文章目录
①流量
②内存
③一些主要的功能才做压力测试,比如同时注册,最大在线,战斗,地图移动,数据存取等。
④2个压力宏观数据保持不变:
a. 各接口的压力比例不变, 首先从同类型游戏或者本游戏内测阶段,日志插桩,收集各个接口的调用比例;然后,将接口比例转化为场景比例,如同时会有个2%完结登陆、15%玩家战斗、20%玩家拉取好友列表、10%玩家赌博(一个手游场景例子)。
b.玩家平均每分钟操作频率不变。同样在内测阶段收集玩家平均操作频率。
因此,压力测试目标就转变成了如何模拟符合ab数据的压力。
⑤服务器配置信息
1)CPU核数
2)内存
3)操作系统
4)带宽
5)网卡
6)硬盘

⑥其他指标
●吞吐量:固定时间间隔内的处理完毕事务个数。通常是1秒内处理完毕的请求个数,单位:事务/秒(tps)。
●平均吞吐量:一段时间内吞吐量的平均值。无法体现吞吐量的瞬间变化。
●峰值吞吐量:一段时间内吞吐量的最大值。是用来评估系统容量的重要指标之一。
●最低吞吐量:一段时间内吞吐量的最小值。如果最小值接近0,说明系统有“卡”的现象。
●70%的吞吐量集中区间:通过统计15%和85%的吞吐量边界值,计算出70%的吞吐量集中区间。区间越集中,吞吐量越稳定。
●响应时间:一次事务的处理时间。通常指从一个请求发出,到服务器进行处理后返回,再到接收完毕应答数据的时间间隔,单位:毫秒。
●平均响应时间:一段时间内响应时间的平均值。无法体现响应时间的波动情况。
●中间响应时间:一段时间内响应时间的中间值,50%响应时间,有一半的服务器响应时间低于该值而另一半高于该值。
●90%响应时间:一段时间内90%的事务响应时间比此数值要小。反应总体响应速度,和高于该值的10%超时率。是用来评估系统容量的重要指标之一。
●最小响应时间:响应时间的最小值。反映服务最快处理能力。
●最大响应时间:响应时间的最大值。反映服务器最慢处理能力。
●CPU占用率:1-CPU空闲率,表示CPU被使用情况,反映了系统资源利用情况。
可以看出从晚上8时到次日下午14时,各个服务器CPU变化区间是固定的。
这个同样是晚上8时到下午14时,随着机器人数量变化而生成的图表。
(内存处于一个区间段,说明程序没有内存泄漏。)
对于具体的内存,CPU所占的百分比,各个游戏之间对比是没有任何意义的,设计和数据的存储方式和存储结构都不相同,而这样的测试目的是在于了解 针对本款游戏在线玩家人数与服务器所占内存,CPU之间的一个关系,为了上线更好地控制每个服承载的最大人数做准备。
①百分之八十以上的开发成本消耗在正常的逻辑处理上,而百分之八十以上的性能消耗点在和视野有关的模块上。
移动包和技能包在CPU上的消耗占比之和在30%以上;战斗做的好的《天涯明月刀》在群战时,仅技能逻辑消耗就在50%以上;另一款腾讯在研MMORPG,因为有后台寻路、体素判定、行为树定义的复杂AI以及分段技能设计,CPU消耗比同类产品要高,统计如下:1)场景心跳 75.5%
2)战斗请求:11.3%
3)移动请求:3.8%
4)其他 : 6.6%
5)剩余客户端请求:2.8%
①消息驱动:
包含玩家上行协议的驱动和其他server的消息驱动,这部分的主要耗时来源时战斗请求包和移动请求包,战斗和移动占这部分80%的性能消耗
②定时器:
包含各大系统的心跳逻辑以及各个OBJ的心跳逻辑,在承载5000个玩家在线时,怪物和NPC往往要打到10W个之多,因此定时器的主要耗时来源是场景心跳(AI\CD检查\扫敌等),这部分占整个CPU耗时处理的75%左右。
③这两部分组成了灰色区域,累计占比高达百分之90%。共同点是有很少的跨场景操作,以及少量公共数据访问(比如邮件、帮会等)。而百分之10%是UI上的各种请求
①LuaJIT有2GB内存的限制(截至目前,官方的最新版本对64位支持是默认关闭的,不建议在release阶段使用),如果线程过多,有可能出现内存不够的情况。
②如果在移动、技能、AI的处理上没有过多使用Lua,那么建议还是使用LuaJIT保持效率。
③如果多线程逻辑过于依赖Lua,那么使用原生的Lua保持多线程的运行也是不错的选择
横轴代表现吞吐量,纵轴代表CPU压力。方法流程
,“录制”就是通过抓取数据包的方式,来获取游戏时的协议,比如用户登录游戏时抓取登录包;“回放”即把这些捕获的协议重新发送给服务端,这样理论上就可以通过工具放大协议量级达到性能测试的目的,比如将之前录制的登入协议扩大1w倍给服务器,这样就模拟了1w人同时登入的情况。
缺点
游戏的协议交互非常复杂,如果只是单纯的放大数据包,对于服务器是产生不了多大的压力的。这类方法比较适合固定输入输出服务类型的测试
并发性不受限制,从1W到10W,压力能够自主设置;可以反复执行,便于性能调优回归;
问题 1:top 输出的利用率信息是如何计算出来的,它精确吗?
