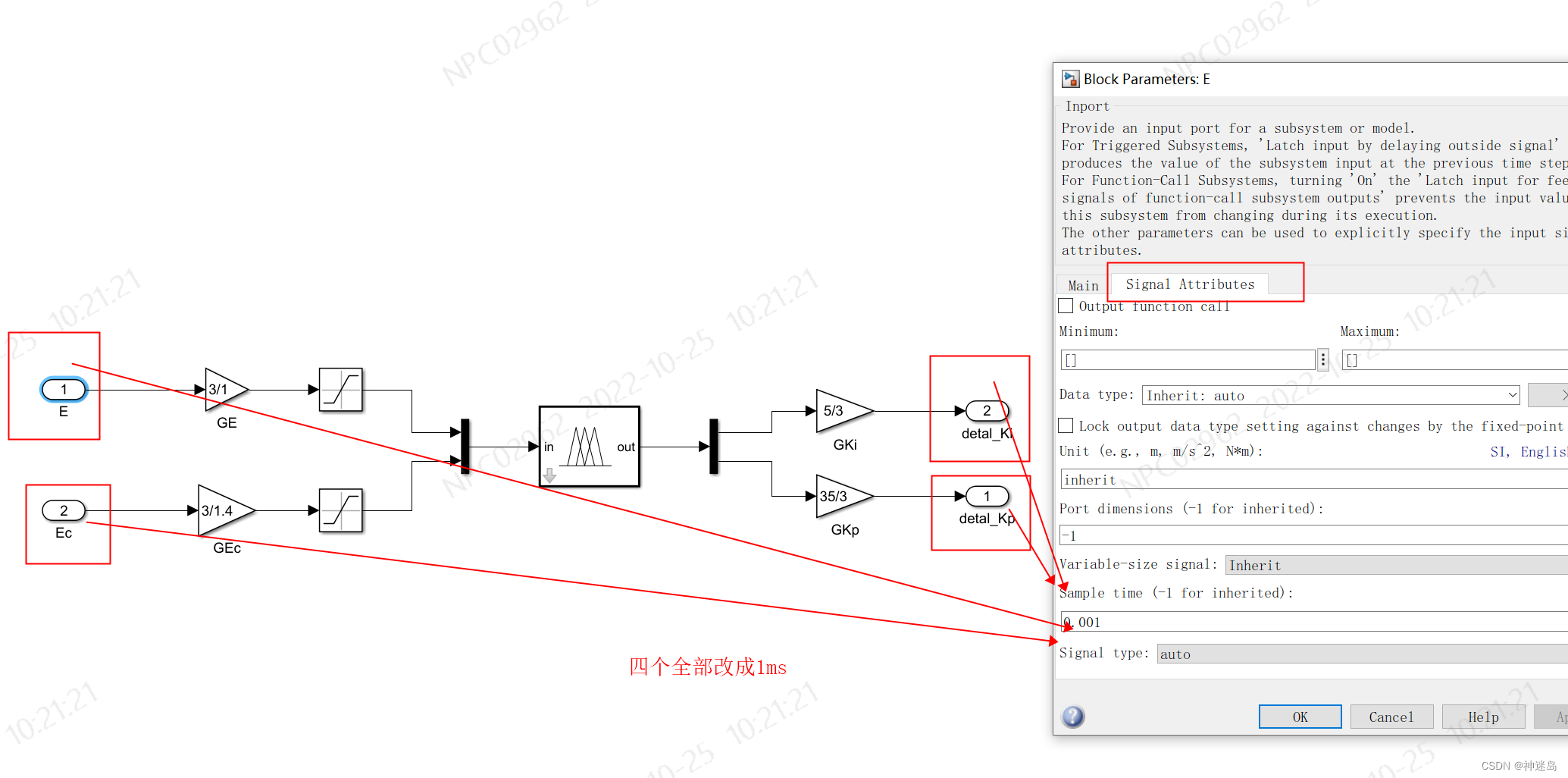
2.设置一下
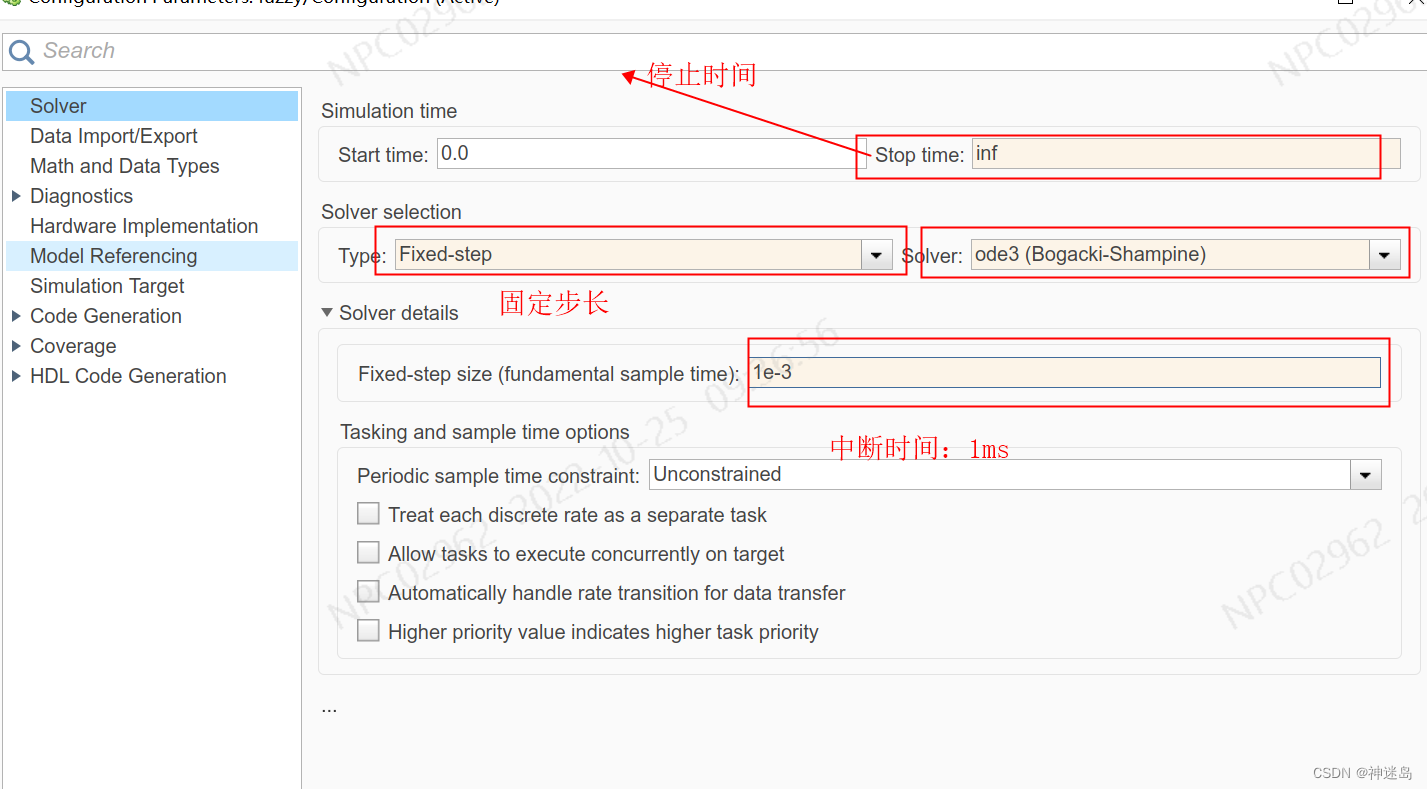
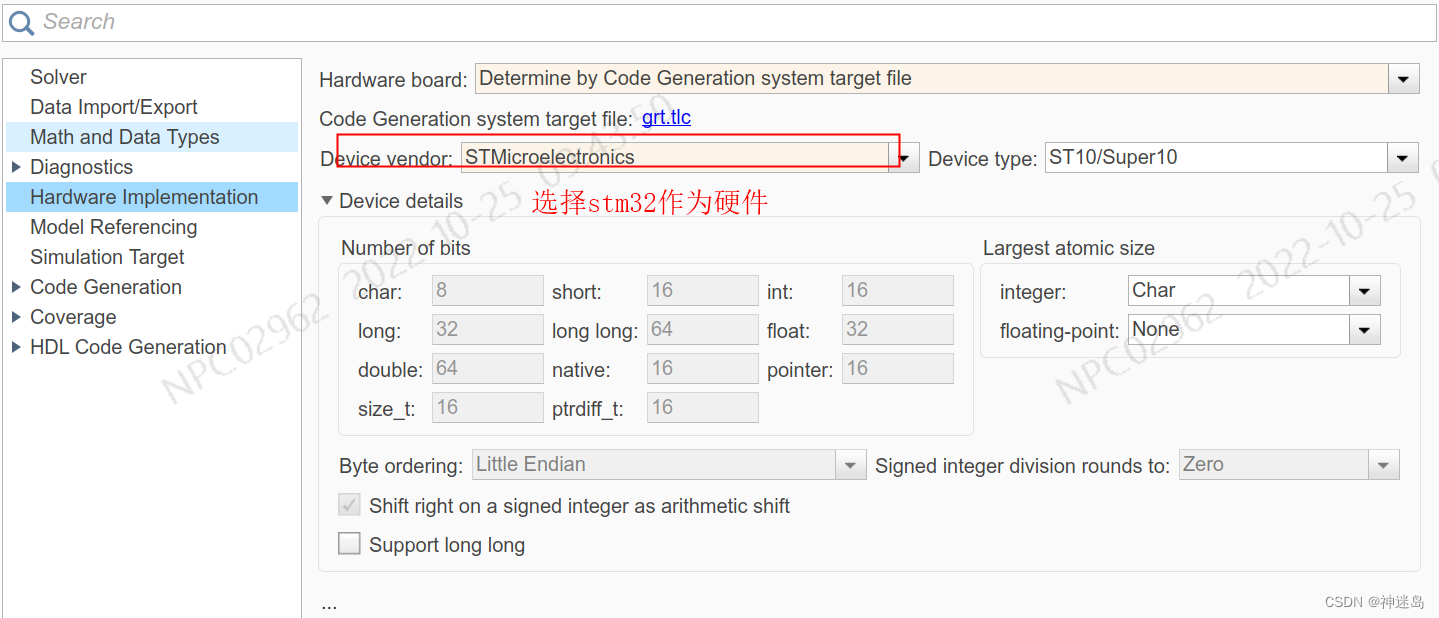
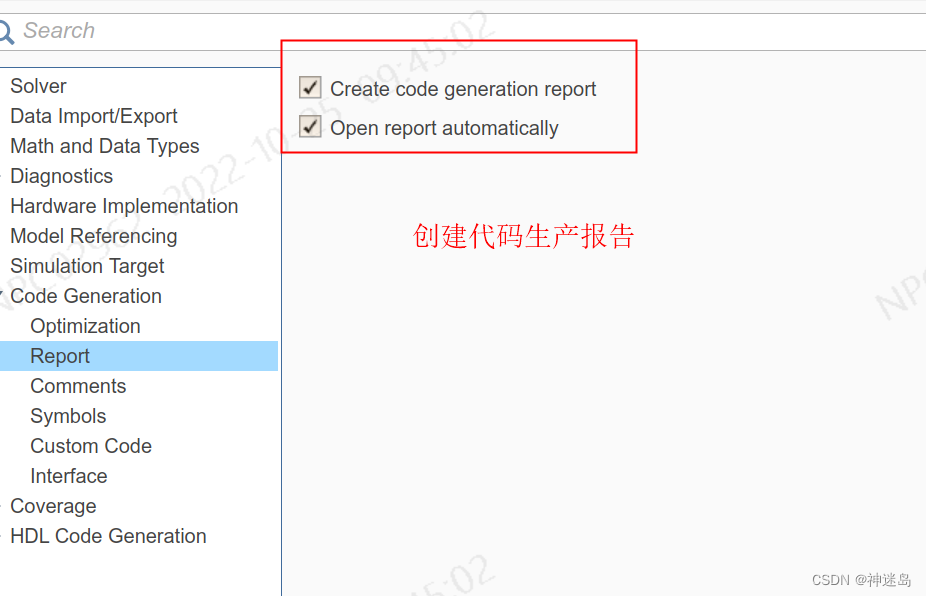
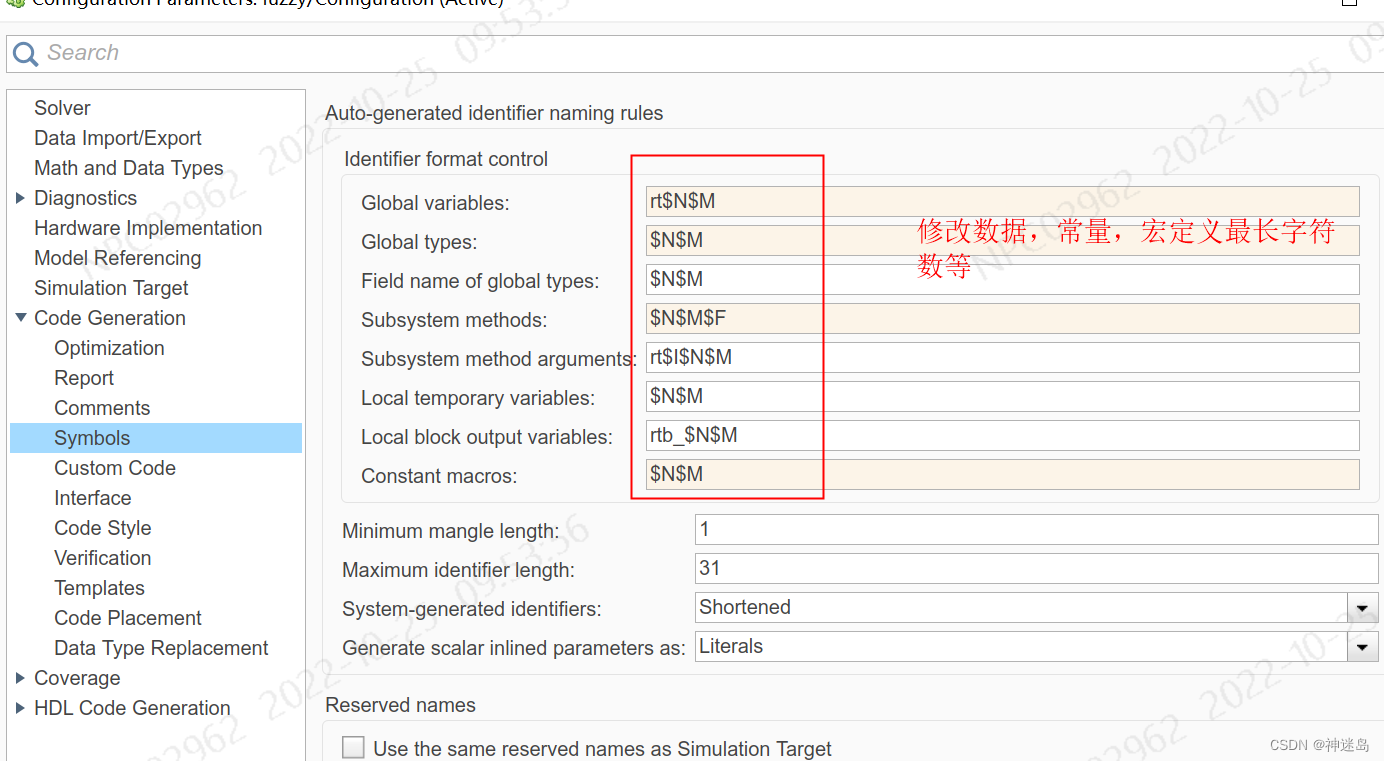
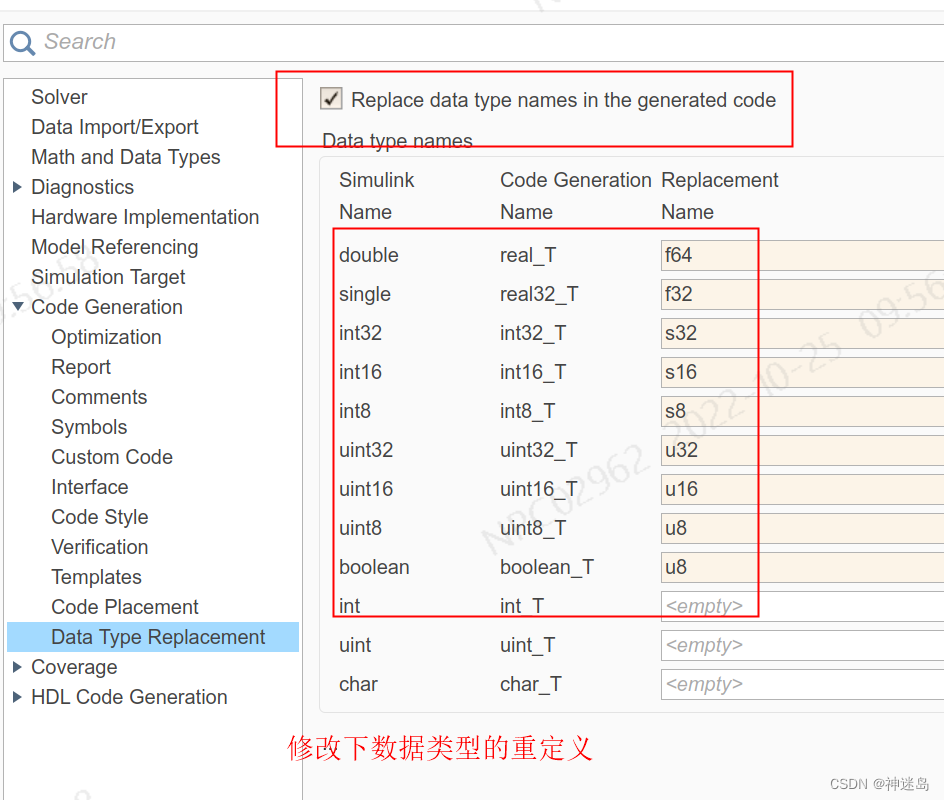
