Haproxy 支持多种调度算法,最常用的有三种
RR算法是最简单最常用的一种算法,即轮询调度
例如:
最小连接数算法,根据后端的节点连接数大小动态分配前端请求
例如:
基于来源访问调度算法,用于一些有Session会记录在服务器端的场景,可以基于来源的IP、Cookie等做集群调度
例如:
是一个使用C语言编写的自由及开放源代码软件,其提供高可用性、负载均衡,以及基于TCP和HTTP的应用程序代理。
HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。
HAProxy运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中,同时可以保护你的web服务器不被暴露到网络上。
HAProxy实现了一种事件驱动,单一进程模型,此模型支持非常大的并发连接数。多进程或多线程模型受内存限制、系统调度器限制以及无处不在的锁限制,很少能处理数千并发连接。
事件驱动模型因为在有更好的资源和时间管理的用户空间(User-Space)实现所有这些任务,所以没有这些问题。此模型的弊端是,在多核系统上,这些程序通常扩展性较差。这就是为什么他们必须进行优化以使每个CPU时间片(Cycle)做更多的工作。
包括 GitHub、Bitbucket、StackOverflow、Reddit、Tumblr、Twitter和 Tuenti在内的知名网站,及亚马逊网络服务系统都使用了HAProxy。
可靠性和稳定性非常好,可以与硬件级的F5负载均衡设备相媲美;
最高可以同时维护40000-50000个并发连接,单位时间内处理的最大请求数为20000个,最大处理能力可达10Git/s;
支持多达8种负载均衡算法,同时也支持会话保持;
支持虚机主机功能,从而实现web负载均衡更加灵活;
支持连接拒绝、全透明代理等独特的功能;
拥有强大的ACL支持,用于访问控制;
其独特的弹性二叉树数据结构,使数据结构的复杂性上升到了0(1),即数据的查寻速度不会随着数据条目的增加而速度有所下降;
支持客户端的keepalive功能,减少客户端与haproxy的多次三次握手导致资源浪费,让多个请求在一个tcp连接中完成;
支持TCP加速,零复制功能,类似于mmap机制;
支持响应池 (response buffering);
支持RDP协议;
基于源的粘性,类似nginx的ip hash功能,把来自同一客户端的请求在一定时间内始终调度到上游的同一服务器;
更好统计数据接口,其web接口显示后端集群中各个服务器的接收、发送、拒绝、错误等数据的统计信息;
详细的健康状态检测,web接口中有关于对上游服务器的健康检测状态, 并提供了一定的管理功能;
基于流量的健康评估机制;
基于http认证;
基于命令行的管理接口;
日志分析器,可对日志进行分析
HAProxy负载均衡策略非常多,常见的有如下8种∶
roundrobin∶表示简单的轮询。
static-rr∶表示根据权重。
leastconn∶ 表示最少连接者先处理。
source∶ 表示根据请求的源IP,类似Nginx的IP hash机制。
ri∶表示根据请求的URI。
rl_param∶表示根据HTTP请求头来锁定每 一 次HTrTP请求。
rdp-cookie (name)∶表示根据据cookie (name)来锁定并哈希每一次TCP请求。
LVS基于Linux操作系统实现软负载均衡,而HAProxy和Nginx是基于第三方应用实现的软负载均衡;
LVS是可实现4层的IP负载均衡技术,无法实现基于目录、URL的转发。而HAProxy和Nainx都可以实现4层和7层技术,HAProxy可提供TCP和HrTP应用的负载均衡综合解决方案
LVS因为工作在ISO模型的第四层,其状态监测功能单一, 而HAProxy在状监测方面功能更丰富、强大, 可支持端口、URL、脚本等多种状态检测方式;
HAProxy功能强大,但整体性能低于4层模式的LVS 负载均衡。
Nginx主要用于Web服务器或缓存服务器。
准备工作:
Haproxy服务器:192.168.10.10
Nginx 服务器1:192.168.10.20
Nginx 服务器2:192.168.10.30
客户端:宿主机
systemctl stop firewalld
setenforce 0
haproxy-1.5.19.tar.gzyum install -y pcre-devel bzip2-devel gcc gcc-c++ make
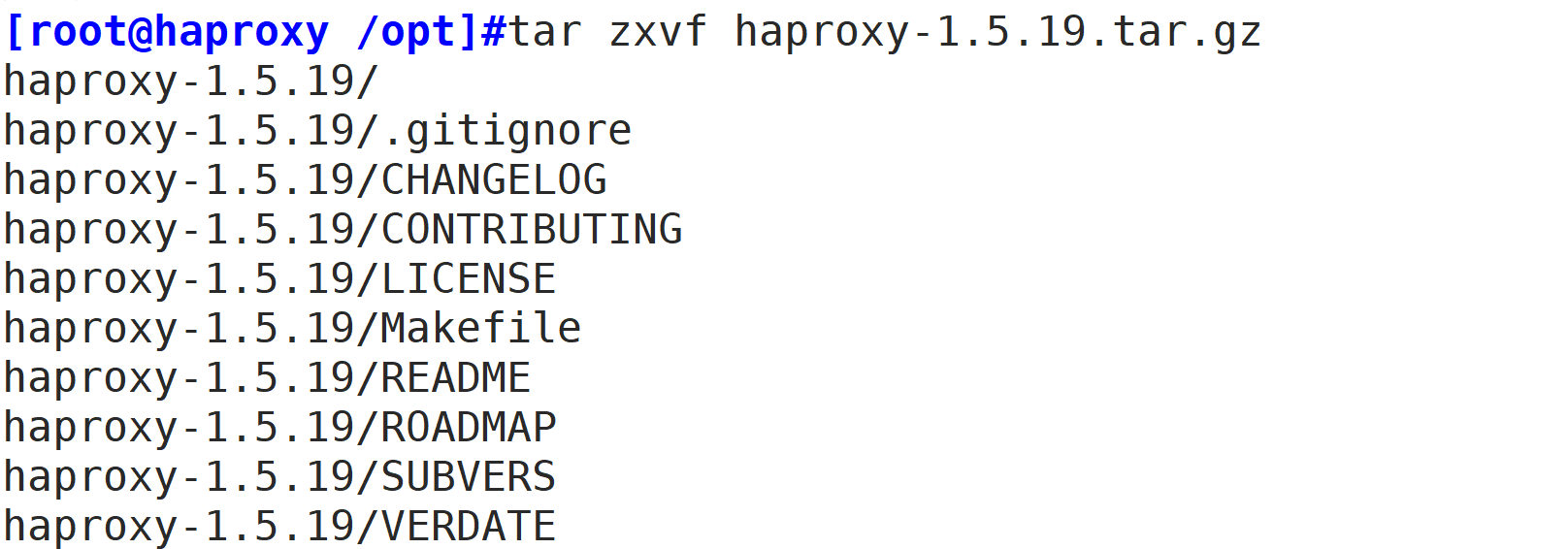
tar zxvf haproxy-1.5.19.tar.gz
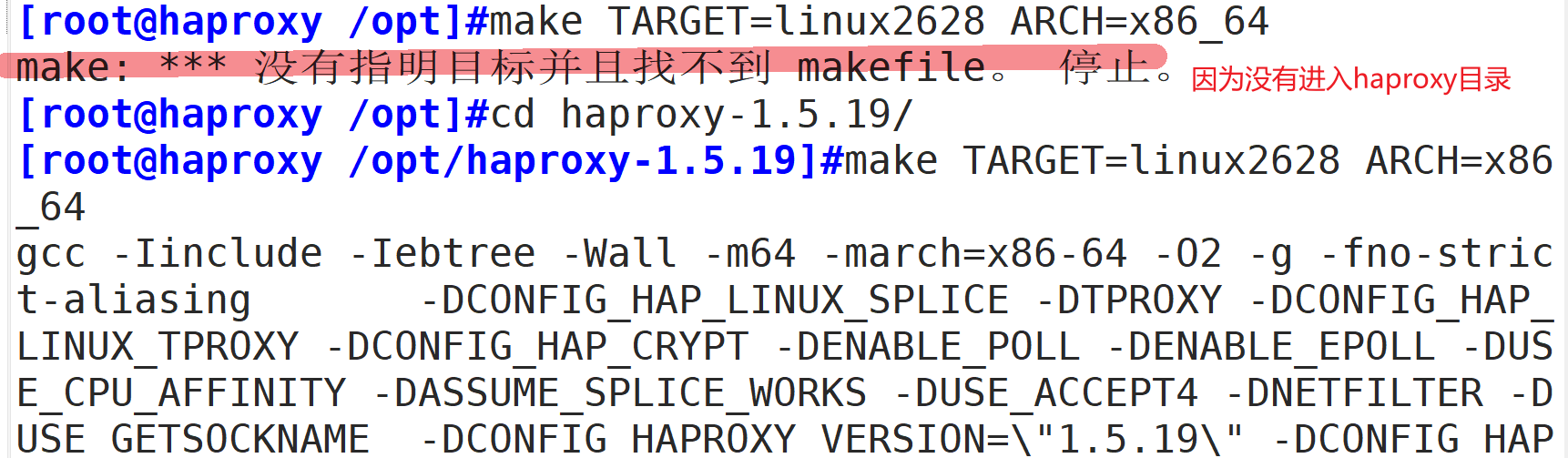
cd haproxy-1.5.19/
make TARGET=linux2628 ARCH=x86_64
make install补充:参数说明
TARGET=linux26 #内核版本,
#使用uname -r查看内核,如:2.6.18-371.el5,此时该参数用TARGET=linux26;kernel大于2.6.28的用TARGET=linux2628
ARCH=x86_64 #系统位数,64位系统
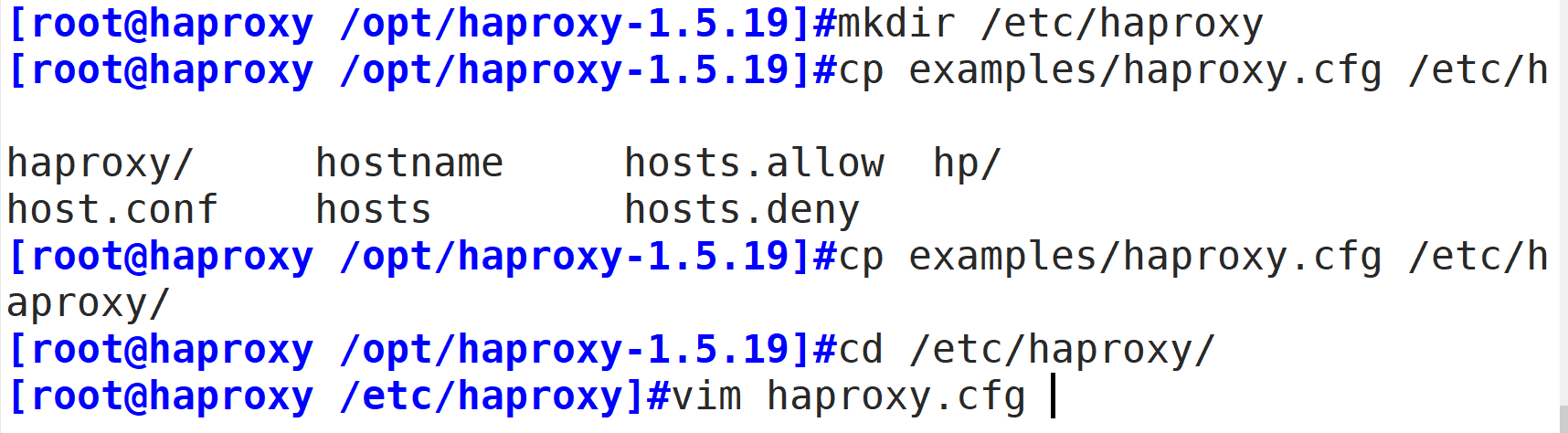
mkdir /etc/haproxy
cp examples/haproxy.cfg /etc/haproxy/
cd /etc/haproxy/
vim haproxy.cfg
global
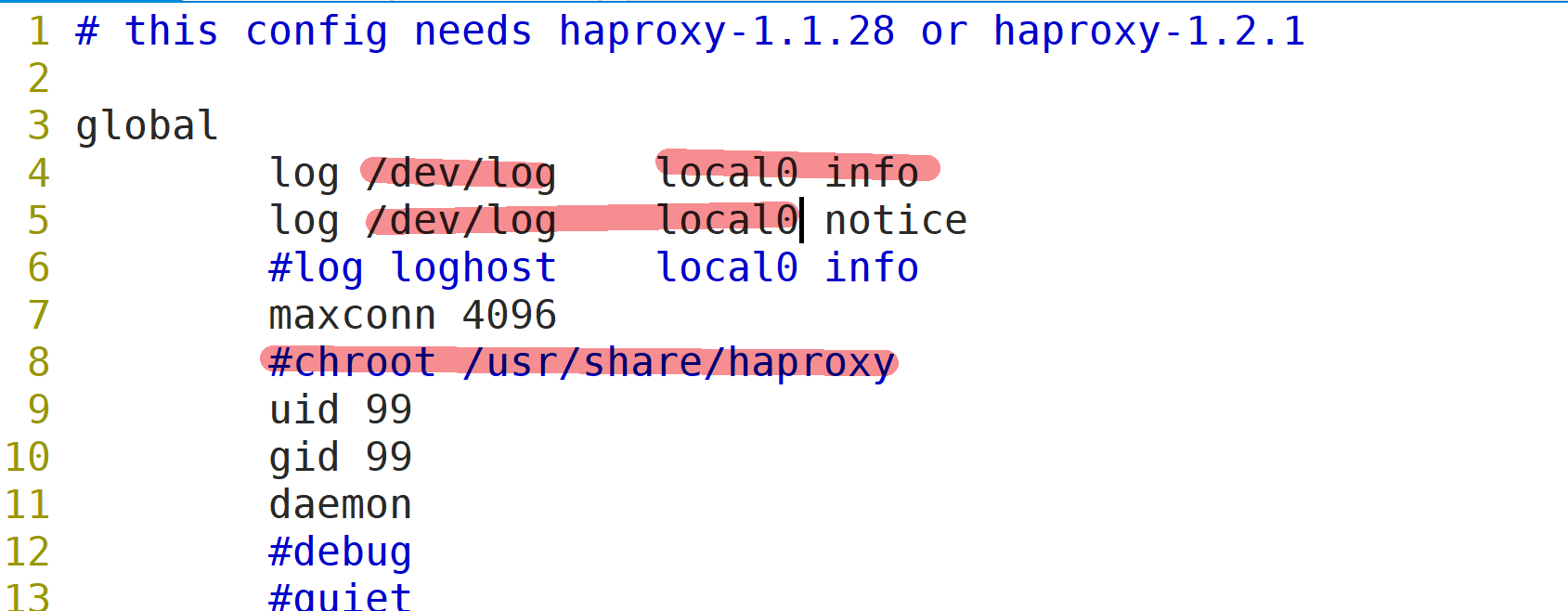
--4~5行--修改,配置日志记录,local0为日志设备,默认存放到系统日志
log /dev/log local0 info
log /dev/log local0 notice
#log loghost local0 info
maxconn 4096 #最大连接数,需考虑ulimit -n限制
--8行--注释,chroot运行路径,为该服务自设置的根目录,一般需将此行注释掉
#chroot /usr/share/haproxy
uid 99 #用户UID
gid 99 #用户GID
daemon #守护进程模式
defaults
log global #定义日志为global配置中的日志定义
mode http #模式为http
option httplog #采用http日志格式记录日志
option dontlognull #不记录健康检查日志信息
retries 3 #检查节点服务器失败次数,连续达到三次失败,则认为节点不可用
redispatch #当服务器负载很高时,自动结束当前队列处理比较久的连接
maxconn 2000 #最大连接数,“defaults”中的值不能超过“global”段中的定义
#contimeout 5000 #设置连接超时时间,默认单位是毫秒
#clitimeout 50000 #设置客户端超时时间,默认单位是毫秒
#srvtimeout 50000 #设置服务器超时时间,默认单位是毫秒
timeout http-request 10s #默认http请求超时时间
timeout queue 1m #默认队列超时时间
timeout connect 10s #默认连接超时时间,新版本中替代contimeout,该参数向后兼容
timeout client 1m #默认客户端超时时间,新版本中替代clitimeout,该参数向后兼容
timeout server 1m #默认服务器超时时间,新版本中替代srvtimeout,该参数向后兼容
timeout http-keep-alive 10s #默认持久连接超时时间
timeout check 10s #设置心跳检查超时时间
--删除下面所有listen项--,添加
listen webcluster 0.0.0.0:80 #定义一个名为webcluster的应用
option httpchk GET /test.html #检查服务器的test.html文件
balance roundrobin #负载均衡调度算法使用轮询算法roundrobin
server inst1 192.168.10.20:80 check inter 2000 fall 3 #定义在线节点
server inst2 192.168.10.30:80 check inter 2000 fall 3
---------------------参数说明---------------------------------------------------------------------------
balance roundrobin #负载均衡调度算法
#轮询算法:roundrobin;最小连接数算法:leastconn;来源访问调度算法:source,类似于nginx的ip_hash
check inter 2000 #表示haproxy服务器和节点之间的一个心跳频率
fall 3 #表示连续三次检测不到心跳频率则认为该节点失效
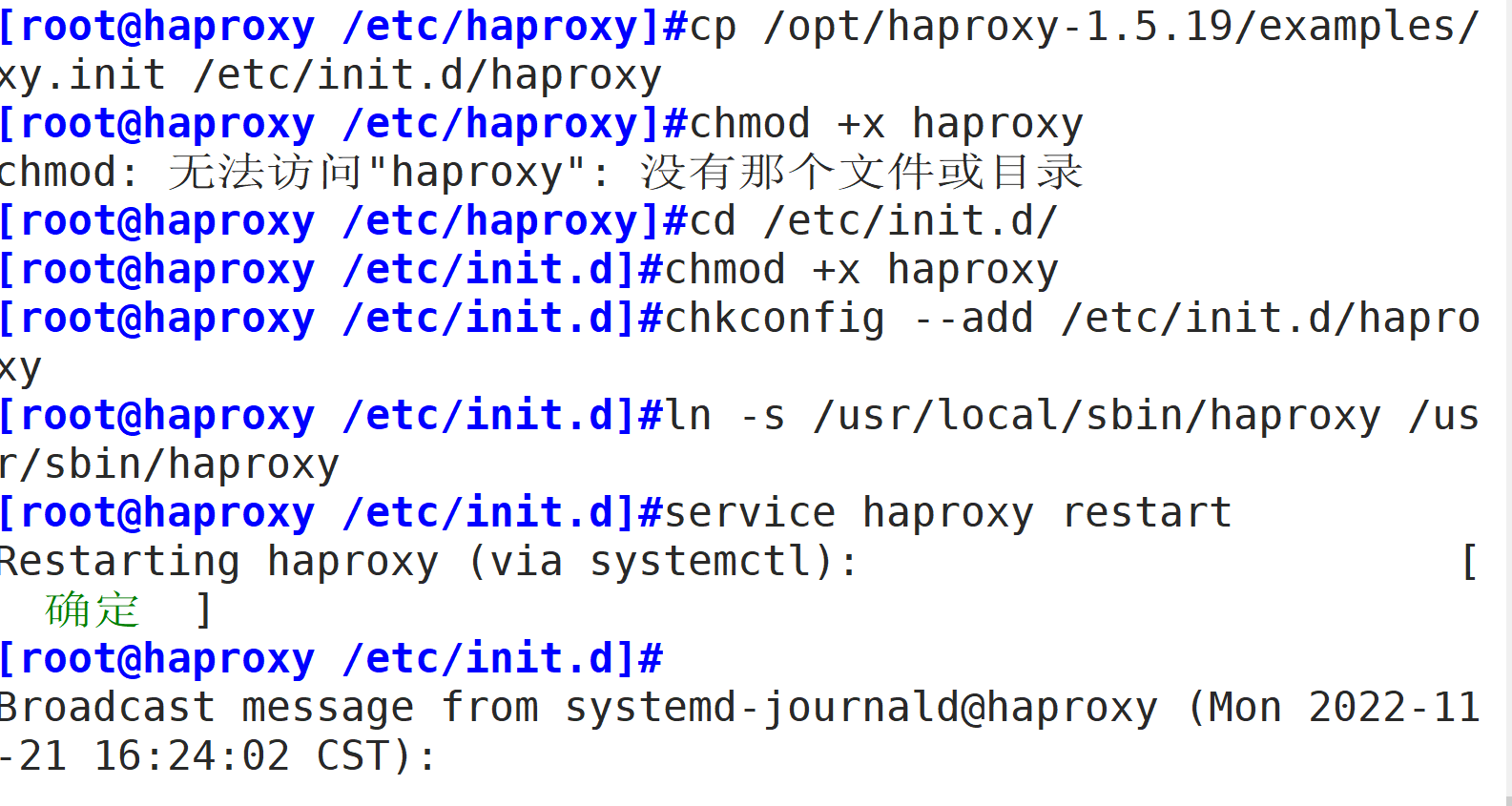
若节点配置后带有“backup”表示该节点只是个备份节点,只有主节点失效该节点才会上。不携带“backup”,表示为主节点,和其它主节点共同提供服务。cp /opt/haproxy-1.5.19/examples/haproxy.init /etc/init.d/haproxy
chmod +x haproxy
chkconfig --add /etc/init.d/haproxy
ln -s /usr/local/sbin/haproxy /usr/sbin/haproxy
service haproxy start 或 /etc/init.d/haproxy startsystemctl stop firewalld
setenforce 0
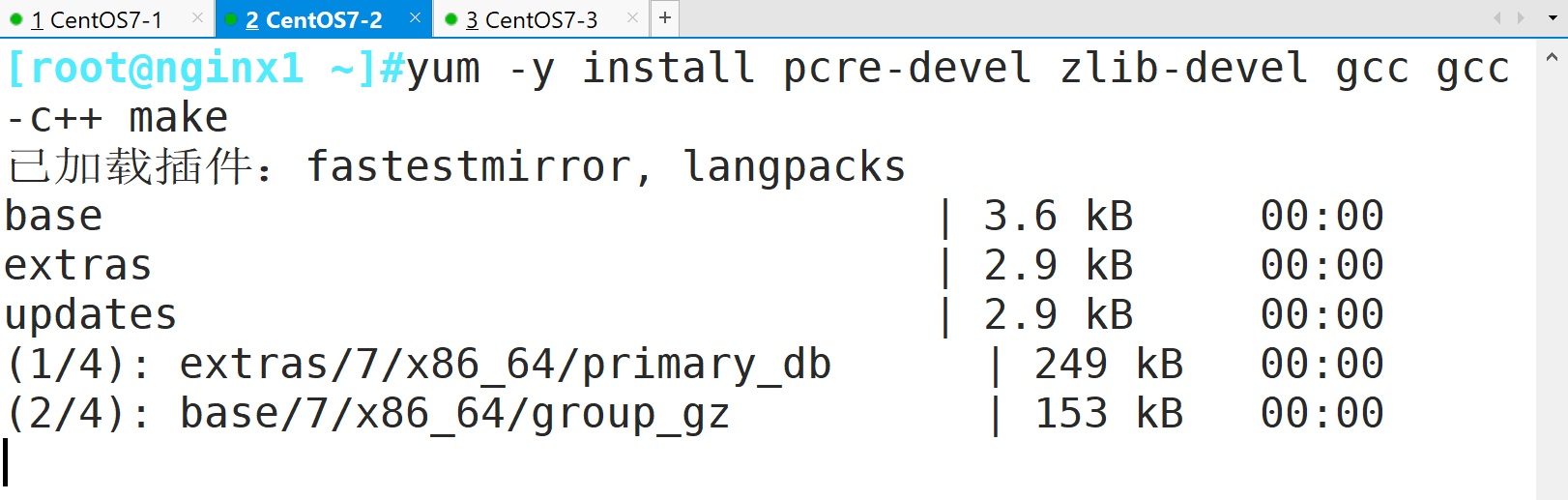
yum install -y pcre-devel zlib-devel gcc gcc-c++ make
useradd -M -s /sbin/nologin nginx
cd /opt
tar zxvf nginx-1.12.0.tar.gz -C /opt/
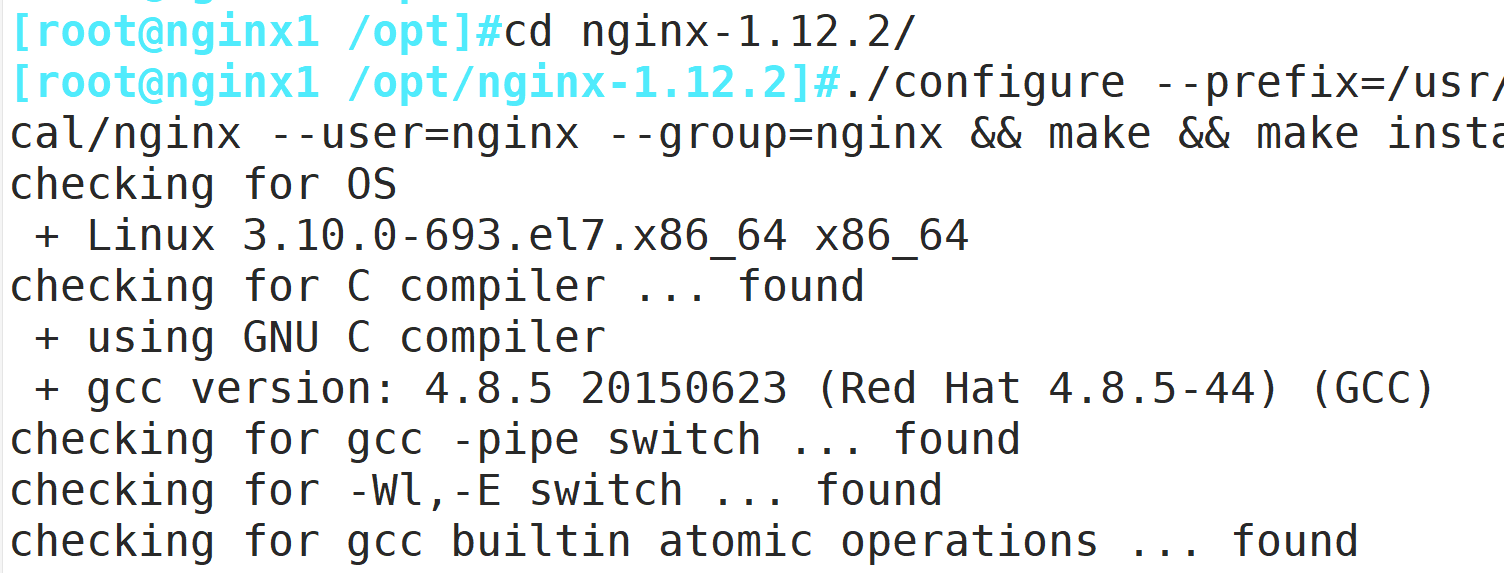
cd nginx-1.12.0/
./configure --prefix=/usr/local/nginx --user=nginx --group=nginx && make && make install
make && make install
--192.168.10.20---
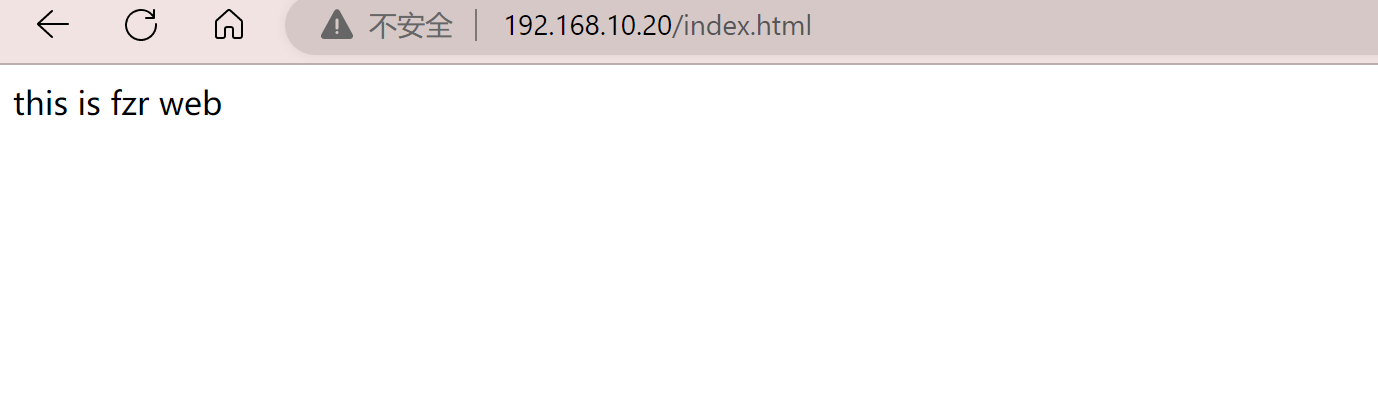
echo "this is xkq web" > /usr/share/nginx/html/index.html
--192.168.10.30---
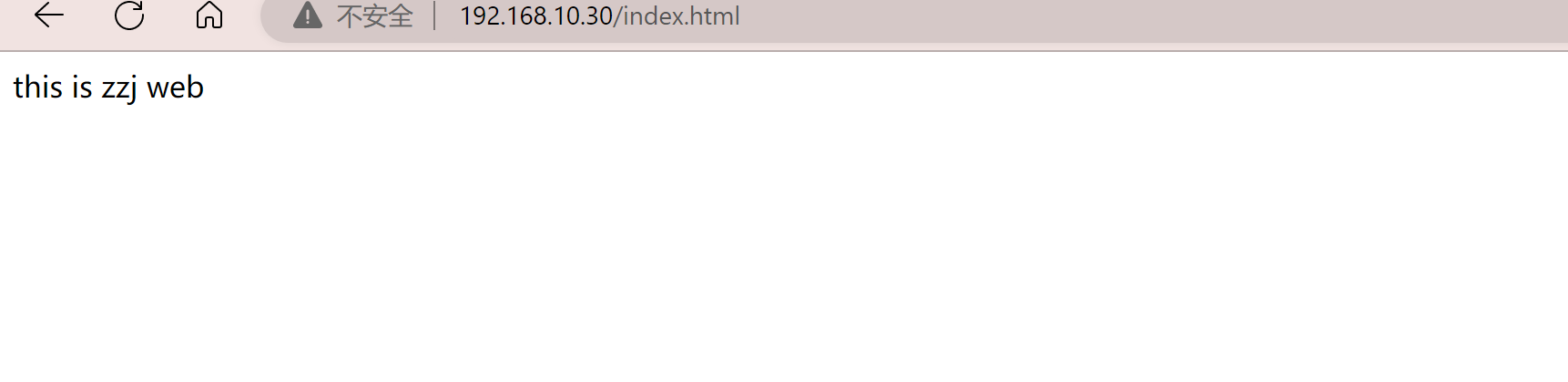
echo "this is wy web" > /usr/share/nginx/html/index.html
ln -s /usr/share/nginx/sbin/nginx /usr/local/sbin/
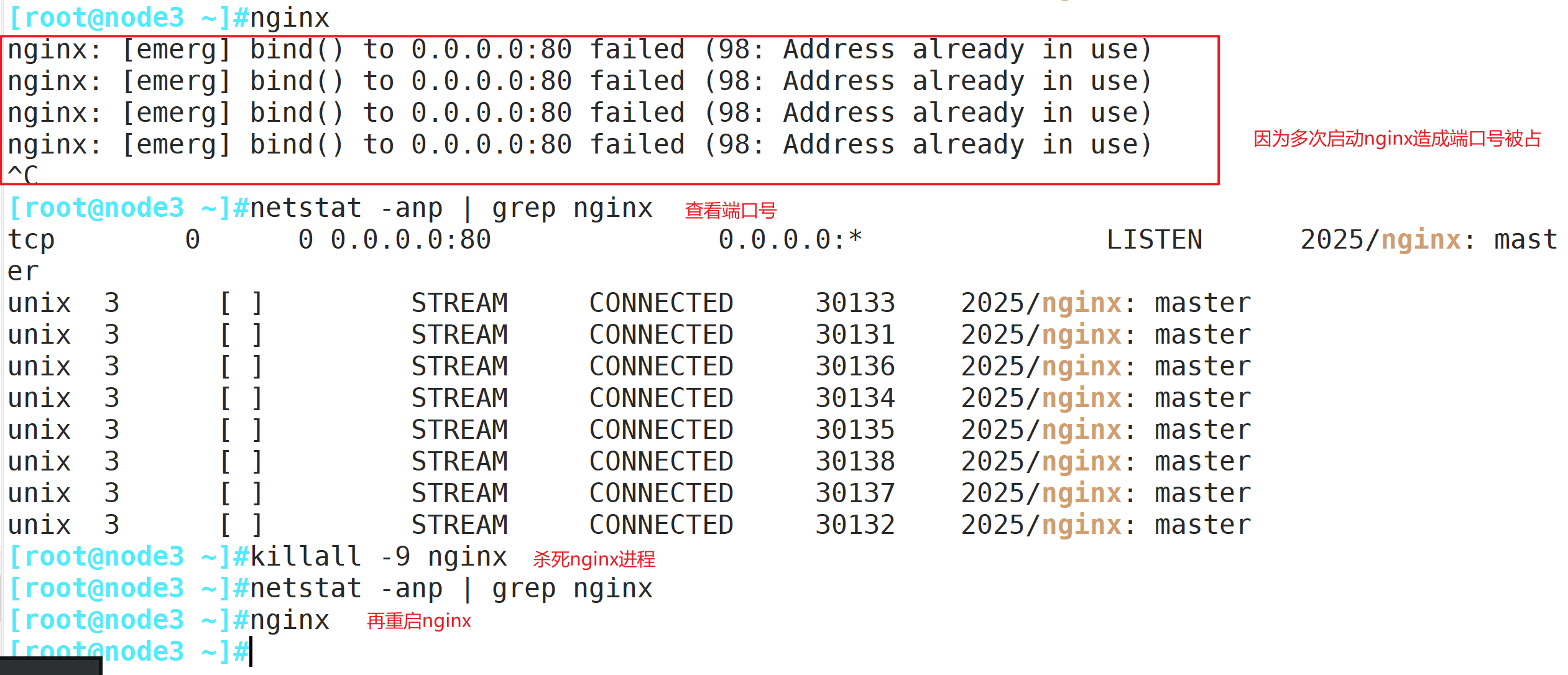
nginx #启动nginx 服
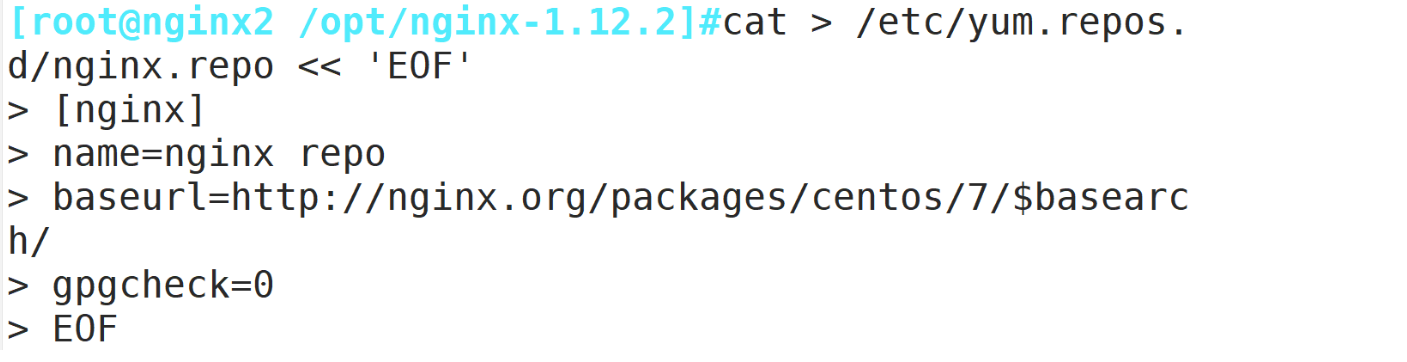
或者用yum安装
cat > /etc/yum.repos.d/nginx.repo << 'EOF'
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/7/$basearch/
gpgcheck=0
EOF
yum install nginx -y在客户端使用浏览器打开 http://192.168.10.10/index.html ,不断刷新浏览器测试负载均衡效果




nginx1节点:


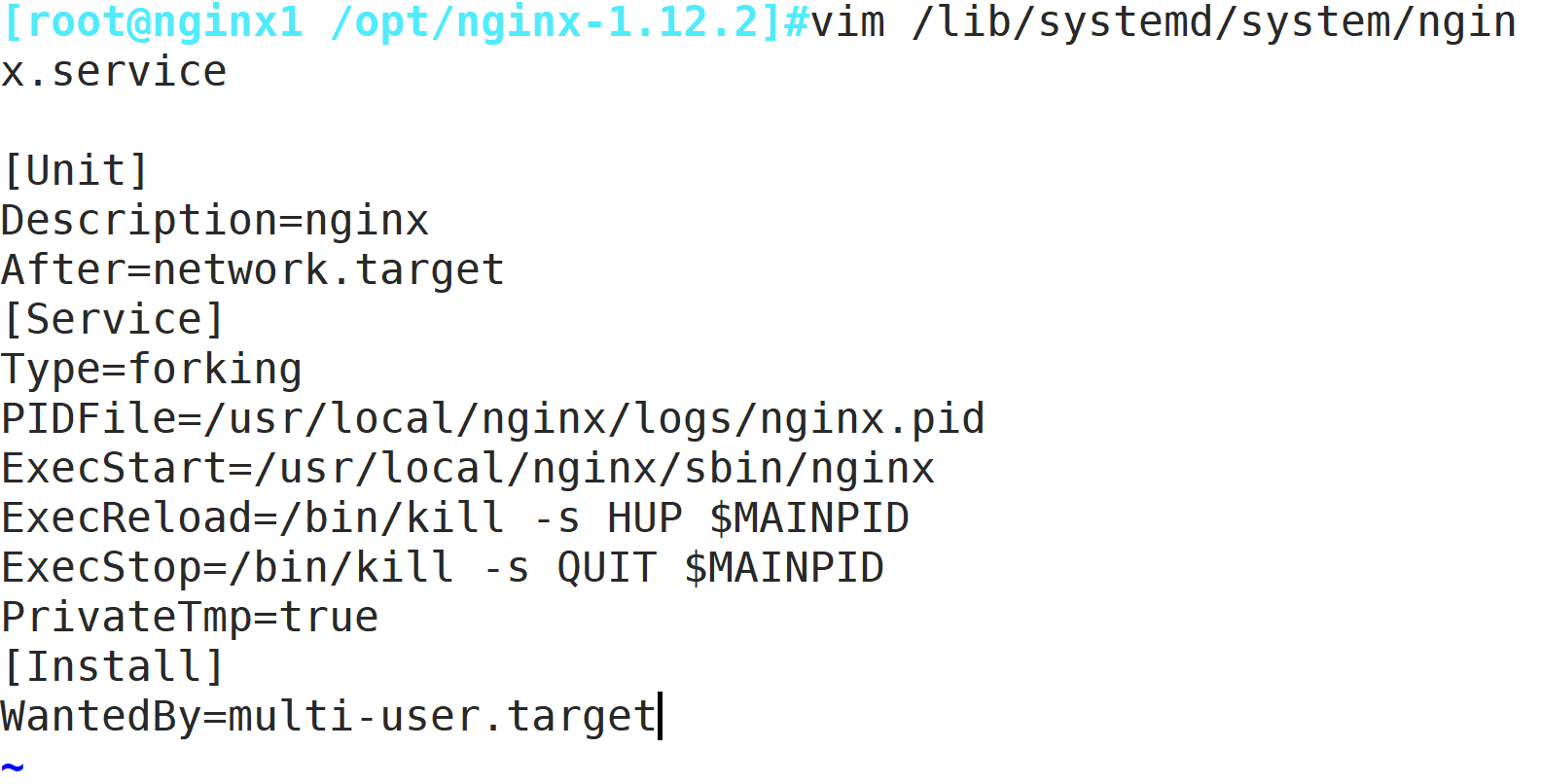

nginx2节点:上次nginx包到/opt目录解压和nginx1操作一样,或者如下操作用yum安装
web1测试页面:
web2测试页面:
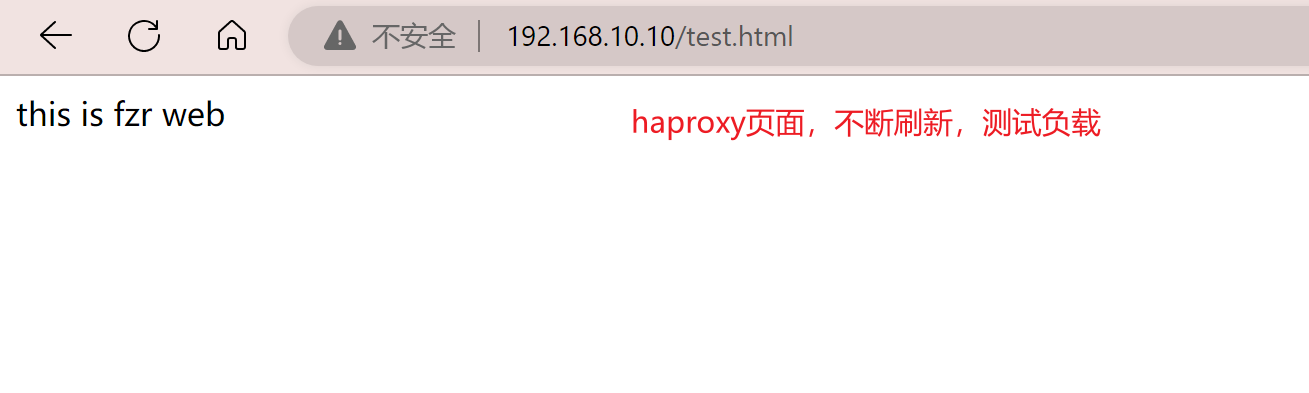
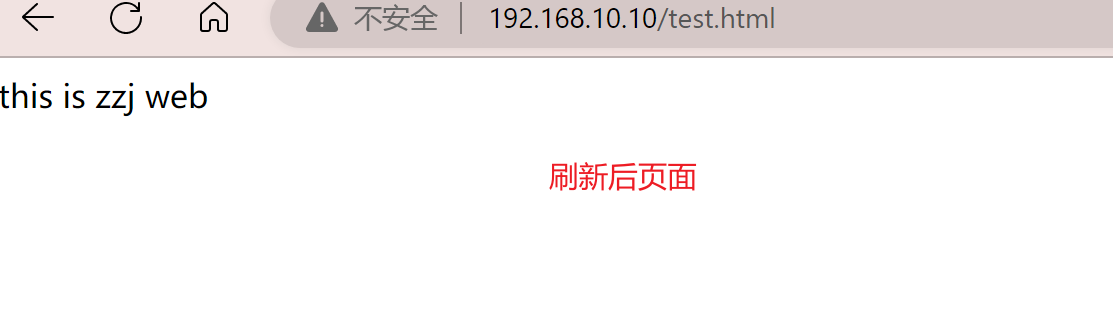
默认haproxy的日志是输出到系统的syslog中,查看起来不是非常方便,为了更好的管理haproxy的日志,我们在生产环境中一般单独定义出来。需要将haproxy的info及notice日志分别记录到不同的日志文件中
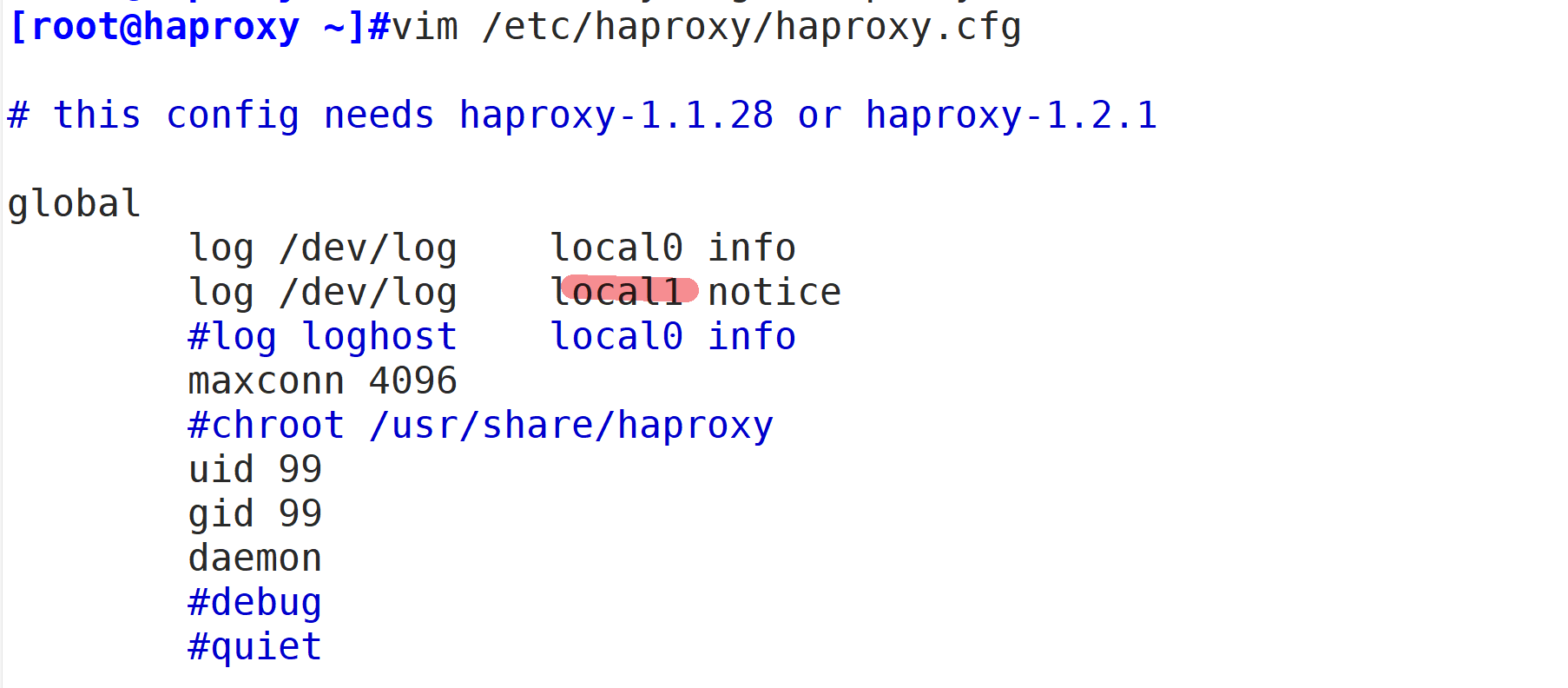
vim /etc/haproxy/haproxy.cfg
global
log /dev/log local0 info
log /dev/log local0 notice
service haproxy restart
#需要修改rsyslog配置,为了便于管理。将haproxy相关的配置独立定义到haproxy.conf,并放到/etc/rsyslog.d/下,rsyslog启动时会自动加载此目录下的所有配置文件。
vim /etc/rsyslog.d/haproxy.conf
if ($programname == 'haproxy' and $syslogseverity-text == 'info')
then -/var/log/haproxy/haproxy-info.log
&~
if ($programname == 'haproxy' and $syslogseverity-text == 'notice')
then -/var/log/haproxy/haproxy-notice.log
&~
#说明:
这部分配置是将haproxy的info日志记录到/var/log/haproxy/haproxy-info.log下,将notice日志记录到/var/log/haproxy/haproxy-notice.log下。“&~”表示当日志写入到日志文件后,rsyslog停止处理这个信息。
systemctl restart rsyslog.service
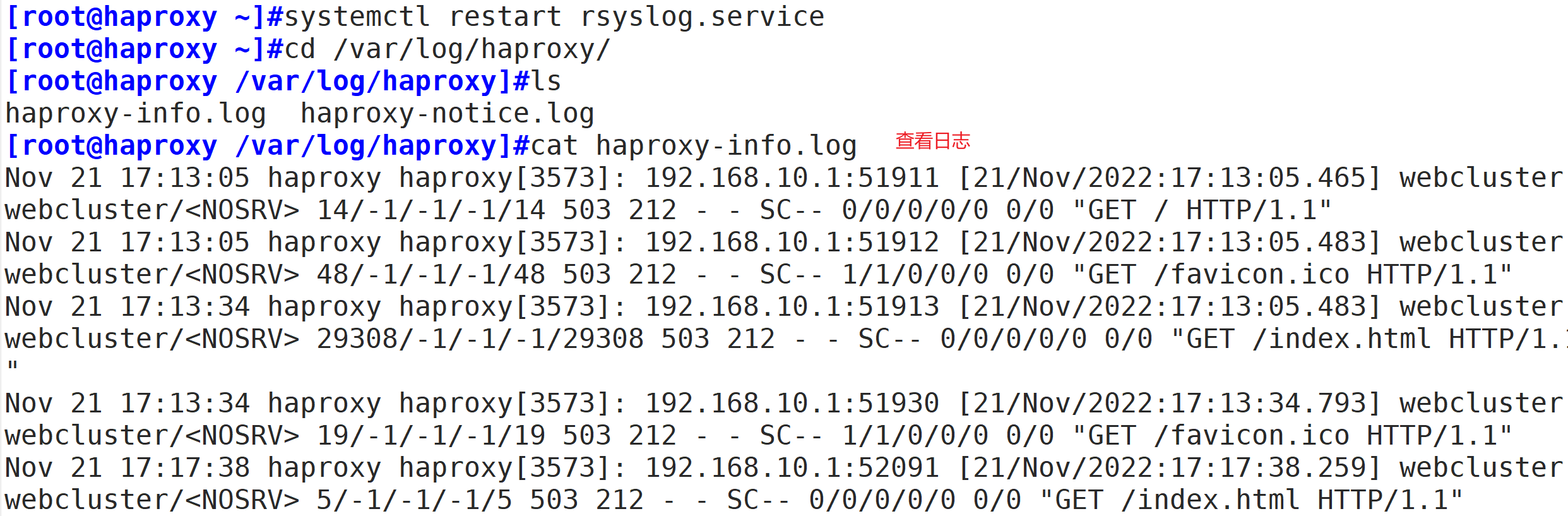
tail -f /var/log/haproxy/haproxy-info.log #查看haproxy的访问请求日志信息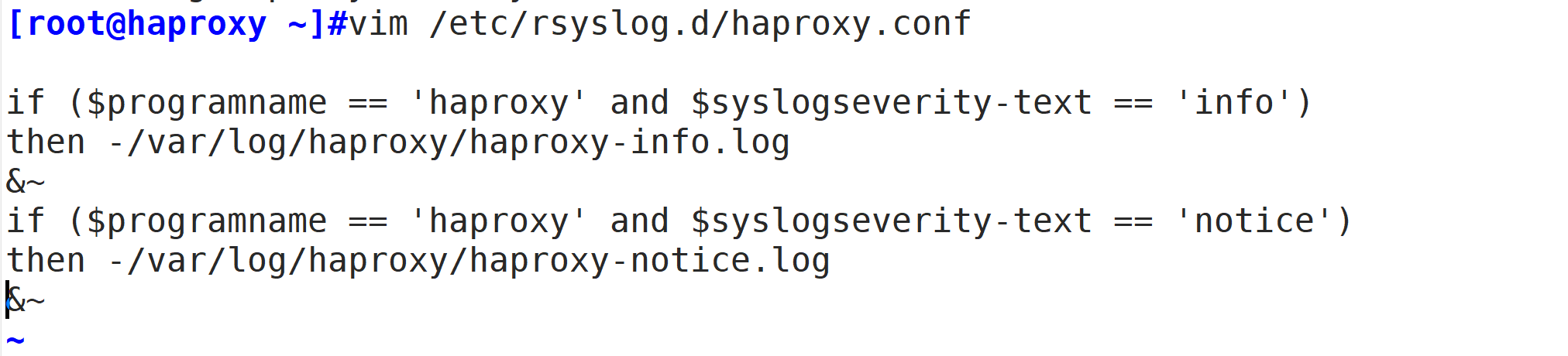
我正在使用Ruby/Mechanize编写一个“自动填写表格”应用程序。它几乎可以工作。我可以使用精彩CharlesWeb代理以查看服务器和我的Firefox浏览器之间的交换。现在我想使用Charles查看服务器和我的应用程序之间的交换。Charles在端口8888上代理。假设服务器位于https://my.host.com。.一件不起作用的事情是:@agent||=Mechanize.newdo|agent|agent.set_proxy("my.host.com",8888)end这会导致Net::HTTP::Persistent::Error:...lib/net/http/pe
Asitcurrentlystands,thisquestionisnotagoodfitforourQ&Aformat.Weexpectanswerstobesupportedbyfacts,references,orexpertise,butthisquestionwilllikelysolicitdebate,arguments,polling,orextendeddiscussion.Ifyoufeelthatthisquestioncanbeimprovedandpossiblyreopened,visitthehelpcenter提供指导。11年前关闭。我是一位精通HTML
我目前正在为一个新网站设计版本化的API。我了解如何为路由命名空间,但我一直坚持在模型中实现版本化方法的最佳方式。下面的代码示例使用的是rails框架,但是事情的原理在大多数web框架之间应该是一致的。目前的路线看起来像这样:MyApp::Application.routes.drawdonamespace:apidonamespace:v1doresources:products,:only=>[:index,:show]endendend和Controller:classApi::V1::ProductsController很明显,我们只是在此处公开Product上可用的属性,如果
我正在尝试使用ruby来使用Sharepoint网络服务。我基本上已经放弃尝试使用NTLM进行身份验证,并暂时将Sharepoint服务器更改为使用基本身份验证。我已成功使用soap4r获得WSDL,但在尝试使用实际Web服务调用时仍然无法进行身份验证。有没有人有过让ruby和Sharepoint对话的经验? 最佳答案 我是个新手。但经过很多时间并在更多经验编码人员的帮助下,我能够让ruby与Sharepoint2010一起工作。下面的代码需要“ntlm/mechanize”gem。我已经能够使用列表GUID和ListV
2022年10月21日星期五【数据指标】加密货币总市值:$0.95万亿BTC市值占比:38.51%恐慌贪婪指数:23极度恐慌 【今日快讯】1、【政讯】1.1.1、美联储布拉德:市场预期美联储11月会加息75个基点1.1.2、美联储哈克:将维持加息一段时间1.2、美国10年期国债收益率触及4.197%,为2008年6月以来最高1.3、法国数字转型部长:政府将专注于DeFi和Web31.4、巴西ATM机将于11月3日起支持USDT1.5、美众议院副议长将于11月初加入a16zCrypto担任政府事务主管1.6、香港数字资产托管机构FirstDigitalTrust首席执行官:香港仍是安全
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
WAF可以对网站进行扫描,识别API漏洞。API安全如何设置API安全_Web应用防火墙-阿里云帮助中心API安全如何划分API业务用途?登录认证手机验证码认证数据保存数据查询数据导出数据分享数据更新数据删除数据增加下线注销信息发送信息认证邮件信息发送邮箱验证码认证账号密码认证账号注册API安全支持检测哪些敏感数据?敏感数据级别敏感数据类型非敏感数据(N)不涉及。特级敏感数据(L0)与一级敏感数据(L1)或二级敏感数据(L2)相同。单次响应中一级敏感数据(L1)较多时,升级为特级敏感数据(L0)。单次响应中二级敏感数据(L2)较多时,升级为一级敏感数据(L1)或特级敏感数据(L0)。一级敏感数
我正在使用RubyonRails3,我正在尝试实现API以从Web服务检索帐户信息。也就是说,我想连接到具有Account类的Web服务并从show获取信息。在URIhttp:///accounts/1处路由的操作.此时,在网络服务中accounts_controller.rb我有的文件:classAccountsController@account.to_json}endendend现在我需要一些关于连接到网络服务的建议。在客户端应用程序中,我应该有一个HTTPGET请求,但这是我的问题:连接到发出HTTP请求的Web服务的“最佳”方法是什么?客户端应用程序中的这段代码有效:url=
谁能告诉我实现rubyonrailsweb应用程序30试用期的最佳方法,很像Basecampfrom37signals的方式是吗?目前我有一个用户登录页面,然后用户可以访问显示有关其产品/定价等的当前信息的仪表板。我希望用户能够注册并拥有完整的应用程序功能,然后在30天后过期。谢谢 最佳答案 创建用于x天试用期的Rails应用程序非常容易。您想为您的用户实现30天的试用期,然后执行以下操作:第1步:在application_controller.rb中创建这些方法,例如#application_controller.rbclas
文章目录查看ES信息查看节点信息查看分片信息实际场景下ES分片及副本数量应该怎么分关于ES的灵活使用查看ES信息查看版本kibana:GET/查看节点信息GET/_cat/nodes?v解释:ip:集群中节点的ip地址;heap.percent:堆内存的占用百分比;ram.percent:总内存的占用百分比,其实这个不是很准确,因为buff/cache和available也被当作使用内存;cpu:cpu占用百分比;load_1m:1分钟内cpu负载;load_5m:5分钟内cpu负载;load_15m:15分钟内cpu负载;node.role:上图的dilmrt代表全部权限master:*代表