文章目录
通过MapReduce的序列化方法统计各个部门员工薪水总和。
员工的数据如下:

各字段描述如下:

7369,SMITH,CLERK,7902,1980/12/17,800,,20
7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
7521,WARD,SALESMAN,7698,1981/2/22,1250,500,30
7566,JONES,MANAGER,7839,1981/4/2,2975,,20
7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981/5/1,2850,,30
7782,CLARK,MANAGER,7839,1981/6/9,2450,,10
7788,SCOTT,ANALYST,7566,1987/4/19,3000,,20
7839,KING,PRESIDENT,,1981/11/17,5000,,10
7844,TURNER,SALESMAN,7698,1981/9/8,1500,0,30
7876,ADAMS,CLERK,7788,1987/5/23,1100,,20
7900,JAMES,CLERK,7698,1981/12/3,950,,30
7902,FORD,ANALYST,7566,1981/12/3,3000,,20
7934,MILLER,CLERK,7782,1982/1/23,1300,,10
将此文件保存在hdfs,作为输入文件。
hdfs dfs -put emp.csv /input_emp
(改为自己的文件目录)
在本地运行时需要添加以下依赖jar包;若不在本地运行,这里可以不添加依赖,Linux系统布署的hadoop已经有这些jar包了。(注:我的本地windows系统没有安装hadoop,所以并没有在本地运行)
修改pom.xml,增加节点,代码如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.serial</groupId>
<artifactId>serialsalarytol</artifactId>
<version>1.0-SNAPSHOT</version>
<name>serialsalarytol</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.7</version>
</dependency>
</dependencies>
<build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
<plugins>
<!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle -->
<plugin>
<artifactId>maven-clean-plugin</artifactId>
<version>3.1.0</version>
</plugin>
<!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging -->
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.1</version>
</plugin>
<plugin>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-install-plugin</artifactId>
<version>2.5.2</version>
</plugin>
<plugin>
<artifactId>maven-deploy-plugin</artifactId>
<version>2.8.2</version>
</plugin>
<!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle -->
<plugin>
<artifactId>maven-site-plugin</artifactId>
<version>3.7.1</version>
</plugin>
<plugin>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.0.0</version>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
(1)编写Emplyee.java类,代码如下:
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Employee implements Writable {
private int empno;
private String ename;
private String job;
private int mgr;
private String hiredate;
private int sal;
private int comm;
private int deptno;
@Override
public void write(DataOutput dataOutput) throws IOException {
//案例三:序列化
dataOutput.writeInt(this.empno);
dataOutput.writeUTF(this.ename);
dataOutput.writeUTF(this.job);
dataOutput.writeInt(this.mgr);
dataOutput.writeUTF(this.hiredate);
dataOutput.writeInt(this.sal);
dataOutput.writeInt(this.comm);
dataOutput.writeInt(this.deptno);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
//反序列化
this.empno = dataInput.readInt();
this.ename = dataInput.readUTF();
this.job = dataInput.readUTF();
this.mgr = dataInput.readInt();
this.hiredate = dataInput.readUTF();
this.sal = dataInput.readInt();
this.comm = dataInput.readInt();
this.deptno = dataInput.readInt();
}
public int getEmpno() {
return empno;
}
public void setEmpno(int empno) {
this.empno = empno;
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public String getJob() {
return job;
}
public void setJob(String job) {
this.job = job;
}
public int getMgr() {
return mgr;
}
public void setMgr(int mgr) {
this.mgr = mgr;
}
public String getHiredate() {
return hiredate;
}
public void setHiredate(String hiredate) {
this.hiredate = hiredate;
}
public int getSal() {
return sal;
}
public void setSal(int sal) {
this.sal = sal;
}
public int getComm() {
return comm;
}
public void setComm(int comm) {
this.comm = comm;
}
public int getDeptno() {
return deptno;
}
public void setDeptno(int deptno) {
this.deptno = deptno;
}
}
(2)编写SalaryTotalMapper.java类,并继承父类Mapper,代码如下:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class SalaryTotalMapper extends Mapper<LongWritable, Text, IntWritable,Employee> {
@Override
protected void map(LongWritable key1, Text value1, Context context) throws IOException, InterruptedException {
//模式匹配
String data = value1.toString();
//分词
String [] words = data.split(",");
//创建员工对象
Employee e = new Employee();
//设置员工属性
e.setEmpno(Integer.parseInt(words[0]));//员工号
e.setEname(words[1]);//姓名
e.setJob(words[2]);//职位
try{
e.setMgr(Integer.parseInt(words[3]));//老板号
}catch (Exception ex){
e.setMgr(-1);
}
e.setHiredate(words[4]);//入职日期
e.setSal(Integer.parseInt(words[5]));//月薪
try{
e.setComm(Integer.parseInt(words[6]));//奖金
}catch (Exception ex){
e.setComm(0);
}
e.setDeptno(Integer.parseInt(words[7]));//部门号
//输出:k2部门号 v2员工对象
context.write(new IntWritable(e.getDeptno()),e);
}
}
(3)编写SalaryTotalReducer.java类,并继承父类Reducer,代码如下:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SalaryTotalReducer extends Reducer<IntWritable,Employee,IntWritable,IntWritable> {
//对v3中的每个员工进行工资求和
@Override
protected void reduce(IntWritable k3, Iterable<Employee> v3, Context context) throws IOException, InterruptedException {
int total = 0;
for(Employee e:v3){
total = total + e.getSal();
}
context.write(k3,new IntWritable(total));
}
}
(4)写主类,让程序能够运行起来,代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.BasicConfigurator;
import java.io.IOException;
public class SalaryTotalMain {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(SalaryTotalMain.class);
//指定job的mapper和输出类型 k2 v2
job.setMapperClass(SalaryTotalMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Employee.class);
//指定job的reducer和输出类型 k4 v4
job.setReducerClass(SalaryTotalReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
//指定job的输入输出的路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.waitForCompletion(true);
}
}
以上工作完成之后,打jar包,使用maven时,将以下工作目录改成自己的本地目录。
通过命令:**“hadoop jar jar包名 包名.主类名 输入数据文件地址(前面将emp.csv传到HDFS的位置) 输出数据文件地址(自己不用创建,会自动创建,不能重复)”**在linux系统运行。
hadoop jar saltotal-1.0-SNAPSHOT.jar 自己写的包名.SalaryTotalMain /input1_emp /output_emp2
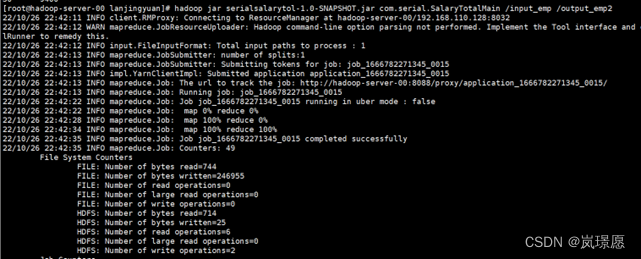
出现map 100% reduce 100%即运行成功。
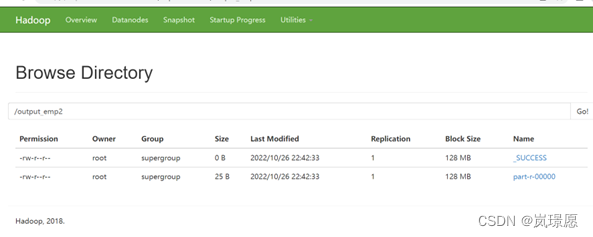

或者直接使用shell命令查看。

实验过程中遇到了很多问题,不过都解决了,下面是问题小结:
(1)emp.csv 数据源导入错误,第一行少了部分数据,导致运行时数据类型转换错误。
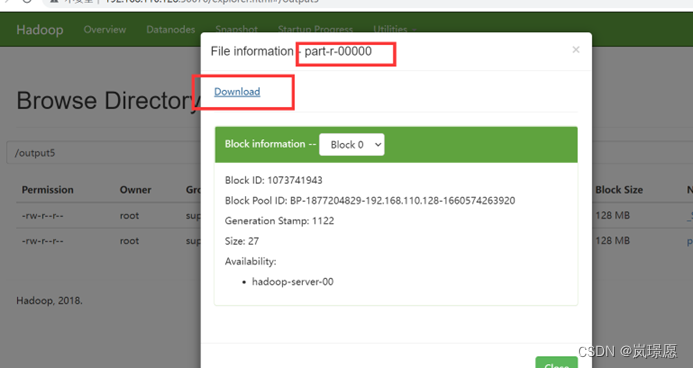
(2)Browse Directory 下载输出结果报错。
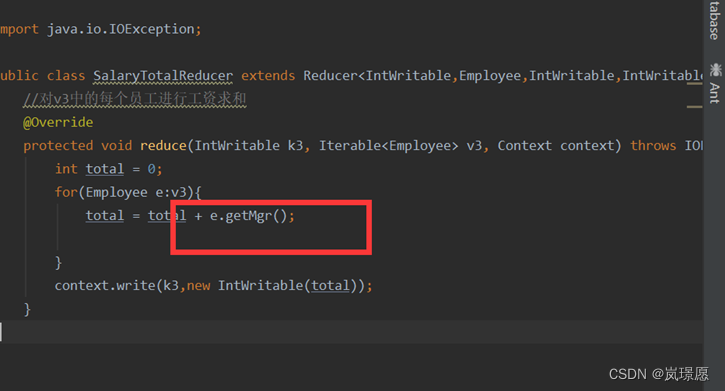
(3)Reducer 处理过程写错了,统计成各部门Mgr(直接领导的员工ID),造成统计数据结果错误。

当发现输出结果出现偏差时,需要认真检查自己写的程序代码和源数据。
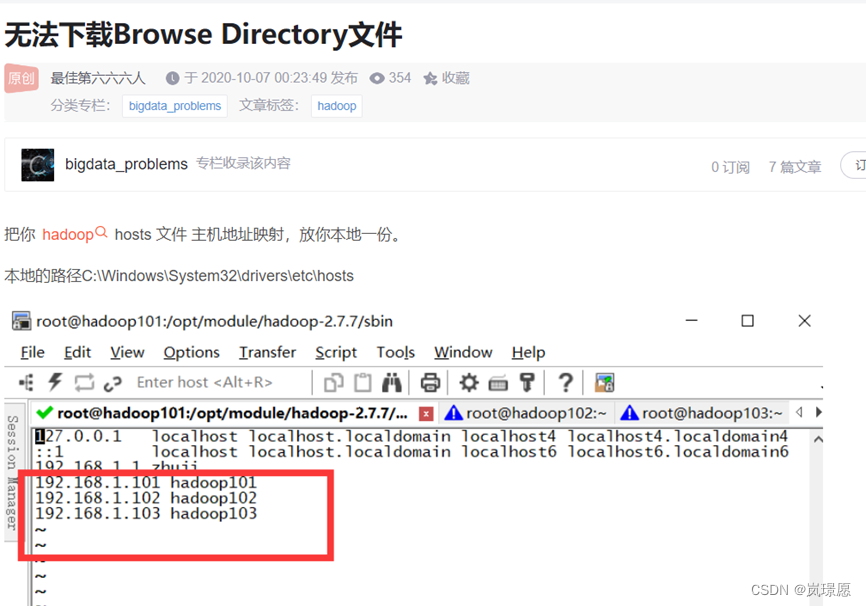
(1)Browse Directory 下载输出结果报错,采取了CSDN给出的解决方法:在本地配置主机映射。
如果还有其它问题,欢迎大家评论交流~~~
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