在这里插入代码片
做了好久啊,里面还有一些没完善的,太累了。制作不易,关注加点赞一波,啊啊啊啊,谢谢!
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
当我在Rails控制台中按向上或向左箭头时,出现此错误:irb(main):001:0>/Users/me/.rvm/gems/ruby-2.0.0-p247/gems/rb-readline-0.4.2/lib/rbreadline.rb:4269:in`blockin_rl_dispatch_subseq':invalidbytesequenceinUTF-8(ArgumentError)我使用rvm来管理我的ruby安装。我正在使用=>ruby-2.0.0-p247[x86_64]我使用bundle来管理我的gem,并且我有rb-readline(0.4.2)(人们推荐的最少
我正在使用Ruby2.1.1和Rails4.1.0.rc1。当执行railsc时,它被锁定了。使用Ctrl-C停止,我得到以下错误日志:~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`gets':Interruptfrom~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`verify_server_version'from~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.
我将我的Rails应用程序部署到OpenShift,它运行良好,但我无法在生产服务器上运行“Rails控制台”。它给了我这个错误。我该如何解决这个问题?我尝试更新rubygems,但它也给出了权限被拒绝的错误,我也无法做到。railsc错误:Warning:You'reusingRubygems1.8.24withSpring.UpgradetoatleastRubygems2.1.0andrun`gempristine--all`forbetterstartupperformance./opt/rh/ruby193/root/usr/share/rubygems/rubygems
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题: