centos7配置静态网络常见问题归纳_centos7网络问题
本文主要介绍zookeeper的本地模式于集群模式的配置,包含集群启动于关闭脚本,以下为配置步骤
条件:centos7已经配置了jdk
配置jdk教程连接:虚拟机centos7配置Hadoop单节点伪分布配置教程
拷贝 apache-zookeeper-3.5.7-bin.tar.gz安装 包 到 Linux系统下
解压 到指定目录
[atguigu@hadoop102 software]$ tar zxvf apache zookeeper 3.5.7bin.tar.gz C /opt/module/
修改名称
[atguigu@hadoop102 module]$ mv apache zookeeper 3.5.7 bin/zookeeper 3.5.7
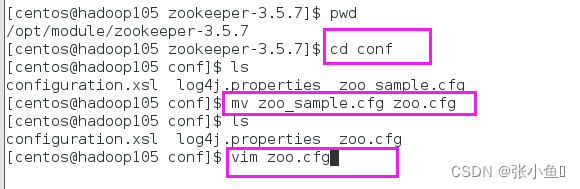
1)将 /opt/module/zookeeper-3.5.7/conf这个 路径下的 zoo_sample.cfg修改 为 zoo.cfg
[atguigu@hadoop102 conf ]$ mv zoo_sample.cfg zoo.cfg
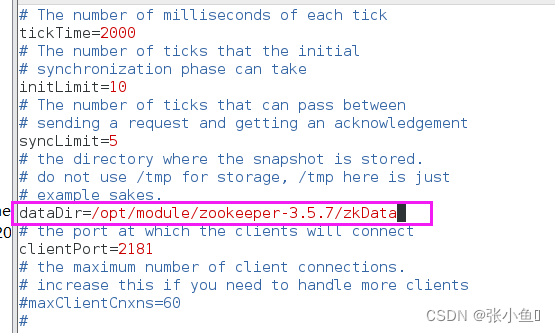
2) 打开 zoo.cfg文件 ,修改 dataDir路径
[atguigu@hadoop102 zookeeper 3.5.7 ]$ vim zoo.cfg
修改如下内容:
dataDir=/opt/module/zookeeper 3.5.7 /zkData
3) 在 /opt/module/zookeeper-3.5.7/这个 目录上创建 zkData文件 夹
[atguigu@hadoop102 zookeeper 3.5.7 ]$ mkdir zkData

1)启动 Zookeeper
[atguigu@hadoop102 zookeeper 3.5.7 ]$ bin/zkServer.sh start
2)查看进程是否启动
[atguigu@hadoop102 zookeeper 3.5.7 ]$ jps
4020 Jps
4001 QuorumPeerMain
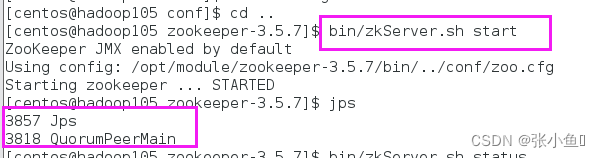
3)查看状态
[atguigu@hadoop102 zookeeper 3.5.7 ]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper 3.5.7 /bin/../conf/zoo.cfg
Mode: standalone

4)启动客户端
[atguigu@hadoop102 zookeeper 3.5.7 ]$ bin/zkCli.sh
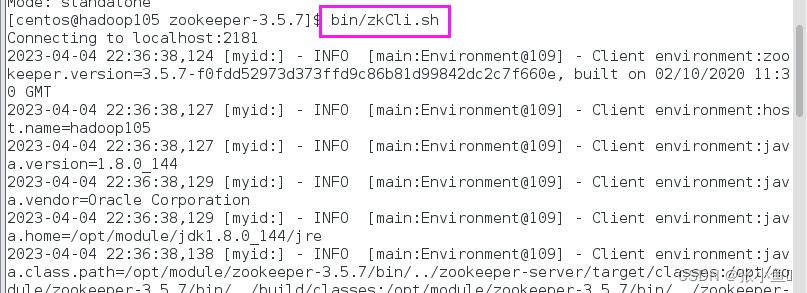
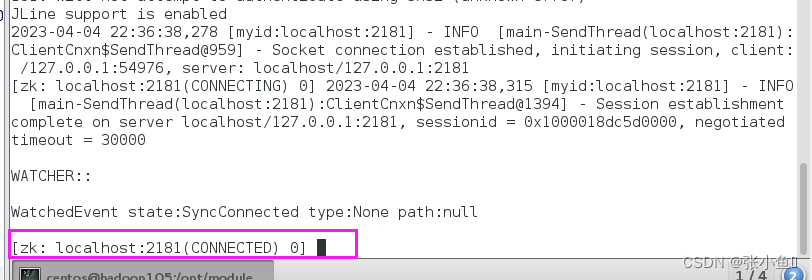
5)退出客户端
[zk: localhost:2181(CONNECTED) 0] quit
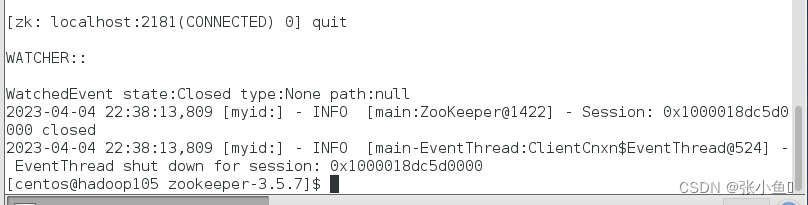
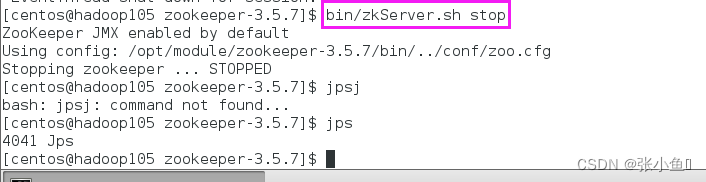
6)停止 Zookeeper
[atguigu@hadoop102 zookeeper 3.5.7 ]$ bin/zkServer.sh stop
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
1)tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
2)initLimit = 10:LF初始通信时限
Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量)

3)syncLimit = 5:LF同步通信时限
Leader和Follower之间通信时间如果超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
4)dataDir:保存Zookeeper中的数据
注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录。
5)clientPort = 2181:客户端连接端口,通常不做修改。
补充:Linux选择zookeeper老大的过程是依据上述来确定的
1)在 hadoop102解压 Zookeeper安装包到 /opt/module/目录下
[atguigu@hadoop102 software]$ tar zxvf apache zookeeper 3.5.7
bin.tar.gz C /opt/module/
2)修改 apache-zookeeper-3.5.7-bin名称为 zookeeper-3.5.7
[atguigu@hadoop102 module]$ mv apache zookeeper 3.5.7 bin/zookeeper 3.5.7
3)配置服务器编号
1)在 /opt/module/zookeeper-3.5.7/这个目录下创建 zkData
[atguigu@hadoop102 zookeeperzookeeper-3.5.73.5.7]$ mkdir zkData
2)在 /opt/module/zookeeper-3.5.7/zkData目录下创建一个目录下创建一个myid的文件的文件
[atguigu@hadoop102 [atguigu@hadoop102 zkDatazkData]$ vi myidvi myid
在文件中添加与在文件中添加与server对应的编号对应的编号(注意:上下不要有空行,左右不要有空格)
2
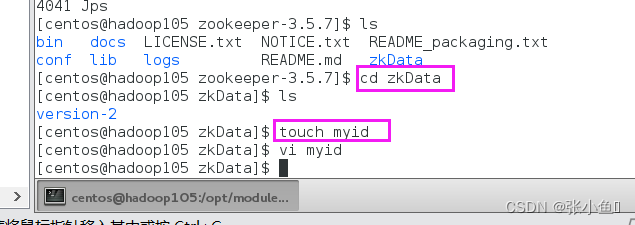
注意 :添加 myid文件,一定要在文件,一定要在Linux里面创建,在里面创建,在notepad++里面很可能乱码里面很可能乱码
3)拷贝配置好的)拷贝配置好的zookeeper到其他机器上到其他机器上
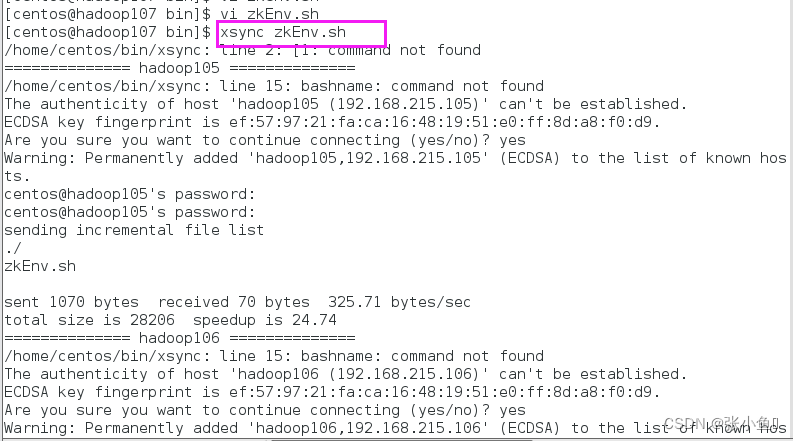
[atguigu@hadoop102 module ]$ xsync zookeeperzookeeper-3.5.7
并分别 在 hadoop103、hadoop104上修改 myid文件中内容为文件中内容为3、4
在此之前,记得切换到/opt/module/zookeeper-3.5.7/bin目录下,加入Java的路径,配置的时候三个都要配置
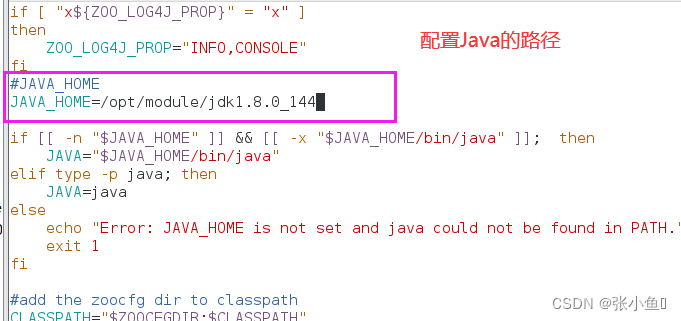
也可以配置i完一个之后分发一下
4)配置zoo.cfg文件
(1)重命名)重命名/opt/module/zookeeper-3.5.7/conf这个目录下的这个目录下的zoo_sample.cfg为 zoo.cfg
[atguigu@hadoop102 confconf]$ mv zoo_sample.cfg zoo.cfg
(2)打开 zoo.cfg文件
[atguigu@hadoop102 confconf]$ vim zoo.cfg
#修改 数据存储路径数据存储路径配置
dataDir=/opt/module/zookeeper zookeeper-3.5.7 /zkData
#增加如下配置增加如下配置
#######################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
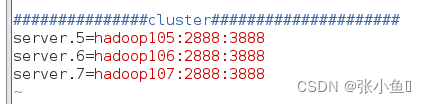
(3)配置参数解读)配置参数解读
server.A=B:C:D
A是一个数字,表示这个是第几号服务器;是一个数字,表示这个是第几号服务器;
集群 模式下配置一个文件模式下配置一个文件myid,这个文件在这个文件在dataDir目录 下,这个文件里面有一个数据下,这个文件里面有一个数据就是 A的值,的值,Zookeeper启动时读取此文件,拿到里面启动时读取此文件,拿到里面的数据与数据与zoo.cfg里面 的配置信息比的配置信息比较从而判断到底是哪个较从而判断到底是哪个server。
B是这个服务器的地址;是这个服务器的地址;
C是这个服务器是这个服务器Follower与集群中的与集群中的Leader服务器交换信息的端口;服务器交换信息的端口;
D是万一集群中的万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。,而这个端口就是用来执行选举时服务器相互通信的端口。
(4)同步 zoo.cfg配置文件配置文件
[atguigu@hadoop102 conf]$ xsync zoo.cfg
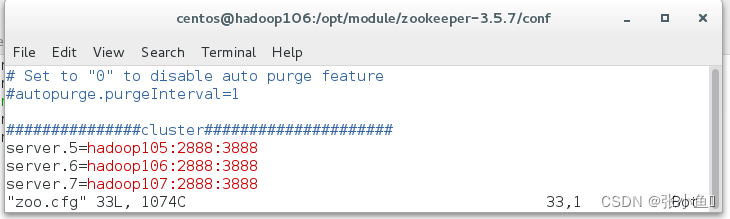
可以看到106结点有了刚才在105做的配置文件
5)集群操作
1)分别启动)分别启动Zookeeper
[atguigu @hadoop102 zookeeper zookeeper-3.5.73.5.7]$ bin/zkServer.sh start
[atguigu@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start
[atguigu@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start
2)查看状态
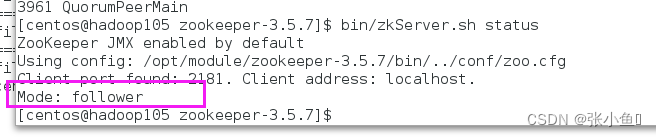
[atguigu@hadoop102 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: follower
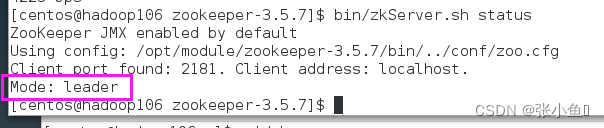
[atguigu@hadoop103 zookeeper-3.5.7]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: leader
[atguigu@hadoop104 zookeeper-3.4.5]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Mode: follower
三个节点的分布情况

1)在bin目录下配置脚本
创建一个zk.sh文件并且写入相关的配置
[atguigu@hadoop102 bin]$ vim zk.sh
2)写入内容
ps:此处小编的是105、106、107结点,具体操作时将对应的位置配置好就好了
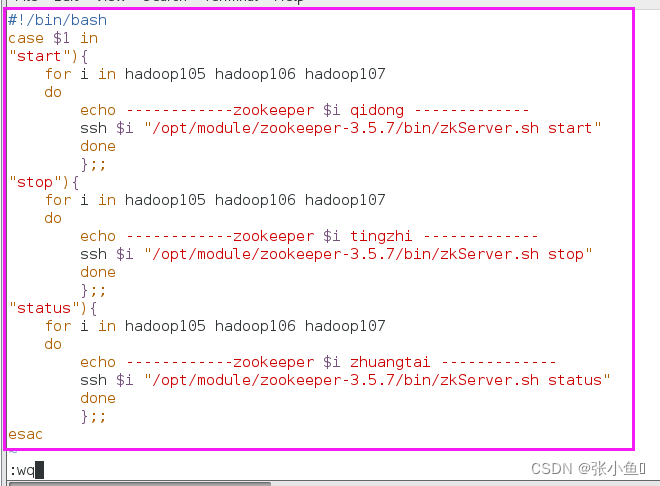
按esc保存退出
:wq
2)增加脚本执行 权限
chomd u+x zk.sh或者chomd 777 zk.sh【两者任选其一】
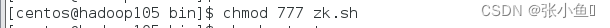
3 )Zookeeper集群 启动脚本
[atguigu@hadoop102 module]$ zk.sh start
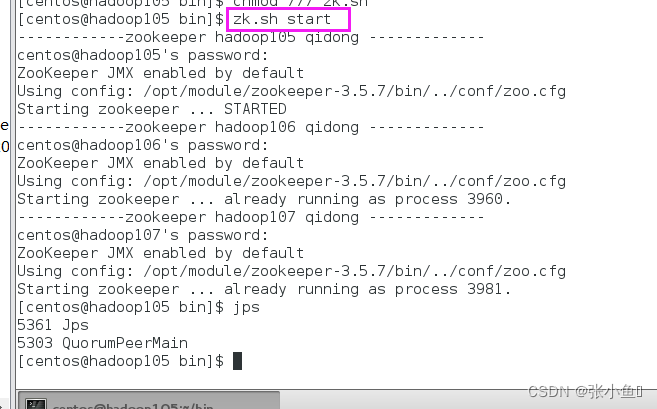
查看其他两个结点


4) Zookeeper集群 停止脚本
[atguigu@hadoop102 module]$ zk.sh stop
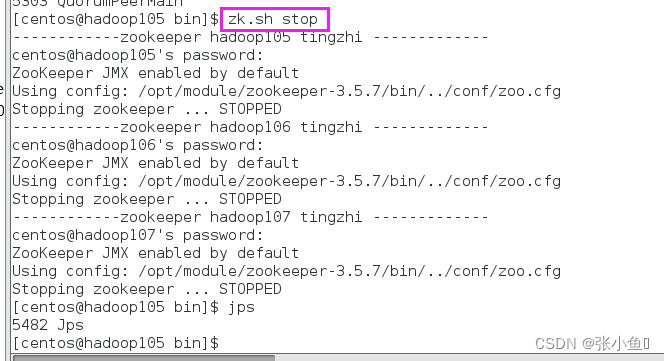
查看其他两个结点


至此zookeeper的集群配置就已经全部完成了
配置过程要书写正确的语句,以上就是今天的内容
最后欢迎大家点赞👍,收藏⭐,转发🚀,
如有问题、建议,请您在评论区留言💬哦。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m