目录
项目链接:House Prices - Advanced Regression Techniques | Kaggle
这是kaggle的一个经典Data Science项目,作为数据分析的新手,房价预测是一个很好的入门练习项目。
数据集分为训练集‘train.csv’和测试集‘test.csv’,要求根据房子的质量、面积、街区、壁炉个数等79个特征,预测相应的房价。
评价指标是回归问题中常用的均方误差(RMSE):
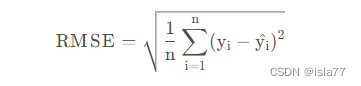
首先导入所需的库:
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息
import numpy as np
import pandas as pd
from scipy.stats import norm, skew #获取统计信息
from scipy import stats # 离散统计分布以及连续统计分布
import seaborn as sns # 绘图包
color = sns.color_palette()
sns.set_style('darkgrid')
import matplotlib
import matplotlib.pyplot as plt
pd.set_option('display.float_format', lambda x: '{:.3f}'.format(x)) # 限制浮点输出到小数点后3位
import os读取训练集和测试集,检查数据集大小,并查看前5行数据:
# 加载数据
train = pd.read_csv('kagglehouse/train.csv')
test = pd.read_csv('kagglehouse/test.csv')
# 检查样本和特征的数量
print("训练集初始大小: {} ".format(train.shape))
print("测试集初始大小: {} ".format(test.shape))训练集初始大小: (1460, 81)
测试集初始大小: (1459, 80)
#查看前5行数据
print(train.head())
print(test.head())
训练集初始大小为1460行81列,测试集初始大小为1459行80列,训练集比测试集多出最后一列价格列,这也是我们测试集的预测目标。
其中第一列Id列没有用,直接删掉:
# 删除原数据集的Id列
train.drop("Id", axis=1, inplace=True)
test.drop("Id", axis=1, inplace=True)目标值就是房屋价格,我们先看一看它的分布情况:
#绘制目标值分布
sns.distplot(train['SalePrice'])
plt.show()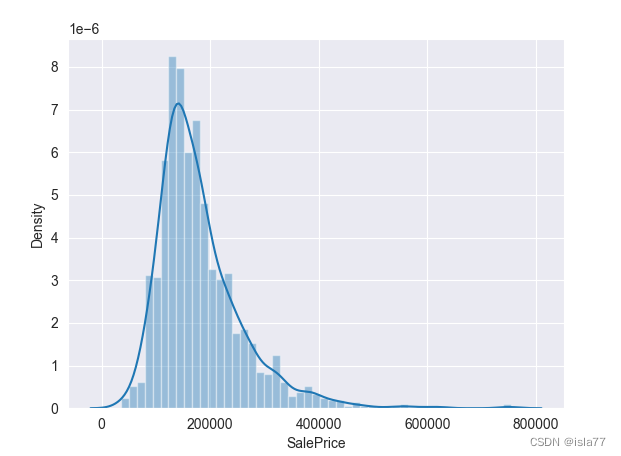
是明显的右偏分布,和正态分布有较大差距,我们再看一下这个分布曲线的峰度和偏度:
# 计算房价的峰度和偏度
SP_skew = train['SalePrice'].skew()
SP_kurt = train['SalePrice'].kurt()
print('峰度:',SP_skew)
print('偏度:',SP_kurt)峰度: 1.8828757597682129
偏度: 6.536281860064529
峰度(Kurtosis)是描述总体中所有取值分布形态陡缓程度的统计量,是与正态分布作比较的。
峰度为0表示该总体数据分布与正态分布的陡缓程度相同;峰度大于0表示该总体数据分布与正态分布相比较为陡峭,为尖顶峰;峰度小于0表示该总体数据分布与正态分布相比较为平坦,为平顶峰。
偏度(Skewness)描述的是某总体取值分布的对称性,同样与正态分布相比较。
偏度为0表示其数据分布形态与正态分布的偏斜程度相同;偏度大于0表示其数据分布形态与正态分布相比为正偏或右偏,即有一条长尾巴拖在右边,数据右端有较多的极端值;偏度小于0表示其数据分布形态与正态分布相比为负偏或左偏。
根据图可知,数据目标值峰度大于0,为尖顶峰,偏度较大,整体呈右偏分布,后期需要我们做一些处理,使其向正态分布靠拢,因为回归模型在正态分布的数据集上表现更好。
查看目标值统计信息:
#查看目标值统计信息
print(train['SalePrice'].describe())count 1460.000
mean 180921.196
std 79442.503
min 34900.000
25% 129975.000
50% 163000.000
75% 214000.000
max 755000.000
Name: SalePrice, dtype: float64
最大值太大了,与75%的取值都差很多,推断最大值附近应该有异常值存在。
下面看一下各个特征与目标值之间的关系,这里要先分开类别特征和数字特征:
num_features = []
cate_features = []
for col in test.columns:
if test[col].dtype == 'object':
cate_features.append(col)
else:
num_features.append(col)
print('数值型特征:', len(num_features))
print('类别型特征:', len(cate_features))数值型特征: 36
类别型特征: 43
先查看各数值型特征与目标值之间的关系,采用散点图:
#数值特征与目标值画散点图
plt.figure(figsize=(20, 30))
plt.subplots_adjust(left=0.1, bottom=0.1,wspace=0.6,hspace=0.6)
for i, feature in enumerate(num_features):
plt.subplot(6,6, i+1)
sns.scatterplot(x=feature, y='SalePrice', data=train, alpha=0.5)
plt.xlabel(feature)
plt.ylabel('SalePrice')
plt.show()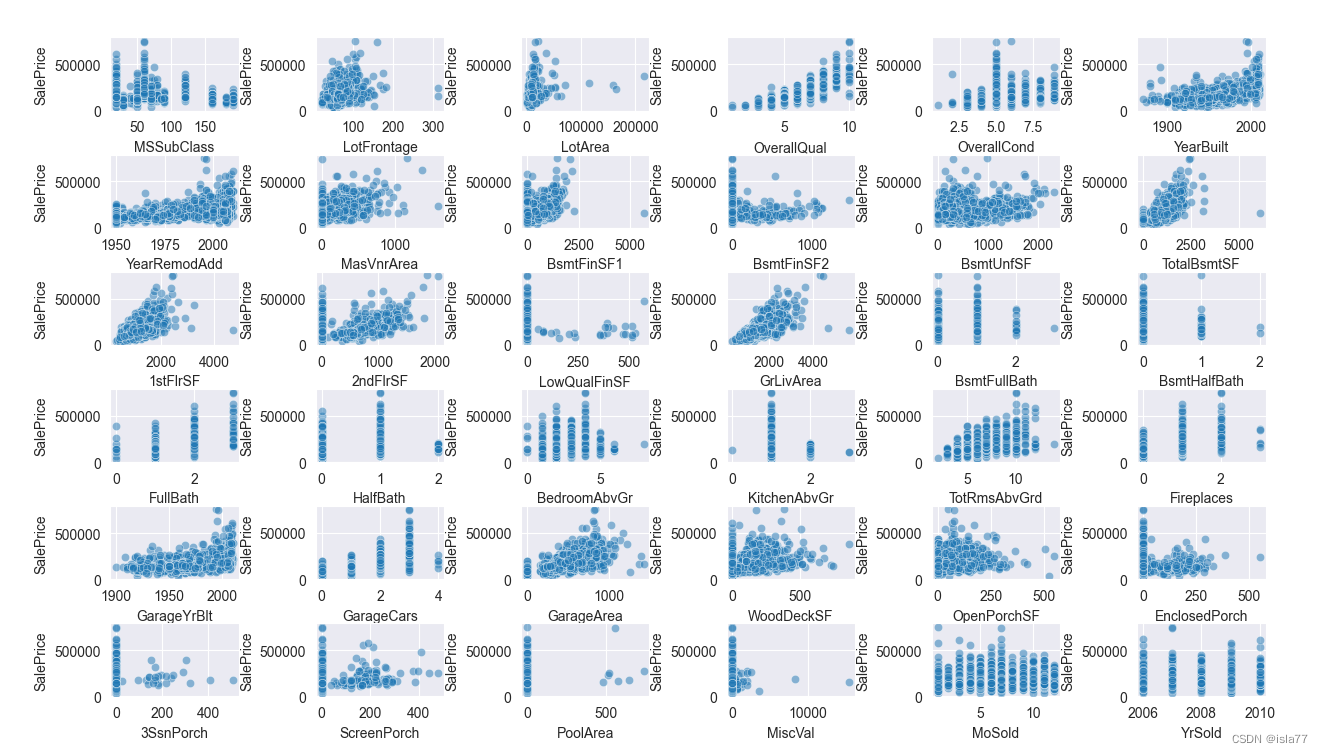
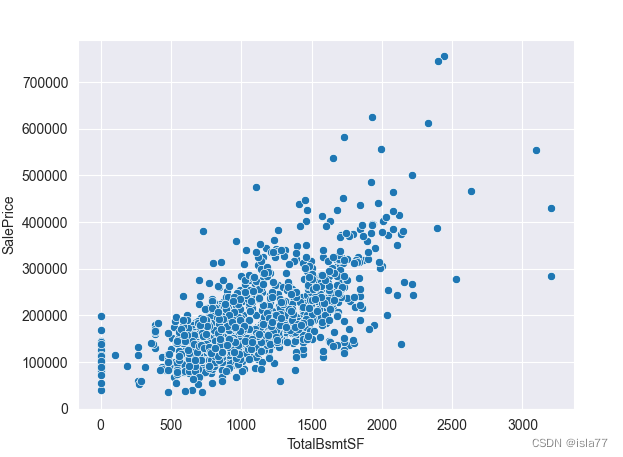
通过散点图发现,“GrLivArea”(地上生活面积)、“TotalBsmtSF”(地下室总面积)、“1stFlrSF”(一层面积)、“2ndFlrSF”(二层面积)这几个数据与目标值呈现明显的线性关系,他们都是与面积相关的,后续可以构造新特征,这也符合常理。
然后再查看一些类别型变量与目标值的关系,用箱型图表示:
上图中的“OverallQual”(房子材料与装修水平)虽然是数值型数据,但是数值实际代表类别,与目标值有明显相关性:
plt.figure(figsize=(20, 16))
sns.boxplot(x='OverallQual', y='SalePrice', data=train)
plt.xlabel('OverallQual')
plt.ylabel('SalePrice')
plt.xticks(rotation=90, fontsize=12)
plt.show()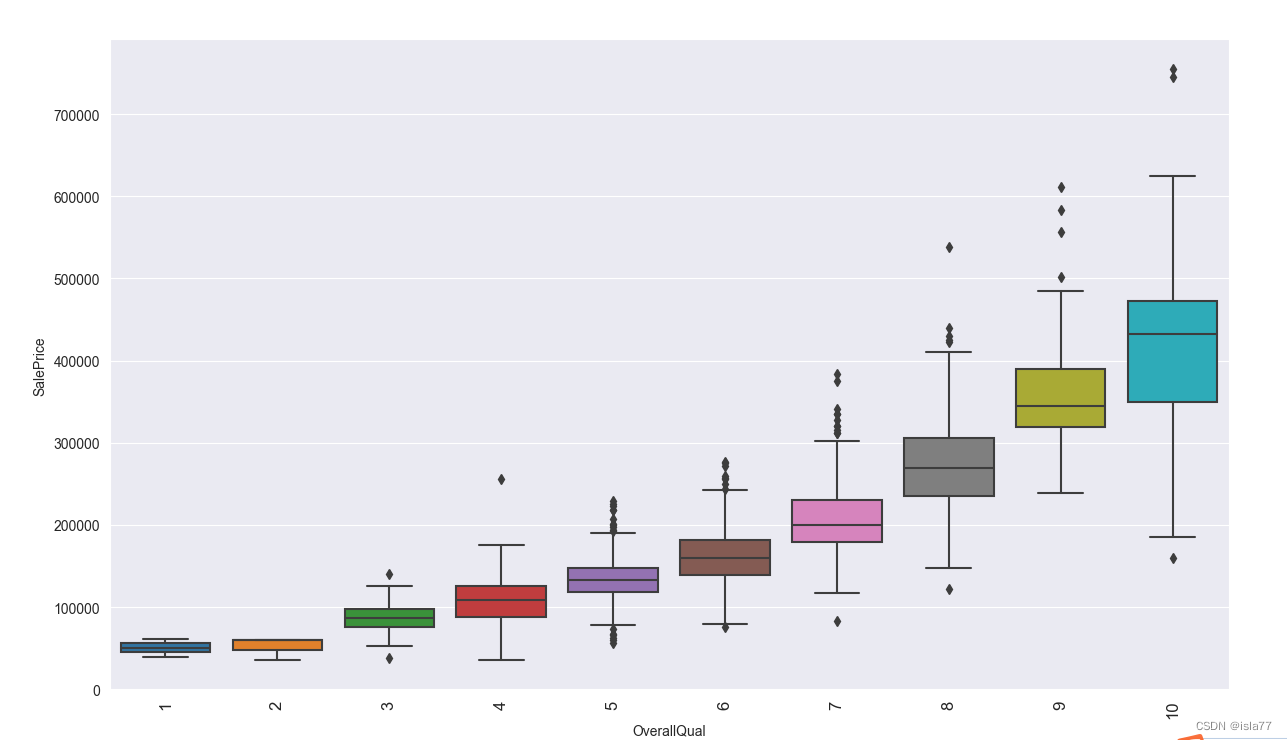
可见装修水平越高,房子售价越高。但是同时意味着购买的人越多么?显然不是,我们通过计算不同装修水平的售出价总和判断哪个装修水平最受青睐:
#柱状图
OverallQual_SalePrice = train[['OverallQual','SalePrice']].groupby(['OverallQual']).sum().sort_values(by='OverallQual',ascending=True)
OverallQual_SalePrice.plot(kind='bar')
plt.show()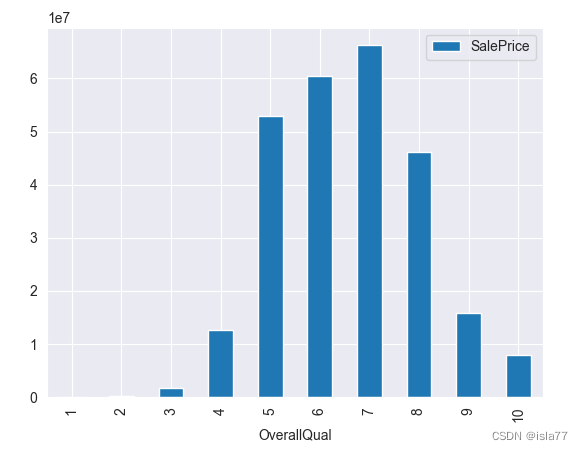
可见5、6、7级装修水平最受买房者青睐。
下面看一下重要的“Neighborhood”(街区位置)与房屋价格的关系:
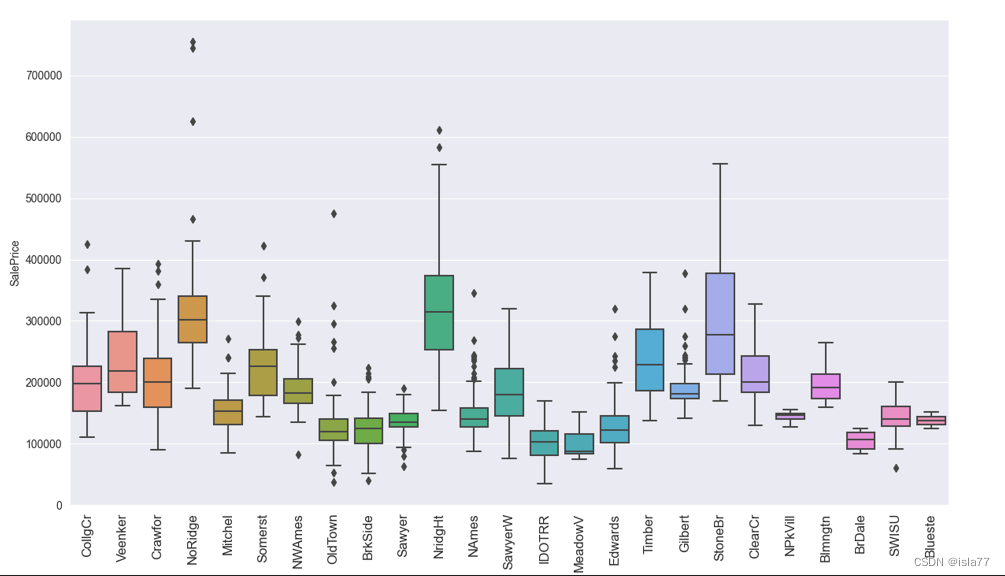
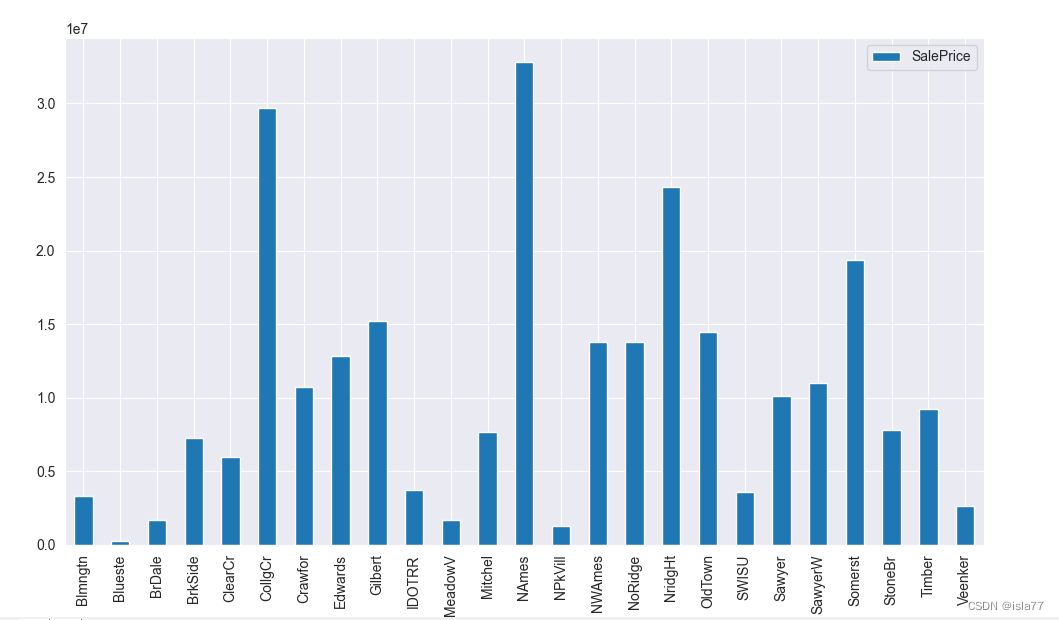
可见不同街区对应不同的房屋价格,NAmes和CollgCr地段房子销售额最高。
接下来看一下变量之间的相关性:
#多变量分析
corrs = train.corr()
plt.figure(figsize=(20, 9))
sns.heatmap(corrs)
plt.show()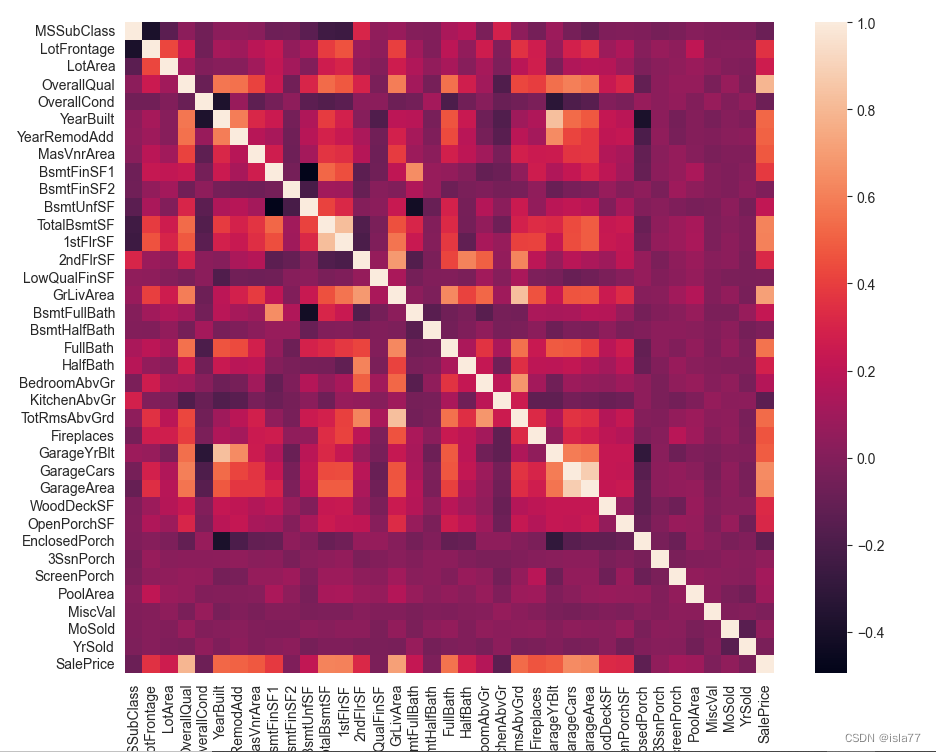
由于特征较多,选取与目标值相关度最高的十个变量再次分析:
corrs = train.corr()
cols_10 = corrs.nlargest(10, 'SalePrice')['SalePrice'].index
corrs_10 = train[cols_10].corr()
plt.figure(figsize=(6, 6))
sns.heatmap(corrs_10, annot=True)
plt.show()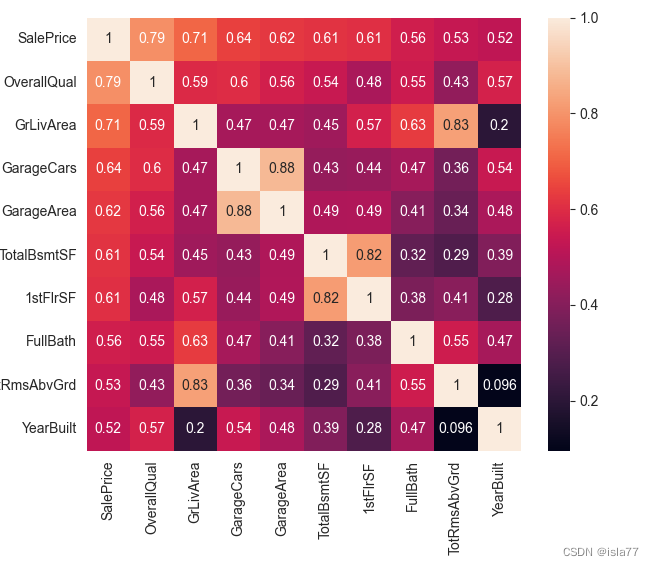
由前面分析已经看到,目标变量呈右偏分布,我们要把他调到标准正态分布,可以采用对数变换。线性回归模型要求变量为正态分布。
y = train['SalePrice']
y = np.log1p(y)
sns.distplot(y, fit=norm)
print('处理后峰度:',y.skew())
print('处理后偏度:',y.kurtosis())
plt.show()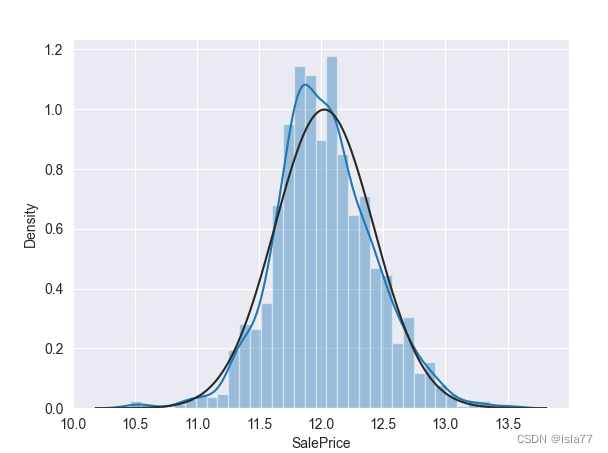
处理后峰度: 0.12134661989685333
处理后偏度: 0.809519155707878
#处理异常值
sns.scatterplot(x='GrLivArea', y='SalePrice', data=train)
plt.show()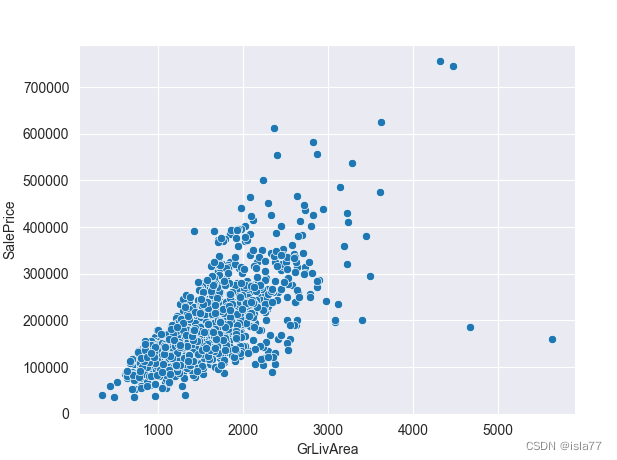
发现右下角有明显的异常值,我们去掉这个异常值:
train = train.drop(train[(train['GrLivArea']>4000) & (train['SalePrice']<200000)].index)
sns.scatterplot(x='GrLivArea', y='SalePrice', data=train)
plt.show()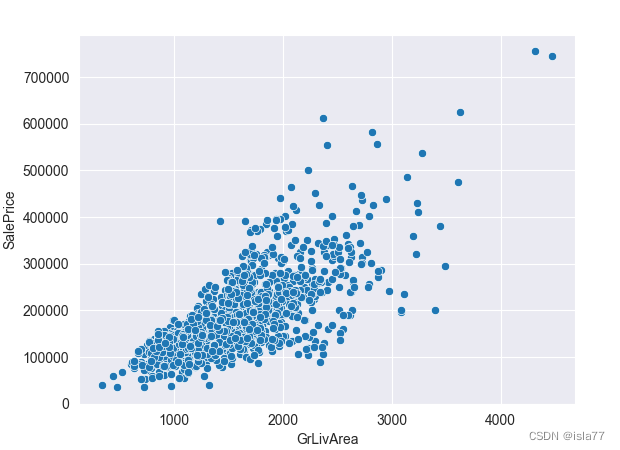
同时发现TotalBsmtSF中的异常值也被去掉了:
很多人是将训练集和测试集拼在一起进行处理,但是这样实际上造成了数据泄露,应该先处理训练值,再用训练值数据同样处理测试值。
先看一下训练集的缺失值个数:
train_nan = train.isnull().sum()
train_nan = train_nan.drop(train_nan[train_nan==0].index).sort_values(ascending=False)
print(train_nan)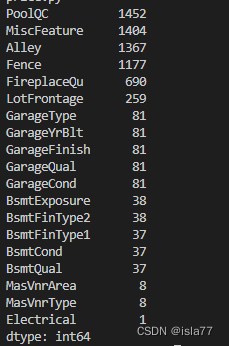
测试集情况也差不多。下面我们填补缺失值。
类别特征缺失值
在data_description.txt中已有说明,一部分特征值的缺失是因为这些房子根本没有该项特征,对于这种情况我们统一用“None”或者“0”来填充。
Python中的None是一个特殊常量,不是0,也不是False,不是空字符串,更多的是表示一种不存在,是真正的空。它就是一个空的对象,只是没有赋值而已。如PoolQC确实的意思是 表示“没有泳池”。
以下这些类别的缺失值填充为None:
none_lists = ['PoolQC', 'MiscFeature', 'Alley', 'Fence', 'FireplaceQu', 'GarageType', 'GarageFinish', 'GarageQual', 'GarageCond', 'BsmtFinType1',
'BsmtFinType2', 'BsmtCond', 'BsmtExposure', 'BsmtQual', 'MasVnrType']
for col in none_lists:
train[col] = train[col].fillna('None')
test[col] = test[col].fillna('None')对于缺失较少的离散型特征,比如Electrical,用众数填补缺失值:
#填充众数
most_lists = ['MSZoning', 'Exterior1st', 'Exterior2nd', 'SaleType', 'KitchenQual', 'Electrical']
for col in most_lists:
train[col] = train[col].fillna(train[col].mode()[0])
test[col] = test[col].fillna(train[col].mode()[0]) Functional居家功能性,数据描述说NA表示类型"Typ"。因此,我们用其填充。
#Functional填充Typ
train['Functional'] = train['Functional'].fillna('Typ')
test['Functional'] = test['Functional'].fillna('Typ')数值特征缺失值
填充0
zero_lists = ['GarageYrBlt', 'MasVnrArea', 'BsmtFullBath', 'BsmtHalfBath', 'BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF', 'GarageCars', 'GarageArea',
'TotalBsmtSF']
for col in zero_lists:
train[col] = train[col].fillna(0)
test[col] = test[col].fillna(0)LotFrontage,由于房屋到街道的距离,最有可能与其附近其他房屋到街道的距离相同或相似,因此我们可以通过该社区的LotFrontage中位数来填充缺失值:
train['LotFrontage'] = train.groupby('Neighborhood')['LotFrontage'].apply(lambda x: x.fillna(x.median()))
for ind in test['LotFrontage'][test['LotFrontage'].isnull().values==True].index:
x = test['Neighborhood'].iloc[ind]
test['LotFrontage'].iloc[ind] = train.groupby('Neighborhood')['LotFrontage'].median()[x]最后我们删除Utilities这个特征,这个特征除了一个“NoSeWa”和 2 个 NA ,其余值都是“AllPub”,因此该项特征的方差非常小。这个特征对预测建模没有帮助。因此,我们可以安全地删除它。
train = train.drop(['Utilities'], axis=1)
test = test.drop(['Utilities'], axis=1)最后检查是否还有缺失值:
print(train.isnull().sum().max())
print(test.isnull().sum().max())返回都为0
转换数值特征为类别特征
部分数值特征虽然是数值,但实际上表征的是类别,因此我们将其转化为类别特征:
train['MSSubClass'] = train['MSSubClass'].apply(str) # apply()函数默认对列进行操作
train['YrSold'] = train['YrSold'].astype(str)
train['MoSold'] = train['MoSold'].astype(str)
test['MSSubClass'] = test['MSSubClass'].apply(str)
test['YrSold'] = test['YrSold'].astype(str)
test['MoSold'] = test['MoSold'].astype(str)转换类别特征为数值特征
有些类别特征实际上有高低好坏之分,这些特征的质量越高,就可能在一定程度导致房价越高,因此要把他转换成编码形式。对于各个类别中可能存在顺序关系的,用LabelEncoder编码,对于不存在顺序关系的,用get_dummies。
先进行LabelEncoder编码,独热编码最后处理:
#LabelEncoder编码
for col in cate_features:
train[col] = train[col].astype(str)
test[col] = test[col].astype(str)
cols = ['Street', 'Alley', 'LotShape', 'LandContour', 'LandSlope', 'HouseStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'ExterQual',
'ExterCond', 'Foundation', 'BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2', 'HeatingQC', 'CentralAir',
'KitchenQual', 'Functional', 'FireplaceQu', 'GarageFinish', 'GarageQual', 'GarageCond', 'PavedDrive', 'PoolQC', 'Fence']
for col in cols:
encoder = LabelEncoder()
value_train = set(train[col].unique())
value_test = set(test[col].unique())
value_list = list(value_train | value_test)
encoder.fit(value_list)
train[col] = encoder.transform(train[col])
test[col] = encoder.transform(test[col])偏斜特征
对于数值型特征,我们希望它们尽量服从正态分布,也就是不希望这些特征出现正负偏态。那么我们先来计算一下各个特征的偏度:
# 计算特征的偏度
numeric_data = train[num_features]
skewed_feats = numeric_data.apply(lambda x: skew(x.dropna())).sort_values(ascending=False)
skewness = pd.DataFrame({'Skew' :skewed_feats})
print(skewness.head(10))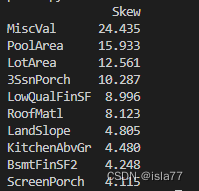
对高偏度的特征进行Box-Cox变换:
new_skewness = skewness[skewness.abs() > 0.5]
print("有{}个高偏度特征被Box-Cox变换".format(new_skewness.shape[0]))有29个高偏度特征被Box-Cox变换
将偏度平滑至0.15
from scipy.special import boxcox1p
skewed_features = new_skewness.index
lam = 0.15
for feat in skewed_features:
train[feat] = boxcox1p(train[feat], lam)
test[feat] = boxcox1p(test[feat], lam)构建新特征
先把训练集和测试集合并,然后构造几个与目标特征相关的新特征
#把所有数据连上
all_data = pd.concat((train.drop('SalePrice', axis=1), test)).reset_index(drop=True)
#构造新特征
all_data['TotalSF'] = all_data['TotalBsmtSF'] + all_data['1stFlrSF'] + all_data['2ndFlrSF'] # 房屋总面积
all_data['OverallQual_TotalSF'] = all_data['OverallQual'] * all_data['TotalSF'] # 整体质量与房屋总面积交互项
all_data['OverallQual_GrLivArea'] = all_data['OverallQual'] * all_data['GrLivArea'] # 整体质量与地上总房间数交互项
all_data['OverallQual_TotRmsAbvGrd'] = all_data['OverallQual'] * all_data['TotRmsAbvGrd'] # 整体质量与地上生活面积交互项
all_data['GarageArea_YearBuilt'] = all_data['GarageArea'] * all_data['YearBuilt'] # 车库面积与建造时间交互项
all_data['IsRemod'] = 1
all_data['IsRemod'].loc[all_data['YearBuilt']==all_data['YearRemodAdd']] = 0 #是否翻新(翻新:1, 未翻新:0)
all_data['BltRemodDiff'] = all_data['YearRemodAdd'] - all_data['YearBuilt'] #翻新与建造的时间差(年)独热编码
把剩余的类别特征赋予独热编码:
dummy_features = list(set(cate_features).difference(set(cols)))
all_data = pd.get_dummies(all_data, drop_first=True) trainset = all_data[:1458]
y = train['SalePrice']
trainset['SalePrice'] = y.values
testset = all_data[1458:]
trainset.to_csv('train_data.csv', index=False)
testset.to_csv('test_data.csv', index=False)
print('The shape of training data:', trainset.shape)
print('The shape of testing data:', testset.shape)
The shape of training data: (1458, 163)
The shape of testing data: (1459, 162)
可以看到,通过一系列处理之后,训练集的列数增加到163,测试集为162。
导入所需库
import numpy as np
import pandas as pd
import time
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso, Ridge
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import KFold, cross_val_score
from sklearn.metrics import mean_squared_error
import warnings
def ignore_warn(*args, **kwargs):
pass
warnings.warn = ignore_warn
pd.set_option('display.float_format', lambda x: '{:.3f}'.format(x)) # 限制浮点输出到小数点后3位拟定不同的50个参数,通过交叉验证选取适合的参数。交叉验证,存储不同的alpha下,均方误差,通过绘图不同参数下的误差曲线查看最好的参数。
y_train = np.log1p(train.pop('SalePrice'))
#岭回归
alphas =np.logspace(-3,2,50)
test_scores = []
for alpha in alphas:
clf = Ridge(alpha)
test_score = np.sqrt(-cross_val_score(clf,train.values,y_train,cv=10,scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
plt.plot(alphas,test_scores)
plt.show()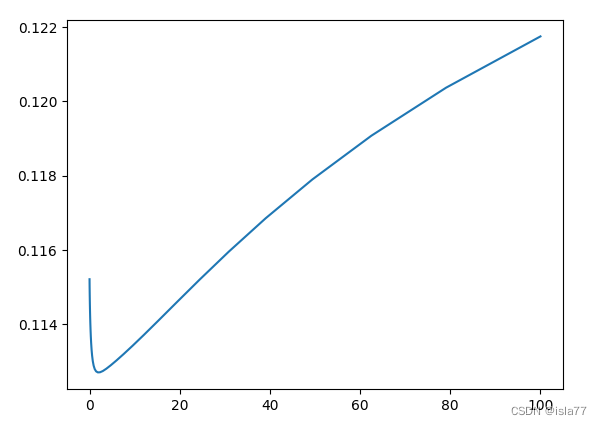
进一步找到最佳位置:
alphas =np.logspace(0,1,50)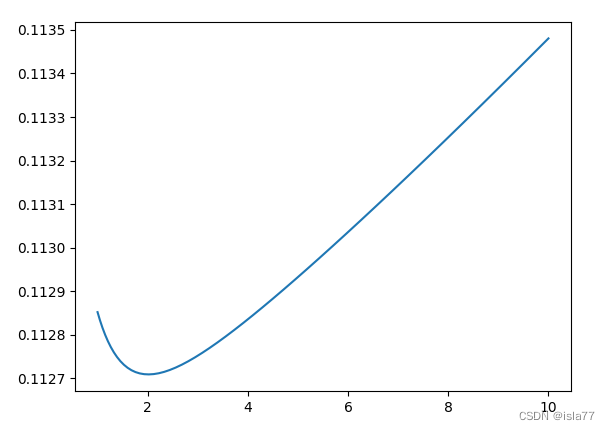
alpha=2.0附近,平均test_score最低,为0.1127
lasso_alpha = np.logspace(-4,1,50)
test_scores = []
for alpha in lasso_alpha:
lasso =Lasso(alpha)
test_score = np.sqrt(-cross_val_score(lasso, train.values, y_train, scoring='neg_mean_squared_error', cv=10))
test_scores.append(np.mean(test_score))
print(alpha,np.mean(test_score))
plt.plot(lasso_alpha,test_scores)
plt.show()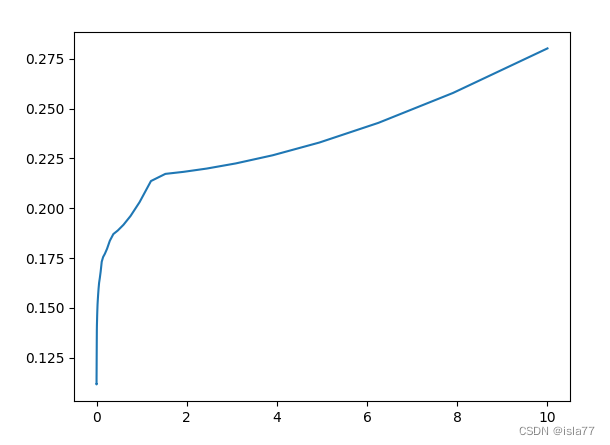
lasso_alpha = np.logspace(-5,-2,50)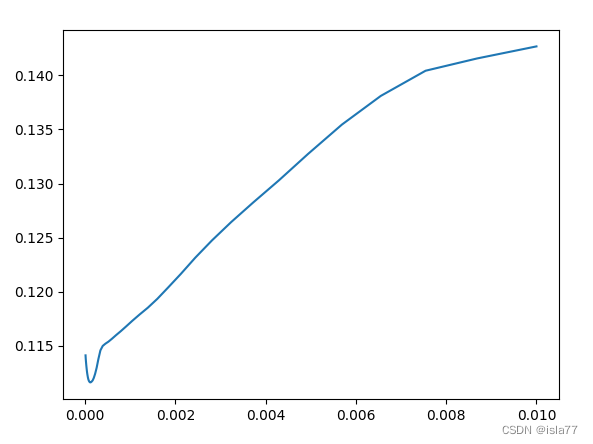
alpha=0.0001附近,平均test_score最低,为0.1116
主要参数:
n_estimators:表示森林里树的个数;
max_features:随机选择特征集合的子集合,并用来分割节点。
将树的个数作为变量,以子集0.3倍的特征,采用交叉验证的方式,来探索多少树个数能得到好的效果。
from sklearn.ensemble import RandomForestRegressor
Ns = [50,100,150,200,250,300,350,400]
test_scores = []
for N in Ns:
clf = RandomForestRegressor(n_estimators=N, max_features=0.3)
test_score = np.sqrt(-cross_val_score(clf, train.values, y_train, cv=10, scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
print(f"N:{N},平均test_score:{sum(test_score)/10}")
plt.plot(Ns,test_scores)
plt.show() 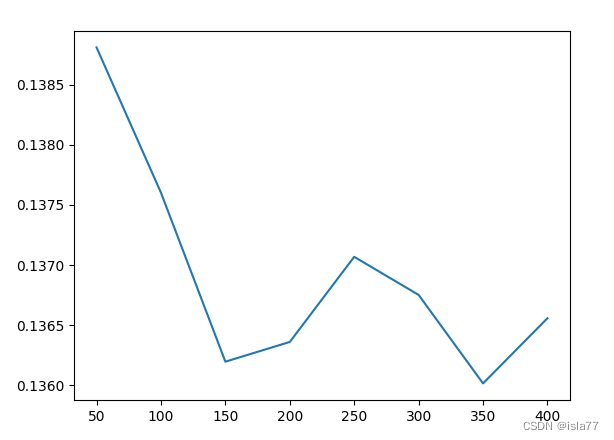
N=350时,平均test_score最低,为0.136
最终选择错误率最低的lasso模型预测测试集:
lasso = Lasso(alpha=0.0001)
lasso.fit(train.values, y_train)
lasso_predict = lasso.predict(test.values)
y_lasso = np.expm1(lasso_predict)保存结果
test0 = pd.read_csv('kagglehouse/test.csv')
test_id = test0['Id']
submission=pd.DataFrame()
submission['Id']=test_id
submission['SalePrice'] = y_lasso
submission.to_csv('kagglehouse/submission.csv', index=False)我在kaggle上上传了最终结果,排名891,大概在21%,作为第一次kaggle比赛,接下来还需要后续的优化过程~

参考资料
Kaggle经典项目——房价预测_Harold_Ran的博客-CSDN博客Kaggle房价预测详解_夜的乄第七章的博客-CSDN博客_kaggle房价预测
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
我正在使用Rails3.1并在一个论坛上工作。我有一个名为Topic的模型,每个模型都有许多Post。当用户创建新主题时,他们也应该创建第一个Post。但是,我不确定如何以相同的形式执行此操作。这是我的代码:classTopic:destroyaccepts_nested_attributes_for:postsvalidates_presence_of:titleendclassPost...但这似乎不起作用。有什么想法吗?谢谢! 最佳答案 @Pablo的回答似乎有你需要的一切。但更具体地说...首先改变你View中的这一行对此#