假设我必须(小型到中型)阵列:tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]如何确定tokens是否以相同的顺序包含template的所有条目?(请注意,在上面的示例中,应忽略第一个“ccc”,从而由于最后一个“ccc”而导致匹配。) 最佳答案 这适用于您的示例数据。tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]po
首先,我使用的是rails3.1.3和来自master的carrierwavegithub仓库的分支。我使用after_init钩子(Hook)来确定基于属性的字段页面模型实例并为这些字段定义属性访问器将值存储在序列化哈希中(希望它清楚我是什么谈论)。这是我正在做的事情的精简版:classPage省略mount_uploader命令让我可以访问我想要的属性。但是当我安装uploader时出现错误消息说“nil类的未定义新方法”我在源代码中读到有方法read_uploader和扩展模块中的write_uploader。我如何必须覆盖这些来制作mount_uploader命令使用我的“虚拟
以前没见过这个,但我想知道如何在Ruby中找到二维数组的两条对角线之和。假设您有一个简单的数组,包含3行和3列。array=[1,2,3,4,5,6,7,8,9]我可以通过使用将它分成三个一组array.each_slice(3).to_a现在是[1,2,3],[4,5,6],[7,8,9][1,2,3][4,5,6][7,8,9]在这种情况下,对角线是1+5+9=153+5+7=15所以总和为15+15=30我想我可以做类似的事情diagonal_sum=0foriin0..2forjin0..2diagonal_sum+=array[i][j]endend
我有一个字符串数组,我需要从中提取第一个单词,将它们转换为整数并获得它们的总和。示例:["5Apple","5Orange","15Grapes"]预期输出=>25我的尝试:["5","5","15"].map(&:to_i).sum 最佳答案 我从你的问题中找到了答案。["5Apple","5Orange","15Grapes"].map(&:to_i).sum在数组中,如果存在任何整数可转换值,那么它将自动转换为整数。 关于arrays-字符串数组中字符串第一部分的总和,我们在Sta
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
我有一个存储JSON数据的列。当它处于编辑状态时,我不知道如何显示它。serialize:value,JSON=f.fields_for:valuedo|ff|.form-group=ff.label:short=ff.text_field:short,class:'form-control'.form-group=ff.label:long=ff.text_field:long,class:'form-control' 最佳答案 代替=f.fields_for:valuedo|ff|请使用以下代码:=f.fields_for:va
在RubyonRails中,如果数组为空,则具有序列化数组字段的模型将不会在.save()上更新,而它之前有数据。我正在使用:ruby2.2.1rails4.2.1sqlite31.3.10我创建了一个字段设置为文本的新模型:railsgmodel用户名:stringexample:text在我添加的User.rb文件中:serialize:example,Array我实例化了User类的一个新实例:test=User.new然后我保存用户以确保它正确保存:test.save()(0.1ms)begintransactionSQL(0.4ms)INSERTINTO"users"("cr
是否可以在使用YAML.load_file时强制Ruby调用初始化方法?我想调用该方法以便为我不序列化的实例变量提供值。我知道我可以将代码分解成一个单独的方法并在调用YAML.load_file之后调用该方法,但我想知道是否有更优雅的方法来处理这个问题。 最佳答案 我认为你做不到。由于您要添加的代码确实特定于要反序列化的类,因此您应该考虑在类中添加该功能。例如,让Foo成为您要反序列化的类,您可以添加一个类方法,例如:classFoodefself.from_yaml(yaml)foo=YAML::load(yaml)#editth
我有以下工厂:FactoryGirl.definedofactory:foodosequence(:name){|n|"Foo#{n}"}trait:ydosequence(:name){|n|"Fooy#{n}"}endendend如果我跑create:foocreate:foocreate:foo,:y我得到Foo1,Foo2,Fooy1。但我想要Foo1,Foo2,Fooy3。我怎样才能做到这一点? 最佳答案 经过smile2day'sanswer的一些提示后和thisanswer,我得出以下解决方案:FactoryGirl.