第一章 从零构建ResNet18
第二章 从零构建ResNet50
文章目录
ResNet 目前是应用很广的网络基础框架,所以有必要了解一下,并且resnet结构清晰,适合练手
pytorch就更不用多说了。(坑自坑 ) 懂自懂
本文使用以下环境构筑
torch 1.11
torchvision 0.12.0
python 3.9
深度残差网络(Deep residual network, ResNet)的提出是CNN图像史上的一件里程碑事件,具体多牛,大家自己某度咯。ResNet的作者何恺明也因此摘得CVPR2016最佳论文奖,当然何博士的成就远不止于此,感兴趣的也可以去搜一下他后来的辉煌战绩。下面简单讲述ResNet的理论及实现。
深度网络的退化问题至少说明深度网络不容易训练。但是我们考虑这样一个事实:现在你有一个浅层网络,你想通过向上堆积新层来建立深层网络,一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即这样新层是恒等映射(Identity mapping)。在这种情况下,深层网络应该至少和浅层网络性能一样,也不应该出现退化现象。
这个有趣的假设让何博士灵感爆发,他提出了残差学习来解决退化问题。对于一个堆积层结构(几层堆积而成)。对于一个堆积层结构(几层堆积而成)当输入为 x时其学习到的特征记为F(x), 现在再加一条分支,直接跳到堆积层的输出,则此时最终输出H(x) = F(x) + x
如下图
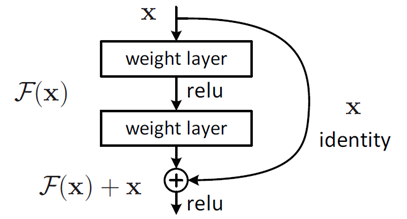
这种跳跃连接就叫做shortcut connection(类似电路中的短路)。具体原理这边不展开叙说,感兴趣的可以去看原论文。上面这种两层结构的叫BasicBlock,一般适用于ResNet18和ResNet34,而ResNet50以后都使用下面这种三层的残差结构叫Bottleneck
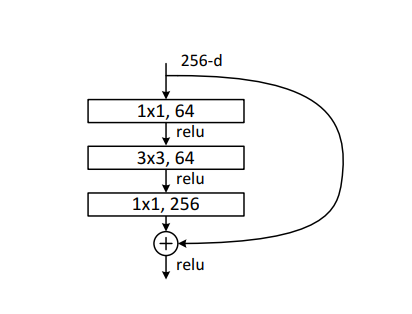
上面简单说了以下残差网络与普通卷积的区别,接下来用图来看一下网络的结构
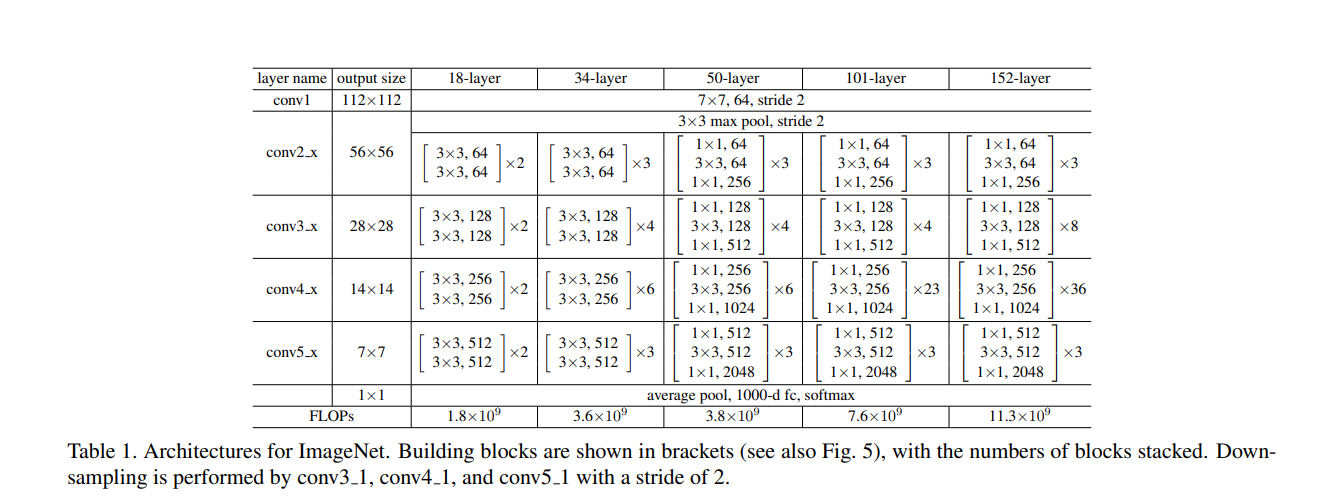
可以看到,18层的网络有五个部分组成,从conv2开始,每层都有两个有残差块,并且每个残差块具有2个卷积层。接下来再具体看看18层以及50层的具体结构
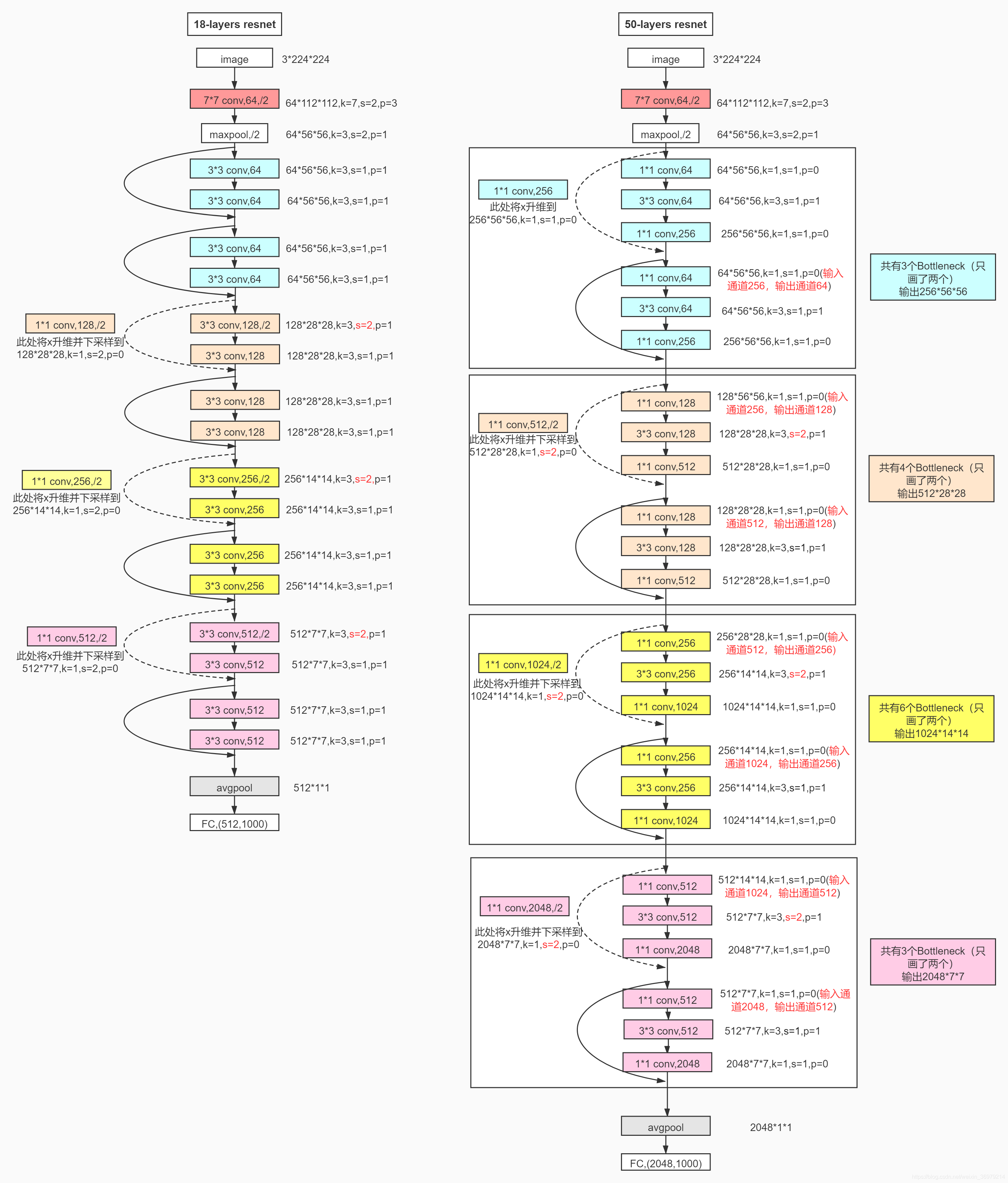
其中,蓝色部分为conv2,然后往下依次按颜色划分为conv3、conv4,conv5。需要注意的是,从conv3开始,第一个残差块的第一个卷积层的stride为2,这是每层图片尺寸变化的原因。另外,stride为2的时候,每层的维度也就是channel也发生了变化,这这时候,残差与输出不是直接相连的,因为维度不匹配,需要进行升维,也就是上图中虚线连接的残差块,实线部分代表可以直接相加.
首先实现残差块:
class BasicBlock(nn.Module):
def __init__(self,in_channels,out_channels,stride=[1,1],padding=1) -> None:
super(BasicBlock, self).__init__()
# 残差部分
self.layer = nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size=3,stride=stride[0],padding=padding,bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True), # 原地替换 节省内存开销
nn.Conv2d(out_channels,out_channels,kernel_size=3,stride=stride[1],padding=padding,bias=False),
nn.BatchNorm2d(out_channels)
)
# shortcut 部分
# 由于存在维度不一致的情况 所以分情况
self.shortcut = nn.Sequential()
if stride[0] != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
# 卷积核为1 进行升降维
# 注意跳变时 都是stride==2的时候 也就是每次输出信道升维的时候
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride[0], bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = self.layer(x)
out += self.shortcut(x)
out = F.relu(out)
return out
接下来是ResNet18的具体实现
# 采用bn的网络中,卷积层的输出并不加偏置
class ResNet18(nn.Module):
def __init__(self, BasicBlock, num_classes=10) -> None:
super(ResNet18, self).__init__()
self.in_channels = 64
# 第一层作为单独的 因为没有残差快
self.conv1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3,bias=False),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# conv2_x
self.conv2 = self._make_layer(BasicBlock,64,[[1,1],[1,1]])
# conv3_x
self.conv3 = self._make_layer(BasicBlock,128,[[2,1],[1,1]])
# conv4_x
self.conv4 = self._make_layer(BasicBlock,256,[[2,1],[1,1]])
# conv5_x
self.conv5 = self._make_layer(BasicBlock,512,[[2,1],[1,1]])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
#这个函数主要是用来,重复同一个残差块
def _make_layer(self, block, out_channels, strides):
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
# out = F.avg_pool2d(out,7)
out = self.avgpool(out)
out = out.reshape(x.shape[0], -1)
out = self.fc(out)
return out
可以输出网络结构看一下
res18 = ResNet18(BasicBlock)
print(res18)
ResNet18(
(conv1): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(conv2): Sequential(
(0): BasicBlock(
(layer): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
(1): BasicBlock(
(layer): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(conv3): Sequential(
(0): BasicBlock(
(layer): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(layer): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(conv4): Sequential(
(0): BasicBlock(
(layer): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(layer): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(conv5): Sequential(
(0): BasicBlock(
(layer): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(layer): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential()
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=10, bias=True)
)
至此,Resnet18就构建好了
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, utils
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data.dataset import Dataset
from torchvision.transforms import transforms
from pathlib import Path
import cv2
from PIL import Image
import torch.nn.functional as F
%matplotlib inline
%config InlineBackend.figure_format = 'svg' # 控制显示
transform = transforms.Compose([ToTensor(),
transforms.Normalize(
mean=[0.5,0.5,0.5],
std=[0.5,0.5,0.5]
),
transforms.Resize((224, 224))
])
training_data = datasets.CIFAR10(
root="data",
train=True,
download=True,
transform=transform,
)
testing_data = datasets.CIFAR10(
root="data",
train=False,
download=True,
transform=transform,
)
class BasicBlock(nn.Module):
def __init__(self,in_channels,out_channels,stride=[1,1],padding=1) -> None:
super(BasicBlock, self).__init__()
# 残差部分
self.layer = nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size=3,stride=stride[0],padding=padding,bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True), # 原地替换 节省内存开销
nn.Conv2d(out_channels,out_channels,kernel_size=3,stride=stride[1],padding=padding,bias=False),
nn.BatchNorm2d(out_channels)
)
# shortcut 部分
# 由于存在维度不一致的情况 所以分情况
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
# 卷积核为1 进行升降维
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride[0], bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
# print('shape of x: {}'.format(x.shape))
out = self.layer(x)
# print('shape of out: {}'.format(out.shape))
# print('After shortcut shape of x: {}'.format(self.shortcut(x).shape))
out += self.shortcut(x)
out = F.relu(out)
return out
# 采用bn的网络中,卷积层的输出并不加偏置
class ResNet18(nn.Module):
def __init__(self, BasicBlock, num_classes=10) -> None:
super(ResNet18, self).__init__()
self.in_channels = 64
# 第一层作为单独的 因为没有残差快
self.conv1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3,bias=False),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# conv2_x
self.conv2 = self._make_layer(BasicBlock,64,[[1,1],[1,1]])
# self.conv2_2 = self._make_layer(BasicBlock,64,[1,1])
# conv3_x
self.conv3 = self._make_layer(BasicBlock,128,[[2,1],[1,1]])
# self.conv3_2 = self._make_layer(BasicBlock,128,[1,1])
# conv4_x
self.conv4 = self._make_layer(BasicBlock,256,[[2,1],[1,1]])
# self.conv4_2 = self._make_layer(BasicBlock,256,[1,1])
# conv5_x
self.conv5 = self._make_layer(BasicBlock,512,[[2,1],[1,1]])
# self.conv5_2 = self._make_layer(BasicBlock,512,[1,1])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
#这个函数主要是用来,重复同一个残差块
def _make_layer(self, block, out_channels, strides):
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
# out = F.avg_pool2d(out,7)
out = self.avgpool(out)
out = out.reshape(x.shape[0], -1)
out = self.fc(out)
return out
# 保持数据集和测试机能完整划分
batch_size=100
train_data = DataLoader(dataset=training_data,batch_size=batch_size,shuffle=True,drop_last=True)
test_data = DataLoader(dataset=testing_data,batch_size=batch_size,shuffle=True,drop_last=True)
images,labels = next(iter(train_data))
print(images.shape)
img = utils.make_grid(images)
img = img.numpy().transpose(1,2,0)
mean=[0.5,0.5,0.5]
std=[0.5,0.5,0.5]
img = img * std + mean
print([labels[i] for i in range(64)])
plt.imshow(img)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = res18.to(device)
cost = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
print(len(train_data))
print(len(test_data))
epochs = 10
for epoch in range(epochs):
running_loss = 0.0
running_correct = 0.0
model.train()
print("Epoch {}/{}".format(epoch+1,epochs))
print("-"*10)
for X_train,y_train in train_data:
# X_train,y_train = torch.autograd.Variable(X_train),torch.autograd.Variable(y_train)
X_train,y_train = X_train.to(device), y_train.to(device)
outputs = model(X_train)
_,pred = torch.max(outputs.data,1)
optimizer.zero_grad()
loss = cost(outputs,y_train)
loss.backward()
optimizer.step()
running_loss += loss.item()
running_correct += torch.sum(pred == y_train.data)
testing_correct = 0
test_loss = 0
model.eval()
for X_test,y_test in test_data:
# X_test,y_test = torch.autograd.Variable(X_test),torch.autograd.Variable(y_test)
X_test,y_test = X_test.to(device), y_test.to(device)
outputs = model(X_test)
loss = cost(outputs,y_test)
_,pred = torch.max(outputs.data,1)
testing_correct += torch.sum(pred == y_test.data)
test_loss += loss.item()
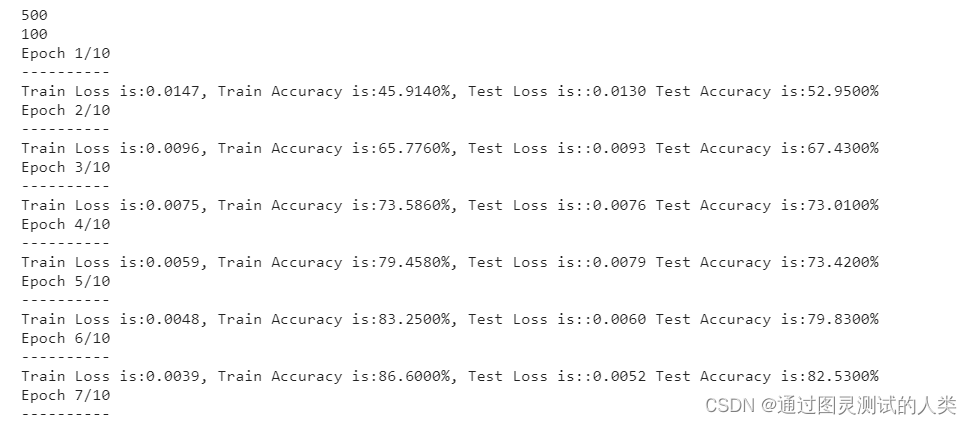
print("Train Loss is:{:.4f}, Train Accuracy is:{:.4f}%, Test Loss is::{:.4f} Test Accuracy is:{:.4f}%".format(
running_loss/len(training_data), 100*running_correct/len(training_data),
test_loss/len(testing_data),
100*testing_correct/len(testing_data)
))
可以看看结果 还是不错的
到目前为止,pytorch构建resnet18就完成了。接下来会构建50
通过手写网络,可以加深对网络的理解,同时运用pytorch更加熟练。
PS: 此博客同时更新于个人博客
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
我看到这个错误:translationmissing:da.datetime.distance_in_words.about_x_hours我的语言环境文件:http://pastie.org/2944890我的看法:我已将其添加到我的application.rb中:config.i18n.load_path+=Dir[Rails.root.join('my','locales','*.{rb,yml}').to_s]config.i18n.default_locale=:da如果我删除I18配置,帮助程序会处理英语。更新:我在config/enviorments/devolpment
如果我使用ruby版本2.5.1和Rails版本2.3.18会怎样?我有基于rails2.3.18和ruby1.9.2p320构建的rails应用程序,我只想升级ruby的版本,而不是rails,这可能吗?我必须面对哪些挑战? 最佳答案 GitHub维护apublicfork它有针对旧Rails版本的分支,有各种变化,它们一直在运行。有一段时间,他们在较新的Ruby版本上运行较旧的Rails版本,而不是最初支持的版本,因此您可能会发现一些关于需要向后移植的有用提示。不过,他们现在已经有几年没有使用2.3了,所以充其量只能让更
大家好!我对我的:username字段进行了一个小的验证,它应该是4到30个字符。我写了一个验证::length=>{:within=>4..30,:message=>I18n.t('activerecord.errors.range')-我想显示一个错误各种错误的消息(不像,太长或太短),但这里有一个问题-我可以将最小值和最大值都传递给翻译,以便有类似的东西:用户名应该在4到30个字符之间。目前我有:range:"shouldbebetween%{count}and%{count}characters",这显然不起作用(只是为了检查)。是否可以从范围中获取这些值?谢谢大家的指教!
在编写Ruby(客户端脚本)时,我看到了三种构建更长字符串的方法,包括行尾,所有这些对我来说“闻起来”有点难看。有没有更干净、更好的方法?变量递增。ifrender_quote?quote="NowthatthereistheTec-9,acrappyspraygunfromSouthMiami."quote+="ThisgunisadvertisedasthemostpopularguninAmericancrime.Doyoubelievethatshit?"quote+="Itactuallysaysthatinthelittlebookthatcomeswithit:themo
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
我正在尝试在配备ARMv7处理器的SynologyDS215j上安装ruby2.2.4或2.3.0。我用了optware-ng安装gcc、make、openssl、openssl-dev和zlib。我根据README中的说明安装了rbenv(版本1.0.0-19-g29b4da7)和ruby-build插件。.这些是随optware-ng安装的软件包及其版本binutils-2.25.1-1gcc-5.3.0-6gconv-modules-2.21-3glibc-opt-2.21-4libc-dev-2.21-1libgmp-6.0.0a-1libmpc-1.0.2-1libm
关闭。这个问题需要更多focused.它目前不接受答案。想改进这个问题吗?更新问题,使其只关注一个问题editingthispost.关闭8年前。Improvethisquestion我们有以下(以及更多)系统,我们将数据从一个应用推送/拉取到另一个:托管CRM(InsideSales.com)Asterisk电话系统(内部)横幅广告系统(openx,我们托管)潜在客户生成系统(自行开发)电子商务商店(spree,我们托管)工作板(本土)一些工作网站抓取+入站工作提要电子邮件传送系统(如Mailchimp,自主开发)事件管理系统(如eventbrite,自主开发)仪表板系统(大量图表和
如果特定语言环境中缺少翻译,如何配置i18n以使用en语言环境翻译?当前已插入翻译缺失消息。我正在使用RoR3.1。 最佳答案 找到相似的question这里是答案:#application.rb#railswillfallbacktoconfig.i18n.default_localetranslationconfig.i18n.fallbacks=true#railswillfallbacktoen,nomatterwhatissetasconfig.i18n.default_localeconfig.i18n.fallback
我正在使用Enumerizegemhttps://github.com/brainspec/enumerize/它允许我以简单的形式使用漂亮的选择。并且此选择中的所有选项均已翻译。en:enumerize:user:sex:male:'Man'female:'Woman'所以,在我的表单中,我选择了变体“男人”和“女人”。当我用“男人”值保存记录时,我得到了“男性”值的性别属性。现在我想在显示页面上将该值显示为“Man”,但是=@user.sex输出为'male'而不是'Man' 最佳答案 我可能会使用.text方法(您可以通过使用