传送门: https://www.cnblogs.com/greentomlee/p/12314064.html
github: https://github.com/Leezhen2014/python_deep_learning
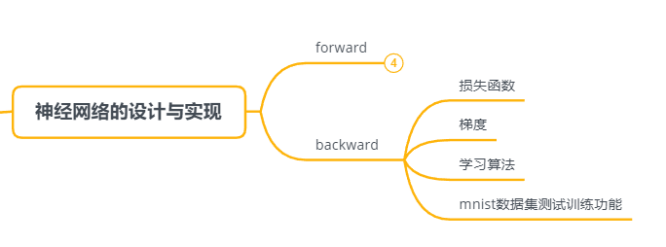
在第二篇中介绍了用数值微分的形式计算神经网络的梯度,数值微分的形式比较简单也容易实现,但是计算上比较耗时。本章会介绍一种能够较为高效的计算出梯度的方法:基于图的误差反向传播。
根据 deep learning from scratch 这本书的介绍,在误差反向传播方法的实现上有两种方法:一种是基于数学式的(第二篇就是利用的这种方法),一种是基于计算图的。这两种方法的本质是一样的,有所不同的是表述方法。计算图的方法可以参考feifei li负责的斯坦福大学公开课CS231n 或者theano的tutorial/Futher readings/graph Structures.
之前我们的误差传播是基于数学式的,可以看出对代码编写者来说很麻烦;
这次我们换成基于计算图的;
Backward是神经网络训练过程中包含的一个过程,在这个过程中会通过反馈调节网络中各个节点的权重,以此达到最佳权重参数。在反馈中,loss value是起点,是衡量与label之间差距的值。Loss value 自然是loss function计算得出的。
TODO:
本章会讲解常见的两种loss function
然后会介绍梯度,梯度是用于修改节点权重的。
最后会实现backward,用mnist数据集训练;
损失函数的种类有很多, 本案只介绍两种损失函数: 均方差、交叉熵;
然后会将交叉熵改写成n-batch的交叉熵;

实现如下:
1 def mean_squared_error(y, t):
2 return 0.5*np.sum((y-t)**2)
交叉熵的公式和实现如下:
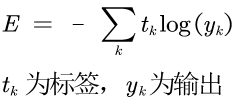
1 def cross_entropy_error(y,t):
2 delta = 1e-7
3 return -np.sum(t*np.log(y+delta))
上述的两个损失函数都是针对于1-batch做的损失函数;如果输入的数据是n-batch的话,上述的损失函数不太适用了;
需要对损失函数做一下修改,以交叉熵为例,n-batch的交叉熵公式和代码实现如下:
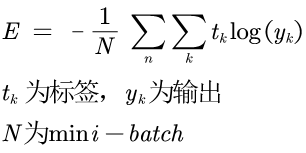
1 def cross_entropy_error(y,t):
2 # batch版本的交叉熵
3 if y.ndim == 1:
4 t = t.reshape(1, t.size)
5 y = y.reshape(1, y.size)
6 batch_size = y.shape[0] # batch
7
8 delta = 1e-7
9 return -np.sum(t*np.log(y+delta))/batch_size
10
本节介绍梯度法的实现,不涉及神经网络的反馈算法。本节内容是为下一节反馈算法做铺垫。
神经网络学习的本质是根据数据的label和预测值的误差,即loss value,然后根据误差修改权重信息。
数据的label和预测值的误差可以使用损失函数来衡量,获得loss value。
修改权重的信息可以用求数学统计求极值的方式获得。
已知导数为0的点为极值点,可以通过求导数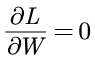 一次性找到极值点。但是这种方法在数据样本或者W的规模相当大的情况下是无法计算的,在具有多个变量的情况下会计算多次的偏导数,可以想象到是一件耗时耗力的事情。
一次性找到极值点。但是这种方法在数据样本或者W的规模相当大的情况下是无法计算的,在具有多个变量的情况下会计算多次的偏导数,可以想象到是一件耗时耗力的事情。
梯度法来恰恰可以弥补上述的缺陷。
梯度法优势在于可以一次计算出多个变量的偏导数,并汇总成向量,像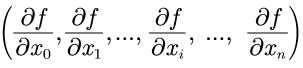 这种汇总而成的向量,称为梯度(注: 来自 deep learning from scratch)。
这种汇总而成的向量,称为梯度(注: 来自 deep learning from scratch)。
接下来就是梯度的实现了,计算机是无法直接求出偏导数或者导数的,不过根据数学知识可以得到偏导数的近似值,因此可以:
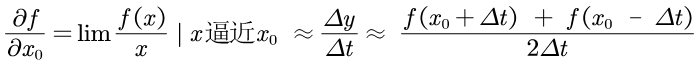
对应的实现程序如下:
1 def numerical_gradient_1d(f, x):
2 '''
