import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style = 'whitegrid')
# 加载 diamonds 数据集
diamonds = sns.load_dataset('diamonds')
diamonds.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
# 画出 点的大小 和 颜色 不同的高维散点图
f, ax = plt.subplots(figsize = (6.5, 6.5))
sns.despine(f, left = True, bottom = True)
clarity_ranking = ['I1', 'SI2', 'SI1', 'VS2', 'VS1', 'VVS2', 'VVS1', 'IF']
sns.scatterplot(
x = 'carat', y = 'price',
hue = 'clarity', size = 'depth',
palette = 'ch:r=-.2,d=.3_r',
hue_order = clarity_ranking,
sizes = (1, 8), linewidth = 0,
data = diamonds, ax = ax
) # hue: 色调,size: 大小
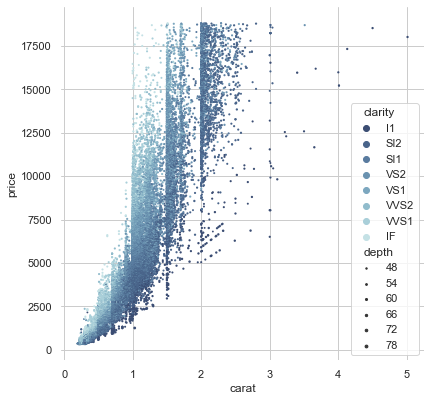
sns.scatterplot() 其他案例来自:https://seaborn.pydata.org/generated/seaborn.scatterplot.html#seaborn.scatterplot
注:seaborn 数据集下载地址 https://github.com/mwaskom/seaborn-data
## 导入数据集
import pandas as pd
tips = pd.read_csv("../../seaborn-data-master/tips.csv")
tips.head()
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
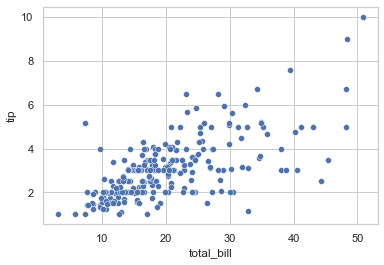
## 以 total_bill 为 x 轴,tip 为 y 轴,绘制散点图
sns.scatterplot(data = tips, x = 'total_bill', y = 'tip')
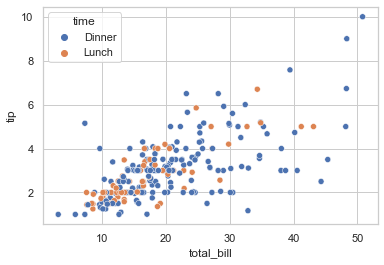
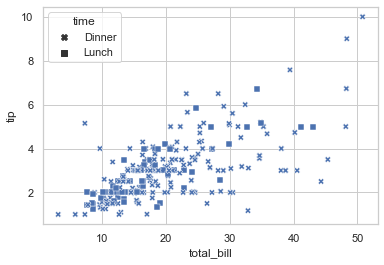
## 以 total_bill 为 x 轴,tip 为 y 轴,time 为分类因子,画出不同 time 类的散点图(用不同颜色区分)
sns.scatterplot(data = tips, x = 'total_bill', y = 'tip', hue = 'time')
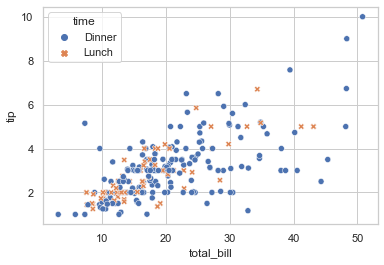
## 在 example 的基础上,增加散点形状区分的条件
sns.scatterplot(data = tips, x = 'total_bill', y = 'tip', hue = 'time', style = 'time')
## 散点的形状和颜色的分类依据可以不同
sns.scatterplot(data = tips, x = 'total_bill', y = 'tip', hue = 'day', style = 'time')
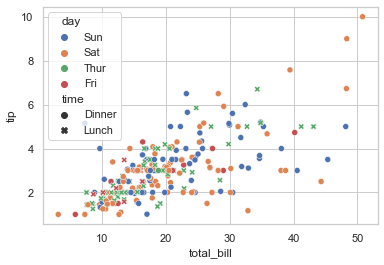
# 若分配给色版的变量是数字,会使用不同的默认调色板
sns.scatterplot(data = tips, x = 'total_bill', y = 'tip', hue = 'size')
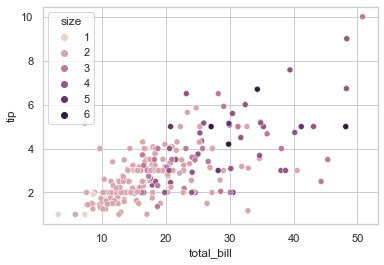
## 可以使用 palette 更改色调
sns.scatterplot(data = tips, x = 'total_bill', y = 'tip', hue = 'size', palette = 'deep')
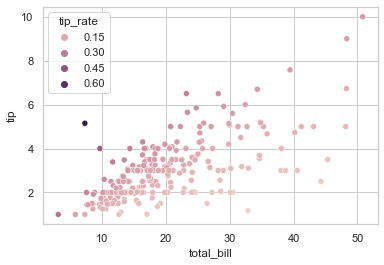
## 如果有大量的唯一数值,图例将显示一个具有代表性的等间距集合
tip_rate = tips.eval('tip / total_bill').rename('tip_rate')
sns.scatterplot(data = tips, x = 'total_bill', y = 'tip', hue = tip_rate)
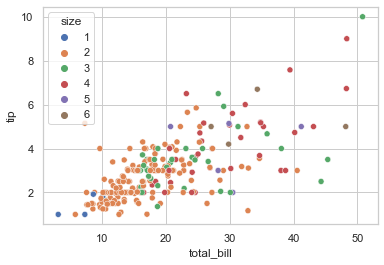
## 在 example 5 的基础上还能增加点的大小
sns.scatterplot(data = tips, x = 'total_bill', y = 'tip', hue = 'size', size = 'size')
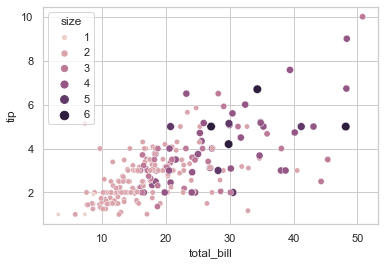
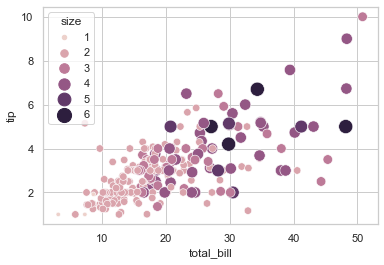
## 可以更改散点的大小
sns.scatterplot(
data = tips, x = 'total_bill', y = 'tip', hue = 'size', size = 'size',
sizes = (20, 200), legend = 'full'
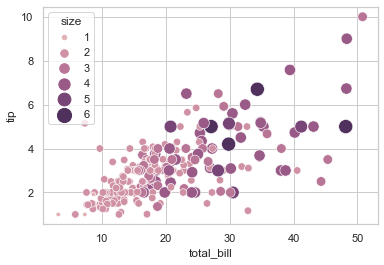
)
## 传入一个元组或matplotlib.colors.Normalize以控制色调
sns.scatterplot(
data = tips, x = 'total_bill', y = 'tip', hue = 'size', size = 'size',
sizes = (20, 200), hue_norm = (0,7), legend = 'full'
)
## 传入一个字典控制散点形状
markers = {'Lunch' : 's', 'Dinner' : 'X'}
sns.scatterplot(data = tips, x = 'total_bill', y = 'tip', style = 'time', markers = markers)
sns.scatterplot(data = tips, x = 'total_bill', y = 'tip', s = 100, color = '.2', marker = "+")
## 可以绘制不同 类型 数据 的 时间序列图像
import numpy as np
import pandas as pd
index = pd.date_range("1 1 2000", periods=100, freq='m', name='date')
data = np.random.randn(100, 4).cumsum(axis=0)
wide_df = pd.DataFrame(data, index, ['a','b','c','d'])
sns.scatterplot(data=wide_df)
wide_df.head()
| a | b | c | d | |
|---|---|---|---|---|
| date | ||||
| 2000-01-31 | 3.381766 | -0.360579 | -0.080106 | 1.578611 |
| 2000-02-29 | 2.724598 | 0.351141 | -0.914548 | 1.825725 |
| 2000-03-31 | 2.276614 | 0.855341 | -0.227480 | 0.075641 |
| 2000-04-30 | 1.385905 | 0.793799 | -0.392478 | -0.053513 |
| 2000-05-31 | -0.011497 | 0.985883 | -0.829674 | 1.539929 |
## 按类别拆分数据,画到不同的子图上
sns.relplot(
data = tips, x = 'total_bill', y = 'tip',
col = 'time', hue = 'day', style = 'day',
kind = 'scatter'
)
我有一个名为posts的模型,它有很多附件。附件模型使用回形针。我制作了一个用于创建附件的独立模型,效果很好,这是此处说明的View(https://github.com/thoughtbot/paperclip):@attachment,:html=>{:multipart=>true}do|form|%>posts中的嵌套表单如下所示:prohibitedthispostfrombeingsaved:@attachment,:html=>{:multipart=>true}do|at_form|%>附件记录已创建,但它是空的。文件未上传。同时,帖子已成功创建...有什么想法吗?
我正在使用Rails3.1并在一个论坛上工作。我有一个名为Topic的模型,每个模型都有许多Post。当用户创建新主题时,他们也应该创建第一个Post。但是,我不确定如何以相同的形式执行此操作。这是我的代码:classTopic:destroyaccepts_nested_attributes_for:postsvalidates_presence_of:titleendclassPost...但这似乎不起作用。有什么想法吗?谢谢! 最佳答案 @Pablo的回答似乎有你需要的一切。但更具体地说...首先改变你View中的这一行对此#
我基本上来自Java背景并且努力理解Ruby中的模运算。(5%3)(-5%3)(5%-3)(-5%-3)Java中的上述操作产生,2个-22个-2但在Ruby中,相同的表达式会产生21个-1-2.Ruby在逻辑上有多擅长这个?模块操作在Ruby中是如何实现的?如果将同一个操作定义为一个web服务,两个服务如何匹配逻辑。 最佳答案 在Java中,模运算的结果与被除数的符号相同。在Ruby中,它与除数的符号相同。remainder()在Ruby中与被除数的符号相同。您可能还想引用modulooperation.
RSpec似乎按顺序匹配方法接收的消息。我不确定如何使以下代码工作:allow(a).toreceive(:f)expect(a).toreceive(:f).with(2)a.f(1)a.f(2)a.f(3)我问的原因是a.f的一些调用是由我的代码的上层控制的,所以我不能对这些方法调用添加期望。 最佳答案 RSpecspy是测试这种情况的一种方式。要监视一个方法,用allowstub,除了方法名称之外没有任何约束,调用该方法,然后expect确切的方法调用。例如:allow(a).toreceive(:f)a.f(2)a.f(1)
A/ctohttp://wiki.nginx.org/CoreModule#usermaster进程曾经以root用户运行,是否可以以不同的用户运行nginxmaster进程? 最佳答案 只需以非root身份运行init脚本(即/etc/init.d/nginxstart),就可以用不同的用户运行nginxmaster进程。如果这真的是你想要做的,你将需要确保日志和pid目录(通常是/var/log/nginx&/var/run/nginx.pid)对该用户是可写的,并且您所有的listen调用都是针对大于1024的端口(因为绑定(
有没有办法跳过CSV文件的第一行,让第二行作为标题?我有一个CSV文件,第一行是日期,第二行是标题,所以我需要能够在遍历它时跳过第一行。我尝试使用slice但它会将CSV转换为数组,我真的很想将其读取为CSV,以便我可以利用header。 最佳答案 根据您的数据,您可以使用另一种方法和skip_lines-option此示例跳过所有以#开头的行require'csv'CSV.parse(DATA.read,:col_sep=>';',:headers=>true,:skip_lines=>/^#/#Markcomments!)do|
有没有办法在sinatra的beforedoblock中停止执行并返回不同的值?beforedo#codeishere#Iwouldliketo'return"Message"'#Iwouldlike"/home"tonotgetcalled.end//restofthecodeget'/home'doend 最佳答案 beforedohalt401,{'Content-Type'=>'text/plain'},'Message!'end如果你愿意,你可以只指定状态,这里有状态、标题和正文的例子
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
我从ui中得到日期范围为-approved_between"=>"2013-03-17-2013-03-18"我需要拆分此approved_start_date="2013-03-17"和approved_end_date="2013-03-18"...我希望使用它在mysql中查询,因为mysql中的日期格式是created_at:2012-07-2810:35:01.我正在做的是:approved=approved_between.split("")approved_start_date=approved[0]approved_end_date=approved[2]很确定这不是处
response是一个散列,可能看起来像以下两种情况之一:response={'demo'=>'nil','test_01'=>'DemoData'}或response={'test'=>'DemoData','demo'=>'nil'}我想做这样的事情:ifresponse.has_key?'test_01'new_response.update(:nps_score=>response['test_01']elsenew_response.update(:nps_score=>response['test']end是否有更“Ruby”的方法来解决这个问题?也许使用||的东西运算符(