很多朋友都问我学完基础知识以后怎样提高编程水平?当然是
刷题啦!很多小伙伴都在纠结从哪里开始,今天给大家推荐一个身边朋友都在使用的刷题网站:点击进入牛客网刷题吧!

今天是 Java + 经典算法 进阶刷题的第四天,结合经典算法学习Java语法!一起升级打怪吧!!
文章目录

最近一直在练习二叉树的经典题目。为了巩固基础算法能力,同时也为了在面试中可以做到心中有数,我通过做题的方式让自己头脑保持清醒,让自己对基础算法题目时刻保持感觉。
我几乎每天都通过刷题的方式让自己保持清醒,最近也感觉自己算法能力又明显的提升,所以说,这样的方式是可行的!希望我的刷题笔记能够帮助到大家,接下来让我们一起开始算法之旅吧。
原题点击:判断是不是二叉搜索树
题目描述:
给定一个二叉树根节点,请你判断这棵树是不是二叉搜索树。
二叉搜索树满足每个节点的左子树上的所有节点均小于当前节点且右子树上的所有节点均大于当前节点。
例:
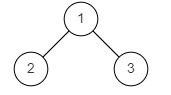
图1
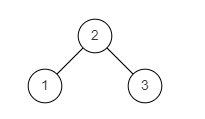
图2
数据范围:
节点数量满足 1 ≤n≤ 10^4
节点上的值满足:
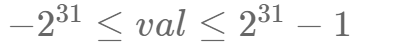
示例1:
输入: {1,2,3}
返回值: false
说明:如题面图1
示例2:
输入: {2,1,3}
返回值: true
说明:如题面图2
题解:
Java代码实现:
import java.util.*;
public class Solution {
int pre = Integer.MIN_VALUE;
//中序遍历
public boolean isValidBST (TreeNode root) {
if (root == null)
return true;
//先进入左子树
if(!isValidBST(root.left))
return false;
if(root.val < pre)
return false;
//更新最值
pre = root.val;
//再进入右子树
return isValidBST(root.right);
}
}
思路: 二叉搜索树的特性就是中序遍历是递增序。既然是判断是否是二叉搜索树,那我们可以使用中序递归遍历。只要之前的节点是二叉树搜索树,那么如果当前的节点小于上一个节点值那么就可以向下判断。
只不过在过程中我们要求反退出。比如一个链表1->2->3->4,只要for循环遍历如果中间有不是递增的直接返回false即可。
if(root.val < pre)
return false;
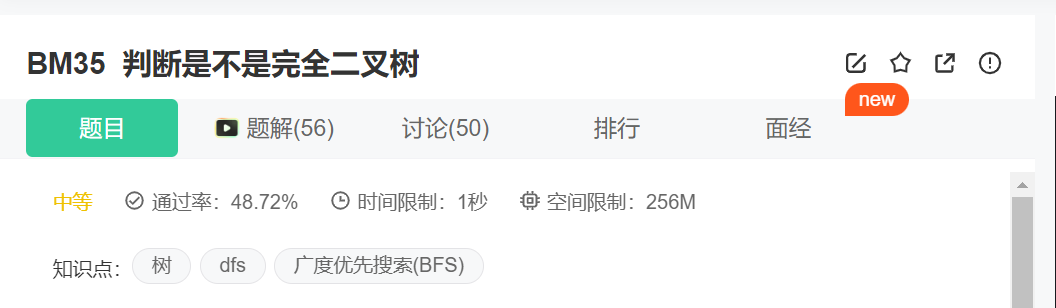
原题点击:判断是不是完全二叉树
题目描述:
给定一个二叉树,确定他是否是一个完全二叉树。
完全二叉树的定义:若二叉树的深度为 h,除第 h 层外,其它各层的结点数都达到最大个数,第 h 层所有的叶子结点都连续集中在最左边,这就是完全二叉树。(第 h 层可能包含 [1~2h] 个节点)
数据范围: 节点数满足 1≤n≤100
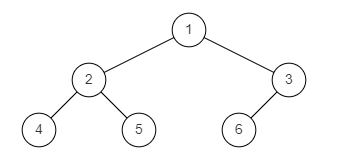
样例图1:
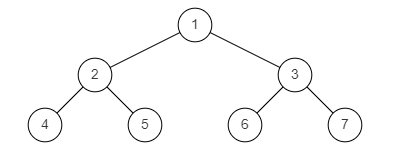
样例图2:
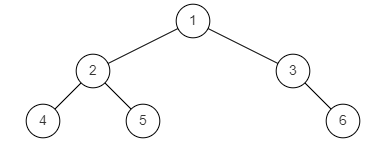
样例图3:
示例1:
输入: {1,2,3,4,5,6}
返回值: true
示例2:
输入: {1,2,3,4,5,6,7}
返回值: true
示例3:
输入: {1,2,3,4,5,#,6}
返回值: false
题解:
Java代码实现:
import java.util.*;
public class Solution {
public boolean isCompleteTree (TreeNode root) {
//空树一定是完全二叉树
if(root == null)
return true;
//辅助队列
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
TreeNode cur;
//定义一个首次出现的标记位
boolean notComplete = false;
while(!queue.isEmpty()){
cur = queue.poll();
//标记第一次遇到空节点
if(cur == null){
notComplete = true;
continue;
}
//后续访问已经遇到空节点了,说明经过了叶子
if(notComplete)
return false;
queue.offer(cur.left);
queue.offer(cur.right);
}
return true;
}
}
思路: 对完全二叉树最重要的定义就是叶子节点只能出现在最下层和次下层,所以我们想到可以使用队列辅助进行层次遍历——从上到下遍历所有层,每层从左到右,只有次下层和最下层才有叶子节点,其他层出现叶子节点就意味着不是完全二叉树。
原题点击:判断是不是平衡二叉树
题目描述:
输入一棵节点数为 n 二叉树,判断该二叉树是否是平衡二叉树。在这里,我们只需要考虑其平衡性,不需要考虑其是不是排序二叉树。
平衡二叉树(Balanced Binary Tree),具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
样例解释: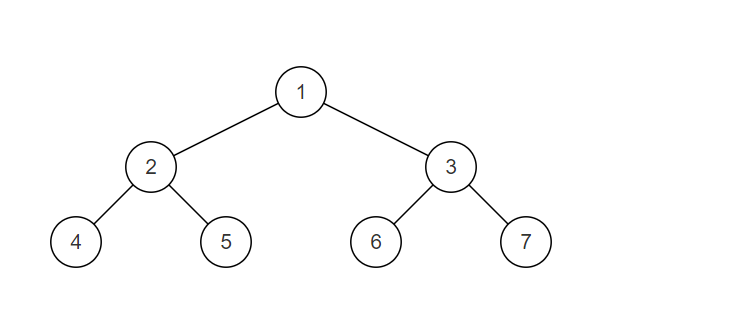
样例二叉树如图,为一颗平衡二叉树
注:我们约定空树是平衡二叉树。
数据范围:n≤100,树上节点的val值满足 0≤n≤1000
要求:空间复杂度O(1),时间复杂度 O(n)
输入描述:
输入一棵二叉树的根节点
返回值描述:
输出一个布尔类型的值
示例1:
输入: {1,2,3,4,5,6,7}
返回值: true
示例2:
输入: {}
返回值: true
题解:
Java代码实现:
public class Solution {
//计算该子树深度函数
public int deep(TreeNode root){
//空节点深度为0
if(root == null)
return 0;
//递归算左右子树的深度
int left = deep(root.left);
int right = deep(root.right);
//子树最大深度加上自己
return (left > right) ? left + 1 : right + 1;
}
public boolean IsBalanced_Solution(TreeNode root) {
//空树为平衡二叉树
if (root == null)
return true;
int left = deep(root.left);
int right = deep(root.right);
//左子树深度减去右子树相差绝对值大于1
if(left - right > 1 || left - right < -1)
return false;
//同时,左右子树还必须是平衡的
return IsBalanced_Solution(root.left) && IsBalanced_Solution(root.right);
}
}
思路: 平衡二叉树任意节点两边的子树深度相差绝对值不会超过1,且每个子树都满足这个条件,那我们可以对每个节点找到两边的深度以后:
int deep(TreeNode root){
if(root == null)
return 0;
int left = deep(root.left);
int right = deep(root.right);
//子树最大深度加上自己
return (left > right) ? left + 1 : right + 1;
}
判断是否两边相差绝对值超过1:
//左子树深度减去右子树相差绝对值大于1
if(left - right > 1 || left - right < -1)
return false;
然后因为每个子树都满足这个条件,我们还需要遍历二叉树每个节点当成一棵子树进行判断,而对于每个每个节点判断后,其子节点就是子问题,因此可以用递归。
IsBalanced_Solution(root.left) && IsBalanced_Solution(root.right);
原题点击:二叉搜索树的最近公共祖先
题目描述:
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
1.对于该题的最近的公共祖先定义:对于有根树T的两个节点p、q,最近公共祖先LCA(T,p,q)表示一个节点x,满足x是p和q的祖先且x的深度尽可能大。在这里,一个节点也可以是它自己的祖先.
2.二叉搜索树是若它的左子树不空,则左子树上所有节点的值均小于它的根节点的值; 若它的右子树不空,则右子树上所有节点的值均大于它的根节点的值
3.所有节点的值都是唯一的。
4.p、q 为不同节点且均存在于给定的二叉搜索树中。
数据范围:
3<=节点总数<=10000
0<=节点值<=10000
如果给定以下搜索二叉树: {7,1,12,0,4,11,14,#,#,3,5},如下图:
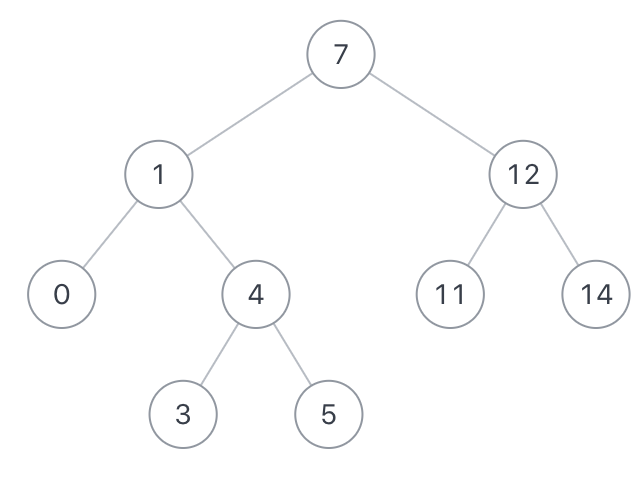
示例1:
输入: {7,1,12,0,4,11,14,#,#,3,5},1,12
返回值:7
说明:节点1 和 节点12的最近公共祖先是7
示例2:
输入: {7,1,12,0,4,11,14,#,#,3,5},12,11
返回值: 12
说明:因为一个节点也可以是它自己的祖先.所以输出12
题解:
Java代码实现:
import java.util.*;
public class Solution {
//求得根节点到目标节点的路径
public ArrayList<Integer> getPath(TreeNode root, int target) {
ArrayList<Integer> path = new ArrayList<Integer>();
TreeNode node = root;
//节点值都不同,可以直接用值比较
while(node.val != target){
path.add(node.val);
//小的在左子树
if(target < node.val)
node = node.left;
//大的在右子树
else
node = node.right;
}
path.add(node.val);
return path;
}
public int lowestCommonAncestor (TreeNode root, int p, int q) {
//求根节点到两个节点的路径
ArrayList<Integer> path_p = getPath(root, p);
ArrayList<Integer> path_q = getPath(root, q);
int res = 0;
//比较两个路径,找到第一个不同的点
for(int i = 0; i < path_p.size() && i < path_q.size(); i++){
int x = path_p.get(i);
int y = path_q.get(i);
//最后一个相同的节点就是最近公共祖先
if(x == y)
res = path_p.get(i);
else
break;
}
return res;
}
}
思路: 二叉搜索树没有相同值的节点,因此分别从根节点往下利用二叉搜索树较大的数在右子树,较小的数在左子树,可以轻松找到p、q:
//节点值都不同,可以直接用值比较
while(node.val != target) {
path.add(node.val);
//小的在左子树
if(target < node.val)
node = node.left;
//大的在右子树
else
node = node.right;
}
直接得到从根节点到两个目标节点的路径,这样我们利用路径比较就可以找到最近公共祖先。
原题点击:序列化二叉树
题目描述:
请实现两个函数,分别用来序列化和反序列化二叉树,不对序列化之后的字符串进行约束,但要求能够根据序列化之后的字符串重新构造出一棵与原二叉树相同的树。
二叉树的序列化(Serialize)是指:把一棵二叉树按照某种遍历方式的结果以某种格式保存为字符串,从而使得内存中建立起来的二叉树可以持久保存。序列化可以基于先序、中序、后序、层序的二叉树等遍历方式来进行修改,序列化的结果是一个字符串,序列化时通过 某种符号表示空节点(#)
二叉树的反序列化(Deserialize)是指:根据某种遍历顺序得到的序列化字符串结果str,重构二叉树。
例如,可以根据层序遍历的方案序列化,如下图:
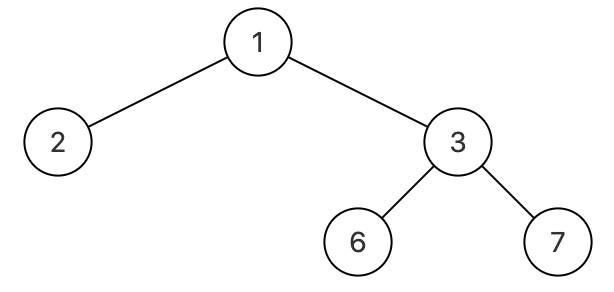
层序序列化(即用函数Serialize转化)如上的二叉树转为"{1,2,3,#,#,6,7}",再能够调用反序列化(Deserialize)将"{1,2,3,#,#,6,7}"构造成如上的二叉树。
当然你也可以根据满二叉树结点位置的标号规律来序列化,还可以根据先序遍历和中序遍历的结果来序列化。不对序列化之后的字符串进行约束,所以欢迎各种奇思妙想。
数据范围: 节点数 n≤100,树上每个节点的值满足 0≤val≤150
要求: 序列化和反序列化都是空间复杂度 O(n),时间复杂度 O(n)。
示例1
输入: {1,2,3,#,#,6,7}
返回值: {1,2,3,#,#,6,7}
说明:如题面图
示例2
输入: {8,6,10,5,7,9,11}
返回值: {8,6,10,5,7,9,11}
题解:
Java代码实现:
import java.util.*;
public class Solution {
//序列的下标
public int index = 0;
//处理序列化的功能函数(递归)
private void SerializeFunction(TreeNode root, StringBuilder str){
//如果节点为空,表示左子节点或右子节点为空,用#表示
if(root == null){
str.append('#');
return;
}
//根节点
str.append(root.val).append('!');
//左子树
SerializeFunction(root.left, str);
//右子树
SerializeFunction(root.right, str);
}
public String Serialize(TreeNode root) {
//处理空树
if(root == null)
return "#";
StringBuilder res = new StringBuilder();
SerializeFunction(root, res);
//把str转换成char
return res.toString();
}
//处理反序列化的功能函数(递归)
private TreeNode DeserializeFunction(String str){
//到达叶节点时,构建完毕,返回继续构建父节点
//空节点
if(str.charAt(index) == '#'){
index++;
return null;
}
//数字转换
int val = 0;
//遇到分隔符或者结尾
while(str.charAt(index) != '!' && index != str.length()){
val = val * 10 + ((str.charAt(index)) - '0');
index++;
}
TreeNode root = new TreeNode(val);
//序列到底了,构建完成
if(index == str.length())
return root;
else
index++;
//反序列化与序列化一致,都是前序
root.left = DeserializeFunction(str);
root.right = DeserializeFunction(str);
return root;
}
public TreeNode Deserialize(String str) {
//空序列对应空树
if(str == "#")
return null;
TreeNode res = DeserializeFunction(str);
return res;
}
}
思路: 序列化即将二叉树的节点值取出,放入一个字符串中,我们可以按照前序遍历的思路,遍历二叉树每个节点,并将节点值存储在字符串中,我们用‘#’表示空节点,用‘!'表示节点与节点之间的分割。
反序列化即根据给定的字符串,将二叉树重建,因为字符串中的顺序是前序遍历,因此我们重建的时候也是前序遍历,即可还原。
📩Java基础学习主要以练习为主,很多朋友听完视频课程学会基础以后感觉对练手项目无从下手,这里推荐去牛客网看看,这里的IT题库内容很丰富,属于国内做的很好的IT学习网站,而且是课程+刷题+面经+求职+讨论区分享。
📩从基础开始练习,知识点编排详细,题目安排合理,题目表述以指导的形式进行。整个题单覆盖了java入门的全部知识点以及全部语法,通过知识点分类逐层递进,从基础开始到最后的实践任务,都会非常详细地指导你应该使用什么函数,应该怎么输入输出。
 📩牛客网还提供题解专区和讨论区会有大神提供题解思路,对新手玩家及其友好,有不清楚的语法,不理解的地方,看看别人的思路,别人的代码,也许就能豁然开朗。
📩牛客网还提供题解专区和讨论区会有大神提供题解思路,对新手玩家及其友好,有不清楚的语法,不理解的地方,看看别人的思路,别人的代码,也许就能豁然开朗。

需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我一直在尝试在Ruby中实现BinaryTree类,但我得到了stackleveltoodeep错误,尽管我似乎没有在该特定代码段中使用任何递归:1.classBinaryTree2.includeEnumerable3.4.attr_accessor:value5.6.definitialize(value=nil)7.@value=value8.@left=BinaryTree.new#stackleveltoodeephere9.@right=BinaryTree.new#andhere10.end11.12.defempty?13.(self.value==nil)?true:
所有题目均有五种语言实现。C实现目录、C++实现目录、Python实现目录、Java实现目录、JavaScript实现目录题目n行m列的矩阵,每个位置上有一个元素你可以上下左右行走,代价是前后两个位置元素值差的绝对值.另外,你最多可以使用一次传送阵(只能从一个数跳到另外一个相同的数)求从走上角走到右下角最少需要多少时间。输入描述:第一行两个整数n,m,分别代表矩阵的行和列。后面n行,每行m个整数,分别代表矩阵中的元素。输出描述:一个整数,表示最少需要多少时间。
提供3种Ubuntu系统安装微信的方法,在Ubuntu20.04上验证都ok。1.WineHQ7.0安装微信:ubuntu20.04安装最新版微信--可以支持微信最新版,但是适配的不是特别好;比如WeChartOCR.exe报错。2.原生微信安装:linux系统下的微信安装(ubuntu20.04)--微信适配的最好,反应最快,但是微信版本只到2.1.1,版本太老,很多功能都没有。3.深度deepin-wine6安装微信:ubuntu20.04+系统deepin-wine6安装新版微信--综合比较好,当前个人使用此种方法1个月,微信版本3.4;没什么大问题,尚可。一、WineHQ7.0安装微信
在神经网络方面,我完全是个初学者。我整天都在与ruby-fann和ai4r搏斗,不幸的是我没有任何东西可以展示,所以我想我会来到StackOverflow并询问这里的知识渊博的人。我有一组样本——每天都有一个数据点,但它们不符合我能够找出的任何明确模式(我尝试了几次回归)。不过,我认为看看是否有任何方法可以仅从日期预测future的数据会很好,而且我认为神经网络将是生成希望表达这种关系的函数的好方法.日期是DateTime对象,数据点是十进制数,例如7.68。我一直在将DateTime对象转换为float,然后除以10,000,000,000得到一个介于0和1之间的数字,我一直在将
我正在尝试从使用RubyonRails的散列创建http参数,我尝试使用URI.encode_www_form(params),但这没有正确生成参数。下面是我的哈希值params['Name'.to_sym]='NiaKun'params['AddressLine1'.to_sym]='AddressOne'params['City'.to_sym]='CityName'这个方法把空格转成+,我要的是把空格转成%20我收到"Name=Nia+Kun&AddressLine1=Address+One&City=City+Name"但我需要将此空格转换为%20
我正在尝试训练一个前馈网络来使用Ruby库AI4R执行异或运算。然而,当我在训练后评估XOR时。我没有得到正确的输出。有没有人以前使用过这个库并得到它来学习异或运算。我使用了两个输入神经元,一个隐藏层中的三个神经元,一个输出层,正如我看到的预计算XOR前馈神经网络就像这样。require"rubygems"require"ai4r"#Createthenetworkwith:#2inputs#1hiddenlayerwith3neurons#1outputsnet=Ai4r::NeuralNetwork::Backpropagation.new([2,3,1])example=[[0,
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
1.深度优先搜索(DFS)深度优先遍历主要思路是从图中一个未访问的顶点V开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成。例题P1605迷宫题目描述给定一个N×MN\timesMN×M方格的迷宫,迷宫里有TTT处障碍,障碍处不可通过。在迷宫中移动有上下左右四种方式,每次只能移动一个方格。数据保证起点上没有障碍。给定起点坐标和终点坐标,每个方格最多经过一次,问有多少种从起点坐标到终点坐标的方案。输入格式第一行为三个正整数N,M,TN,M,TN,M,T,分别表示迷宫的长宽和障碍总数。第二行为四个正整数SX,S
代码请进行一定修改后使用,本代码保证100%通过率,本题目提供了java、python、c++三种代码。复盘思路在文章的最后题目描述祖国西北部有一片大片荒地,其中零星的分布着一些湖泊,保护区,矿区;整体上常年光照良好,但是也有一些地区光照不太好。某电力公司希望在这里建设多个光伏电站,生产清洁能源对每平方公里的土地进行了发电评估,其中不能建设的区域发电量为0kw,可以发电的区域根据光照,地形等给出了每平方公里年发电量x千瓦。我们希望能够找到其中集中的矩形区域建设电站,能够获得良好的收益。输入描述第一行输入为调研的地区长,宽,以及准备建设的电站【长宽相等,为正方形】的边长最低要求的发电量之后每行为