3 数值微分,求f(x)的梯度
4 :param f: 函数
5 :param x: 梯度值
6 :return: df在x处的导数
7 '''
8 h = 1e-4 # 0.0001
9 grad = np.zeros_like(x)
10
11 for idx in range(x.size):
12 tmp_val = x[idx] # 缓存原来的值
13 x[idx] = float(tmp_val) + h
14 fxh1 = f(x) # f(x+h)
15
16 x[idx] = tmp_val - h
17 fxh2 = f(x) # f(x-h)
18 grad[idx] = (fxh1 - fxh2) / (2*h)
19
20 x[idx] = tmp_val # 原来的值
21
22 return grad以上是1D的梯度下降,我们可以扩展成2D的梯度下降函数numerical_gradient_2d:
1 def numerical_gradient_2d(f, X):
2 if X.ndim == 1:
3 return _numerical_gradient_1d(f, X)
4 else:
5 grad = np.zeros_like(X)
6
7 for idx, x in enumerate(X):
8 grad[idx] = _numerical_gradient_1d(f, x)
9
10 return grad
11
1
2 def numerical_gradient(f, x):
3 '''
4 数值微分,求f(x)的梯度
5 :param f:
6 :param x:
7 :return:
8 '''
9 h = 1e-4 # 0.0001
10 grad = np.zeros_like(x)
11
12 it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
13 while not it.finished:
14 idx = it.multi_index
15 tmp_val = x[idx]
16 x[idx] = tmp_val + h
17 fxh1 = f(x) # f(x+h)
18
19 x[idx] = tmp_val - h
20 fxh2 = f(x) # f(x-h)
21 grad[idx] = (fxh1 - fxh2) / (2*h)
22
23 x[idx] = tmp_val # 恢复成原来的值
24 it.iternext()
25
26 return grad
27
作为一个严谨的程序员,自己 写的每一个模块至少需要做一次验证,以减少后期出现bug的调试;
在此,简单的验证 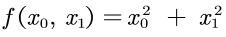 的在点
的在点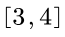 上的梯度;
上的梯度;
根据数学知识,可以知道梯度为: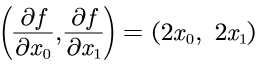
那么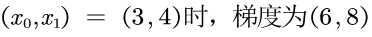
下面开始验证
片段1: function的实现:
1 def function(x):
2 return x[0]**2 + x[1]**2function的坐标图如下, 可见整个函数的最小值在(0,0)处,因此点(3,4)的梯度方向应该指向(0,0),即:梯度值应该为正数。
1 from matplotlib import pyplot as plot # 用来绘制图形
2 import numpy as np # 用来处理数据
3 from mpl_toolkits.mplot3d import Axes3D # 用来给出三维坐标系。
4 figure = plot.figure()
5
6 # 画出三维坐标系:
7 axes = Axes3D(figure)
8 X = np.arange(-10, 10, 0.25)
9 Y = np.arange(-10, 10, 0.25)
10 X, Y = np.meshgrid(X, Y) # 限定图形的样式是网格线的样式:
11 Z = function([X,Y])
12 axes.plot_surface(X, Y, Z, cmap='rainbow') # 绘制曲面,采用彩虹色着色:
13 # 图形可视化:
14 plot.show()
15
16 if __name__ == '__main__':
17 # show()
18 print(numerical_gradient(function, np.array([3.0,4.0])))对应的输出:
[6. 8.]
验证正确, 说明grad的书写没有问题。
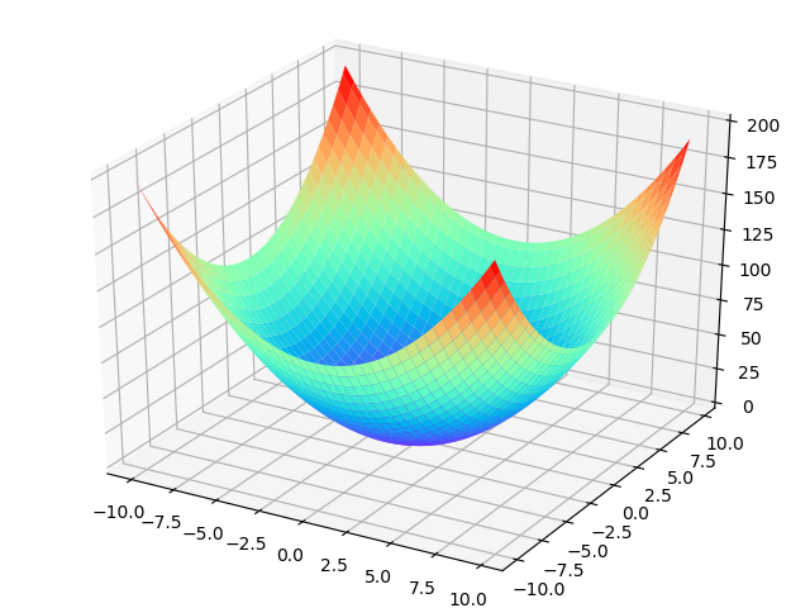
神经网络学习的主要任务是在学习过程中寻找最优参数,这些参数使得loss function 取得最小值。这里的神经网络可以用g(x)表示。
一般来说,神经网络的参数空间较大,损失函数也较为复杂,往往会通过梯度来寻找g(x)的最小值。但需要注意:梯度表示的各个点处函数值减小最多的方向,无法保证是真正的应该进行梯度下降的方向。
尽管如此,沿着梯度的方向依旧是可以最大限度的找到减小损失函数的值。通过不断的向梯度的方向迈进,便会使得loss function逐渐减小(这个过程被称为 梯度法,gradient method)。
梯度法是解决机器学习中优化问题的常用方法,根据优化的目标可以分为: 梯度下降法和梯度上升法。
用数学表达为:
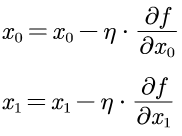
利用上面的公式和numerical_gradient,梯度法的实现如下:
1 def gradient_descent(f, init_x, learning_rate=0.01, step_num=200):
2 '''
3 通过一步一步的迭代,优化目标函数,找出使得目标函数最小的点
4 :param f: 目标函数
5 :param init_x: 初始位置
6 :param learning_rate: 学习率
7 :param step_num: 迭代次数
8 :return:
9 '''
10 x = init_x
11 for i in range(step_num):
12 grad = numerical_gradient(f,x)
13 x = x - learning_rate*grad # 公式的实现
14 return x
15
16 if __name__ == '__main__':
17 # show()
18 #print(numerical_gradient(function, np.array([3.0,4.0])))
19 min_value = gradient_descent(function, init_x=np.array([3.0,4.0]))
20 print(min_value)
本节会阐述学习算法的伪代码,具体实现会在3.4给出。
神经网络的学习中使用到了梯度法(见3.2节),根据梯度法我们可以了解到神经网络学习的过程:可以按照以下4个步骤进行:
Step1:获取minibatch:
从数据集中选取一部分数据,这部分数据称为mini-batch,现在的目标就是减小minibatch 的loss fucntion value。
Step2:计算梯度值
为了减小loss function的值,求出各个权重参数的梯度。梯度是表示损失函数值减小最多的方向。
Step3:更新参数
梯度表示的是损失函数减小的方向;因此将权重参数沿着梯度所指的方向进行微小的更新。
Step4:迭代重复
重复Step1,2,3
以上使用的是梯度下降的方法,由于是随机选择的mini-batch数据(也就是说随机选择的初始点),所以称为 随机梯度下降(stochastic gradient descent)注:见Deep Learning from Scratch
本节整合前面的代码,实现一个两层的神经网络。用mnist数据集训练,来了解整个学习的过程。整个过程会尽量简化.
为了简化起见,网络输入层是784*1,有两个隐含层,神经元的数量分别是50和10; 由于输出层和上一层的输出数量一致,因此用恒等函数即可, 损失函数使用交叉熵。
网络结构如下:
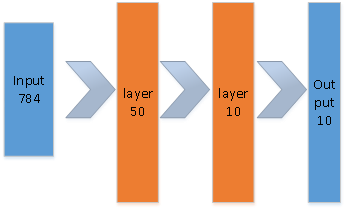
网络结构的实现:
1 # -*- coding: utf-8 -*-
2 # @File : two_layer_net.py
3 # @Author: lizhen
4 # @Date : 2020/1/28
5 # @Desc : 使用梯度的网络
6
7 from src.common.functions import *
8 from src.common.gradient import numerical_gradient
9 import numpy as np
10
11 class TwoLayerNet:
12
13 def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
14
15 self.params = {}
16 self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
17 self.params['b1'] = np.zeros(hidden_size)
18 self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
19 self.params['b2'] = np.zeros(output_size)
20
21 def predict(self, x):
22 W1, W2 = self.params['W1'], self.params['W2']
23 b1, b2 = self.params['b1'], self.params['b2']
24
25 a1 = np.dot(x, W1) + b1
26 z1 = sigmoid(a1)
27 a2 = np.dot(z1, W2) + b2
28 y = softmax(a2)
29
30 return y
31
32 # x:输入参数, t:label
33 def loss(self, x, t):
34 y = self.predict(x)
35
36 return cross_entropy_error(y, t)
37
38 def accuracy(self, x, t):
39 y = self.predict(x)
40 y = np.argmax(y, axis=1)
41 t = np.argmax(t, axis=1)
42
43 accuracy = np.sum(y == t) / float(x.shape[0])
44 return accuracy
45
46 # x:输入参数, t:label
47 def numerical_gradient(self, x, t):
48 loss_W = lambda W: self.loss(x, t)
49
50 grads = {}
51 grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
52 grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
53 grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
54 grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
55
56 return grads
57
58 def gradient(self, x, t):
59 W1, W2 = self.params['W1'], self.params['W2']
60 b1, b2 = self.params['b1'], self.params['b2']
61 grads = {}
62
63 batch_num = x.shape[0]
64
65 # forward
66 a1 = np.dot(x, W1) + b1
67 z1 = sigmoid(a1)
68 a2 = np.dot(z1, W2) + b2
69 y = softmax(a2)
70
71 # backward
72 dy = (y - t) / batch_num
73 grads['W2'] = np.dot(z1.T, dy)
74 grads['b2'] = np.sum(dy, axis=0)
75
76 dz1 = np.dot(dy, W2.T)
77 da1 = sigmoid_grad(a1) * dz1
78 grads['W1'] = np.dot(x.T, da1)
79 grads['b1'] = np.sum(da1, axis=0)
80
81 return grads
训练代码:
1 # -*- coding: utf-8 -*-
2 # @File : train_neuralnet.py
3 # @Author: lizhen
4 # @Date : 2020/2/2
5 # @Desc : 第三篇的实现: 利用梯度
6
7 import numpy as np
8 import matplotlib.pyplot as plt
9 from src.datasets.mnist import load_mnist
10 from src.test.two_layer_net import TwoLayerNet
11
12 # 获取训练数据
13 (x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
14
15 network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
16
17 iters_num = 10000 # 迭代次数
18 train_size = x_train.shape[0]
19 batch_size = 100
20 learning_rate = 0.1
21
22 train_loss_list = []
23 train_acc_list = []
24 test_acc_list = []
25
26 iter_per_epoch = max(train_size / batch_size, 1)
27
28 for i in range(iters_num):
29 batch_mask = np.random.choice(train_size, batch_size)
30 x_batch = x_train[batch_mask]
31 t_batch = t_train[batch_mask]
32
33 # 计算梯度
34 grad = network.numerical_gradient(x_batch, t_batch)
35 # grad = network.gradient(x_batch, t_batch) # 较快
36
37 # 更新权重
38 for key in ('W1', 'b1', 'W2', 'b2'):
39 network.params[key] -= learning_rate * grad[key]
40
41 loss = network.loss(x_batch, t_batch)
42 train_loss_list.append(loss)
43
44 if i % iter_per_epoch == 0:
45 train_acc = network.accuracy(x_train, t_train)
46 test_acc = network.accuracy(x_test, t_test)
47 train_acc_list.append(train_acc)
48 test_acc_list.append(test_acc)
49 print("train acc, test acc , loss | " + str(train_acc) + ", " + str(test_acc)+", "+str(loss))
50
51
52 # 绘制图
53 markers = {'train': 'o', 'test': 's'}
54 x = np.arange(len(train_acc_list))
55 plt.plot(x, train_acc_list, label='train acc')
56 plt.plot(x, test_acc_list, label='test acc', linestyle='--')
57
58 plt.xlabel("epochs")
59 plt.ylabel("accuracy")
60 plt.ylim(0, 1.0)
61 plt.legend(loc='lower right')
62 plt.show()
63
64 # plt.plot(train_loss_list,label='loss value')
65 # plt.show()
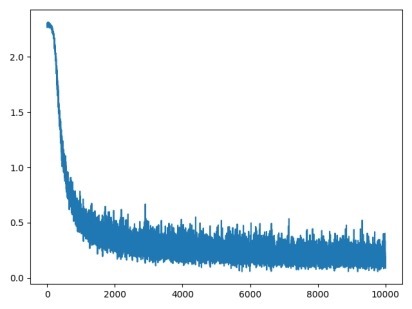
输出:

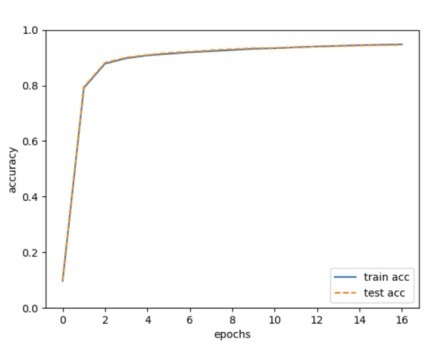
Loss 曲线图和acc变化曲线如下
2020年2月3日星期一
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg