年轻代使用mimor GC速度快,老年代使用full GC速度就会慢很多。
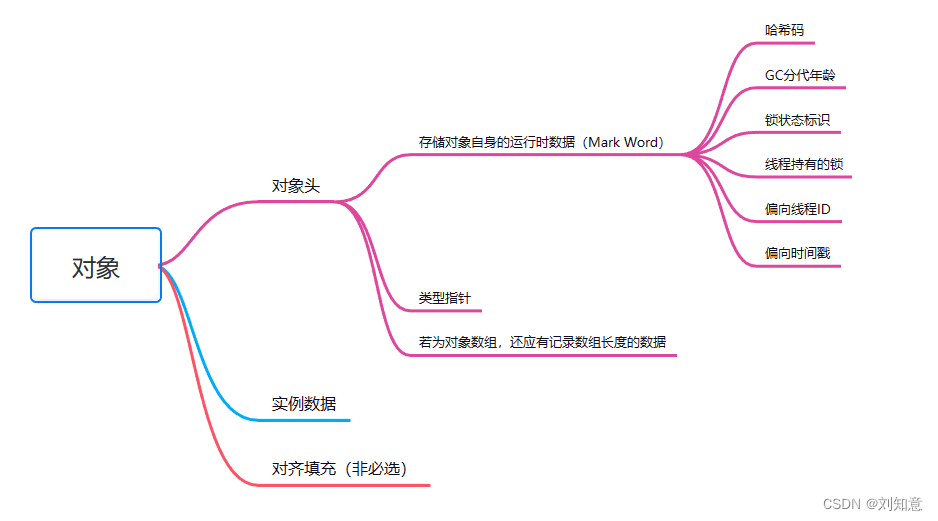
Dalvik虚拟机内存分配:
ART:
Non Moving Space
Zygote Space
Alloc Space
Image Space:预加载的类信息
Large Obj Space:分配大对象 如bitmap
可达性分析算法GCoot:
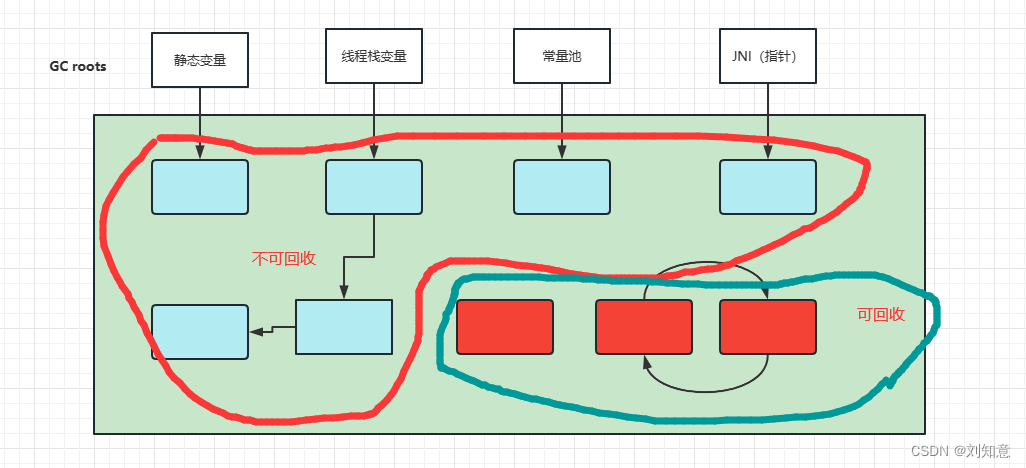
强引用
软引用:GC扫描到不一定被回收,只有内存不足时才会被回收
弱引用:被GC扫描到就会被回收
虚引用:没有引用
特点:
位置不连续,产生碎片,效率略低,两次扫描
多次扫描后会产生大量内存碎片
特点:
实现简单,运行高效,没有内存碎片,利用率只有一半
假设内存又4M,使用的只有2M
特点:
没有内存碎片,效率偏低,两遍扫描,指针需要调整
扫描标记可回收后,整理存活对象和可回收对象,分区
综合运用
新生区对象存活低使用复制算法,老年区对象存活久,清除频率低,使用标记算法
Android给每个app分配一个VM,让app运行在dalvik上,这样即使app崩溃也不会影响到系统。系统给VM分配了一定的内存大小,app可以申请使用的内存大小不能超过此硬件逻辑限制,就算物理内存富余,如果应用超过VM最大内存,就会出现内存溢出crash。
由程序控制操作的内存空间在heap上,分java heapsize 和native heapsize。
查看App内存限制
adb shell
cat /system/build.prop
通过代码获取
ActivityManager activityManager = (ActivityManager)getBaseContext().getSystemService(Context.ACCESSIBILITY_SERVICE);
activityManager.getMemoryClass();
ams为什么能获取:因为 ams.setsystemprocess中的meminfobinder调用底层内存信息
app:内存 大小 每个厂商机型给初始分配内存不同 源码中有两个地方可以修改
1./frameworks/base/core/jni/AndroidRuntime.cpp
parseRuntimeOption("dalvik.vm.heapstartsize", heapstartsizeOptsBuf, "-Xms", "4m");
parseRuntimeOption("dalvik.vm.heapsize", heapsizeOptsBuf, "-Xmx", "16m"); //修改这里
OOM解决问题 :主动获取了解当前app的内存使用情况
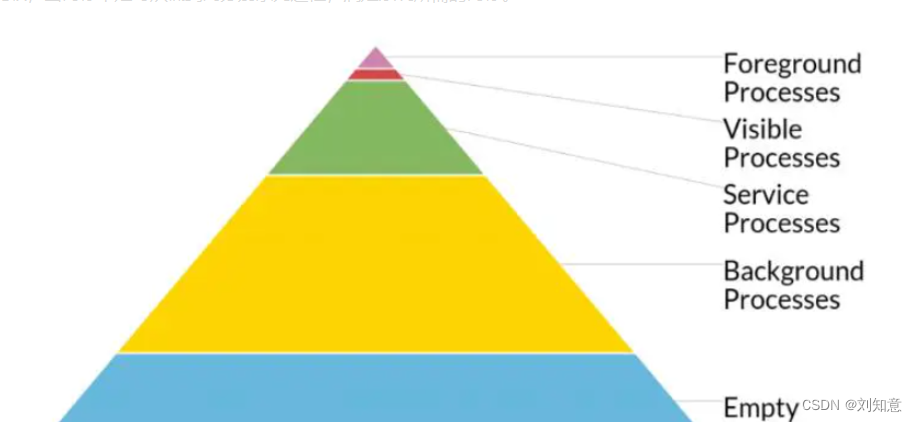
app运行时,点击home app挂到后台 不会立马被系统杀掉,开多应用挂后台,安卓系统给应用分级
数字越大越容易被系统杀掉,粗粒度
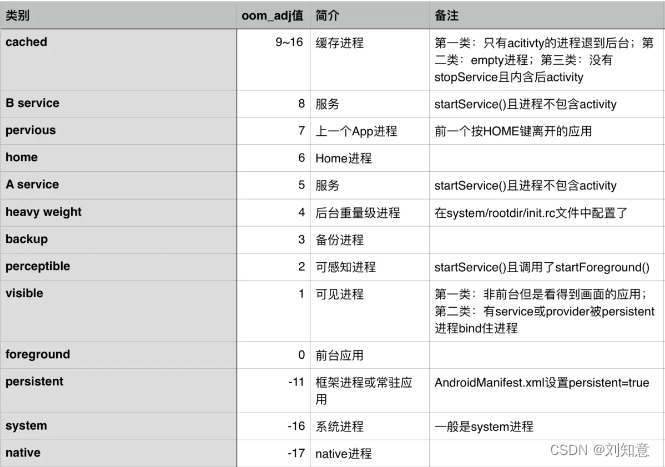
app: 前台可见 oom_adj 0,后台2
oom_score_adj [-1000,1000] 更细粒度杀进程
adb shell下使用 cat /proc/进程号/oom_adj即可查询该应用的oom_adj值
若两个应用a 和b oom_adj值都是11 则谁占用内存多杀谁
所以要尽量降低应用进入后台的内存
1.内存抖动
内存波动图呈锯齿状,GC导致卡顿
在AS中的Profiler中使用查看波动图,内存抖动会频繁GC,如自定义view中的ondraw()中频繁创建销毁画笔路径等,最后会导致内存千疮百孔
2.内存泄漏
在当前应用周期内不再使用的对象被GC Roots引用,导致不能回收,使实际可使用内存变小
产生泄漏之后不会立马导致应用崩溃,1个地方存在泄漏,程序跑久了之后,内存泄漏会一直积攒着,达到OOM级别,会导致应用低内存,会导致发热,耗电更严重的导致内存溢出
**注:**OOM不是只代表Java堆内存溢出。还因为无足够连续内存空间:FD(文件句柄,数字)数量超出限制;线程数量超出限制;虚拟内存不足;
3.内存溢出
即OOM,OOM时会导致程序异常。Android设备出厂后,Java虚拟机对单个应用的最大分配内存就确定下来了,超出这个值就会OOM
常用内存调优分析命令:
内存指标概念:
| Item | 全称 | 含义 | 等价 |
|---|---|---|---|
| USS | Unique Set Size | 物理内存 | 进程独占的内存 |
| PSS | Proportional Set Size | 物理内存 | PSS=USS+按比例包含共享库 |
| RSS | Resident Set Size | 物理内存 | RSS=USS+包含共享库 |
| VSS | Virtual Set Size | 虚拟内存 | VSS=RSS+未分配实例物理内存 |
总结:VSS>=RSS>=PSS>=USS,但/dev/kgsl-3d0部分必须考虑VSS 看的时候主要看PSS

dumpsys meminfo --package + 包名可以查看具体应用的内存情况
总结:
被持有
持有
hprof-conv xxx.hprof 转一下即可用MAT打开内存快照
单独自己的占用大小
总计引用占用大小
最近因为项目需要,需要将Android手机系统自带的某个系统软件反编译并更改里面某个资源,并重新打包,签名生成新的自定义的apk,下面我来介绍一下我的实现过程。APK修改,分为以下几步:反编译解包,修改,重打包,修改签名等步骤。安卓apk修改准备工作1.系统配置好JavaJDK环境变量2.需要root权限的手机(针对系统自带apk,其他软件免root)3.Auto-Sign签名工具4.apktool工具安卓apk修改开始反编译本文拿Android系统里面的Settings.apk做demo,具体如何将apk获取出来在此就不过多介绍了,直接进入主题:按键win+R输入cmd,打开命令窗口,并将路
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分
LL库和HAL库简介LL:Low-Layer,底层库HAL:HardwareAbstractionLayer,硬件抽象层库LL库和hal库对比,很精简,这实际上是一个精简的库。LL库的配置选择如下:在STM32CUBEMX中,点击菜单的“ProjectManager”–>“AdvancedSettings”,在下面的界面中选择“AdvancedSettings”,然后在每个模块后面选择使用的库总结:1、如果使用的MCU是小容量的,那么STM32CubeLL将是最佳选择;2、如果结合可移植性和优化,使用STM32CubeHAL并使用特定的优化实现替换一些调用,可保持最大的可移植性。另外HAL和L
是否存在GC.disable会降低性能的情况?只要我使用的是真正的RAM而不是交换内存,就可以这样做吗?我正在使用MRIRuby2.0,据我所知,它是64位的,并且使用的是64位的Ubuntu:ruby2.0.0p0(2013-02-24revision39474)[x86_64-linux]Linux[redacted]3.2.0-43-generic#68-UbuntuSMPWedMay1503:33:33UTC2013x86_64x86_64x86_64GNU/Linux 最佳答案 GC.disable将禁用垃圾回收。像rub
我希望Ruby的解析器会进行这种微不足道的优化,但似乎并没有(谈到YARV实现,Ruby1.9.x、2.0.0):require'benchmark'deffib1a,b=0,1whileb由于这两种方法除了在第二种方法中使用预定义常量而不是常量表达式外是相同的,因此Ruby解释器似乎在每个循环中一次又一次地计算幂常数。是否有一些Material说明为什么Ruby根本不进行这种基本优化或只在某些特定情况下进行? 最佳答案 很抱歉给出了另一个答案,但我不想删除或编辑我之前的答案,因为它下面有有趣的讨论。正如JörgWMittag所说,
我尝试在Internet上搜索有关使用angularJS进入RubyonRails项目与RubyonRailspure的View性能的信息。我的问题是因为2个月前我开始使用纯AngularJS,现在我需要将AngularJS集成到一个新项目中,但需要展示使用带有RubyonRails的AngularJS呈现View的性能如何,并消除对RubyonRails的负担.例如:带Rails的Angular:使用RubyonRails获取数据(从数据库或GET请求),将信息发送到file.js.erb并使用AngularJS操作数据并显示带有解析数据的View。纯粹的Rails:(自然流程)使用
我觉得我理解require和require_dependency之间的区别(来自Howarerequire,require_dependencyandconstantsreloadingrelatedinRails?)。但是,我想知道如果我使用一些不同的方法(参见http://hemju.com/2010/09/22/rails-3-quicktip-autoload-lib-directory-including-all-subdirectories/和Bestwaytoloadmodule/classfromlibfolderinRails3?)来加载所有文件会发生什么,所以我们: