MyBatis 内置了一个强大的事务性查询缓存机制,它可以非常方便地配置和定制。 为了使它更加强大而且易于配置,我们对 MyBatis 3 中的缓存实现进行了许多改进。
Mybatis的一级缓存(也叫本地缓存/Local Cache)是指SqlSession级别的,作用域是SqlSession。
Mybatis默认开启一级缓存,在同一个SqlSession中,相同的Sql查询的时候,第一次查询的时候,就会从缓存中取,如果发现没有数据,那么就从数据库查询出来,并且缓存到HashMap中,如果下次还是相同的查询,就直接从缓存中查询,就不在去查询数据库,对应的就不在去执行SQL语句。
当查询到的数据,进行增删改的操作的时候,缓存将会失效。在spring容器管理中每次查询都是创建一个新的sqlSession,所以在分布式环境中不会出现数据不一致的问题。
一级缓存原理图:
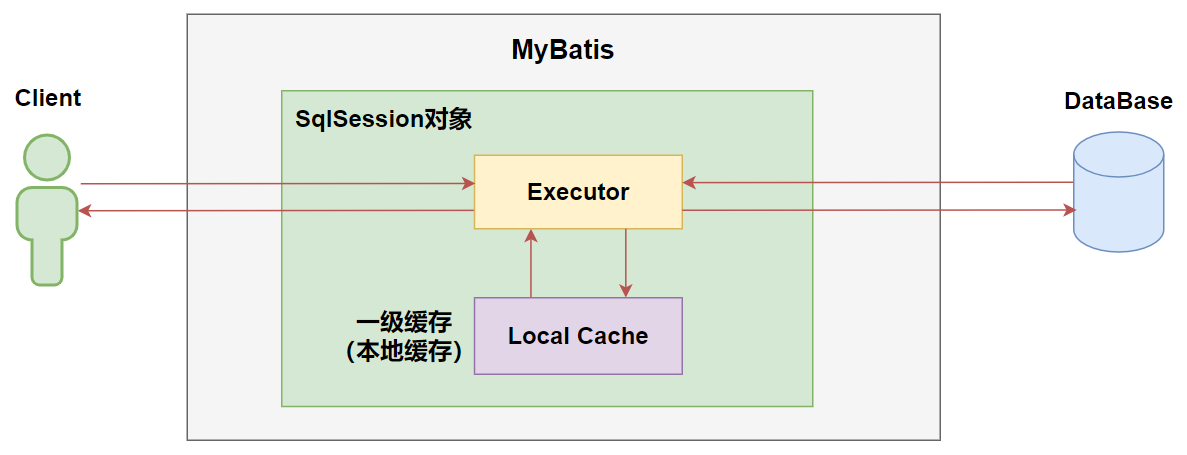
在参数和SQL完全一样的情况下,我们使用同一个SqlSession对象调用一个Mapper方法,往往只执行一次SQL,因为使用SelSession第一次查询后,MyBatis会将其放在缓存中,以后再查询的时候,如果没有声明需要刷新,并且缓存没有超时的情况下,SqlSession都会取出当前缓存的数据,而不会再次发送SQL到数据库。
每一次会话都对应自己的一级缓存,作用范围比较小,一旦会话关闭就查询不到了。
需求:当第一次查询id=1的Monster后,再次查询id=1的monster对象,就会直接从一级缓存获取,不会再次发出sql
(1)Monster实体类
package com.li.entity;
import java.util.Date;
/**
* @author 李
* @version 1.0
*/
public class Monster {
//属性和表的字段对应
private Integer id;
private Integer age;
private String name;
private String email;
private Date birthday;
private double salary;
private Integer gender;
//省略全参、无参构造器、setter、getter、toString方法
}
(2)MonsterMapper接口方法
//查询-根据id
public Monster getMonsterById(Integer id);
//查询所有的Monster
public List<Monster> findAllMonster();
(3)映射文件(部分)
<mapper namespace="com.li.mapper.MonsterMapper">
<!--配置getMonsterById方法-->
<select id="getMonsterById" resultType="Monster">
SELECT * FROM `monster` WHERE id=#{id};
</select>
<!--实现findAllMonster方法-->
<select id="findAllMonster" resultType="Monster">
SELECT * FROM `monster`;
</select>
</mapper>
(4)测试(部分代码)
//测试一级缓存
@Test
public void level1CacheTest() {
System.out.println("==========第一次查询=========");
Monster monster = monsterMapper.getMonsterById(10);
System.out.println("monster=" + monster);
System.out.println("==========第二次查询=========");
Monster monster2 = monsterMapper.getMonsterById(10);
System.out.println("monster=" + monster2);
//关闭sqlSession会话
if (sqlSession != null) {
sqlSession.close();
}
}
一级缓存默认打开,在同一个会话中,当重复查询时,不会再发出sql语句,而是从一级缓存中直接获取数据:
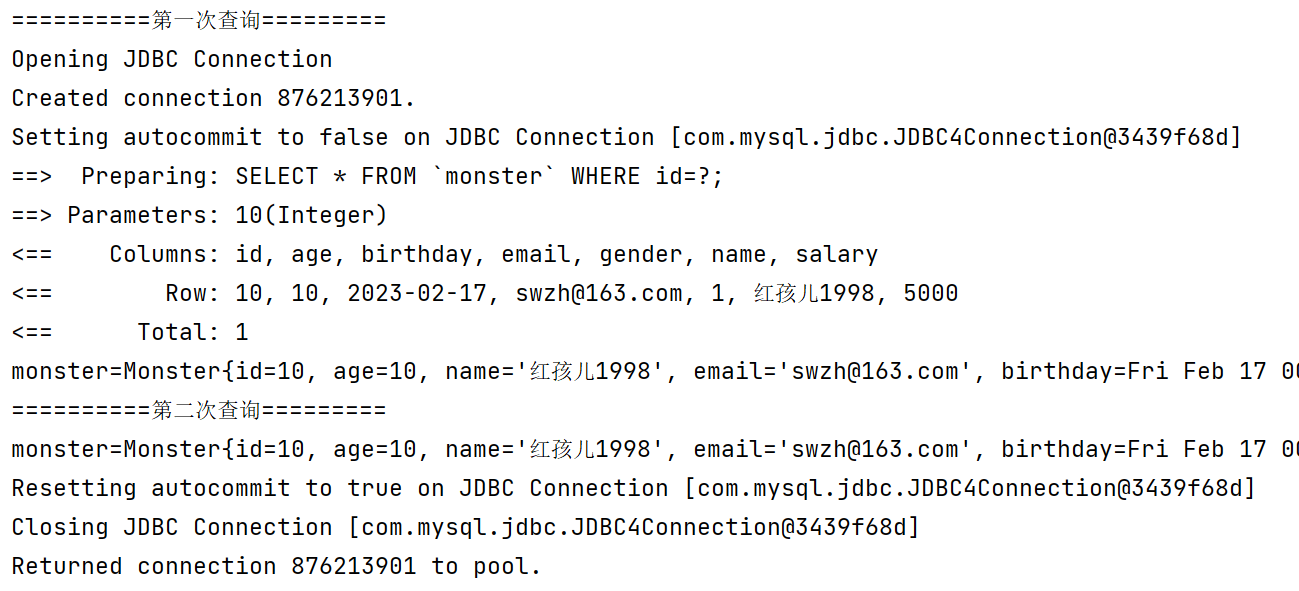
注意是重复查询,如果是不同的查询操作还是会向数据库发出sql
一级缓存到底是什么?
我们通过查看SqlSession的结构可以看出,一级缓存就是一个HashMap,缓存其实就是一个本地存放的map对象,每一个SqlSession都会存放一个map对应的引用。
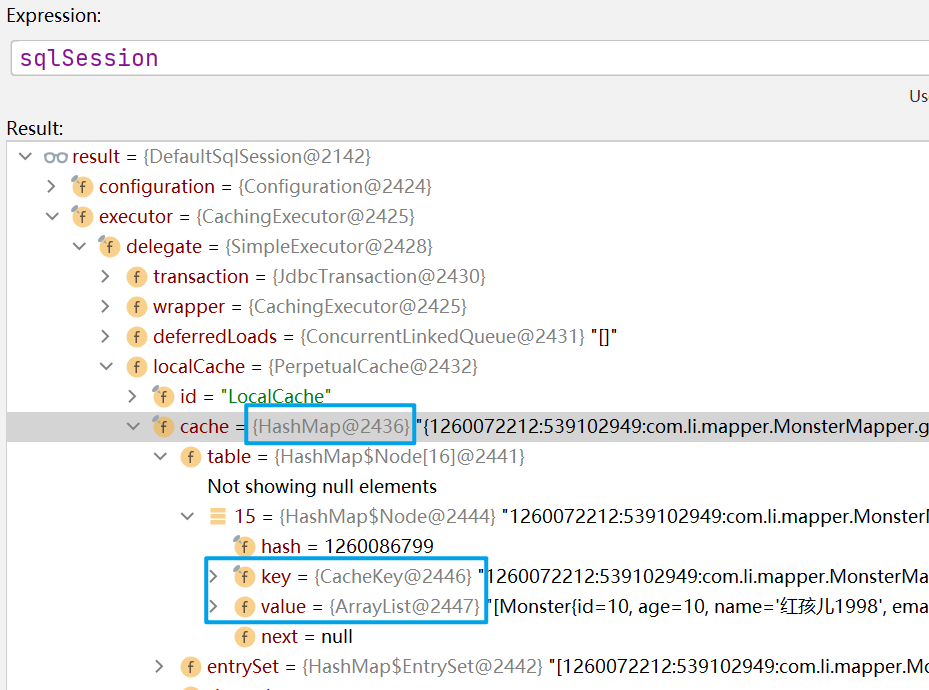
我们知道,一级缓存是和SqlSession会话关联的,一旦SqlSession关闭了,一级缓存就会失效。测试如下:
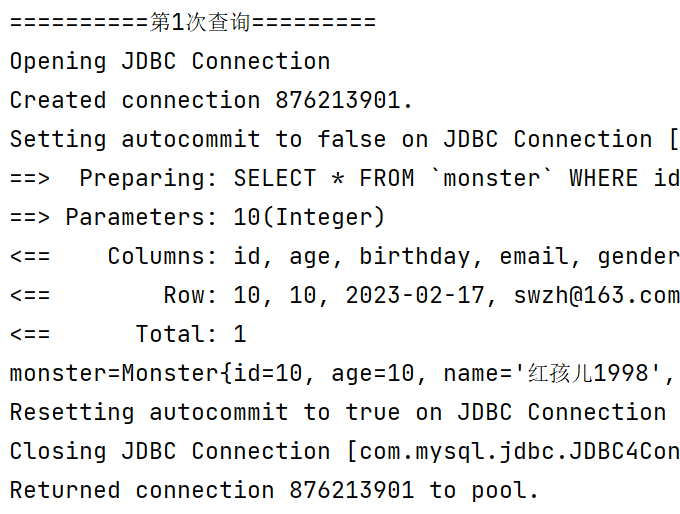
//测试一级缓存失效
@Test
public void level1CacheTest2() {
System.out.println("==========第1次查询=========");
Monster monster = monsterMapper.getMonsterById(10);
System.out.println("monster=" + monster);
//关闭sqlSession,一级缓存失效
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("==========第2次查询=========");
sqlSession = MybatisUtils.getSqlSession();//重新获取SqlSession对象
monsterMapper = sqlSession.getMapper(MonsterMapper.class);//重新初始化
Monster monster2 = monsterMapper.getMonsterById(10);
System.out.println("monster2=" + monster2);
if (this.sqlSession != null) {
this.sqlSession.close();
}
}
结果:可以看到两次查询都发出了sql操作,说明如果SqlSession会话关闭了,第二次查询依然回到数据库查询,一级缓存失效。
当执行sqlSession.clearCache()时(手动清理缓存),一级缓存失效。
clearCache()方法底层执行如下:
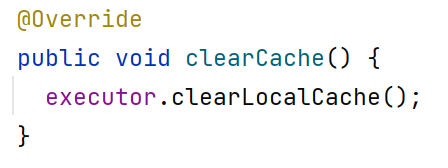
测试方法如下:
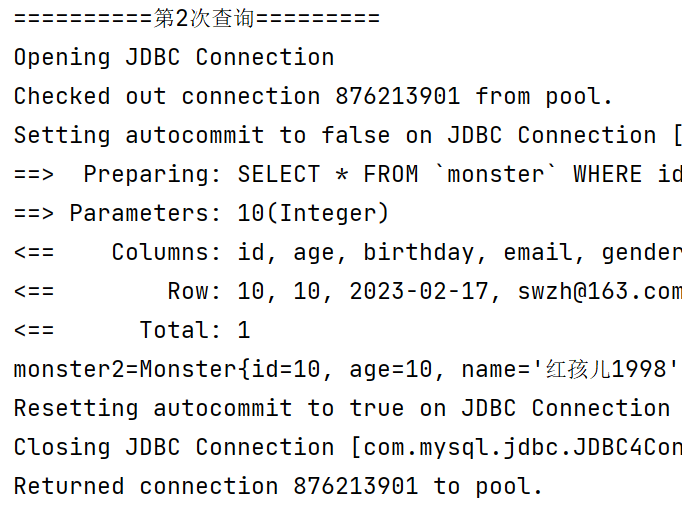
//测试一级缓存失效
@Test
public void level1CacheTest3() {
System.out.println("==========第1次查询=========");
Monster monster = monsterMapper.getMonsterById(10);
System.out.println("monster=" + monster);
//手动清理缓存,也会导致一级缓存失效
sqlSession.clearCache();
System.out.println("==========第2次查询=========");
Monster monster2 = monsterMapper.getMonsterById(10);
System.out.println("monster2=" + monster2);
if (this.sqlSession != null) {
this.sqlSession.close();
}
}
测试结果如下,查询操作相同,且在同一个SqlSession会话内,但底层仍然到数据库执行了两次相同操作,这说明当手动清理缓存后,一级缓存也会失效。
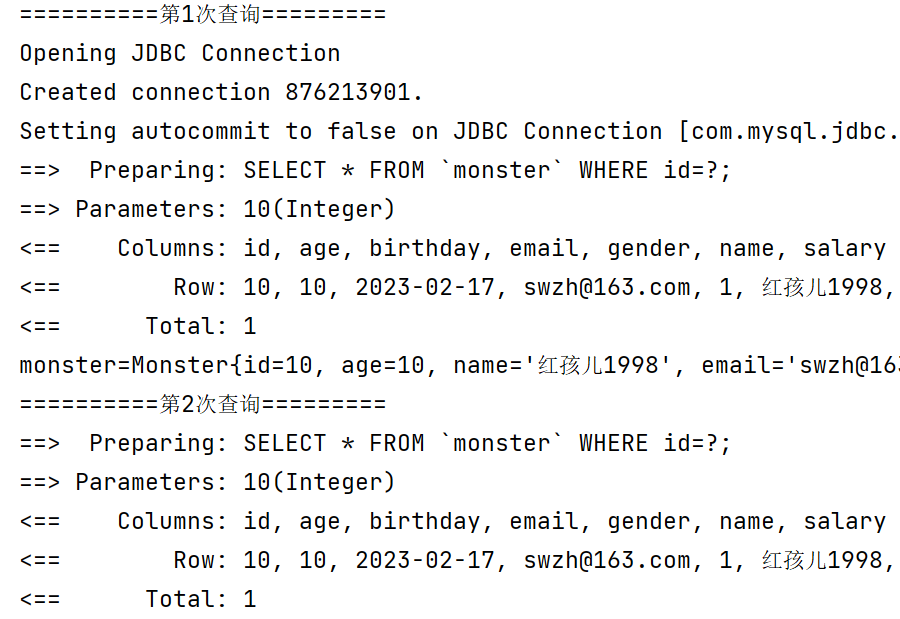
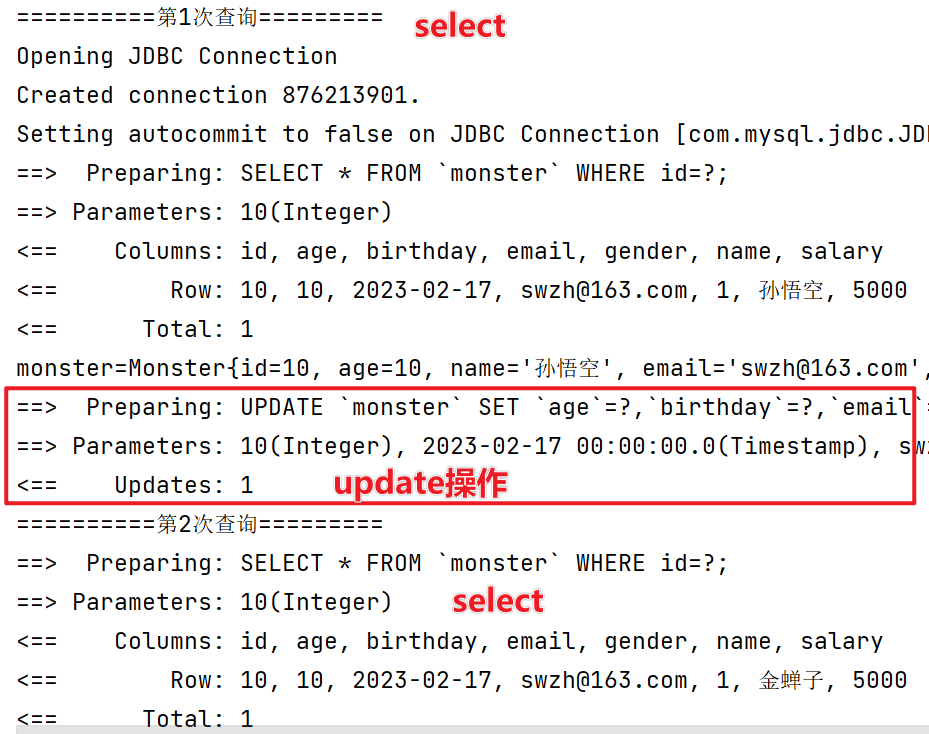
在两次相同的查询中间进行update操作,是否会对一级缓存产生影响?
//如果被查询的数据进行了增删改操作,会导致一级缓存数据失效
@Test
public void level1CacheTest4() {
System.out.println("==========第1次查询=========");
Monster monster = monsterMapper.getMonsterById(10);
System.out.println("monster=" + monster);
//对要查询的数据id=10进行update操作
monster.setName("金蝉子");
monsterMapper.updateMonster(monster);
System.out.println("==========第2次查询=========");
Monster monster2 = monsterMapper.getMonsterById(10);
System.out.println("monster2=" + monster2);
if (sqlSession != null) {
sqlSession.commit();//注意提交事务
sqlSession.close();
}
}
如下,在两次相同查询操作之间进行update操作,一级缓存同样失效了,因为第二次查询操作仍然向数据库发出sql语句。
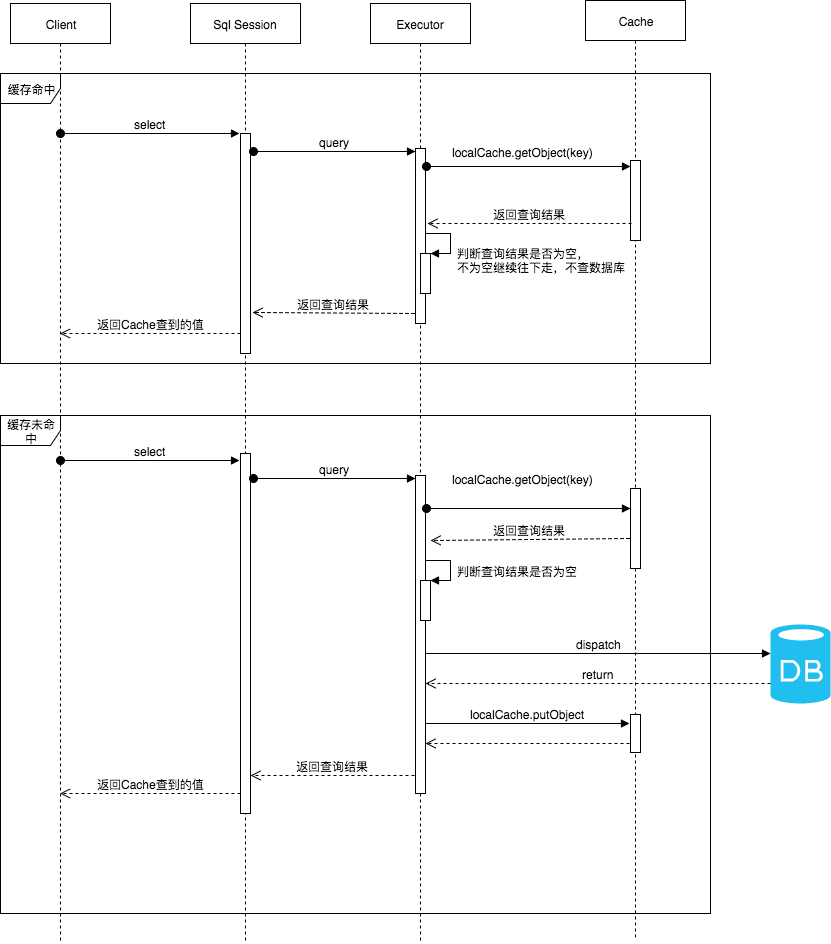
二级缓存原理图:
开启二级缓存后,会使用CachingExecutor装饰Executor,进入一级缓存的查询流程前,先在CachingExecutor进行二级缓存的查询,具体的工作流程如下所示。
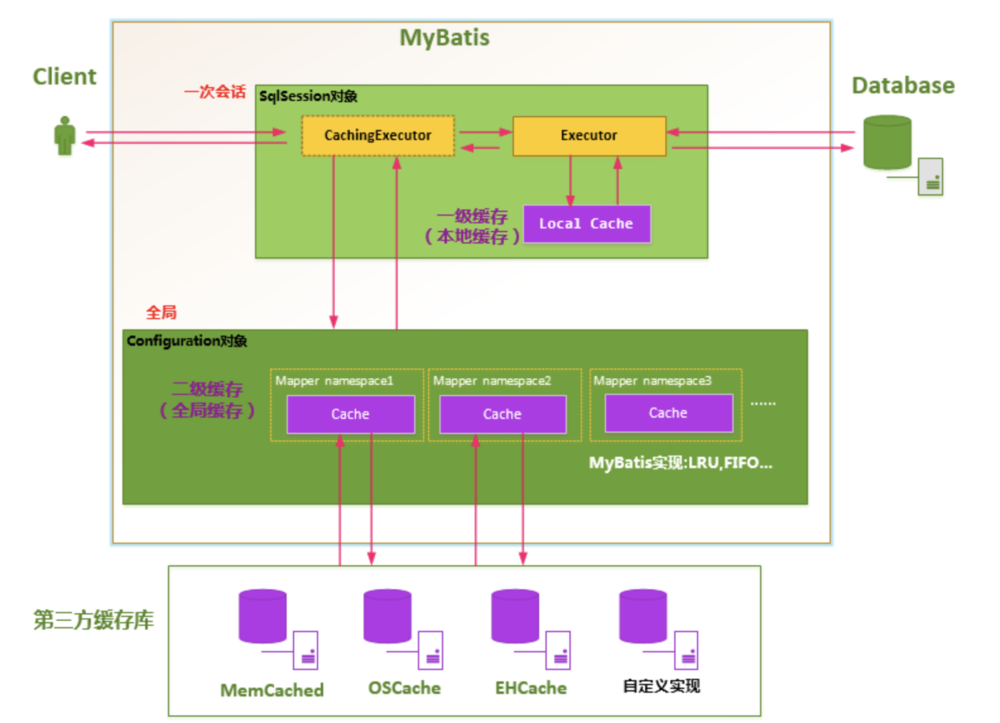
二级缓存开启后,同一个namespace下的所有操作语句,都影响着同一个Cache,即二级缓存被多个SqlSession共享,是一个全局的变量。当开启缓存后,数据的查询执行的流程就是 二级缓存 -> 一级缓存 -> 数据库。
(1)mybatis-config.xml配置中开启二级缓存
| 设置名 | 描述 | 有效值 | 默认值 |
|---|---|---|---|
| cacheEnabled | 全局性开启或关闭所有映射器配置文件中已配置的任何缓存 | true、false | true |
<settings>
<!--开启二级缓存,默认下值为true-->
<setting name="cacheEnabled" value="true"/>
</settings>
(2)使用二级缓存时entity类实现序列化接口(serializable),因为二级缓存可能使用到序列化技术
大部分情况下,二级缓存不去置序列化也可以使用,只是有些二级缓存产品可能用到序列化

(3)在对应的xxMapper.xml中设置二级缓存的策略
<!--配置二级缓存
FIFO:先进先出,按对象进入缓存的顺序来移除它们
flushInterval:刷新间隔为60000ms,即60s
size:存储结果对象或列表的 512 个引用,默认为1024
readOnly:只读属性,如果只用于读操作,建议设置成true,如果有修改操作,则设置为false(默认)
-->
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
(4)测试
//测试二级缓存
@Test
public void level2CacheTest() {
System.out.println("==========第一次查询=========");
Monster monster = monsterMapper.getMonsterById(5);
System.out.println("monster=" + monster);
//关闭这个会话
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("==========第二次查询=========");
//获取新的sqlSession会话
sqlSession = MybatisUtils.getSqlSession();
monsterMapper = sqlSession.getMapper(MonsterMapper.class);
Monster monster2 = monsterMapper.getMonsterById(5);
System.out.println("monster=" + monster2);
if (this.sqlSession != null) {
this.sqlSession.close();
}
}
测试结果:二级缓存的作用域是全局范围,因此不同的sqlSession会话都有效
二级缓存命中率 = 缓存生效的次数 / 总查询的次数
要启用全局的二级缓存,只需要在你的 SQL 映射文件中添加一行:
<cache/>
可以通过 cache 元素的属性来修改你的策略。比如:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
配置创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突。
eviction:缓存的回收策略。
flushInterval(刷新间隔)属性为任意的正整数,设置的值应该是一个以毫秒为单位时间。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。
size(引用数目)属性为任意正整数,欲缓存对象的大小和运行环境中可用的内存资源有关。默认值为 1024。
readOnly(只读)属性可以为 true 或 false。只读缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改,从而使性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
LRU – 最近最少使用:移除最长时间不被使用的对象。(默认策略)FIFO – 先进先出:按对象进入缓存的顺序来移除它们。SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。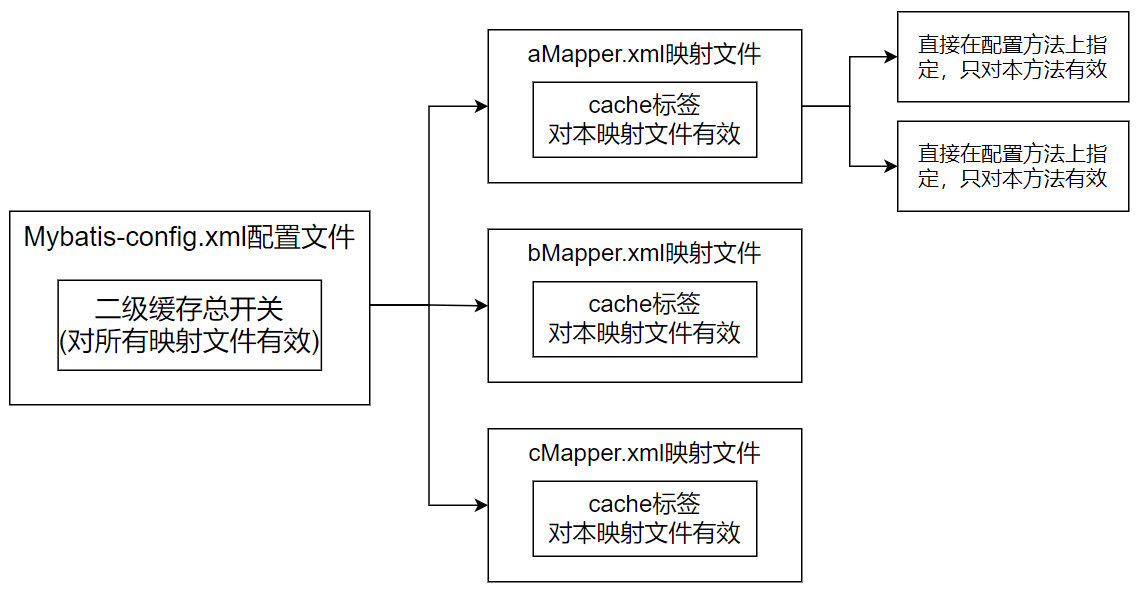
(1)在mybatis-config.xml文件的settings标签中设置二级缓存的开关。
注意这里的配置只是和二级缓存有关,和一级缓存无关
<settings>
<!--全局性开启或关闭所有映射器配置文件中已经配置的任何缓存,可以理解为二级缓存的总开关,默认为true-->
<setting name="cacheEnabled" value="false"/>
</settings>
(2)二级缓存的设置不仅要在配置文件中设置,还要在对应的映射文件中配置才有效。因此如果要禁用二级缓存,也可以在对应的映射文件中注销cache元素,这时候二级缓存对该映射文件无效。
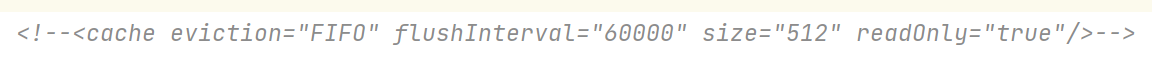
(3)或者使用控制力度更加精确的方法,直接在配置方法上指定
设置useCache="false"可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况为true

注意:一般不用去修改,使用默认的即可
insert,update,delete 操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读:

默认情况下 flushCache 的值为true,一般不用修改。
缓存的执行顺序为:二级缓存-->一级缓存-->数据库
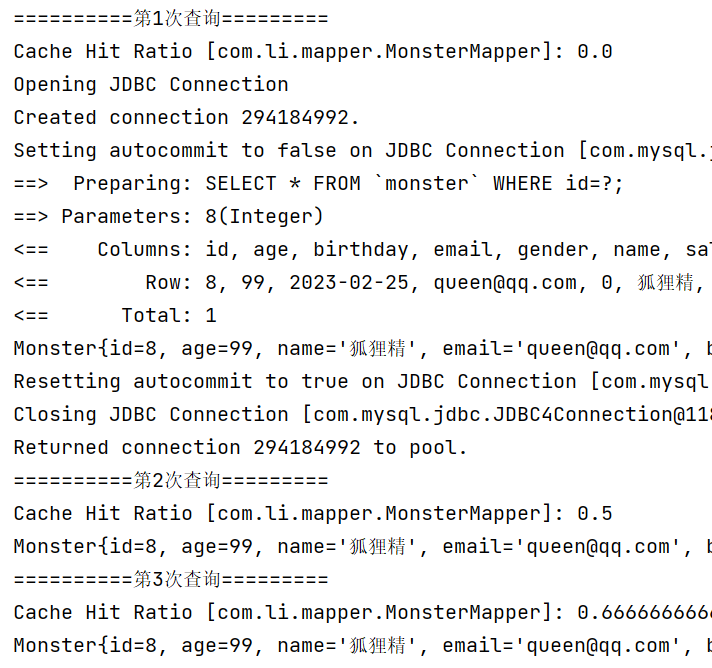
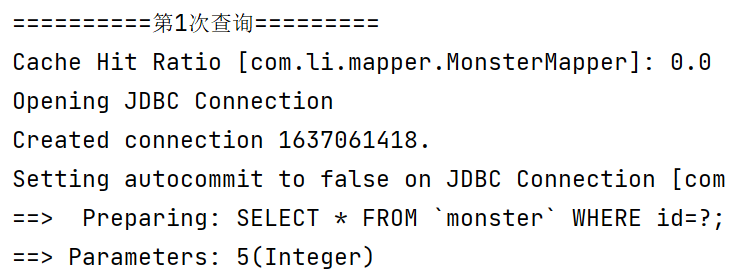
测试:验证缓存的执行顺序,我们事先打开二级缓存和一级缓存。
//二级缓存->一级缓存->数据库
@Test
public void cacheSeqTest() {
System.out.println("==========第1次查询=========");
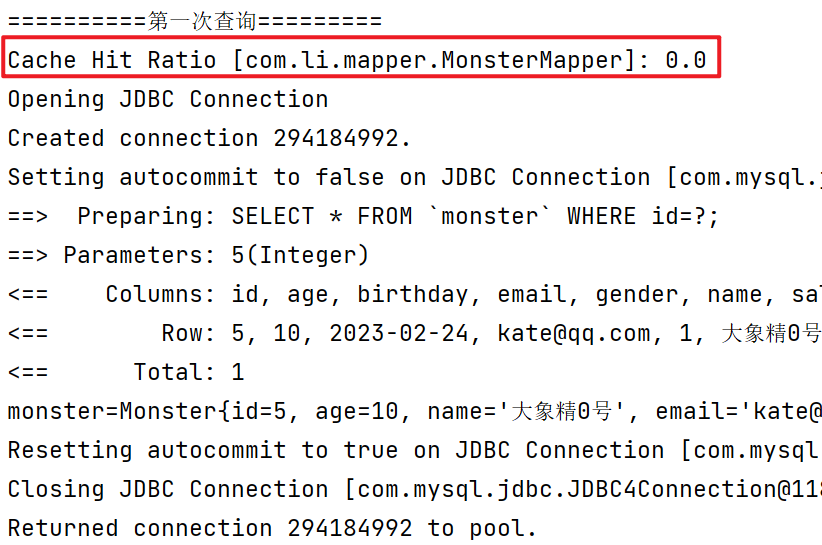
//Cache Hit Ratio: 0.0
Monster monster = monsterMapper.getMonsterById(8);
System.out.println(monster);
//当一级缓存的会话被关闭时,一级缓存的数据就会被放入二级缓存,前提是二级缓存是开启的
sqlSession.close();
sqlSession = MybatisUtils.getSqlSession();
monsterMapper = sqlSession.getMapper(MonsterMapper.class);
System.out.println("==========第2次查询=========");
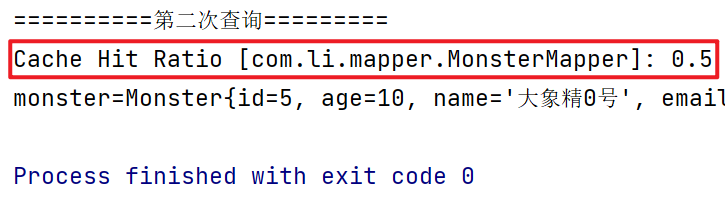
//从二级缓存获取 id=8 的 monster信息
//Cache Hit Ratio: 0.5
Monster monster2 = monsterMapper.getMonsterById(8);
System.out.println(monster2);
System.out.println("==========第3次查询=========");
//这时一二级缓存都有数据,但是由于先查询二级缓存,因此数据依然是从二级缓存中获取的
//Cache Hit Ratio: 0.6666666666666666
Monster monster3 = monsterMapper.getMonsterById(8);
System.out.println(monster3);
sqlSession.close();
}
注意事项:
不会出现一级缓存和二级缓存中有同一个数据,因为二级缓存的数据是在一级缓存关闭之后才有的。(当一级缓存的会话被关闭时,如果二级缓存开启了,一级缓存的数据就会被放入二级缓存)
//分析执行顺序,二级缓存的数据是在一级缓存被关闭之后才有的,不会出现一二级缓存同时拥有相同数据的情况
@Test
public void cacheSeqTest2() {
System.out.println("==========第1次查询=========");
//二级缓存命中率 Cache Hit Ratio: 0.0,走数据库
Monster monster = monsterMapper.getMonsterById(8);
System.out.println(monster);
System.out.println("==========第2次查询=========");
//Cache Hit Ratio: 0.0
//拿的是一级缓存的数据,不会发出sql
Monster monster2 = monsterMapper.getMonsterById(8);
System.out.println(monster2);
System.out.println("==========第3次查询=========");
//Cache Hit Ratio: 0.0
//拿的是一级缓存的数据,不会发出sql
Monster monster3 = monsterMapper.getMonsterById(8);
System.out.println(monster3);
if (sqlSession != null) {
sqlSession.close();
}
}
(1)加入相关依赖,修改pom.xml文件
<dependencies>
<!--引入EhCache核心库-->
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache-core</artifactId>
<version>2.6.11</version>
</dependency>
<!--引入需要使用的slf4j-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<!--引入mybatis整合ehcache库-->
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-ehcache</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
(2)确保mybatis-config.xml文件打开了二级缓存
<settings>
<!--不配置也可以,因为二级缓存默认是打开的-->
<setting name="cacheEnabled" value="true"/>
</settings>
(3)在resource目录下加入ehcache.xml 配置文件
Java Ehcache缓存的timeToIdleSeconds和timeToLiveSeconds区别 - TaoBye
<?xml version="1.0" encoding="UTF-8"?>
<ehcache>
<!--diskStore:为缓存路径,ehcache分为内存和磁盘两级,此属性定义磁盘的缓存位置。参数解释如下:
user.home – 用户主目录
user.dir – 用户当前工作目录
java.io.tmpdir – 默认临时文件路径 -->
<diskStore path="java.io.tmpdir/Tmp_EhCache"/>
<!--defaultCache:默认缓存策略,当ehcache找不到定义的缓存时,使用这个缓存策略。只能定义一个-->
<!--name:缓存名称。
maxElementsInMemory:缓存最大数目
maxElementsOnDisk:硬盘最大缓存个数。
eternal:对象是否永久有效,一但设置了,timeout将不起作用。
overflowToDisk:是否保存到磁盘,当系统宕机时
timeToIdleSeconds:设置对象在失效前的允许闲置时间(单位:秒)。仅当eternal=false对象不是永久有效时使用,可选属性,默认值是0,也就是可闲置时间无穷大。
timeToLiveSeconds:设置对象在失效前允许存活时间(单位:秒)。最大时间介于创建时间和失效时间之间。仅当eternal=false对象不是永久有效时使用,默认是0,也就是对象存活时间无穷大。
diskPersistent:是否缓存虚拟机重启期数据 Whether the disk store persists between restarts of the Virtual Machine. The default value is false.
diskSpoolBufferSizeMB:这个参数设置DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区。
diskExpiryThreadIntervalSeconds:磁盘失效线程运行时间间隔,默认是120秒。
memoryStoreEvictionPolicy:当达到maxElementsInMemory限制时,Ehcache将会根据指定的策略去清理内存。默认策略是LRU(最近最少使用)。你可以设置为FIFO(先进先出)或是LFU(较少使用)。
clearOnFlush:内存数量最大时是否清除。
memoryStoreEvictionPolicy:可选策略有:LRU(最近最少使用,默认策略)、FIFO(先进先出)、LFU(最少访问次数)。
FIFO,first in first out,这个是大家最熟的,先进先出。
LFU, Less Frequently Used,就是上面例子中使用的策略,直白一点就是讲一直以来最少被使用的。如上面所讲,缓存的元素有一个hit属性,hit值最小的将会被清出缓存。
LRU,Least Recently Used,最近最少使用的,缓存的元素有一个时间戳,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的元素将被清出缓存。-->
<defaultCache
eternal="false"
maxElementsInMemory="10000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="259200"
memoryStoreEvictionPolicy="LRU"/>
</ehcache>
(4)在XxxMapper.xml中启用了EhCace,当然原来Mybatis自带的缓存配置需要注销
<!--启用ehcache-->
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
(5)测试
//测试二级缓存
@Test
public void ehCacheTest() {
System.out.println("==========第1次查询=========");
Monster monster = monsterMapper.getMonsterById(5);
System.out.println("monster=" + monster);
//关闭当前会话,一级缓存数据失效,将数据放入二级缓存(此时为 ehcache)
if (sqlSession != null) {
sqlSession.close();
}
//获取新的sqlSession会话
sqlSession = MybatisUtils.getSqlSession();
monsterMapper = sqlSession.getMapper(MonsterMapper.class);
System.out.println("==========第2次查询=========");
//从二级缓存ehcache中获取数据,不会发出sql
Monster monster2 = monsterMapper.getMonsterById(5);
System.out.println("monster=" + monster2);
System.out.println("==========第3次查询=========");
//还是从二级缓存获取数据,不会发出sql
Monster monster3 = monsterMapper.getMonsterById(5);
System.out.println("monster=" + monster3);
if (this.sqlSession != null) {
this.sqlSession.close();
}
}

如何理解EhCache和Mybatis缓存的关系?
MyBatis提供了一个Cache接口,只要实现了该Cache接口,就可以作为二级缓存产品和MyBatis整合使用,EhCache就是实现了该接口。
MyBatis默认情况(即一级缓存)是使用的PerpetualCache类实现Cache接口的,是核心类
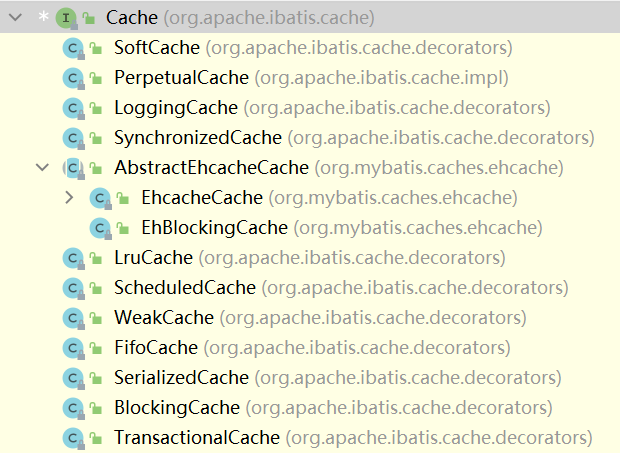
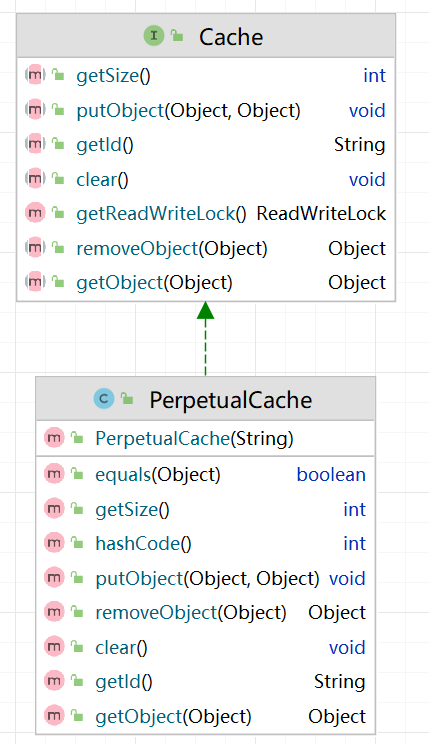
当我们使用了EhCache后,就是EhcacheCache类实现Cache接口,它是核心类
缓存的本质就是 Map<Object,Object>

我试过重新启动apache,缓存的页面仍然出现,所以一定有一个文件夹在某个地方。我没有“公共(public)/缓存”,那么我还应该查看哪些其他地方?是否有一个URL标志也可以触发此效果? 最佳答案 您需要触摸一个文件才能清除phusion,例如:touch/webapps/mycook/tmp/restart.txt参见docs 关于ruby-如何在Ubuntu中清除RubyPhusionPassenger的缓存?,我们在StackOverflow上找到一个类似的问题:
尝试在我的RoR应用程序中实现计数器缓存列时出现错误Unknownkey(s):counter_cache。我在这个问题中实现了模型关联:Modelassociationquestion这是我的迁移:classAddVideoVotesCountToVideos0Video.reset_column_informationVideo.find(:all).eachdo|p|p.update_attributes:videos_votes_count,p.video_votes.lengthendenddefself.downremove_column:videos,:video_vot
我有一个任务列表(名称、starts_at),我试图在每日View中显示它们(就像iCal)。deftodays_tasks(day)Task.find(:all,:conditions=>["starts_atbetween?and?",day.beginning,day.ending]end我不知道如何将Time.now(例如“2009-04-1210:00:00”)动态转换为一天的开始(和结束),以便进行比较。 最佳答案 deftodays_tasks(now=Time.now)Task.find(:all,:conditio
什么是0day漏洞?0day漏洞,是指已经被发现,但是还未被公开,同时官方还没有相关补丁的漏洞;通俗的讲,就是除了黑客,没人知道他的存在,其往往具有很大的突发性、破坏性、致命性。0day漏洞之所以称为0day,正是因为其补丁永远晚于攻击。所以攻击者利用0day漏洞攻击的成功率极高,往往可以达到目的并全身而退,而防守方却一无所知,只有在漏洞公布之后,才后知后觉,却为时已晚。“后知后觉、反应迟钝”就是当前安全防护面对0day攻击的真实写照!为了方便大家理解,中科三方为大家梳理当前安全防护模式下,一个漏洞从发现到解决的三个时间节点:T0:此时漏洞即0day漏洞,是已经被发现,还未被公开,官方还没有相
当我尝试进行bundle安装时,我的gem_path和gem_home指向/usr/local/rvm/gems/我没有写入权限,并且由于权限无效而失败。因此,我已将两个路径都更改为我具有写入权限的本地目录。这样做时,我进行了bundle安装,我得到:bruno@test6:~$bundleinstallFetchinggemmetadatafromhttps://rubygems.org/.........Fetchinggemmetadatafromhttps://rubygems.org/..Bundler::GemspecError:Couldnotreadgemat/afs/
我一直在Heroku上尝试不同的缓存策略,并添加了他们的memcached附加组件,目的是为我的应用程序添加Action缓存。但是,当我在我当前的应用程序上查看Rails.cache.stats时(安装了memcached并使用dalligem),在执行应该缓存的操作后,我得到current和total_items为0。在Controller的顶部,我想缓存我有的Action:caches_action:show此外,我修改了我的环境配置(对于在Heroku上运行的配置)config.cache_store=:dalli_store我是否可以查看其他一些统计数据,看看它是否有效或我做错
我有一个具有页面缓存的ControllerAction,我制作了一个清扫程序,它使用Controller和指定的Action调用expire_page...Controller操作呈现一个js.erb模板,所以我试图确保expire_page删除public/javascripts中的.js文件,但它没有这样做。classJavascriptsController"javascripts",:action=>"lol",:format=>'js')endend...所以,我访问javascripts/lol.js并呈现我的模板。我验证了public/javascripts/lol.js
ruby1.9.3dev(2011-09-23修订版33323)[i686-linux]轨道3.0.20最近为什么在与DateTimeonRails相关的RSpecs项目上工作我发现在给定日期以下语句发出的值date.end_of_day.to_datetime和date.to_datetime.end_of_day虽然它们表示相同的日期时间,但比较时返回false。为了确认这一点,我打开了Rails控制台并尝试了以下操作1.9.3dev:053>monday=Time.now.monday=>2013-02-2500:00:00+05301.9.3dev:054>monday.cla
我的Controller有这个:caches_action:render_ticker_for_channel,:expires_in=>30.seconds在我的路由文件中我有这个:match'/render_c_t/:channel_id'=>'render#render_ticker_for_channel',:as=>:render_channel_ticker在日志文件中我看到了这个:Writefragmentviews/mcr3.dev/render_c_t/63(11.6ms)我如何手动使它过期?我需要从与渲染Controller不同的Controller使它过期,但即使
我在开发和生产中都使用docker,真正困扰我的一件事是docker缓存的简单性。我的ruby应用程序需要bundleinstall来安装依赖项,因此我从以下Dockerfile开始:添加GemfileGemfile添加Gemfile.lockGemfile.lock运行bundleinstall--path/root/bundle所有依赖项都被缓存,并且在我添加新gem之前效果很好。即使我添加的gem只有0.5MB,从头开始安装所有应用程序gem仍然需要10-15分钟。由于依赖项文件夹的大小(大约300MB),然后再花10分钟来部署它。我在node_modules和npm上遇到了