问题 2:ni 这一列是 nice,它输出的是 cpu 在处理啥时的开销?
问题 3:wa 代表的是 io wait,那么这段时间中 cpu 到底是忙碌还是空闲?
ON_CPU火焰图查看CPU和内存占用前十的进程
ps aux|head -1;ps -aux | sort -k3nr | head -n 10 //查看前10个最占用CPU的进程
ps aux|head -1;ps -aux | sort -k4nr | head -n 10 //查看前10个最占用内存的进程
1、安装perf:我目前的服务器发行版是Ubuntu 16.04.6 LTS因此需要先安装perf才能使用,该工具由linux-tools-common提供,但是它需要安装后面的依赖。
#ubantu安装
root@master:~# apt install linux-tools-common linux-tools-4.4.0-142-generic linux-cloud-tools-4.4.0-142-generic -y
root@master:~# perf -v #显示perf的版本
perf version 4.4.167
#centos安装
yum install perf
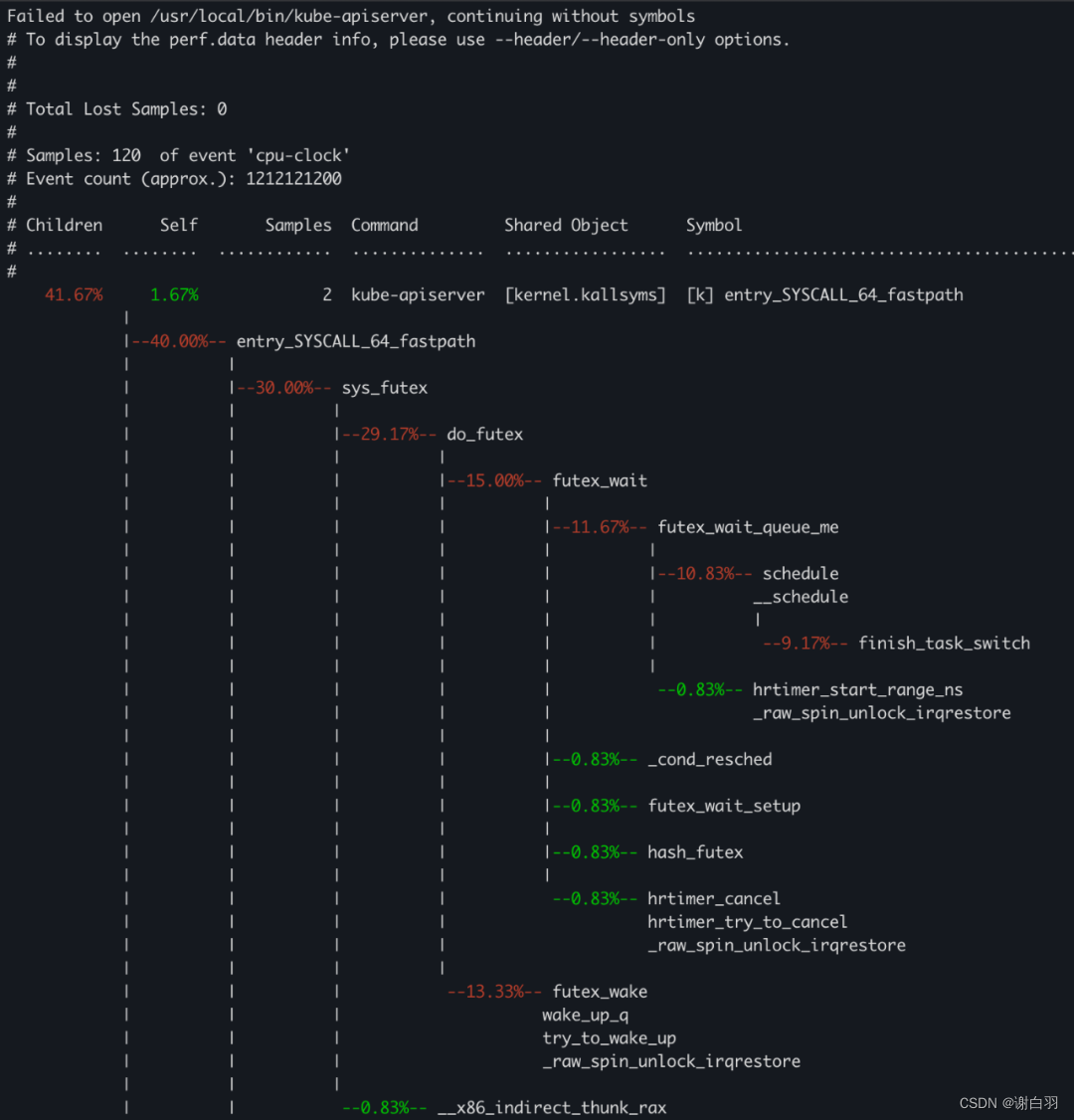
2、在安装完成时候,我们就可以对上图CPU使用率最高的进程ID为25633的进程进行采样分析。首选我们采集一下该进程的调用栈信息:
root@master:~# sudo perf record -F 99 -p 25633 -g -- sleep 30
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.039 MB perf.data (120 samples) ]
3、参数说明
这个命令会产生一个大的数据文件,取决与你采集的进程与CPU的配置,如果一台服务器有16个 CPU,每秒抽样99次,持续30秒,就得到 47,520 个调用栈,长达几十万甚至上百万行。生成的数据采集文件在当前目录下,名称为perf.data。
1)perf record表示记录,命令可以从高到低排列统计每个调用栈出现的百分比
2)-F 99表示每秒99次,
3)-p 25633是进程号,即对哪个进程进行分析,
4)-g表示记录调用栈,
5)sleep 30则是持续30秒
可以简单在linux下展示每个调用栈出现的百分比
root@master:~# sudo perf report -n --stdio
②解析数据:statckcollapse/pl(用perf script工具对perf.data进行解析,生成perf.unfold)
# perf script -i /root/perf.data &> /root/perf.unfold
或
perf script -i perf.data &> perf.unfold
用 stackcollapse-perf.pl 将 perf 解析出的内容 perf.unfold 中的符号进行折叠
#安装stackcollapse
git clone https://github.com/brendangregg/FlameGraph.git
#拷贝stackcollapse-perf.pl和flamegraph.pl到目标机器上。
chmod +x flamegraph.pl
chmod +x stackcollapse-perf.pl
# ./stackcollapse-perf.pl /root/perf.unfold &> /root/perf.folded //这里折叠堆栈
③生成火焰图: flamegraph.pi
./flamegraph.pl /root/perf.folded > /root/perf.svg
或
./flamegraph.pl perf.folded > perf.svg
浏览器打开。
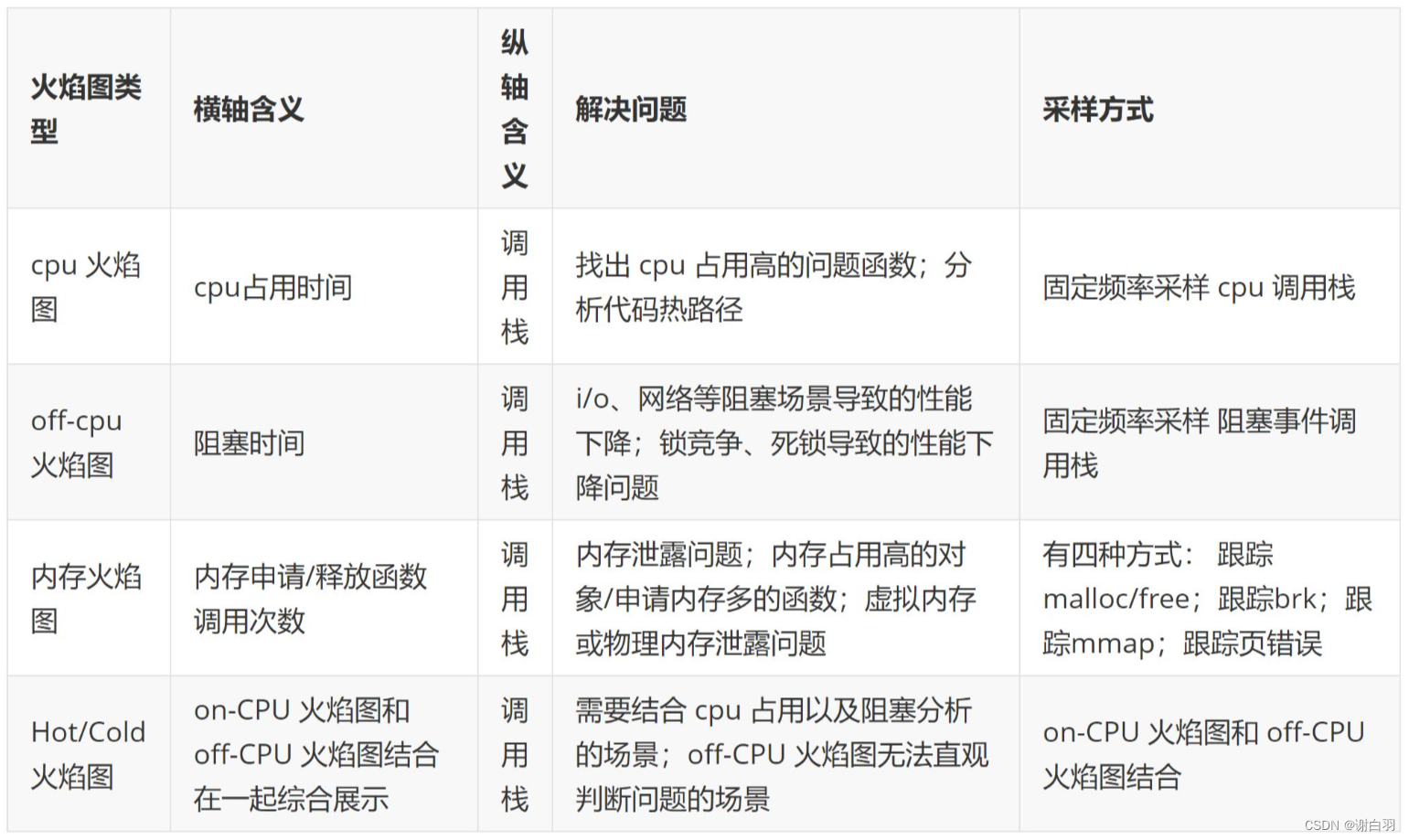
⑤OFF-CPU火焰图
⑥内存火焰图
⑦显示lua堆栈(chatgpt说的,我没试过)
参数意义
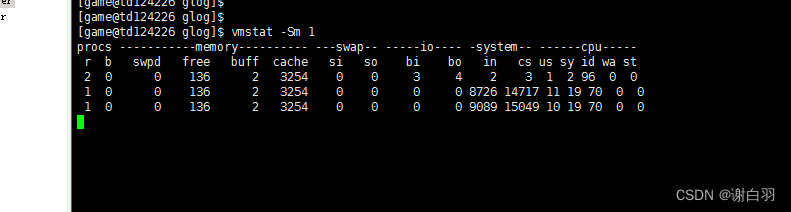
swpd 交换出的内存量
free 空闲的可用内存
buff 用于缓冲缓存的内存
cache 用于页缓存的内存
si 换入的内存(换页)
so 换出的内存(换页)
注释
若so和si一直为非0,说明有大量换页的操作,用top或ps可以看每个进程使用的内存
命令
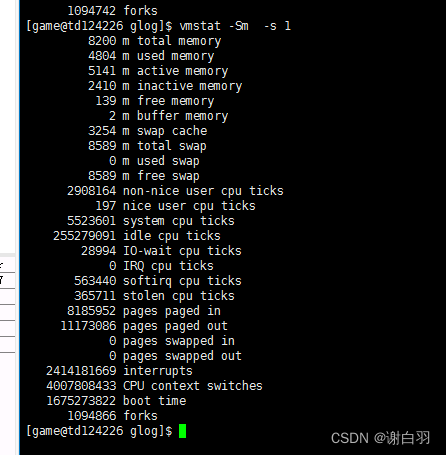
Usage:
vmstat [options] [delay [count]]
Options:
-a, --active active/inactive memory
-f, --forks number of forks since boot
-m, --slabs slabinfo
-n, --one-header do not redisplay header
-s, --stats event counter statistics 输出列表
-d, --disk disk statistics
-D, --disk-sum summarize disk statistics
-p, --partition <dev> partition specific statistics
-S, --unit <char> define display unit ### 单位,按照多少内存对齐k(1000),K(1024),m(1000000),M(1048576) bytes
-w, --wide wide output
-t, --timestamp show timestamp
-h, --help display this help and exit
-V, --version output version information and exit
For more details see vmstat(8).
root:# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
smmsp 3521 0.0 0.7 6556 1616 ? Ss 20:40 0:00 sendmail: Queue runner@01:00:00 f
root 3532 0.0 0.2 2428 452 ? Ss 20:40 0:00 gpm -m /dev/input/mice -t imps2
htt 3563 0.0 0.0 2956 196 ? Ss 20:41 0:00 /usr/sbin/htt -retryonerror 0
htt 3564 0.0 1.7 29460 3704 ? Sl 20:41 0:00 htt_server -nodaemon
root 3574 0.0 0.4 5236 992 ? Ss 20:41 0:00 crond
xfs 3617 0.0 1.3 13572 2804 ? Ss 20:41 0:00 xfs -droppriv -daemon
root 3627 0.0 0.2 3448 552 ? SNs 20:41 0:00 anacron -s
root 3636 0.0 0.1 2304 420 ? Ss 20:41 0:00 /usr/sbin/atd
dbus 3655 0.0 0.5 13840 1084 ? Ssl 20:41 0:00 dbus-daemon-1 --system
常用命令
-o表示按照什么标准排序
top -0 %MEM
top -o %CPU
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我正在尝试从Postgresql表(table1)中获取数据,该表由另一个相关表(property)的字段(table2)过滤。在纯SQL中,我会这样编写查询:SELECT*FROMtable1JOINtable2USING(table2_id)WHEREtable2.propertyLIKE'query%'这工作正常:scope:my_scope,->(query){includes(:table2).where("table2.property":query)}但我真正需要的是使用LIKE运算符进行过滤,而不是严格相等。然而,这是行不通的:scope:my_scope,->(que
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
1.在Python3中,下列关于数学运算结果正确的是:(B)a=10b=3print(a//b)print(a%b)print(a/b)A.3,3,3.3333...B.3,1,3.3333...C.3.3333...,3.3333...,3D.3.3333...,1,3.3333...解析: 在Python中,//表示地板除(向下取整),%表示取余,/表示除(Python2向下取整返回3)2.如下程序Python2会打印多少个数:(D)k=1000whilek>1: print(k)k=k/2A.1000 B.10C.11D.9解析: 按照题意每次循环K/2,直到K值小于等
require"socket"server="irc.rizon.net"port="6667"nick="RubyIRCBot"channel="#0x40"s=TCPSocket.open(server,port)s.print("USERTesting",0)s.print("NICK#{nick}",0)s.print("JOIN#{channel}",0)这个IRC机器人没有连接到IRC服务器,我做错了什么? 最佳答案 失败并显示此消息::irc.shakeababy.net461*USER:Notenoughparame
修改(澄清问题)我已经花了几天时间试图弄清楚如何从Facebook游戏中抓取特定信息;但是,我遇到了一堵又一堵砖墙。据我所知,主要问题如下。我可以使用Chrome的检查元素工具手动查找我需要的html-它似乎位于iframe中。但是,当我尝试抓取该iframe时,它是空的(属性除外):如果我使用浏览器的“查看页面源代码”工具,这与我看到的输出相同。我不明白为什么我看不到iframe中的数据。答案不是它是由AJAX之后添加的。(我知道这既是因为“查看页面源代码”可以读取Ajax添加的数据,也是因为我有b/c我一直等到我可以看到数据页面之后才抓取它,但它仍然不存在)。发生这种情况是因为
我有一个使用PDFKit呈现网页的pdf版本的Rails应用程序。我使用Thin作为开发服务器。问题是当我处于开发模式时。当我使用“bundleexecrailss”启动我的服务器并尝试呈现任何PDF时,整个过程会陷入僵局,因为当您呈现PDF时,会向服务器请求一些额外的资源,如图像和css,看起来只有一个线程.如何配置Rails开发服务器以运行多个工作线程?非常感谢。 最佳答案 我找到的最简单的解决方案是unicorn.geminstallunicorn创建一个unicorn.conf:worker_processes3然后使用它: