上文(【Codelabs挑战赛示例讲解1】核酸检测结果认证查询系统-认证登录)实现了核酸检测结果认证查询系统的认证登录部分的功能,认证登录完成后,接下来便是要实现核酸检测结果数据的导入与查询功能。
云数据库是一款端云协同的数据库产品,提供端云数据的协同管理、统一的数据模型和丰富的数据管理API接口等能力,完全可以满足数据的查询功能。
《Codelabs挑战赛——零基础搭建认证查询系统》活动正在火热进行中,分享作品有机会获得华为freebuds pro无线耳机、华为手环6nfc版、联盟背包等丰厚大礼,快来参与吧>>https://developer.huawei.com/consumer/cn/forum/topic/0202851788421280176?fid=0102822233052010012
AppGallery Connect以SDK的方式开放了其数据管理功能,在开发数据管理功能之前,首先需要先集成云数据库SDK,且需要下载AGC提供的JSON文件获取应用的基本信息和数据处理位置信息等;其次,数据的展示需要依赖表格,此次我们选取了开源的自动化表格框架-SmartTable,同样也需要先集成SDK。
1. 集成云数据库和SmartTable SDK之前,请确保您已经完成maven仓、AGC插件及编译依赖的集成。
2. 在应用级build.gradle文件下配置集成云数据库和SmartTable SDK。
dependencies {
//agc-core的依赖
implementation 'com.huawei.agconnect:agconnect-core:1.6.0.300'
implementation 'androidx.appcompat:appcompat:1.3.0'
implementation 'com.google.android.material:material:1.3.0'
implementation 'androidx.constraintlayout:constraintlayout:2.0.4'
testImplementation 'junit:junit:4.+'
androidTestImplementation 'androidx.test.ext:junit:1.1.3'
androidTestImplementation 'androidx.test.espresso:espresso-core:3.4.0'
//云数据库sdk
implementation 'com.huawei.agconnect:agconnect-cloud-database:1.4.9.300'
compile 'com.github.huangyanbin:SmartTable:2.0'
}上述SDK或依赖添加完成后,需要点击右上角“Sync Now”等待同步完成。
1. 登录AGC管理台,点击“我的项目”,选择之前创建的项目。
2. 在菜单目录下找到“构建-云数据库”,点击右上角“立即开通”,开通后界面如下,至此,云数据库服务已经开通成功。
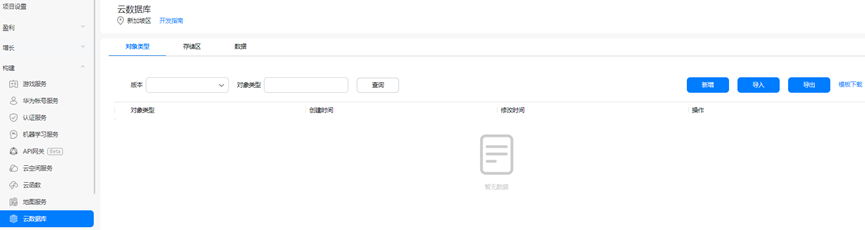
在对云数据库进行管理前,需要先新增云数据库数据对象。数据对象主要规定了数据库存储区中数据的类型,后续可以到处为对象添加到项目中使用。
1. 在云数据服务界面选择“对象类型”页签,点击“新增”,对象类型填写“personInfo”,新增“id”、“name”、“age”、“hasInoculate”、“cardNo”字段用于存储检测人群的身份数据。
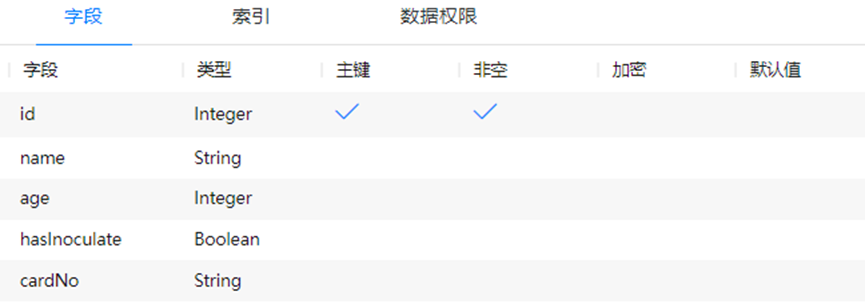
2. 设置对象类型的索引或者对象类型中对某个字段的索引。此处我只设置了对name的索引,可酌情设置。
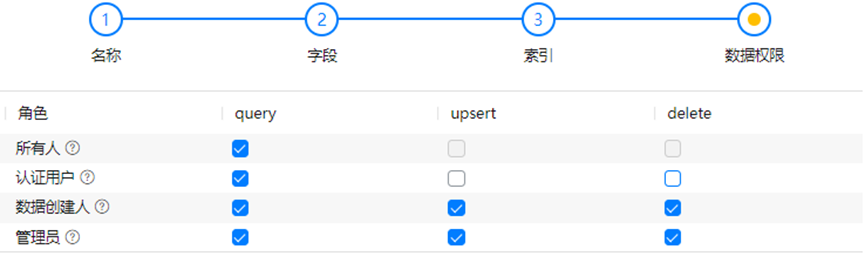
3. 设置数据管理的权限,此处按我的产品定位选的是管理员和数据创建人拥有所有权限即可。更多角色查看可参考权限管理。
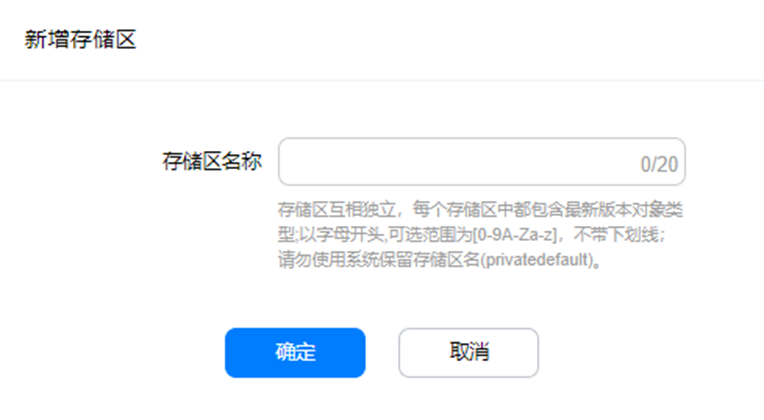
数据的增删查需要在数据存储区中进行,在进行上述操作管理某个对象类型的数据前需要先创建存储区。此处,仅需指定存储区的名称即可,而后在代码中往哪个存储区中插入某个对象类型的数据。
在云数据服务界面选择“存储区”页签,点击“新增”,填写存储区名称创建,此处以创建名为“personInfoZone”的存储区为例介绍。
PS:“数据”页签下,可以根据存储区和对象类型查询数据,数据插入后可作为云侧查询数据使用。
您可以选择“手动导入”和“批量导入”两种方式导入检测数据。
1. 手动导入
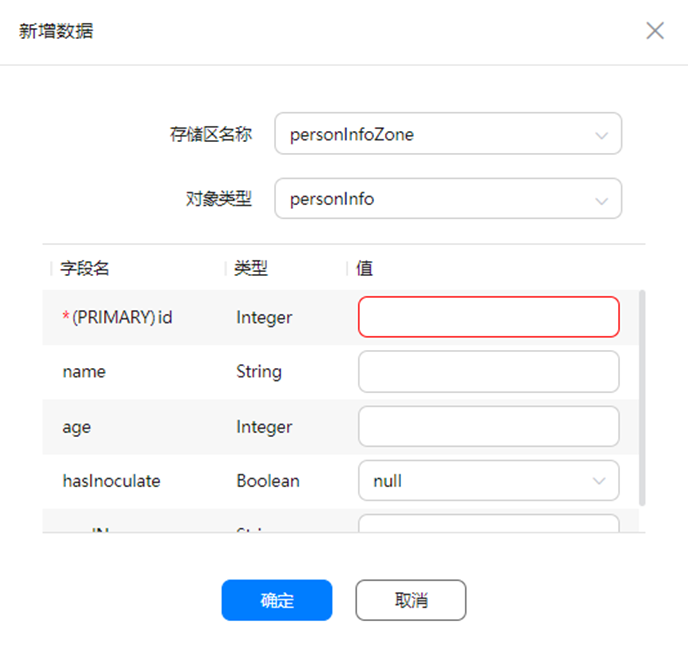
在“数据”页签下,选择创建的对象类型及存储区名称,点击“新增”。

按对象类型中的字段新增数据,此处以“personInfo”为例介绍:
2. 批量导入
在“数据”页签下,选择创建的对象类型及存储区名称,点击“数据模板”。
说明:数据模板为包含存储区和对象类型信息的示例数据json文件,您可以直接新增数据后导入。

打开数据模板json文件,按对象类型字段新增数据。如下,新增了两条有效数据:
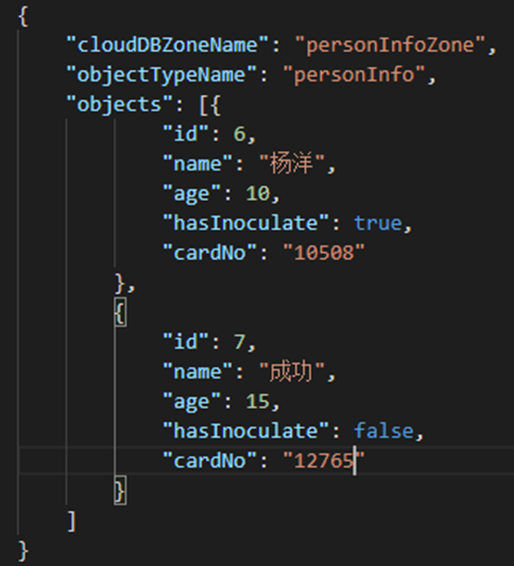
点击“… > 导入”,导入新增的数据,可增量新增json中的数据,如下图:
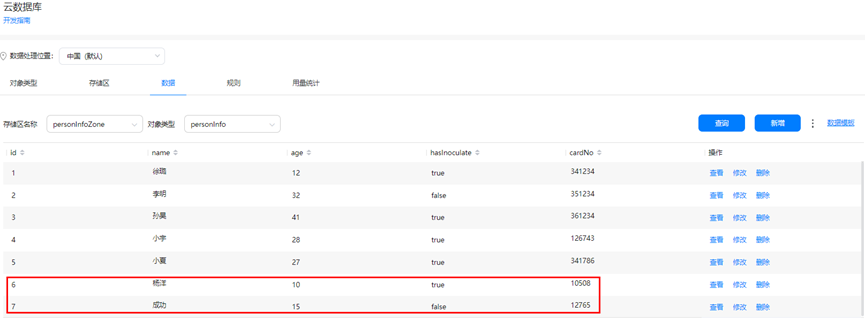
说明:如数据存储在Excel文件中,可先转换为json文件再新增,Excel转json方法请自行Google。
云数据库服务开通后,AGC会将云数据库的对象类型等信息写入JSON文件,故需要重新下载“agconnect-services.json”文件并在Android Studio项目中更新,详细可参考系列上篇的“集成SDK-添加配置文件”章节。
主功能界面的设计比较简单,包含以下内容:
1. 检测数据的展示表格;
2. 登出按钮。
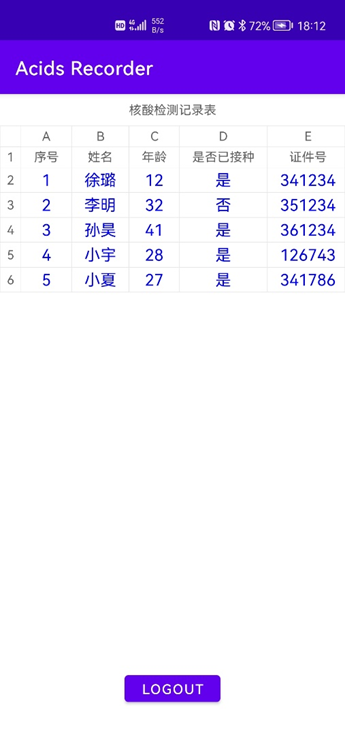
说明:此处为成功查询到数据的界面示例,表格初始时为空。
在开发准备章节新建的数据对象必须先导入Android Studio项目才能在代码中对对象执行新建、插入、修改等操作。具体操作如下:
1. 登录AGC,进入项目下的云数据库服务下。
2. 在对象类型页签下,点击右上角“导出”,导出文件格式选择“java”格式(因为我们开发的是Android项目,针对web等项目,AGC也提供js格式的对象类型格式文件等)。
3. 在src\main\java\com\example\packagename目录下,新建名为model的package,并将刚刚下载的personInfo对象文件和对象帮助文件放在该目录下。
本系统的业务需求为进入主界面即查询导入的检测数据,查询前需要先对数据库进行初始化,详细请参考官方文档-初始化。
1. 初始化AGConnectCloudDB、数据库配置和存储区,初始化后要在生命周期中随时操作数据库,故需要定义以下全局变量。
//初始化数据库
AGConnectCloudDB mCloudDB;
//初始化数据库配置
CloudDBZoneConfig mConfig;
//初始化存储区
CloudDBZone mCloudDBZone;
//初始化表格
private SmartTable table;
//云端数据对象List
private static List<personInfo> personInfoList = new ArrayList<>();2. 完成获取AGConnectCloudDB实例,创建对象类型,打开Cloud DB Zone一系列操作。(personInfo需要换成实际的存储区名称,此处Cloud DB Zone的同步配置属性为缓存模式,访问属性为公共存储区)。
private void initView() {
//初始化云数据库
AGConnectCloudDB.initialize(getApplicationContext());
AGConnectInstance instance = AGConnectInstance.buildInstance(new AGConnectOptionsBuilder().setRoutePolicy(AGCRoutePolicy.CHINA).build(getApplicationContext()));
mCloudDB = AGConnectCloudDB.getInstance(instance, AGConnectAuth.getInstance(instance));
Log.i(TAG,"The cloudDB is" + mCloudDB);
try {
mCloudDB.createObjectType(model.ObjectTypeInfoHelper.getObjectTypeInfo());
mConfig = new CloudDBZoneConfig("personInfoZone",
CloudDBZoneConfig.CloudDBZoneSyncProperty.CLOUDDBZONE_CLOUD_CACHE,
CloudDBZoneConfig.CloudDBZoneAccessProperty.CLOUDDBZONE_PUBLIC);
mConfig.setPersistenceEnabled(true);
Task<CloudDBZone> openDBZoneTask = mCloudDB.openCloudDBZone2(mConfig, true);
openDBZoneTask.addOnSuccessListener(new OnSuccessListener<CloudDBZone>() {
@Override
public void onSuccess(CloudDBZone cloudDBZone) {
Log.i("open clouddbzone", "open cloudDBZone success");
mCloudDBZone = cloudDBZone;
//开始绑定数据
bindData();
// Add subscription after opening cloudDBZone success
//addSubscription();
}
}).addOnFailureListener(new OnFailureListener() {
@Override
public void onFailure(Exception e) {
Log.w("open clouddbzone", "open cloudDBZone failed for " + e.getMessage());
}
});
} catch (AGConnectCloudDBException e) {
Toast.makeText(DatabaseActivity.this, "initialize CloudDB failed" + e, Toast.LENGTH_LONG).show();
}
}1. 上步中bindData函数的作用是将AGC云端导入的数据与SmartTable表格框架绑定,进而展示。
private void bindData() {
CloudDBZoneQuery<personInfo> query = CloudDBZoneQuery.where(personInfo.class);
queryPersonInfo(query);
}private List<personInfo> queryPersonInfo(CloudDBZoneQuery<personInfo> query) {
if (mCloudDBZone == null) {
Log.w(TAG, "CloudDBZone is null, try re-open it");
return null;
}
Task<CloudDBZoneSnapshot<personInfo>> queryTask = mCloudDBZone.executeQuery(query,
CloudDBZoneQuery.CloudDBZoneQueryPolicy.POLICY_QUERY_FROM_CLOUD_ONLY);
//List<personInfo> tmpInfoList = new ArrayList<>();
queryTask.addOnSuccessListener(new OnSuccessListener<CloudDBZoneSnapshot<personInfo>>() {
@Override
public void onSuccess(CloudDBZoneSnapshot<personInfo> snapshot) {
try {
personInfoList = processQueryResult(snapshot);
} catch (AGConnectCloudDBException e) {
Log.e(TAG, "onfailed: "+e.getErrMsg() );
}
Log.i(TAG, "onSuccess: query result success");
}
}).addOnFailureListener(new OnFailureListener() {
@Override
public void onFailure(Exception e) {
mUiCallBack.updateUiOnError("Query failed");
Log.i(TAG, "onSuccess: query result failed");
}
});
return personInfoList;
}2. processQueryResult为处理并展示云端数据的主函数,此处需要将数据对象中的字段添加到list中,并添加到SmartTable中。
private List<personInfo> processQueryResult(CloudDBZoneSnapshot<personInfo> snapshot) throws AGConnectCloudDBException {
CloudDBZoneObjectList<personInfo> bookInfoCursor = snapshot.getSnapshotObjects();
List<personInfo> bookInfoList = new ArrayList<>();
List<PersonInfo> list = new ArrayList<>();
table = findViewById(R.id.table);
try {
while (bookInfoCursor.hasNext()) {
personInfo info = bookInfoCursor.next();
bookInfoList.add(info);
list.add(new PersonInfo(info.getId(),info.getName(),info.getAge(),info.getHasInoculate()==true?"是":"否",info.getCardNo()));
//list.add(new PersonInfo(1,"xuhao",34,true,"12321"));
}
} catch (AGConnectCloudDBException e) {
Log.w(TAG, "processQueryResult: " + e.getMessage());
} finally {
snapshot.release();
mCloudDB.closeCloudDBZone(mCloudDBZone);
}
table.setData(list);
table.getConfig().setContentStyle(new FontStyle(50, Color.BLUE));
mUiCallBack.onAddOrQuery(bookInfoList);
return bookInfoList;
}3. 帐号登出后,系统会跳转到登录界面,调用AGConnectAuth. signOut方法即可,无需过多赘述。
findViewById(R.id.login_out).setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
AGConnectAuth.getInstance().signOut();
Intent intent = new Intent();
intent.setClass(DatabaseActivity.this, LoginActivity.class);
startActivity(intent);
Log.i(TAG, "onClick: log out successfully");
}
});至此,核酸检测结果查询系统的开发工作已全部完成,运行后登录系统即可查询到云数据库云端全部的检测数据。
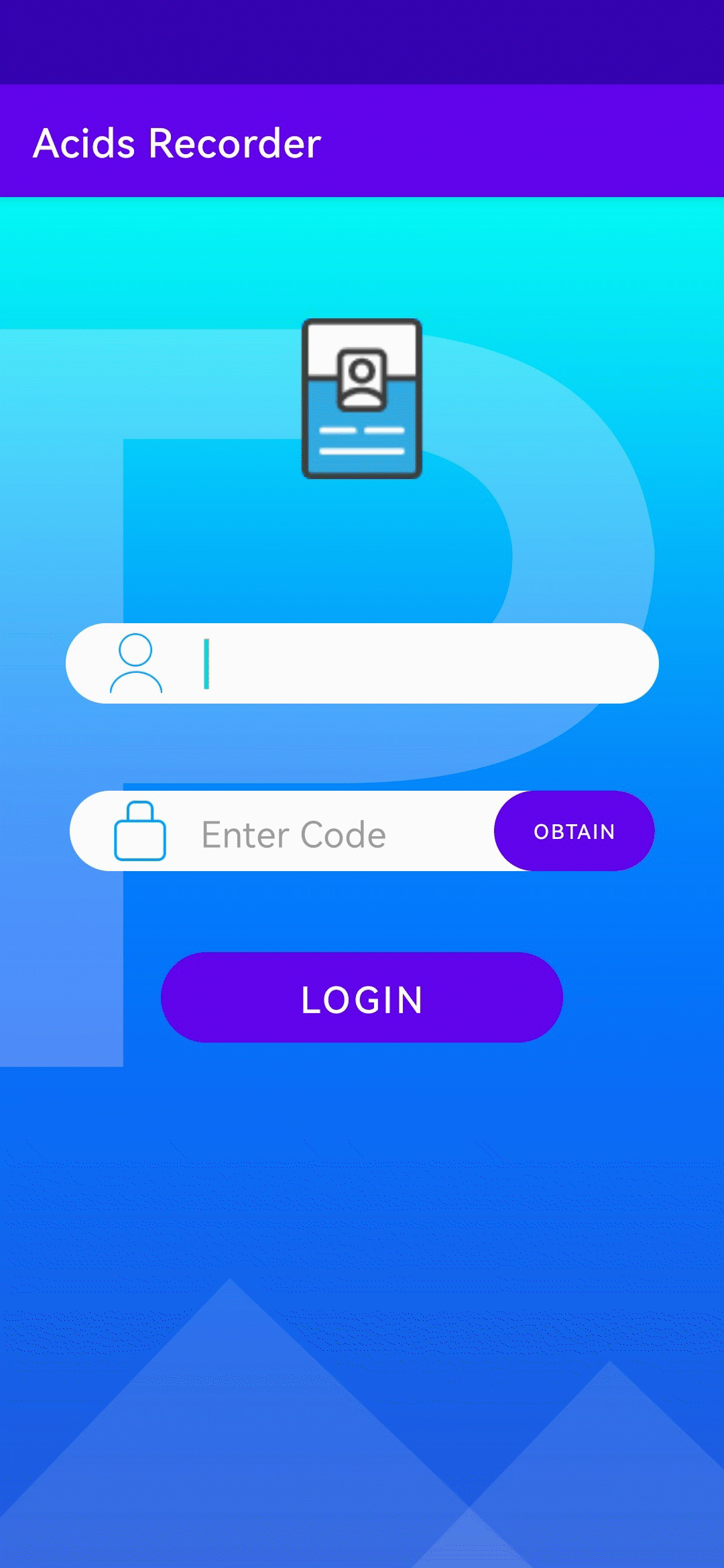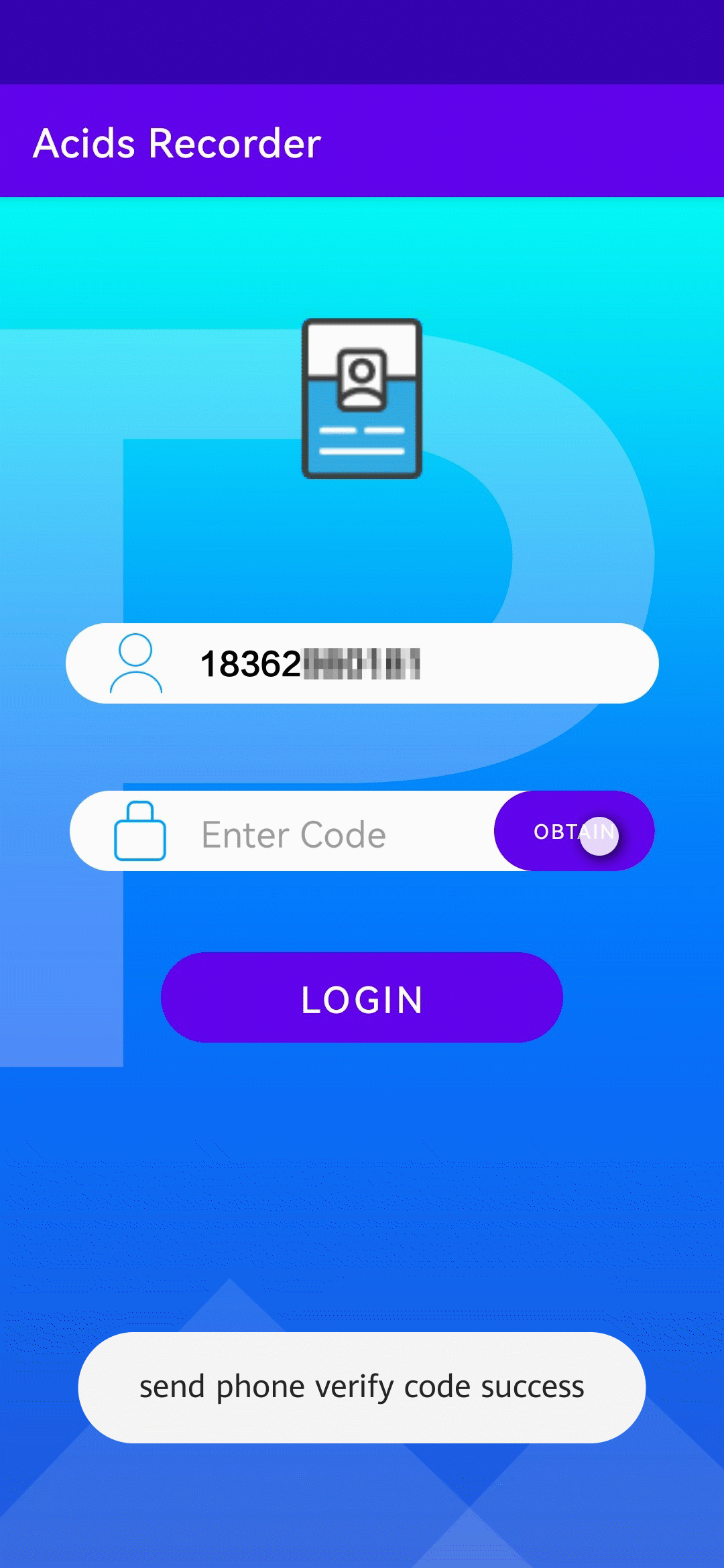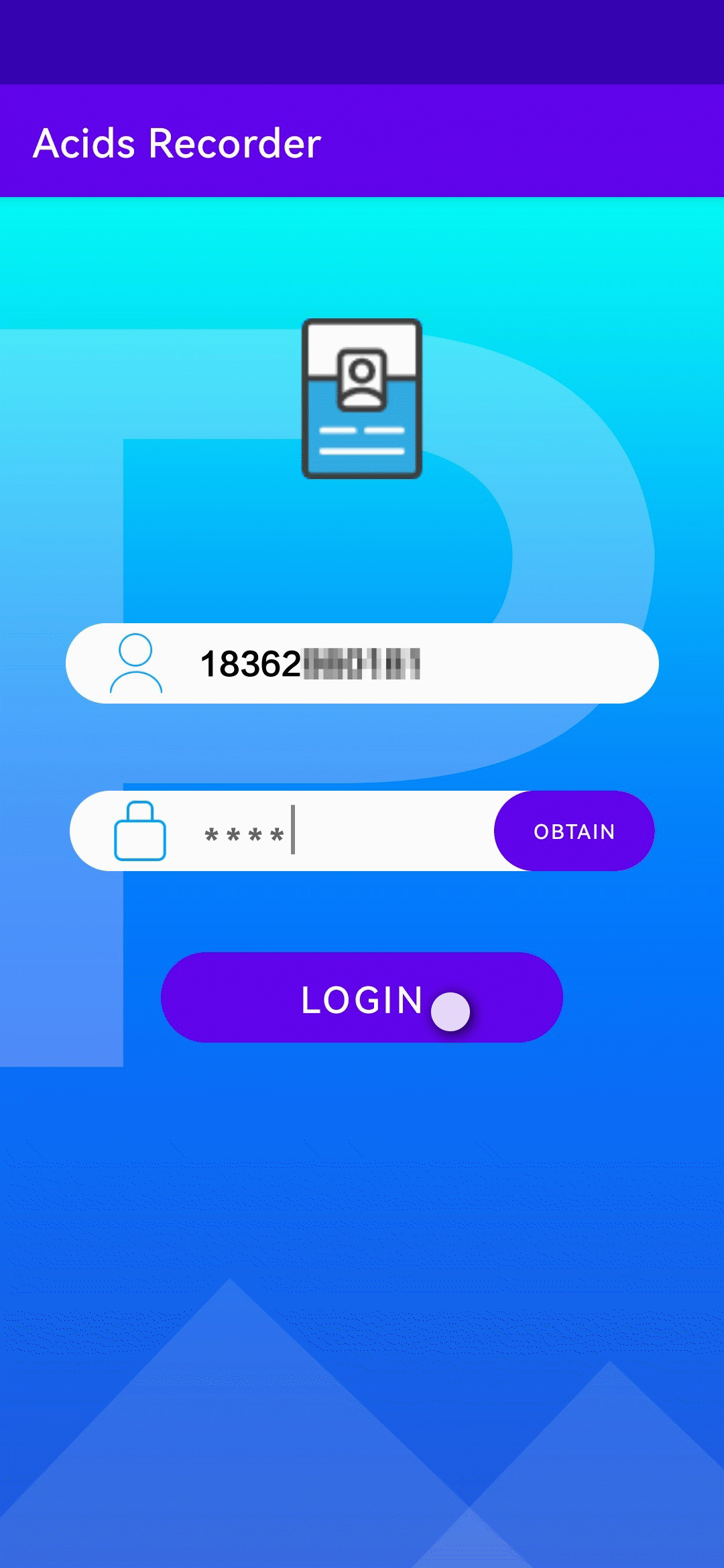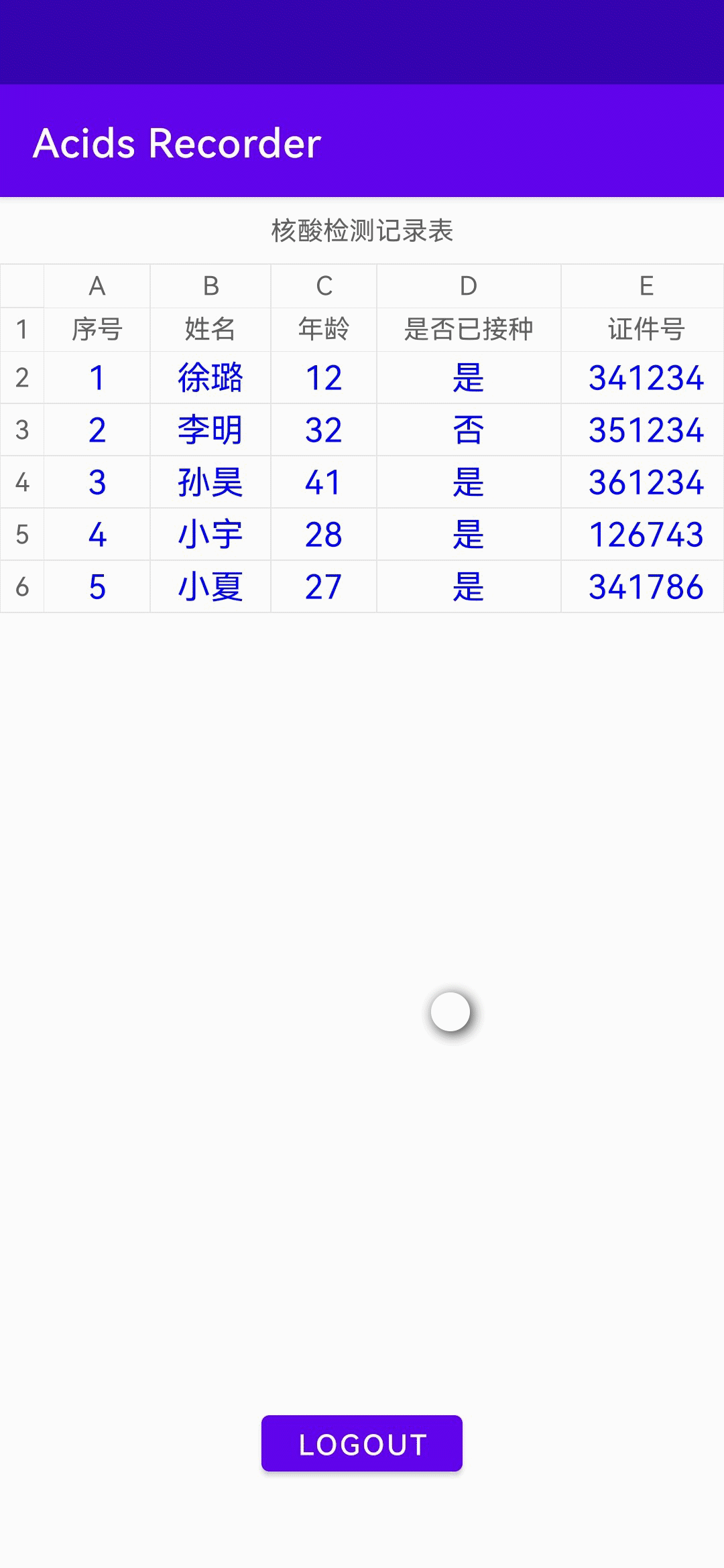
AGC云数据库服务提供的端云数据同步的能力还是非常实用,免除了服务器部署、数据管理等工作量。当然,除了数据查询还可以在系统内直接实现新增或删除数据等常见数据操作,云数据库服务提供的能力远不止查询而已。
至此,我们完成了核酸检测结果系统的功能开发,此系统仅为Codelab挑战赛主题功能的基本实现成功,大家可以基于指导文档和Demo,结合自己的想象,为AGC Serverless服务的构造更多的可能性。
云数据库云端数据查询:
开发准备和集成SDK必读:
SmartTable原项目及集成指导:
https://github.com/huangyanbin/smartTable
附另一篇示例讲解:【Codelabs挑战赛示例讲解1】核酸检测结果认证查询系统-认证登录
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
如何检查Ruby文件是否是通过“require”或“load”导入的,而不是简单地从命令行执行的?例如:foo.rb的内容:puts"Hello"bar.rb的内容require'foo'输出:$./foo.rbHello$./bar.rbHello基本上,我想调用bar.rb以不执行puts调用。 最佳答案 将foo.rb改为:if__FILE__==$0puts"Hello"end检查__FILE__-当前ruby文件的名称-与$0-正在运行的脚本的名称。 关于ruby-检查是否
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我对图像处理完全陌生。我对JPEG内部是什么以及它是如何工作一无所知。我想知道,是否可以在某处找到执行以下简单操作的ruby代码:打开jpeg文件。遍历每个像素并将其颜色设置为fx绿色。将结果写入另一个文件。我对如何使用ruby-vips库实现这一点特别感兴趣https://github.com/ender672/ruby-vips我的目标-学习如何使用ruby-vips执行基本的图像处理操作(Gamma校正、亮度、色调……)任何指向比“helloworld”更复杂的工作示例的链接——比如ruby-vips的github页面上的链接,我们将不胜感激!如果有ruby-
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果