文章目录
| 指标名称 | 指标特点 | 例子 |
|---|---|---|
| 极大型(效益性)指标 | 越大(多)越好 | 成绩、GDP增速、企业利润 |
| 极小型(成本型)指标 | 越小(少)越好 | 费用、坏品率、污染程度 |
| 中间型指标 | 越接近某个值越好 | 水质量评估时的PH值 |
| 区间型指标 | 落在某个区间最好 | 体温、水中植物性营养物量 |
正向化就是将原始数据指标都转化为极大型指标。
| 符号 | 含义 |
|---|---|
| max | 一列当中最大的元素 |
| xbest | 区间最好的值 |
| a | 区间下限 |
| b | 区间上限 |
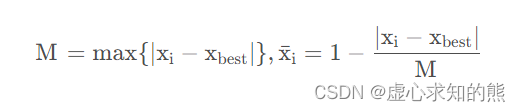
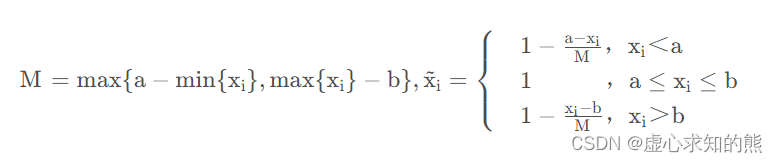
标准化的目的是消除不同指标量纲的影响。
假设有 n 个要评价对象,m个评价指标(已经正向化了)构成的正向化矩阵如下:

那么,对其标准化的矩阵记为 Z ,Z 当中的每一个元素:
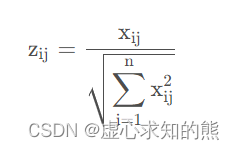 (每一个元素 / 其所在列的元素的平方和的开方)
(每一个元素 / 其所在列的元素的平方和的开方)
得到标准化矩阵 Z :



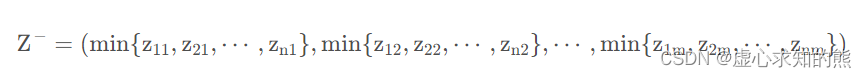

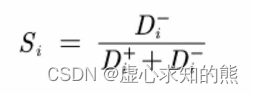
关于具体实现,需要有一定的数据,这里实现所选用的数据如下:
| 河流 | 含氧量(ppm) | PH值 | 细菌总数(个/mL) | 植物性营养物量 |
|---|---|---|---|---|
| A | 4.69 | 6.59 | 51 | 11.94 |
| B | 2.03 | 7.86 | 19 | 6.46 |
| C | 9.11 | 6.31 | 46 | 8.91 |
| D | 8.61 | 7.05 | 46 | 26.43 |
| E | 7.13 | 6.5 | 50 | 23.57 |
| F | 2.39 | 6.77 | 38 | 24.62 |
| G | 7.69 | 6.79 | 38 | 6.01 |
| H | 9.3 | 6.81 | 27 | 31.57 |
| I | 5.45 | 7.62 | 5 | 18.46 |
| J | 6.19 | 7.27 | 17 | 7.51 |
| K | 7.93 | 7.53 | 9 | 6.52 |
| L | 4.4 | 7.28 | 17 | 25.3 |
| M | 7.46 | 8.24 | 23 | 14.42 |
| N | 2.01 | 5.55 | 47 | 26.31 |
| O | 2.04 | 6.4 | 23 | 17.91 |
| P | 7.73 | 6.14 | 52 | 15.72 |
| Q | 6.35 | 7.58 | 25 | 29.46 |
| R | 8.29 | 8.41 | 39 | 12.02 |
| S | 3.54 | 7.27 | 54 | 3.16 |
| T | 7.44 | 6.26 | 8 | 28.41 |
clear;clc
load data_water_quality.mat
[n,m] = size(X);
disp(['共有' num2str(n) '个评价对象, ' num2str(m) '个评价指标'])
Judge = input(['这' num2str(m) '个指标是否需要经过正向化处理,需要请输入1 ,不需要输入0: ']);
if Judge == 1
Position = input('请输入需要正向化处理的指标所在的列,例如第2、3、6三列需要处理,那么你需要输入[2,3,6]: '); %[2,3,6]
disp('请输入需要处理的这些列的指标类型(1:极小型, 2:中间型, 3:区间型) ')
Type = input('例如:第2列是极小型,第3列是区间型,第6列是中间型,就输入[1,3,2]: '); %[2,1,3]
% 注意,Position和Type是两个同维度的行向量
for i = 1 : size(Position,2) %这里需要对这些列分别处理,因此我们需要知道一共要处理的次数,即循环的次数
X(:,Position(i)) = Positivization(X(:,Position(i)),Type(i),Position(i));
% Positivization是我们自己定义的函数,其作用是进行正向化,其一共接收三个参数
% 第一个参数是要正向化处理的那一列向量 X(:,Position(i)) 回顾上一讲的知识,X(:,n)表示取第n列的全部元素
% 第二个参数是对应的这一列的指标类型(1:极小型, 2:中间型, 3:区间型)
% 第三个参数是告诉函数我们正在处理的是原始矩阵中的哪一列
% 该函数有一个返回值,它返回正向化之后的指标,我们可以将其直接赋值给我们原始要处理的那一列向量
end
disp('正向化后的矩阵 X = ')
disp(X)
end
| 含氧量(ppm) | PH值 | 细菌总数(个/mL) | 植物性营养物量 |
|---|---|---|---|
| 4.69 | 0.717241379 | 3 | 1 |
| 2.03 | 0.406896552 | 35 | 0.694036301 |
| 9.11 | 0.524137931 | 8 | 0.905790838 |
| 8.61 | 0.965517241 | 8 | 0.444252377 |
| 7.13 | 0.655172414 | 4 | 0.691443388 |
| 2.39 | 0.84137931 | 16 | 0.600691443 |
| 7.69 | 0.855172414 | 16 | 0.65514261 |
| 9.3 | 0.868965517 | 27 | 0 |
| 5.45 | 0.572413793 | 49 | 1 |
| 6.19 | 0.813793103 | 37 | 0.784788245 |
| 7.93 | 0.634482759 | 45 | 0.699222126 |
| 4.4 | 0.806896552 | 37 | 0.541918755 |
| 7.46 | 0.144827586 | 31 | 1 |
| 2.01 | 0 | 7 | 0.454624028 |
| 2.04 | 0.586206897 | 31 | 1 |
| 7.73 | 0.406896552 | 2 | 1 |
| 6.35 | 0.6 | 29 | 0.182368194 |
| 8.29 | 0.027586207 | 15 | 1 |
| 3.54 | 0.813793103 | 0 | 0.408815903 |
| 7.44 | 0.489655172 | 46 | 0.273120138 |
function [posit_x] = Min2Max(x)
posit_x = max(x) - x;
%posit_x = 1 ./ x; %如果x全部都大于0,也可以这样正向化
end
function [posit_x] = Mid2Max(x,best)
M = max(abs(x-best));
posit_x = 1 - abs(x-best) / M;
end
function [posit_x] = Inter2Max(x,a,b)
r_x = size(x,1); % row of x
M = max([a-min(x),max(x)-b]);
posit_x = zeros(r_x,1); %zeros函数用法: zeros(3) zeros(3,1) ones(3)
% 初始化posit_x全为0 初始化的目的是节省处理时间
for i = 1: r_x
if x(i) < a
posit_x(i) = 1-(a-x(i))/M;
elseif x(i) > b
posit_x(i) = 1-(x(i)-b)/M;
else
posit_x(i) = 1;
end
end
end
% function [输出变量] = 函数名称(输入变量)
% 函数的中间部分都是函数体
% 函数的最后要用end结尾
% 输出变量和输入变量可以有多个,用逗号隔开
% function [a,b,c]=test(d,e,f)
% a=d+e;
% b=e+f;
% c=f+d;
% end
% 自定义的函数要单独放在一个m文件中,不可以直接放在主函数里面(和其他大多数语言不同)
function [posit_x] = Positivization(x,type,i)
% 输入变量有三个:
% x:需要正向化处理的指标对应的原始列向量
% type: 指标的类型(1:极小型, 2:中间型, 3:区间型)
% i: 正在处理的是原始矩阵中的哪一列
% 输出变量posit_x表示:正向化后的列向量
if type == 1 %极小型
disp(['第' num2str(i) '列是极小型,正在正向化'] )
posit_x = Min2Max(x); %调用Min2Max函数来正向化
disp(['第' num2str(i) '列极小型正向化处理完成'] )
disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~')
elseif type == 2 %中间型
disp(['第' num2str(i) '列是中间型'] )
best = input('请输入最佳的那一个值: ');
posit_x = Mid2Max(x,best);
disp(['第' num2str(i) '列中间型正向化处理完成'] )
disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~')
elseif type == 3 %区间型
disp(['第' num2str(i) '列是区间型'] )
a = input('请输入区间的下界: ');
b = input('请输入区间的上界: ');
posit_x = Inter2Max(x,a,b);
disp(['第' num2str(i) '列区间型正向化处理完成'] )
disp('~~~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~')
else
disp('没有这种类型的指标,请检查Type向量中是否有除了1、2、3之外的其他值')
end
end
Z = X ./ repmat(sum(X.*X) .^ 0.5, n, 1);
disp('标准化矩阵 Z = ')
disp(Z)
| 含氧量(ppm) | PH值 | 细菌总数(个/mL) | 植物性营养物量 |
|---|---|---|---|
| 0.162185916 | 0.248255278 | 0.024544035 | 0.306457563 |
| 0.070199874 | 0.140837129 | 0.286347071 | 0.212692674 |
| 0.315034904 | 0.181417319 | 0.065450759 | 0.277586453 |
| 0.297744294 | 0.334189798 | 0.065450759 | 0.136144501 |
| 0.24656409 | 0.226771648 | 0、03272538 | 0.211898056 |
| 0.082649113 | 0.291222538 | 0.130901518 | 0.184086436 |
| 0.265929573 | 0.295996678 | 0.130901518 | 0.200773408 |
| 0.321605335 | 0.300770818 | 0.220896312 | 0 |
| 0.188467643 | 0.198126809 | 0.4008859 | 0.306457563 |
| 0.214057745 | 0.281674258 | 0.302709761 | 0.240504293 |
| 0.274229065 | 0.219610438 | 0.36816052 | 0.214281909 |
| 0.152157363 | 0.279287188 | 0.302709761 | 0.166075101 |
| 0.257975892 | 0.05012847 | 0.253621692 | 0.306457563 |
| 0.06950825 | 0 | 0.057269414 | 0.139322972 |
| 0.070545686 | 0.202900949 | 0.253621692 | 0.306457563 |
| 0.267312822 | 0.140837129 | 0.01636269 | 0.306457563 |
| 0.21959074 | 0.207675088 | 0.237259002 | 0.055888112 |
| 0.286678304 | 0.00954828 | 0.122720173 | 0.306457563 |
| 0.122417515 | 0.281674258 | 0 | 0.125284726 |
| 0.257284268 | 0.169481969 | 0.376341865 | 0.083699732 |
D_P = sum([(Z - repmat(max(Z),n,1)) .^ 2 ],2) .^ 0.5; % D+ 与最大值的距离向量
D_N = sum([(Z - repmat(min(Z),n,1)) .^ 2 ],2) .^ 0.5; % D- 与最小值的距离向量
S = D_N ./ (D_P+D_N); % 未归一化的得分
disp('最后的得分为:')
stand_S = S / sum(S)%归一化后的得分
%[sorted_S,index] = sort(stand_S ,'descend')
| 河流 | D+ | D- | Stand_S(归一化后得分) | 排名 |
|---|---|---|---|---|
| K | 0.1579 | 0.5212 | 0.0702 | 1 |
| J | 0.1683 | 0.4997 | 0.0684 | 2 |
| I | 0.1904 | 0.5550 | 0.0681 | 3 |
| L | 0.2471 | 0.4517 | 0.0591 | 4 |
| T | 0.2855 | 0.4611 | 0.0565 | 5 |
| G | 0.2977 | 0.4285 | 0.0539 | 6 |
| O | 0.3193 | 0.4466 | 0.0533 | 7 |
| M | 0.3262 | 0.4430 | 0.0527 | 8 |
| H | 0.3570 | 0.4503 | 0.0510 | 9 |
| D | 0.3770 | 0.4320 | 0.0488 | 10 |
| C | 0.3698 | 0.4178 | 0.0485 | 11 |
| B | 0.3500 | 0.3835 | 0.0478 | 12 |
| Q | 0.3405 | 0.3537 | 0.0466 | 13 |
| A | 0.4177 | 0.4059 | 0.0451 | 14 |
| F | 0.3832 | 0.3688 | 0.0448 | 15 |
| R | 0.4289 | 0.3953 | 0.0438 | 16 |
| P | 0.4338 | 0.3913 | 0.0434 | 17 |
| E | 0.4021 | 0.3588 | 0.0431 | 18 |
| S | 0.4858 | 0.3128 | 0.0358 | 19 |
| N | 0.5668 | 0.1506 | 0.0192 | 20 |
在 TOPSIS 当中,默认了各个评价指标所占的权重相同,但在实际的评价过程当中由于各种主观客观因素的影响,导致每一个评价指标所占的权重是有差异的。因此,对于 TOPSIS 模型的优化,可以从合理调整个评价指标所占权重入手。
在此处只是简单介绍,详细介绍有时间的话会补充
| 标度 | 含义 |
|---|---|
| 1 | 表示两个因素相比,具有同样重要性 |
| 3 | 表示两个因素相比,一个因素比另一个因素稍微重要 |
| 5 | 表示两个因素相比,一个因素比另一个因素明显重要 |
| 7 | 表示两个因素相比,一个因素比另一个因素强烈重要 |
| 9 | 表示两个因素相比,一个因素比另一个因素极端重要 |
| 2、4、6、8 | 上述两相邻判断的中值 |
| 倒数 | A和B相比如果标度为3,那么B和A相比就是1/3 |


一致矩阵有一个特征值为 n,其余特征值均为 0。另外,我们很容易可以得到,特征值为 n 时,对应的特征向量刚好为:
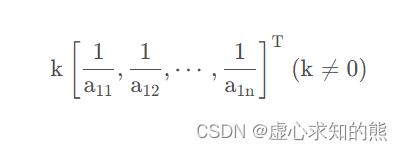
在实际过程中建议综合三种方法求得的权重得到一个综合的权重向量更具有说服力。


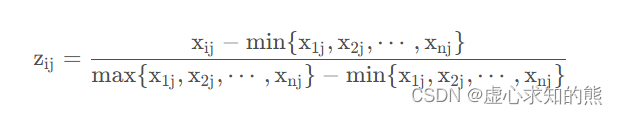


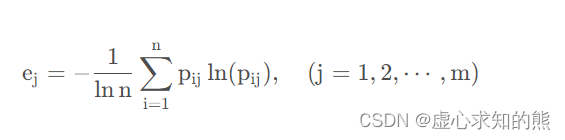
在各个对象与最大值、最小值之间的距离公式转变为: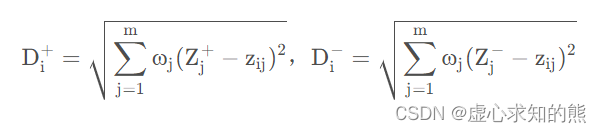
技术选型1,前端小程序原生MINA框架cssJavaScriptWxml2,管理后台云开发Cms内容管理系统web网页3,数据后台小程序云开发云函数云开发数据库(基于MongoDB)云存储4,人脸识别算法基于百度智能云实现人脸识别一,用户端效果图预览老规矩我们先来看效果图,如果效果图符合你的需求,就继续往下看,如果不符合你的需求,可以跳过。1-1,登录注册页可以看到登录页有注册入口,注册页如下我们的注册,需要管理员审核,审核通过后才可以正常登录使用小程序1-2,个人中心页登录成功以后,我们会进入个人中心页我们在个人中心页可以注册人脸,因为我们做人脸识别签到,需要先注册人脸才可以进行人脸比对,进
我在查询中使用geo_distancefilter和tire,它工作正常:search.filter:geo_distance,:distance=>"#{request.distance}km",:location=>"#{request.lat},#{request.lng}"我预计结果会以某种方式包括到我用于过滤器的地理位置的计算距离。有没有办法告诉elasticsearch在响应中包含它,这样我就不必在ruby中为每个结果计算它?==更新==我在谷歌群组中的foundtheanswer:search.sortdoby"_geo_distance","location"=>"
我有一个MongoDB,其中包含大约100万个文档。这些文档都有一个字符串,表示256位bin的1和0,例如:0110101010101010110101010101理想情况下,我想查询近似二进制匹配项。这意味着,如果这两个文件具有以下编号。是的,这就是汉明距离。Mongo当前不支持此功能。所以,我不得不在应用层做。因此,鉴于此,我试图找到一种方法来避免在文档之间进行单独的汉明距离比较。这使得基本上不可能有时间做这件事。我有很多内存。而且,在ruby中,似乎有一个很棒的gem(算法)可以创建许多树,但我似乎(还)没有一个可以减少我需要进行的查询数量。理想情况下,我想进行100万次查
在ruby中,计算两个无符号整数之间的位差(例如汉明距离)的最有效方法是什么?例如,我有整数a=2323409845和b=1782647144。它们的二进制表示是:a=10001010011111000110101110110101b=01101010010000010000100101101000a和b之间的位差是17..我可以对它们进行逻辑异或,但这会给我一个不同的整数!=17,然后我将不得不遍历结果的二进制表示并计算1的数量。计算位差的最有效方法是什么?现在,计算多个整数序列的位差的答案是否改变了?例如。给定2个无符号整数序列:x={2323409845,64176042
我可以用Ruby测量两个字符串之间的距离吗?即:compare('Test','est')#Returns1compare('Test','Tes')#Returns1compare('Test','Tast')#Returns1compare('Test','Taste')#Returns2compare('Test','tazT')#Returns5 最佳答案 由于原生C绑定(bind),更加容易和快速:geminstalllevenshtein-ffigeminstalllevenshteinrequire'levenshte
我想知道是否有一种方法可以在不依赖GoogleMapsAPI的情况下计算两个GPS坐标的距离。我的应用程序可能会收到float坐标,否则我将不得不对地址执行反向GEO。 最佳答案 地球上两个坐标之间的距离通常使用Haversineformula来计算.该公式考虑了地球形状和半径。这是我用来计算以米为单位的距离的代码。defdistance(loc1,loc2)rad_per_deg=Math::PI/180#PI/180rkm=6371#Earthradiusinkilometersrm=rkm*1000#Radiusinmeter
有符号距离场(SDF:SignedDistanceField)是距离场的一种变体,它在3D(2D)空间中将位置映射到其到最近平面(边缘)的距离。距离场在图像处理、物理学和计算机图形学等许多研究中都有应用。在计算机图形的上下文中,距离场通常是有符号的,表示某个位置是否在网格内。在计算机图形学和游戏开发中,SDF显示出极大的通用性,它可以用于碰撞测试、网格表示、光线追踪等。此外,人们发现它在使用光线追踪渲染场景时也有一些好处(即,ray-marching)算法——几乎不需要额外成本就可以产生像软阴影和环境光遮蔽这样的阴影效果。这个项目是关于实时光线行进渲染器的从零开始的C++实现,它包括一个SDF
我在堆栈中查看了不同的链接距离,似乎为了改变链接距离,您需要实现一个函数,然后传递该函数以动态分配链接距离:functionlinkDistance(d){returnd.distance;}然后我认为我可以传递给svg,但返回函数错误而不是现有的linkdistance或distancevarlink=svg.selectAll(".link").data(bilinks).enter().append("path").style("stroke","#6b7071")//gunmetalgreylink.attr("class","link").linkDistance(linkD
所以我有一个div在另一个里面-我怎样才能得到它们之间的距离?我尝试了类似$('#child').parentsUntil($('#parent')).andSelf()的方法-但它返回的是对象,而不是距离。附言我需要它来按下其他按钮。 最佳答案 http://api.jquery.com/position/要获得您可以使用的左侧距离:vardistLeft=$('#child').position().left;这将返回以px为单位的相对于父级偏移量的距离如果您对元素的页面偏移感兴趣:varoffsLeft=$('#child')
我想运行Levenshtein,但要快得多,因为它是我正在构建的实时应用程序。一旦距离大于10,它就会终止。 最佳答案 从评论来看,人们似乎对Sift3很满意.http://sift.codeplex.com 关于javascript-对于字符串距离,是否有比Levenshtein更快(不太精确)的算法?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/6178708/